1 概述
在开发完Spark作业之后,就该为作业配置合适的资源了。Spark的资源参数,基本都可以在spark-submit命令中作为参数设置。很多Spark初学者,通常不知道该设置哪些必要的参数,以及如何设置这些参数,最后就只能胡乱设置,甚至压根儿不设置。资源参数设置的不合理,可能会导致没有充分利用集群资源,作业运行会极其缓慢;或者设置的资源过大,队列没有足够的资源来提供,进而导致各种异常。总之,无论是哪种情况,都会导致Spark作业的运行效率低下,甚至根本无法运行。因此我们必须对Spark作业的资源使用原理有一个清晰的认识,并知道在Spark作业运行过程中,有哪些资源参数是可以设置的,以及如何设置合适的参数值。
2 Spark作业基本原理
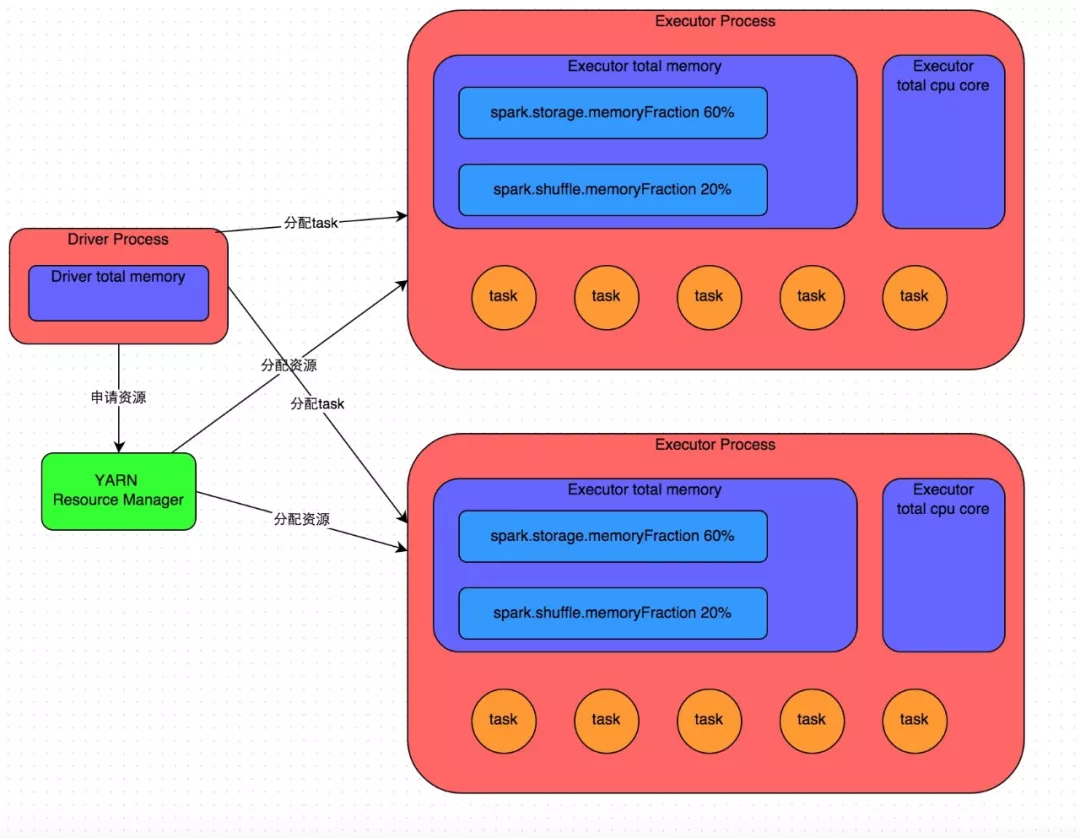
我们使用spark-submit提交一个Spark作业之后,这个作业就会启动一个对应的Driver进程。根据你使用的部署模式(deploy-mode)不同,Driver进程可能在本地启动,也可能在集群中某个工作节点上启动。Driver进程本身会根据我们设置的参数,占有一定数量的内存和CPU core。而Driver进程要做的第一件事情,就是向集群管理器(可以是Spark YARN作为资源管理集群)申请运行Spark作业需要使用的资源,这里的资源指的就是Executor进程。YARN集群管理器会根据我们为Spark作业设置的资源参数,在各个工作节点上,启动一定数量的Executor进程,每个Executor进程都占有一定数量的内存和CPU core。
在申请到了作业执行所需的资源之后,Driver进程就会开始调度和执行我们编写的作业代码了。Driver进程会将我们编写的Spark作业代码分拆为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批task,然后将这些task分配到各个Executor进程中执行。task是最小的计算单元,负责执行一模一样的计算逻辑(也就是我们自己编写的某个代码片段),只是每个task处理的数据不同而已。一个stage的所有task都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。下一个stage的task的输入数据就是上一个stage输出的中间结果。如此循环往复,直到将我们自己编写的代码逻辑全部执行完,并且计算完所有的数据,得到我们想要的结果为止。
Spark是根据shuffle类算子来进行stage的划分。如果我们的代码中执行了某个shuffle类算子(比如reduceByKey、join等),那么就会在该算子处,划分出一个stage界限来。可以大致理解为,shuffle算子执行之前的代码会被划分为一个stage,shuffle算子执行以及之后的代码会被划分为下一个stage。因此一个stage刚开始执行的时候,它的每个task可能都会从上一个stage的task所在的节点,去通过网络传输拉取需要自己处理的所有key,然后对拉取到的所有相同的key使用我们自己编写的算子函数执行聚合操作(比如reduceByKey()算子接收的函数),这个过程就是shuffle。
当我们在代码中执行了cache/persist等持久化操作时,根据我们选择的持久化级别的不同,每个task计算出来的数据也会保存到Executor进程的内存或者所在节点的磁盘文件中。
因此Executor的内存主要分为三块:
第一块是让
task执行我们自己编写的代码时使用,默认是占Executor总内存的20%;
第二块是让task通过shuffle过程拉取了上一个stage的task的输出后,进行聚合等操作时使用,默认也是占>Executor总内存的20%;
第三块是让RDD持久化时使用,默认占Executor总内存的60%。
