- 第一:Spark Streaming基本原理
- 第二:为什么需要Spark Streaming?
- 第三:Spark Streaming应用程序数据流是什么
- 第四: 使用DStream简化Streaming应用程序
- 模拟方法
- 实施
- 第五:结构化流
- 第六:利用PySpark Streaming读取和分析数据
- Spark Streaming + Kafka Integration Guide (Kafka broker version 0.8.2.1 or higher)">第七:Spark Streaming + Kafka Integration Guide (Kafka broker version 0.8.2.1 or higher)
- Spark Streaming + Flume Integration Guide (Kafka broker version 0.8.2.1 or higher)">第八:Spark Streaming + Flume Integration Guide (Kafka broker version 0.8.2.1 or higher)
第一:Spark Streaming基本原理
Spark Streaming的核心是一种可扩展、容错的数据流系统,它采用RDD批量模式(即批量处理数据)并加快处理速度。Spark Streaming可以以小批量或批次间隔(从500毫秒到更大的的间隔窗口)运行。
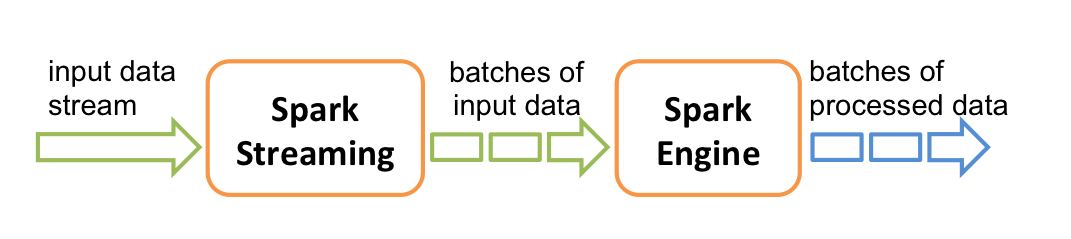 如上图所示,Spark Streaming接收输入数据流,并在内部将数据流分为多个较小的batch(batch大小取决于batch的间隔)。Spark引擎将这些输入数据的batch处理后,生成处理过数据的batch结果集。
如上图所示,Spark Streaming接收输入数据流,并在内部将数据流分为多个较小的batch(batch大小取决于batch的间隔)。Spark引擎将这些输入数据的batch处理后,生成处理过数据的batch结果集。
Spark Streaming的主要抽象是离散流(DStream),它代表了前面提到的构成数据流的那些小批量。DSteam建立在RDD之上,允许Spark开发人员在RDD和batch的相同上下文中工作,现在只将其应用于一系列流问题当中。另外一个重要的方面是,由于你使用的是Apache Spark,Spark Streaming与ML、SQL、DataFrame和GraphFrames都做了集成。
 Spark Streaming的基本组件:
Spark Streaming的基本组件:
Spark Streaming是Spark API核心的扩展,支持可扩展,高吞吐量,实时数据流的容错流处理。 数据可以从Kafka,Flume,Kinesis或TCP套接字等许多来源获取,并且可以使用复杂的算法进行处理,这些算法用map,reduce,join和window等高级函数表示。 最后,处理的数据可以推送到文件系统,数据库和实时仪表板。 事实上,您可以将Spark的机器学习和图形处理算法应用于数据流。
其中,Kafaka+Spark Streaming最常用。
Apache Kafka将发布 - 订阅消息传递重新视为分布式的,分区的,复制的提交日志服务。 在使用Spark开始集成之前,请仔细阅读Kafka文档。
Kafka项目在0.8和0.10版本之间引入了一个新的 consumer API,因此有两个独立的相应的Spark Streaming软件包可用。 请为您的brokers和desired features 选择正确的版本。 注意0.8集成与后来的0.9和0.10代理兼容,但0.10集成与早期的代理不兼容。
Kafka 0.8版本
第二:为什么需要Spark Streaming?
随着在线交易和社交媒体以及传感器和设备的普及,很多公司正在以更快的速度产生和处理更多的数据。开发有规模的,实时的可实现的可预测的能力,为这些企业提供了竞争优势,流分析在数据科学家和数据工程师的工具箱中变得日益重要。
Spark Streaming正在被迅速采用,原因在于Apache Spark在同一框架内统一了所有这些不同的数据处理范例(ML的机器学习,Spark SQL和Streaming)。用户可以从培训机器学习模型(ML)到使用模型(Streaming)评测模型,并使用BI工具(SQL)执行分析与可视化展示,所有这些都在同一框架内完成。
Spark Streaming目前的应用场景!
(1)流ETL:将数据推入下游系统之前对其进行持续的清洗和聚合,可以减少最终数据存储中的数据量。
(2)触发器(Triggers):实时检测行为或异常事件,及时触发下游动作。
(3)数据浓缩:实时数据与其他数据集连接,可以进行更为丰富的分析。
(4)复杂会话和持续学习。
第三:Spark Streaming应用程序数据流是什么
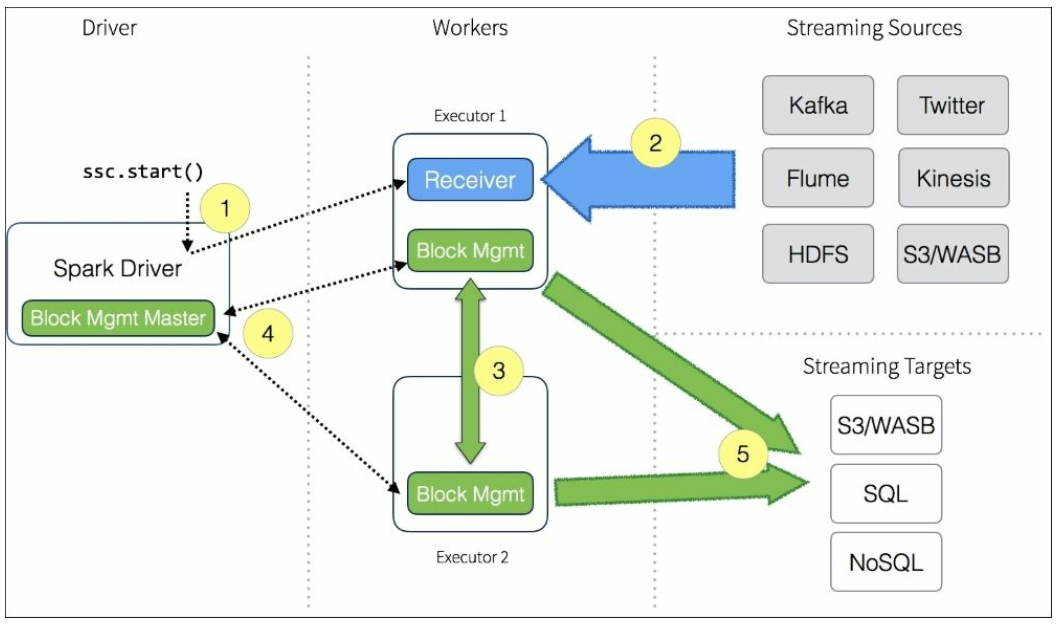 如上图所示,提供了Spark Driver/Workers/Streaming源与目标间的数据流:Spark Streaming Context的ssc.start()是入口点。
如上图所示,提供了Spark Driver/Workers/Streaming源与目标间的数据流:Spark Streaming Context的ssc.start()是入口点。
目前,Spark Streaming有很多应用程序需要不断优化和配置。 Spark Streaming的文档在Scala中更完整,所以,因为您正在使用Python API,您可能有时需要请参考文档的Scala版本。
第四: 使用DStream简化Streaming应用程序
