基于PySpark的模型开发
pyspark官方文档http://spark.apache.org/docs/latest/api/python/index.html
会员流失预测模型
通用模型开发流程

模型开发流程
需求沟通与问题确立
定义流失口径:比如,流失客户定义为最近一次购买日期距今的时间大于平均购买间期加3倍的标准差;非流失客户定义为波动比较小,购买频次比较稳定的客户 选定时间窗口:比如,选择每个会员最近一次购买时间回溯一年的历史订单情况 推测可能的影响因素:头脑风暴,特征初筛,从业务角度出发,尽可能多的筛选出可能的影响因素作为原始特征集
数据整合与特征工程
1)把来自不同表的数据整合到一张宽表中,一般是通过SQL处理
2)数据预处理和特征工程
预处理与特征工程
模型开发与效果评估
1)样本数据先按照正负例分别随机拆分,然后分别组成训练和测试集,保证训练集和测试集之间没有重复数据,训练集和测试集正负例比例基本一致,最终两个数据集中正负例比例均接近1:1
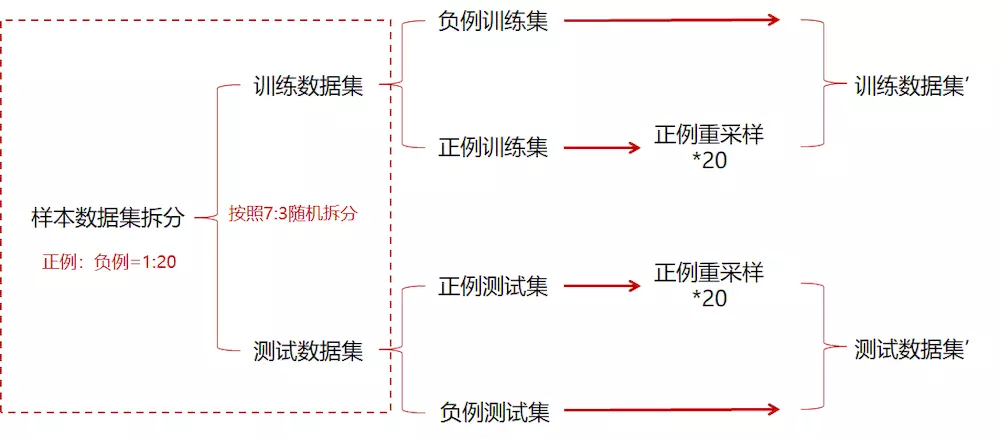
数据集拆分过程
2)对于建立模型而言并非特征越多越好,建模的目标是使用尽量简单的模型去实现尽量好的效果。减少一些价值小贡献小的特征有利于在表现效果不变或降低很小的前提下,找到最简单的模型。
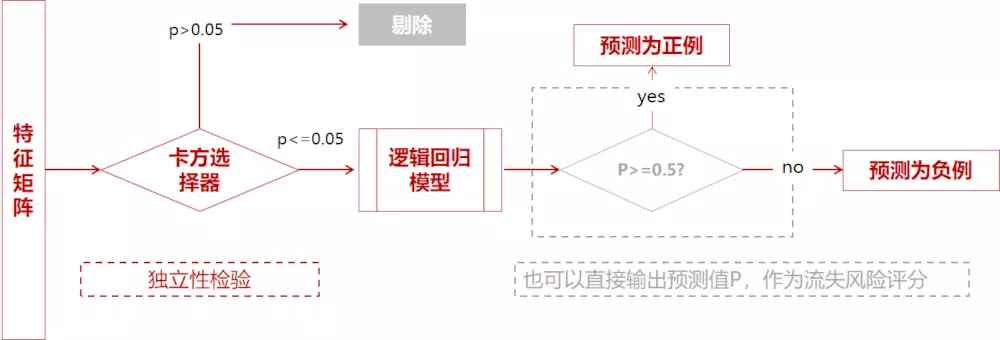
特征选择与模型建立
使用卡方检验对特征与因变量进行独立性检验,如果独立性高就表示两者没太大关系,特征可以舍弃;如果独立性小,两者相关性高,则说明该特征会对应变量产生比较大的影响,应当选择。
3)CV或者TVS将数据划分为训练数据和测试数据,对于每个(训练,测试)对,遍历一组参数。用每一组参数来拟合,得到训练后的模型,再用AUC和ACC评估模型表现,选择性能表现最优模型对应参数表。
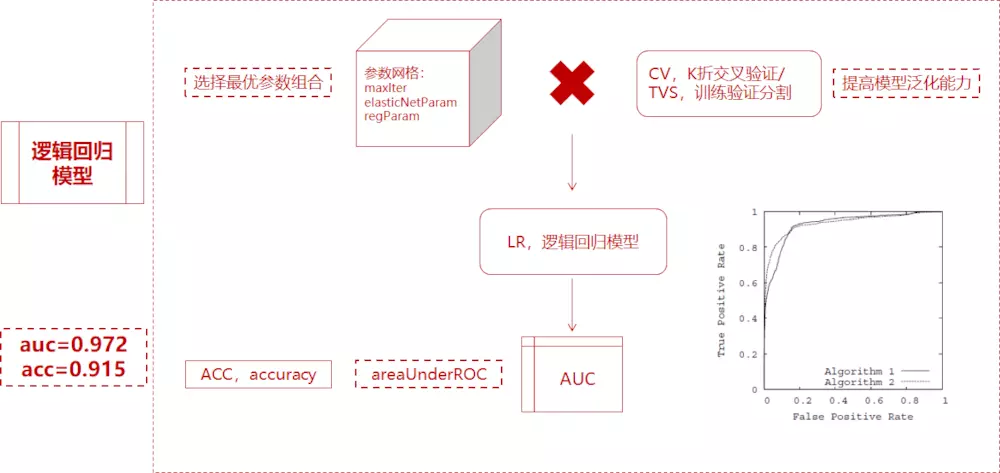
超参调整与模型评估
模型应用与迭代优化
应用模型预测结果/评分进行精细化营销或者挽回,同时不断根据实际情况优化模型,再用优化后的模型重新预测,形成一个迭代优化的闭环。
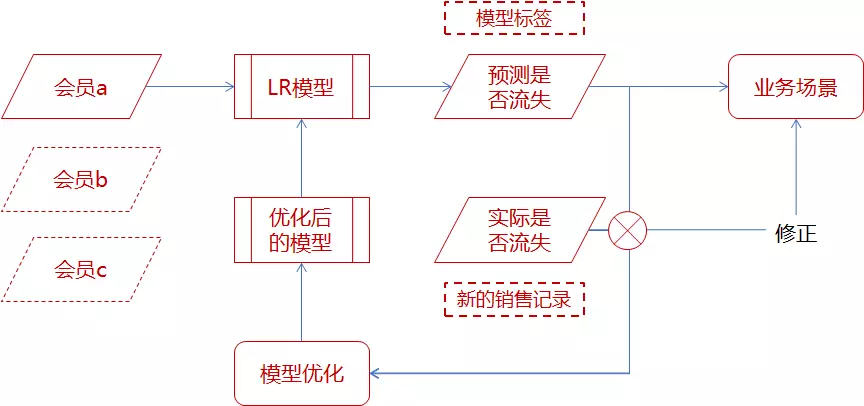
模型迭代流程
模型代码
附1:本地开发的Python代码
# coding: utf-8from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType, StructField, StringType, DoubleTypeimport pyspark.sql.functions as fnfrom pyspark.sql.functions import regexp_extract,col # regexp_extract是pyspark正则表达式模块from pyspark.ml.feature import Bucketizer, QuantileDiscretizer, OneHotEncoder, StringIndexer, IndexToString, VectorIndexer, VectorAssemblerfrom pyspark.ml.feature import ChiSqSelector, StandardScalerfrom pyspark.ml import Pipeline, PipelineModelfrom pyspark.ml.classification import RandomForestClassifier, LogisticRegression,LogisticRegressionModelfrom