task的执行速度是跟每个Executor进程的CPU core数量有直接关系的。一个CPU core同一时间只能执行一个线程。而每个Executor进程上分配到的多个task,都是以每个task一条线程的方式,多线程并发运行的。如果CPU core数量比较充足,而且分配到的task数量比较合理,那么通常来说,可以比较快速和高效地执行完这些task线程。
以上就是Spark作业的基本运行原理的说明,大家可以结合上图来理解。理解作业基本原理,是我们进行资源参数调优的基本前提。
3 资源参数调优
了解完了Spark作业运行的基本原理之后,对资源相关的参数就容易理解了。所谓的Spark资源参数调优,其实主要就是对Spark运行过程中各个使用资源的地方,通过调节各种参数,来优化资源使用的效率,从而提升Spark作业的执行性能。以下参数就是Spark中主要的资源参数,每个参数都对应着作业运行原理中的某个部分,我们同时也给出了一个调优的参考值。
3.1 num-executors
参数说明:
该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
调优建议:
每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太少或太多的Executor进程都不好。设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。
3.2 executor-memory
参数说明:
该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
调优建议:
每个Executor进程的内存设置4G~8G较为合适。但是这只是一个参考值,具体的设置还是得根据不同部门的资源队列来定。可以看看自己团队的资源队列的最大内存限制是多少,num-executors*executor-memory,是不能超过队列的最大内存量的。此外,如果你是跟团队里其他人共享这个资源队列,那么申请的内存量最好不要超过资源队列最大总内存的 1/3~1/2,避免你自己的Spark作业占用了队列所有的资源,导致别的同学的作业无法运行。
3.3 executor-cores
参数说明:
该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
调优建议:
Executor的CPU core数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,再依据设置的Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同学的作业运行。
3.4 driver-memory
参数说明:
该参数用于设置Driver进程的内存。
调优建议:
Driver的内存通常来说不设置,或者设置1G左右应该就够了。唯一需要注意的一点是,如果需要使用collect算子将RDD的数据全部拉取到Driver上进行处理,那么必须确保Driver的内存足够大,否则会出现OOM内存溢出的问题。
3.5 spark.default.parallelism
参数说明:
该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
调优建议:
Spark作业的默认task数量为500~1000个较为合适。很多同学常犯的一个错误就是不去设置这个参数,那么此时就会导致Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。通常来说,Spark默认设置的数量是偏少的(比如就几十个task),如果task数量偏少的话,就会导致你前面设置好的Executor的参数都前功尽弃。试想一下,无论你的Executor进程有多少个,内存和CPU有多大,但是task只有1个或者10个,那么90%的Executor进程可能根本就没有task执行,也就是白白浪费了资源!因此Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍较为合适,比如Executor的总CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