Spark Streaming的基本原理是将实时输入数据流以时间片(通常在0.5~2秒之间)为单位进行拆分,然后采用Spark引擎以类似批处理的方式处理每个时间片数据。
Spark Streaming最主要的抽象是离散化数据流(Discretized Stream,DStream),表示连续不断的数据流。在内部实现上,Spark Streaming的输入数据按照时间片(如1秒)分成一段一段,每一段数据转换为Spark中的RDD,并且对DStream的操作都最终被转变为对相应的RDD的操作。例如,如图7-10所示,在进行单词的词频统计时,一个又一个句子会像流水一样源源不断到达,Spark Streaming会把数据流切分成一段一段,每段形成一个RDD,即RDD @ time1、RDD @ time 2、RDD@ time 3和RDD @ time 4等,每个RDD里面都包含了一些句子,这些RDD就构成了一个DStream (名称为lines)。对这个DStream执行flatMap操作时,实际上会被转换成针对每个RDD的flatMap操作,转换得到的每个新的RDD中都包含了一些单词,这些新的RDD(即RDD @ result 1、RDD @result 2、RDD @ result 3、RDD @ result 4等)又构成了一个新的DStream(名称为words)。整个流式计算可根据业务的需求对这些中间的结果进一步处理,或者存储到外部设备中。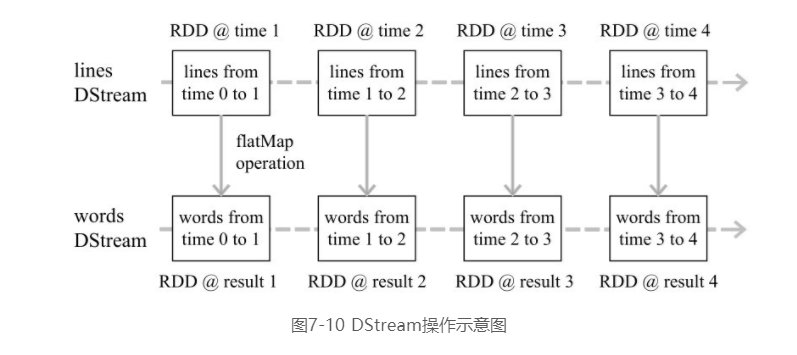
4.1 DStream操作概述
Spark Streaming工作机制
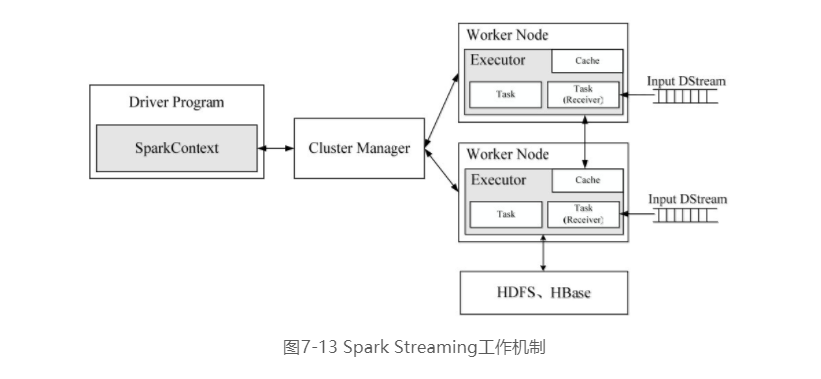
如图7-13所示,在Spark Streaming中,会有一个组件Receiver,作为一个长期运行的任务(Task)运行在一个Executor上,每个Receiver都会负责一个DStream输入流(如从文件中读取数据的文件流、套接字流或者从Kafka中读取的一个输入流等)。Receiver组件接收到数据源发来的数据后,会提交给Spark Streaming程序进行处理。处理后的结果,可以交给可视化组件进行可视化展示,也可以写入到HDFS、HBase中。
编写Spark Streaming程序的基本步骤
编写Spark Streaming程序的基本步骤如下:
• 通过创建输入 DStream(Input Dstream)来定义输入源。流计算处理的数据对象是来自输入源的数据,这些输入源会源源不断产生数据,并发送给Spark Streaming,由Receiver组件接收到以后,交给用户自定义的Spark Streaming程序进行处理;
• 通过对DStream应用转换操作和输出操作来定义流计算。流计算过程通常是由用户自定义实现的,需要调用各种DStream操作实现用户处理逻辑;
• 调用StreamingContext对象的start()方法来开始接收数据和处理流程;
• 通过调用StreamingContext对象的awaitTermination()方法来等待流计算进程结束,或者可以通过调用StreamingContext对象的stop()方法来手动结束流计算进程。
创建StreamingContext对象
在RDD编程中需要生成一个SparkContext对象,在Spark SQL编程中需要生成一个SparkSession对象,同理,如果要运行一个Spark Streaming程序,就需要首先生成一个StreamingContext对象,它是Spark Streaming程序的主入口。
可以从一个SparkConf对象创建一个StreamingContext对象。登录Linux系统后,启动spark-shell。进入spark-shell以后,就已经获得了一个默认的SparkConext对象,也就是sc。因此,可以采用如下方式来创建StreamingContext对象:
scala> import org.apache.spark.streaming._scala> val ssc = new StreamingContext(sc, Seconds(1))
new StreamingContext(sc, Seconds(1))的两个参数中,sc表示SparkContext对象,Seconds(1)表示在对 Spark Streaming 的数据流进行分段时,每1秒切成一个分段。可以调整分段大小,比如使用Seconds(5)就表示每5秒切成一个分段。但是,该系统无法实现毫秒级别的分段,因此,Spark Streaming无法实现毫秒级别的流计算。
如果是编写一个独立的Spark Streaming程序,而不是在spark-shell中运行,则需要在代码文件中通过如下方式创建StreamingContext对象:
maven:
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><spark.version>2.2.1</spark.version><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target></properties><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version><scope>test</scope></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.11</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka_2.11</artifactId><version>1.6.2</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>2.11.8</version></dependency></dependencies>
package com.hx.testimport org.apache.spark._import org.apache.spark.streaming._/*** fileName : Test11StreamingWordCount* Created by 970655147 on 2016-02-12 13:21.*/object Test11StreamingWordCount {// 基于sparkStreaming的wordCount// 环境windows7 + spark1.2 + jdk1.7 + scala2.10.4// 1\. 启动netcat [nc -l -p 9999]// 2\. 启动当前程序// 3\. netcat命令行中输入数据// 4\. 回到console, 查看结果[10s 之内]// *******************************************// 每一个print() 打印一次// -------------------------------------------// Time: 1455278620000 ms// -------------------------------------------// Another Infomation !// *******************************************// inputText : sdf sdf lkj lkj lkj lkj// MappedRDD[23] at count at Test11StreamingWordCount.scala:39// 2// (sdf,2), (lkj,4)def main(args :Array[String]) = {// Create a StreamingContext with a local master// Spark Streaming needs at least two working thread// val conf = new SparkConf().setAppName("TestDStream").setMaster("local[2]")// val sc = new StreamingContext(conf, Seconds(1))val sc = new StreamingContext("local[2]", "NetworkWordCount", Seconds(10) )// Create a DStream that will connect to serverIP:serverPort, like localhost:9999val lines = sc.socketTextStream("192.168.47.141", 9999)// Split each line into words// 以空格把收到的每一行数据分割成单词val words = lines.flatMap(_.split(" "))// 在本批次内计单词的数目val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)// 打印每个RDD中的前10个元素到控制台wordCounts.print()sc.start() // 开始计算sc.awaitTermination() // 等待计算结束}}
4.2 基本输入源
文件流
文件流在文件流的应用场景中,需要编写Spark Streaming程序,一直对文件系统中的某个目录进行监听,一旦发现有新的文件生成,Spark Streaming 就会自动把文件内容读取过来,使用用户自定义的处理逻辑进行处理。
套接字流
Spark Streaming可以通过Socket端口监听并接收数据,然后进行相应处理。
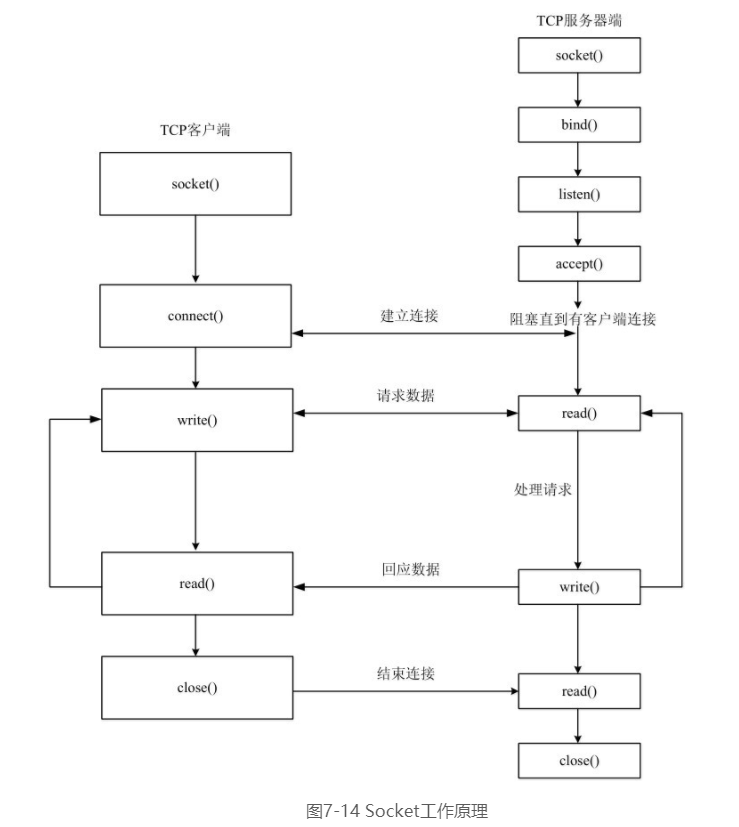
- Socket工作原理
在网络编程中,大量的数据交换都是通过Socket实现的。Socket工作原理和日常生活的电话交流非常类似。在日常生活中,用户A要打电话给用户B,首先,用户A拨号,用户B听到电话铃声后提起电话,这时A和B就建立起了连接,二者之间就可以通话了。等交流结束以后,挂断电话结束此次交谈。Socket工作过程也是类似的,即“open(拨电话)—write/read(交谈)—close(挂电话)”模式。如图7-14所示,服务器端先初始化Socket,然后与端口绑定(Bind),对端口进行监听(Listen),调用accept()方法进入阻塞状态,等待客户端连接。客户端初始化一个Socket,然后连接服务器(Connect),如果连接成功,这时客户端与服务器端的连接就建立了。客户端发送数据请求,服务器端接收请求并处理请求,然后把回应数据发送给客户端,客户端读取数据,最后关闭连接,一次交互结束。
- 2.使用套接字流作为数据源
在套接字流作为数据源的应用场景中,Spark Streaming程序就是图7-14所示的Socket通信的客户端,它通过Socket方式请求数据,获取数据以后启动流计算过程进行处理。下面编写一个Spark Streaming独立应用程序来实现这个应用场景。执行上面命令以后,就在当前的Linux终端(即“流计算终端”)内顺利启动了Socket客户端。现在,再打开一个新的Linux终端(这里称为“数据源终端”),启动一个Socket服务器端,让该服务器端接收客户端的请求,并给客户端不断发送数据流。通常,Linux发行版中都带有NetCat(简称nc),可以使用如下nc命令生成一个Socket服务器端:$ nc -lk 9999在上面的nc命令中,-l这个参数表示启动监听模式,也就是作为Socket服务器端,nc会监听本机(localhost)的9999号端口,只要监听到来自客户端的连接请求,就会与客户端建立连接通道,把数据发送给客户端;-k参数表示多次监听,而不是只监听1次。