3.6 spark.storage.memoryFraction
参数说明:
该参数用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6。也就是说,默认Executor 60%的内存,可以用来保存持久化的RDD数据。根据你选择的不同的持久化策略,如果内存不够时,可能数据就不会持久化,或者数据会写入磁盘。
调优建议:
如果Spark作业中,有较多的RDD持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。避免内存不够缓存所有的数据,导致数据只能写入磁盘中,降低了性能。但是如果Spark作业中的shuffle类操作比较多,而持久化操作比较少,那么这个参数的值适当降低一些比较合适。此外,如果发现作业由于频繁的gc导致运行缓慢(通过spark web ui可以观察到作业的gc耗时),意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
3.7 spark.shuffle.memoryFraction
参数说明:
该参数用于设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2。也就是说,Executor默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。
调优建议:
如果Spark作业中的RDD持久化操作较少,shuffle操作较多时,建议降低持久化操作的内存占比,提高shuffle操作的内存占比比例,避免shuffle过程中数据过多时内存不够用,必须溢写到磁盘上,降低了性能。此外,如果发现作业由于频繁的gc导致运行缓慢,意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
3.8 参数调优总结
资源参数的调优,没有一个固定的值,需要同学们根据自己的实际情况(包括Spark作业中的shuffle操作数量、RDD持久化操作数量以及spark web ui中显示的作业gc情况),同时参考本篇文章中给出的原理以及调优建议,合理地设置上述参数。
3.9 参数调优实例
./bin/spark-submit \--master yarn-cluster \--num-executors 100 \--executor-memory 6G \--executor-cores 4 \--driver-memory 1G \--conf spark.default.parallelism=1000 \--conf spark.storage.memoryFraction=0.5 \--conf spark.shuffle.memoryFraction=0.3 \
更多关于Spark性能调优的具体内容请参考如下文章:
开发调优: http://blog.csdn.net/u012102306/article/details/51322209
资源调优:http://blog.csdn.net/u012102306/article/details/51637366
数据倾斜调优:http://blog.csdn.net/u012102306/article/details/51556450
shuffle调优:http://blog.csdn.net/u012102306/article/details/51637732
4 Spark SQL
下面内容来自https://mp.weixin.qq.com/s/DAxI4gVsZjjSxHZ1-Pwkjw