由于之前已经在“流计算终端”内运行了NetworkWordCount程序,该程序扮演了Socket客户端的角色,会向本地(localhost)主机的9999号端口发起连接请求,所以,“数据源终端”内的nc程序就会监听到本地(localhost)主机的9999号端口有来自客户端(NetworkWordCount程序)的连接请求,于是就会建立服务器端(nc程序)和客户端(NetworkWordCount程序)之间的连接通道。连接通道建立以后,nc 程序就会把我们在“数据源终端”内手动输入的内容,全部发送给“流计算终端”内的NetworkWordCount程序进行处理。为了测试程序运行效果,在“数据源终端”内执行上面的nc命令后,可以通过键盘输入一行英文句子后按Enter键,反复多次输入英文句子并按Enter键,nc程序会自动把一行又一行的英文句子不断发送给“流计算终端”的NetworkWordCount程序。在“流计算终端”内,NetworkWordCount程序会不断接收到nc发来的数据,每隔1秒就会执行词频统计,并打印出词频统计信息
4.3 高级数据源
Kafka
Spark Streaming是用来进行流计算的组件,可以把Kafka(或Flume)作为数据源,让Kafka(或Flume)产生数据发送给Spark Streaming应用程序,Spark Streaming应用程序再对接收到的数据进行实时处理,从而完成一个典型的流计算过程。这里仅以Kafka为例进行介绍,Spark和Flume的组合使用也是类似的
Kafka是一种高吞吐量的分布式发布订阅消息系统,为了更好地理解和使用Kafka,这里介绍一下Kafka的相关概念:
• Broker:Kafka集群包含一个或多个服务器,这些服务器被称为Broker。
• Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个Broker上,但用户只需指定消息的Topic,即可生产或消费数据,而不必关心数据存于何处。
• Partition:是物理上的概念,每个Topic包含一个或多个Partition。
• Producer:负责发布消息到Kafka Broker。
• Consumer:消息消费者,向Kafka Broker读取消息的客户端。
• Consumer Group:每个Consumer属于一个特定的Consumer Group,可为每个Consumer指定Group Name,若不指定Group Name,则属于默认的Group。
为了让Spark Streaming应用程序能够顺利使用Kafka数据源,在下载Kafka安装文件的时候要注意,Kafka版本号一定要和自己电脑上已经安装的Scala版本号一致才可以。本教材安装的Spark版本号是2.1.0,Scala版本号是2.11,所以,一定要选择Kafka版本号是2.11开头的。例如,到Kafka官网中,可以下载安装文件kafka_2.11-0.10.2.0,前面的2.11就是支持的Scala版本号,后面的0.10.2.0是Kafka自身的版本号。
- 添加相关jar包
Kafka和Flume等高级输入源,需要依赖独立的库(jar文件)。已经安装好的Spark版本,这些jar包都不在里面。下载spark-streaming-kafka-0-8_2.11-2.1.0.jar文件。现在,需要把这个文件复制到Spark目录的jars目录下。
用spark streaming流式处理kafka中的数据,第一步当然是先把数据接收过来,转换为spark streaming中的数据结构Dstream。接收数据的方式有两种:1.利用Receiver接收数据,2.直接从kafka读取数据。
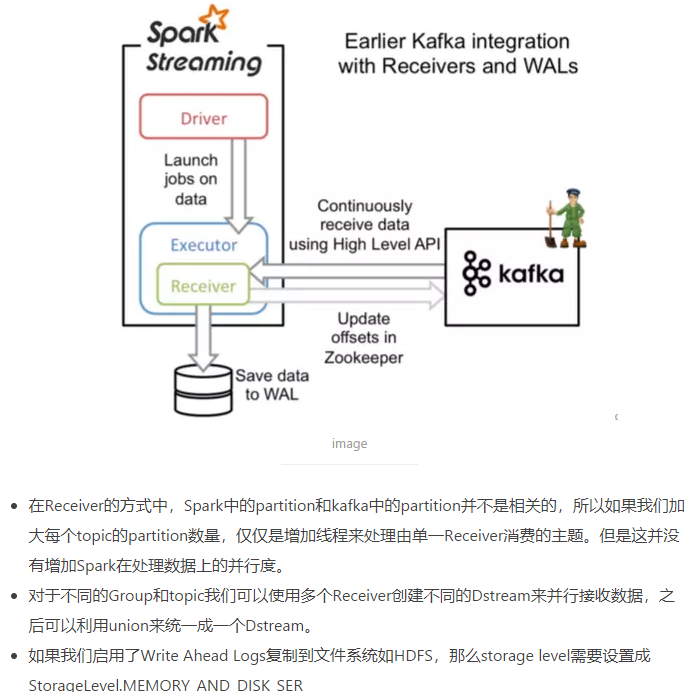
基于Receiver的方式
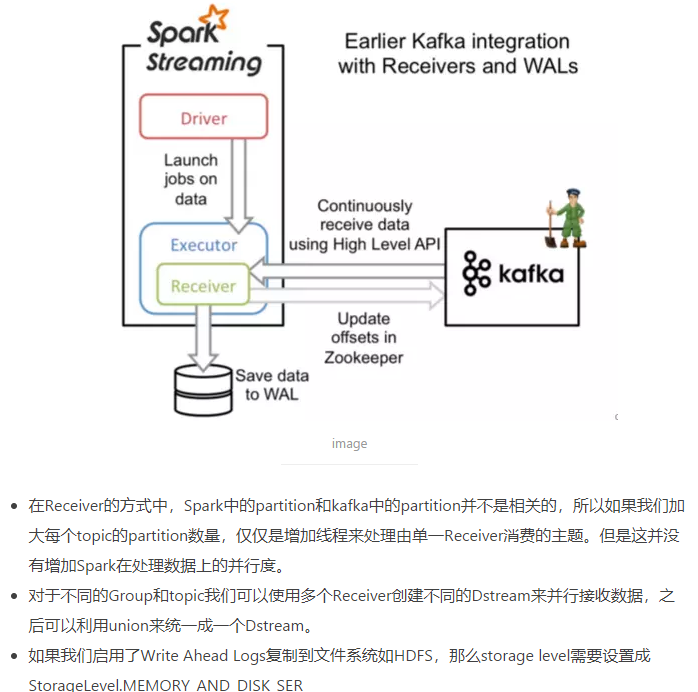
这种方式利用接收器(Receiver)来接收kafka中的数据,其最基本是使用Kafka高阶用户API接口。对于所有的接收器,从kafka接收来的数据会存储在spark的executor中,之后spark streaming提交的job会处理这些数据。如下图:
直接Direct读取方式

offset存储问题
2.1 背景
spark streaming + kafka 是很常见的分布式流处理组合。spark streaming 消费kafka有两种方式:Receiver DStream方式和Direct DStream的方式,前者不需要自己管理offset,但是比较迂回会产生大量数据冗余到hdfs,后者比较直接,但是如果程序出现问题导致需要重启,那么offset的存储就可以避免重复消费或者丢失数据,所以Direct DStream的offset 需要自己管理。
2.2 方式
在官网文档上我们可以看到三种存储offset的方式。
2.2.1 Checkpoints
这种方式使用简单,直接利用spark streaming的checkpoint机制把offset存到hdfs里,但是比较坑的是,除了offset,还有spark streaming的很多字节数据都备份了,所以修改了代码就不能再从checkpoint启动了。
2.2.2 Kafka itself
kafka会自动将offset存到另一个topic,注意 enable.auto.commit 要设置为false,不然默认是定期自动存储,会出问题。想用这种方式的话官网文档有示例。
2.2.3 Your own data store .
第三种方式是自己DIY,可以存到mysql、hbase、zookeeper等等。
之前用过存储到hbase,目前组内好像spark和hbase不是通的。
offset存储到zk的方式,网上也有很多可用的代码,但是对于spark2.x和kafka 10的组合,并没有找到可用的代码,相比于旧版本,api的更改还是很多的。
2.3 offset存储到zookeeper
版本:spark-streaming-kafka-0-10_2.11-2.2.0.jar 和 kafka_2.11-0.10.0.1.jar
调用示例:
createDStream(
ssc,
“test0418”,
“test_spark_streaming_group”,
“localhost:2181”,
“localhost:9092”,
kafkaParams
)
/*** 创建DStream,会读取zk上存储的offset,没有的话就直接创建一个* @param ssc* @param topics* @param group* @param ZKservice* @param broker* @param kafkaParams* @return*/def createDStream(ssc:StreamingContext, topics:Set[String], group:String, ZKservice:String,broker:String, kafkaParams:Map[String, Object]):InputDStream[ConsumerRecord[String, String]] ={val zkClient = new ZkClient(ZKservice)var kafkaStream : InputDStream[ConsumerRecord[String, String]] = nullvar fromOffsets: Map[TopicPartition, Long] = Map()for(topic <-topics){//创建一个 ZKGroupTopicDirs 对象val topicDirs = new ZKGroupTopicDirs(group, topic)// 获取 zookeeper 中的路径,这里会变成 /consumers/test_spark_streaming_group/offsets/topic_nameval zkTopicPath = s"${topicDirs.consumerOffsetDir}"//查询该路径下是否字节点(默认有字节点为我们自己保存不同 partition 时生成的)val children = zkClient.countChildren(s"${topicDirs.consumerOffsetDir}")//如果 zookeeper 中有保存 offset,我们会利用这个 offset 作为 kafkaStream 的起始位置val leaders = getLeaders(topic,broker)if (children > 0) {//如果保存过 offset,这里更好的做法,还应该和 kafka 上最小的 offset 做对比,不然会报 OutOfRange 的错误for (i <- 0 until children) {val partitionOffset = zkClient.readData[String](s"${topicDirs.consumerOffsetDir}/${i}")val tp = new TopicPartition(topic, i)val tap = TopicAndPartition(topic, i)//比较最早的offsetval requestMin = OffsetRequest(Map(tap -> PartitionOffsetRequestInfo(OffsetRequest.EarliestTime, 1)))val consumerMin = new SimpleConsumer(leaders.get(i).get, 9092, 10000, 10000, "getMinOffset")val curOffsets = consumerMin.getOffsetsBefore(requestMin).partitionErrorAndOffsets(tap).offsetsvar nextOffset = partitionOffset.toLongif (curOffsets.length > 0 && nextOffset < curOffsets.head) { // 通过比较从 kafka 上该 partition 的最小 offset 和 zk 上保存的 offset,进行选择nextOffset = curOffsets.head}fromOffsets += (tp -> nextOffset)// println("@@@@@@ topic[" + topic + "] partition[" + i + "] offset[" + partitionOffset + "] @@@@@@")}}}if(fromOffsets.isEmpty){//没有存储过,第一次创建kafkaStream = KafkaUtils.createDirectStream[String, String](ssc,PreferConsistent,Subscribe[String, String](topics, kafkaParams))}else{kafkaStream = KafkaUtils.createDirectStream[String, String](ssc,PreferConsistent,Assign[String, String](fromOffsets.keys.toList, kafkaParams, fromOffsets))}kafkaStream}/*** 处理完成后将from offset写入zk* 注意是from offset 不是 until offset* 为了保证数据不丢失,重启时可能有一个betch数据重复提交* @param group* @param ZKservice* @param kafkaStream*/def updateZKOffsets(group:String, ZKservice:String, kafkaStream:InputDStream[ConsumerRecord[String, String]]): Unit = {val zkClient = new ZkClient(ZKservice)var offsetRanges = Array[OffsetRange]()kafkaStream.transform{ rdd =>//得到该 rdd 对应 kafka 的消息的 offsetoffsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRangesrdd}.map(msg => msg.value()).foreachRDD { rdd =>for (o <- offsetRanges) {//不同的topic对应不同的目录val topicDirs = new ZKGroupTopicDirs(group, o.topic)val zkPath = s"${topicDirs.consumerOffsetDir}/${o.partition}"//将该 partition 的 offset 保存到 zookeepernew ZkUtils(zkClient,new ZkConnection(ZKservice),false).updatePersistentPath(zkPath, o.fromOffset.toString)// println(s"@@@@@@ topic ${o.topic} partition ${o.partition} fromoffset ${o.fromOffset} untiloffset ${o.untilOffset} #######")}}}/*** 根据任意一台kafka机器ip获取 topich的partition和机器的对应关系* @param topic_name* @param broker* @return*/def getLeaders(topic_name:String,broker:String): Map[Int,String] ={val topic2 = List(topic_name)val req = new TopicMetadataRequest(topic2, 0)val getLeaderConsumer = new SimpleConsumer(broker, 9092, 10000, 10000, "OffsetLookup")val res = getLeaderConsumer.send(req)val topicMetaOption = res.topicsMetadata.headOption// 将结果转化为 partition -> leader 的映射关系val partitions = topicMetaOption match {case Some(tm) =>tm.partitionsMetadata.map(pm => (pm.partitionId, pm.leader.get.host)).toMap[Int, String]case None =>Map[Int, String]()}partitions}
测试代码如下:
var ssc = new StreamingContext(sc, Seconds(30))val servers = "broker1.test-bus-kafka.data.m.com:9092,broker2.test-bus-kafka.data.m.com:9092,broker3.test-bus-kafka.data.m.com:9092"val topic = "antispam.test.ly,antispam.test.ly2"val path = "/home/hadoopuser/ly/"val broker = "broker1.test-bus-kafka.data.m.com"val ZKservice = "zk1.test-inf-zk.data.m.com:2181,zk2.test-inf-zk.data.m.com:2181,zk3.test-inf-zk.data.m.com:2181"val group = "test_spark_streaming_group"val kafkaParams = Map[String, Object]("bootstrap.servers" -> servers,"key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"group.id" -> "test","auto.offset.reset" -> "earliest")val topics = topic.split(",").toSet// val topic = "antispam.test.ly2"val DStream = createDStream(ssc,topics,group,ZKservice,broker,kafkaParams)DStream.foreachRDD { recored =>recored.saveAsTextFile(path)recored.foreachPartition(message => {while (message.hasNext) {println(s"@^_^@ [" + message.next() + "] @^_^@")}})}updateZKOffsets(group,ZKservice,DStream)ssc.start()