Spark SQL是Apache Spark最广泛使用的一个组件,它提供了非常友好的接口来分布式处理结构化数据,在很多应用领域都有成功的生产实践,但是在超大规模集群和数据集上,Spark SQL仍然遇到不少易用性和可扩展性的挑战。本文首先讨论Spark SQL在大规模数据集上遇到的挑战,然后介绍自适应执行的背景和基本架构,以及自适应执行如何应对Spark SQL这些问题。
4.1 挑战1:关于shuffle partition数
在Spark SQL中, shufflepartition数可以通过参数spark.sql.shuffle.partition来设置,默认值是200。这个参数决定了SQL作业每个reduce阶段任务数量,对整个查询性能有很大影响。假设一个查询运行前申请了E个Executor,每个Executor包含C个core(并发执行线程数),那么该作业在运行时可以并行执行的任务数就等于E x C个,或者说该作业的并发数是E x C。假设shuffle partition个数为P,除了map stage的任务数和原始数据的文件数量以及大小相关,后续的每个reduce stage的任务数都是P。由于Spark作业调度是抢占式的,E x C个并发任务执行单元会抢占执行P个任务,“能者多劳”,直至所有任务完成,则进入到下一个Stage。但这个过程中,如果有任务因为处理数据量过大(例如:数据倾斜导致大量数据被划分到同一个reducer partition)或者其它原因造成该任务执行时间过长,一方面会导致整个stage执行时间变长,另一方面E x C个并发执行单元大部分可能都处于空闲等待状态,集群资源整体利用率急剧下降。
那么spark.sql.shuffle.partition参数究竟是多少比较合适?如果设置过小,分配给每一个reduce任务处理的数据量就越多,在内存大小有限的情况下,不得不溢写(spill)到计算节点本地磁盘上。Spill会导致额外的磁盘读写,影响整个SQL查询的性能,更差的情况还可能导致严重的GC问题甚至是OOM。相反,如果shuffle partition设置过大。第一,每一个reduce任务处理的数据量很小并且很快结束,进而导致Spark任务调度负担变大。第二,每一个mapper任务必须把自己的shuffle输出数据分成P个hash bucket,即确定数据属于哪一个reduce partition,当shuffle partition数量太多时,hash bucket里数据量会很小,在作业并发数很大时,reduce任务shuffle拉取数据会造成一定程度的随机小数据读操作,当使用机械硬盘作为shuffle数据临时存取的时候性能下降会更加明显。最后,当最后一个stage保存数据时会写出P个文件,也可能会造成HDFS文件系统中大量的小文件。
从上,shuffle partition的设置既不能太小也不能太大。为了达到最佳的性能,往往需要经多次试验才能确定某个SQL查询最佳的shuffle partition值。然而在生产环境中,往往SQL``以定时作业的方式处理不同时间段的数据,数据量大小可能变化很大,我们也无法为每一个SQL查询去做耗时的人工调优,这也意味这些SQL`作业很难以最佳的性能方式运行。
Shuffle partition的另外一个问题是,同一个shuffle partition数设置将应用到所有的stage。Spark在执行一个SQL作业时,会划分成多个stage。通常情况下,每个stage的数据分布和大小可能都不太一样,全局的shuffle partition设置最多只能对某个或者某些stage最优,没有办法做到全局所有的stage设置最优。
这一系列关于shufflepartition的性能和易用性挑战,促使我们思考新的方法:我们能否根据运行时获取的shuffle数据量信息,例如数据块大小,记录行数等等,自动为每一个stage设置合适的shuffle partition值?