调优
Spark streaming+Kafka的使用中,当数据量较小,很多时候默认配置和使用便能够满足情况,但是当数据量大的时候,就需要进行一定的调整和优化,而这种调整和优化本身也是不同的场景需要不同的配置。
- 3.1合理的批处理时间(batchDuration)
几乎所有的Spark Streaming调优文档都会提及批处理时间的调整,在StreamingContext初始化的时候,有一个参数便是批处理时间的设定。
如果这个值设置的过短,即个batchDuration所产生的Job并不能在这期间完成处理,那么就会造成数据不断堆积,最终导致Spark Streaming发生阻塞。
一般对于batchDuration的设置不会小于500ms,因为过小会导致SparkStreaming频繁的提交作业,对整个streaming造成额外的负担。在平时的应用中,根据不同的应用场景和硬件配置。
- 3.2合理的Kafka拉取量(maxRatePerPartition重要)
对于Spark Streaming消费kafka中数据的应用场景,这个配置是非常关键的。 配置参数为:
spark.streaming.kafka.maxRatePerPartition。
这个参数默认是没有上线的,即kafka当中有多少数据它就会直接全部拉出。而根据生产者写入Kafka的速率以及消费者本身处理数据的速度,同时这个参数需要结合上面的batchDuration,使得每个partition拉取在每个batchDuration期间拉取的数据能够顺利的处理完毕,做到尽可能高的吞吐量。
- 3.3缓存反复使用的Dstream(RDD)
Spark中的RDD和SparkStreaming中的Dstream,如果被反复的使用,最好利用cache(),将该数据流缓存起来,防止过度的调度资源造成的网络开销
- 3.4 设置合理的CPU资源数
CPU的core数量,每个executor可以占用一个或多个core,可以通过观察CPU的使用率变化来了解计算资源的使用情况,例如,很常见的一种浪费是一个executor占用了多个core,但是总的CPU使用率却不高.
- 3.5 设置合理的parallelism
在SparkStreaming+kafka的使用中,我们采用了Direct连接方式,前文阐述过Spark中的partition和Kafka中的Partition是一一对应的,我们一般默认设置为Kafka中Partition的数量。
- 3.6 使用高性能的算子
- 3.7 使用Kryo优化序列化性能
———————————————————————————————————————————————————————————-
———————————————————————————————————————————————————————————-
———————————————————————————————————————————————————————————-
- 使用Python的Spark Streaming来创建一个简单的单词计数例子
- 使用DStream————由众多小批次数据组成的离散数据流
模拟方法
To run this example:
使用Linux中bash终端将多个单词发送到我们计算机的本地端口(9999),请注意,在终端1中输入单词
Terminal 1: nc -lk 9999
运行Spark Streaming来接收这些文字,并对他们进行计数
Terminal 2: ./bin/spark-submit streaming_word_count.py localhost 9999
实施
打开两个终端,一个用于nc命令,另一个用于Spark Streaming程序
nc -lk 9999 从这个点开始,你在终端所输入的一切将被传送到9999端口。
在另一终端屏幕运行以下streaming_word_count.py脚本
# streaming_word_count.py 如下# 导入必要的类并创建一个本地的SparkContext和StreamingContexts,StreamingContexts是Spark Streaming的入口点from pyspark import SparkContextfrom pyspark.streaming import StreamingContext# 用两个工作线程创建Spark Context(注意:`local [2]`)sc = SparkContext("local[2]", "NetworkWordCount")# 创建1秒的本地StreamingContextwith批处理间隔,1是批间隔,每秒运行微批次。ssc = StreamingContext(sc, 1)# 创建DStream,将连接到连接到localhost:9999的输入行的流,lines = ssc.socketTextStream("localhost", 9999)# 统计单词words = lines.flatMap(lambda line: line.split(" "))pairs = words.map(lambda word: (word, 1))wordCounts = pairs.reduceByKey(lambda x, y: x + y)# 将此DStream中生成的每个RDD的前十个元素打印到控制台wordCounts.pprint()# 启动Spark Streaming开始计算,然后等待终止命令来停止运行(CTRL+C),如果没有等到停止命令,Spark Streaming程序将继续运行。ssc.start()# 等待计算结束ssc.awaitTermination()
全局实施
from pyspark import SparkContextfrom pyspark.streaming import StreamingContextsc = SparkContext("local[2]", "StatefulNetworkWordCount")ssc = StreamingContext(sc, 1)# 给Saprk Streaming配置了一个检查点(checkpoint)ssc.checkpoint("checkpoint")def updateFunc(new_values, last_sum):return sum(new_values) + (last_sum or 0)lines = ssc.socketTextStream("localhost", 9999)running_counts = lines.flatMap(lambda line: line.split(" "))\.map(lambda word: (word, 1))\.updateStateByKey(updateFunc)running_counts.pprint()ssc.start()ssc.awaitTermination()
第五:结构化流
利用DataFrame引入结构化流,简化代码。
# Structured Streaming Word Count Example# Original Source: https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html## To run this example:# Terminal 1: nc -lk 9999# Terminal 2: ./bin/spark-submit structured_streaming_word_count.py localhost 9999# Note, type words into Terminal 1## Import the necessary classes and create a local SparkSessionfrom pyspark.sql import SparkSessionfrom pyspark.sql.functions import explodefrom pyspark.sql.functions import splitspark = SparkSession \.builder \.appName("StructuredNetworkWordCount") \.getOrCreate()# Create DataFrame representing the stream of input lines from connection to localhost:9999lines = spark\.readStream\.format('socket')\.option('host', 'localhost')\.option('port', 9999)\.load()# Split the lines into wordswords = lines.select(explode(split(lines.value, ' ')).alias('word'))# Generate running word countwordCounts = words.groupBy('word').count()# Start running the query that prints the running counts to the consolequery = wordCounts\.writeStream\.outputMode('complete')\.format('console')\.start()# Await Spark Streaming terminationquery.awaitTermination()
第六:利用PySpark Streaming读取和分析数据
Step 1. Starting Zookeeper, creating the topic, starting Apache Kafka broker, starting the console producer.
kafka$ bin/zookeeper-server-start.sh config/zookeeper.propertieskafka$ bin/kafka-server-start.sh config/server.propertieskafka$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic pysparkBookTopickafka$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic pysparkBookTopic
Step 2. Starting PySpark with spark-streaming-kafka package.
$ pyspark --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.0.0
Step 3. Creating sum of each row of numbers.
def stringToNumberSum(data):removedSpaceData = data.strip()if removedSpaceData == '' :return(None)splittedData = removedSpaceData.split(' ')numData = [float(x) for x in splittedData]sumOfData = sum(numData)return (sumOfData)dataInString = '10 10 20 'stringToNumberSum(dataInString)
Step 4. Reading data from Kafka and getting sum of each row.
from pyspark.streaming.kafka import KafkaUtilsfrom pyspark.streaming import StreamingContextbookStreamContext = StreamingContext(sc, 10)bookKafkaStream = KafkaUtils.createStream(ssc = bookStreamContext,zkQuorum = 'localhost:2185',groupId = 'pysparkBookGroup',topics = {'pysparkBookTopic':1})sumedData = bookKafkaStream.map( lambda data : stringToNumberSum(data[1]))sumedData.pprint()bookStreamContext.start()bookStreamContext.awaitTerminationOrTimeout(30)
第七:Spark Streaming + Kafka Integration Guide (Kafka broker version 0.8.2.1 or higher)
方法1:基于接收者的方法
对于Python应用程序,在部署应用程序时,必须添加上面的库及其依赖关系。 请参阅下面的部署小节。
(1)导入KafkaUtils并创建一个输入DStream,如下所示:
from pyspark.streaming.kafka import KafkaUtilskafkaStream = KafkaUtils.createStream(streamingContext, \[ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
- 默认情况下,Python API会将Kafka数据解码为UTF8编码的字符串。 您可以指定自定义解码函数,将Kafka记录中的字节数组解码为任意的数据类型。
- Kafka中的主题分区与Spark Streaming中生成的RDD的分区不相关。 因此,增加KafkaUtils.createStream()中主题特定分区的数量只会增加单个接收者使用哪些主题的线程数,在处理数据时不会增加Spark的并行性。
- 多个Kafka输入DStreams可以创建不同的组和主题,用于使用多个接收器并行接收数据。如果已经使用HDFS等复制文件系统启用了写入日志,则接收到的数据已经被复制到日志中。
(2)部署:与任何Spark应用程序一样,spark-submit用于启动您的应用程序。
对于缺乏SBT / Maven项目管理的Python应用程序,可以使用—packages直接将spark-streaming-kafka-0-8_2.11及其依赖关系添加到spark-submit
./bin/spark-submit --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.2.1 ...
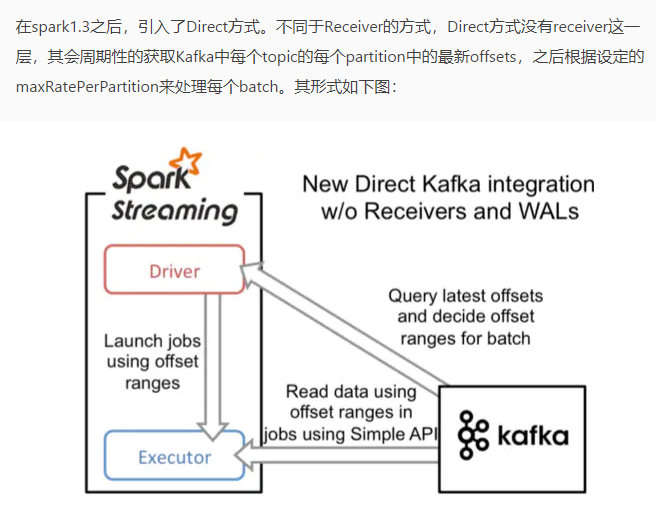
方法2:直接方法(无接收者)
在Spark 1.3中引入了这种新的无接收器“直接”方法,以确保更强大的端到端保证。 这种方法不是使用接收器来接收数据,而是定期查询Kafka在每个主题+分区中的最新偏移量,并相应地定义要在每个批次中处理的偏移量范围。 当处理数据的作业启动时,Kafka简单的客户API用于读取Kafka中定义的偏移范围(类似于从文件系统读取文件)。
与基于接收机的方法(即方法1)相比,这种方法具有以下优点。
- 简化的并行性:不需要创建多个输入Kafka流并将其合并。使用directStream,Spark Streaming将创建与使用Kafka分区一样多的RDD分区,这些分区将全部从Kafka并行读取数据。所以在Kafka和RDD分区之间有一对一的映射关系,这更容易理解和调整。
- 效率:在第一种方法中实现零数据丢失需要将数据存储在预写日志中,这会进一步复制数据。这实际上是效率低下的,因为数据被有效地复制了两次 - 一次是由卡夫卡(Kafka),另一次是由预先写入日志(Write Ahead Log)复制。这个第二种方法消除了这个问题,因为没有接收器,因此不需要预先写入日志。只要你有足够的卡夫卡保留,消息可以从卡夫卡恢复。
- 完全一次的语义:第一种方法使用Kafka的高级API来存储Zookeeper中消耗的偏移量。传统上这是从卡夫卡消费数据的方式。虽然这种方法(结合提前写入日志)可以确保零数据丢失(即至少一次语义),但是在某些失败情况下,有一些记录可能会消耗两次。发生这种情况是因为Spark Streaming可靠接收到的数据与Zookeeper跟踪的偏移之间的不一致。因此,在第二种方法中,我们使用不使用Zookeeper的简单Kafka API。在其检查点内,Spark Streaming跟踪偏移量。这消除了Spark Streaming和Zookeeper / Kafka之间的不一致,因此Spark Streaming每次记录都会在发生故障时有效地接收一次。为了实现输出结果的一次语义,将数据保存到外部数据存储区的输出操作必须是幂等的,或者是保存结果和偏移量的原子事务(请参阅主程序中输出操作的语义指导进一步的信息)。
请注意,这种方法的一个缺点是它不会更新Zookeeper中的偏移量,因此基于Zookeeper的Kafka监控工具将不会显示进度。但是,您可以在每个批次中访问由此方法处理的偏移量,并自己更新Zookeeper(请参见下文)。
接下来,我们将讨论如何在流式应用程序中使用这种方法。
(1)导入KafkaUtils并创建一个输入DStream,如下所示:
from pyspark.streaming.kafka import KafkaUtilsdirectKafkaStream = KafkaUtils.createDirectStream(ssc, [topic], {"metadata.broker.list": brokers})