4.2 挑战2:Spark SQL最佳执行计划
Spark SQL在执行SQL之前,会将SQL或者Dataset程序解析成逻辑计划,然后经历一系列的优化,最后确定一个可执行的物理计划。最终选择的物理计划的不同对性能有很大的影响。如何选择最佳的执行计划,这便是Spark SQL的Catalyst优化器的核心工作。Catalyst早期主要是基于规则的优化器(RBO),在Spark 2.2中又加入了基于代价的优化(CBO)。目前执行计划的确定是在计划阶段,一旦确认以后便不再改变。然而在运行期间,当我们获取到更多运行时信息时,我们将有可能得到一个更佳的执行计划。
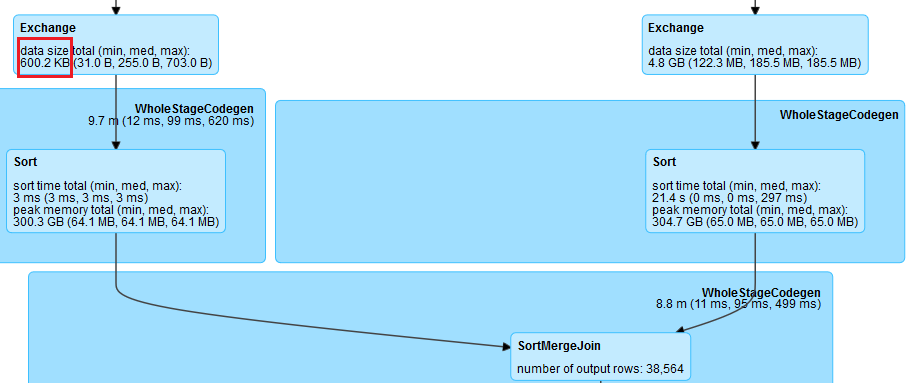
以join操作为例,在Spark中最常见的策略是BroadcastHashJoin和SortMergeJoin。BroadcastHashJoin属于map side join,其原理是当其中一张表存储空间大小小于broadcast阈值时,Spark选择将这张小表广播到每一个Executor上,然后在map阶段,每一个mapper读取大表的一个分片,并且和整张小表进行join,整个过程中避免了把大表的数据在集群中进行shuffle。而SortMergeJoin在map阶段2张数据表都按相同的分区方式进行shuffle写,reduce阶段每个reducer将两张表属于对应partition的数据拉取到同一个任务中做join。RBO根据数据的大小,尽可能把join操作优化成BroadcastHashJoin。Spark中使用参数spark.sql.autoBroadcastJoinThreshold来控制选择BroadcastHashJoin的阈值,默认是10MB。然而对于复杂的SQL查询,它可能使用中间结果来作为join的输入,在计划阶段,Spark并不能精确地知道join中两表的大小或者会错误地估计它们的大小,以致于错失了使用BroadcastHashJoin策略来优化join执行的机会。但是在运行时,通过从shuffle写得到的信息,我们可以动态地选用BroadcastHashJoin。以下是一个例子,join一边的输入大小只有600K,但Spark仍然规划成SortMergeJoin。
4.3 挑战3:数据倾斜
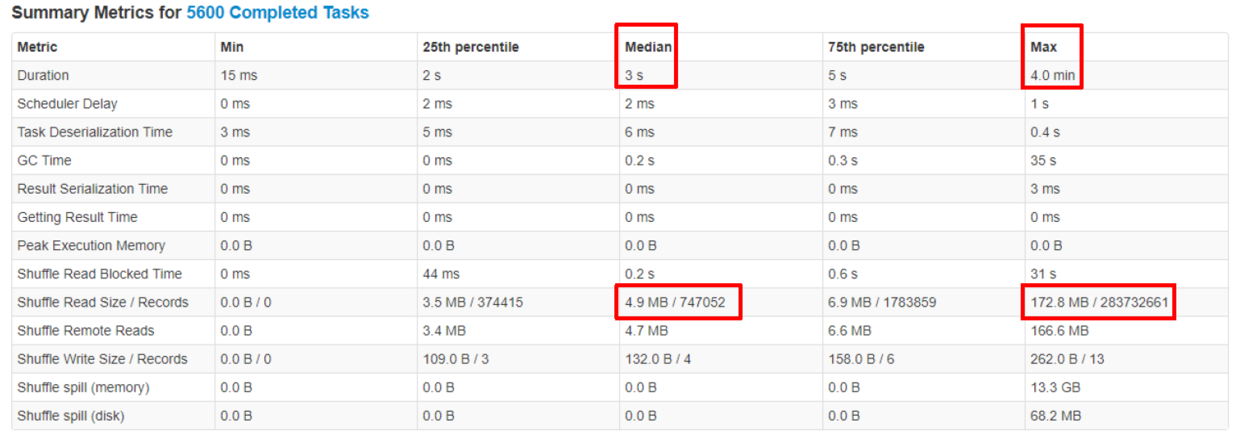
数据倾斜是常见的导致Spark SQL性能变差的问题。数据倾斜是指某一个partition的数据量远远大于其它partition的数据,导致个别任务的运行时间远远大于其它任务,因此拖累了整个SQL的运行时间。在实际SQL作业中,数据倾斜很常见,join key对应的hash bucket总是会出现记录数不太平均的情况,在极端情况下,相同join key对应的记录数特别多,大量的数据必然被分到同一个partition因而造成数据严重倾斜。如图2,可以看到大部分任务3秒左右就完成了,而最慢的任务却花了4分钟,它处理的数据量却是其它任务的若干倍。
目前,处理join时数据倾斜的一些常见手段有:
(1)增加shuffle partition数量,期望原本分在同一个partition中的数据可以被分散到多个partition中,但是对于同key的数据没有作用。
(2)调大BroadcastHashJoin的阈值,在某些场景下可以把SortMergeJoin转化成BroadcastHashJoin而避免shuffle产生的数据倾斜。
(3)手动过滤倾斜的key,并且对这些数据加入随机的前缀,在另一张表中这些key对应的数据也相应的膨胀处理,然后再做join。
综上,这些手段都有各自的局限性并且涉及很多的人为处理。基于此,我们思考了第三个问题:Spark能否在运行时自动地处理join中的数据倾斜?

若有收获,就点个赞吧
0 人点赞