- 您也可以传递一个messageHandler到createDirectStream来访问包含关于当前消息的元数据的KafkaMessageAndMetadata并将其转换为任何需要的类型。 默认情况下,Python API会将Kafka数据解码为UTF8编码的字符串。 您可以指定自定义解码函数,将Kafka记录中的字节数组解码为任意的数据类型。 查看API文档和示例。
- 在Kafka参数中,您必须指定metadata.broker.list或bootstrap.servers。 默认情况下,它将开始消耗每个Kafka分区的最新偏移量。 如果您将Kafka参数中的配置auto.offset.reset设置为最小,那么它将从最小的偏移量开始消耗。
- 你也可以使用KafkaUtils.createDirectStream的其他变体开始消耗任何偏移量。 此外,如果您想访问每批中消耗的卡夫卡补偿,您可以执行以下操作。
offsetRanges = []def storeOffsetRanges(rdd):global offsetRangesoffsetRanges = rdd.offsetRanges()return rdddef printOffsetRanges(rdd):for o in offsetRanges:print "%s %s %s %s" % (o.topic, o.partition, o.fromOffset, o.untilOffset)directKafkaStream \.transform(storeOffsetRanges) \.foreachRDD(printOffsetRanges)
- 如果您希望基于Zookeeper的Kafka监视工具显示流应用程序的进度,您可以使用它自己更新Zookeeper。
- 请注意,HasOffsetRanges的类型转换只会在directKafkaStream中调用的第一个方法中完成,而不是在方法链之后。您可以使用transform()而不是foreachRDD()作为第一个方法调用,以访问偏移量,然后调用更多的Spark方法。但是,请注意,RDD分区与Kafka分区之间的一对一映射在任何混洗或重新分区的方法(例如, reduceByKey()或window()。
- 另外要注意的是,由于这种方法不使用接收器,与标准接收器相关的(即spark.streaming.receiver。形式的配置)将不适用于由此方法创建的输入DStream(将应用于其他输入DStreams)。相反,使用配置spark.streaming.kafka。。最重要的是spark.streaming.kafka.maxRatePerPartition,它是每个Kafka分区将被这个直接API读取的最大速率(每秒消息数)。
(2)部署:与任何Spark应用程序一样,spark-submit用于启动您的应用程序。
对于缺乏SBT / Maven项目管理的Python应用程序,可以使用—packages直接将spark-streaming-kafka-0-8_2.11及其依赖关系添加到spark-submit
./bin/spark-submit --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.2.1 ...
第八:Spark Streaming + Flume Integration Guide (Kafka broker version 0.8.2.1 or higher)
Apache Flume是一个分布式的,可靠的,可用的服务,用于高效地收集,聚合和移动大量的日志数据。 在这里我们解释如何配置Flume和Spark Streaming来接收来自Flume的数据。 有两种方法。
方法1:Flume-style Push-based Approach
Flume旨在在Flume代理之间推送数据。 在这种方法中,Spark Streaming基本上设置了一个接收器,作为Flume的一个Avro代理,Flume可以将这个接收器推送到这个接收器。
配置步骤:
General Requirements
选择群集中的一台机器
- 当启动Flume + Spark Streaming应用程序时,其中一名Spark工作人员必须在该机器上运行。
- Flume可以配置为将数据推送到该机器上的端口。
由于推送模式,流媒体应用程序需要启动,接收机已安排并在所选端口上侦听,Flume才能够推送数据。
Configuring Flume
配置Flume代理通过在配置文件中包含以下内容将数据发送到Avro接收器。
agent.sinks = avroSinkagent.sinks.avroSink.type = avroagent.sinks.avroSink.channel = memoryChannelagent.sinks.avroSink.hostname = <chosen machine's hostname>agent.sinks.avroSink.port = <chosen port on the machine>
Configuring Spark Streaming Application(以Python为例)
from pyspark.streaming.flume import FlumeUtilsflumeStream = FlumeUtils.createStream(streamingContext, [chosen machine's hostname], [chosen port])
默认情况下,Python API会将Flume事件主体解码为UTF8编码的字符串。 您可以指定自定义解码函数,将Flume事件中的正文字节数组解码为任意任意数据类型。 查看API文档和示例。
请注意,主机名应该与群集中的资源管理器(Mesos,YARN或Spark Standalone)所使用的相同,以便资源分配可以匹配名称,并在正确的机器中启动接收器。
对于缺乏SBT / Maven项目管理的Python应用程序,spark-streaming-flume_2.11及其依赖项可直接添加到使用—packages的spark-submit
./bin/spark-submit --packages org.apache.spark:spark-streaming-flume_2.11:2.2.1 ...
方法2:Pull-based Approach using a Custom Sink
Flume不是直接将数据直接推送到Spark Streaming,而是运行一个自定义的Flume接收器,它允许进行以下操作。
Flume将数据推入接收器,并且数据保持缓冲。
Spark Streaming使用可靠的Flume接收器和事务来从接收器中提取数据。 只有在Spark Streaming接收和复制数据后,事务才能成功。
这确保了比以前的方法更强大的可靠性和容错保证。 但是,这需要配置Flume运行自定义接收器。
配置步骤:
General Requirements
选择一台将在Flume代理中运行定制接收器的机器。 Flume管道的其余部分配置为向该代理发送数据。 Spark群集中的机器应该可以访问运行定制接收器的选定机器。
Configuring Flume
Configuring Spark Streaming Application
from pyspark.streaming.flume import FlumeUtilsaddresses = [([sink machine hostname 1], [sink port 1]), ([sink machine hostname 2], [sink port 2])]flumeStream = FlumeUtils.createPollingStream(streamingContext, addresses)

若有收获,就点个赞吧
0 人点赞