pyspark.ml.evaluation import BinaryClassificationEvaluatorfrom pyspark.ml.tuning import CrossValidator, ParamGridBuilder, TrainValidationSplitif __name__ == '__main__':# 创建spark连接spark = SparkSession.builder.appName("usrLostModel").master("local[*]").getOrCreate()# 定义数据格式schema = StructType([StructField('label', DoubleType(), True),StructField('erp_code', StringType(), True),StructField('gender', StringType(), True),StructField('is_nt_concn_webchat', StringType(), True),StructField('erp_corp', StringType(), True),StructField('is_nm', DoubleType(), True),StructField('is_tel', DoubleType(), True),StructField('is_birth_dt', DoubleType(), True),StructField('is_cert_num', DoubleType(), True),StructField('is_handl_org', DoubleType(), True),StructField('is_addr', DoubleType(), True),StructField('year_count_erp', DoubleType(), True),StructField('haft_year_count_erp', DoubleType(), True),StructField('three_month_count_erp', DoubleType(), True),StructField('one_month_count_erp', DoubleType(), True),StructField('year_avg_count_erp', DoubleType(), True),StructField('haftyear_avg_count_erp', DoubleType(), True),StructField('threemonth_avg_count_erp', DoubleType(), True),StructField('onemonth_avg_count_erp', DoubleType(), True),StructField('year_recv_amt_sum', DoubleType(), True),StructField('year_discnt_amt_sum', DoubleType(), True),StructField('haftyear_recv_amt_sum', DoubleType(), True),StructField('haftyear_discnt_amt_sum', DoubleType(), True),StructField('threemonth_recv_amt_sum', DoubleType(), True),StructField('threemonth_discnt_amt_sum', DoubleType(), True),StructField('onemonth_recv_amt_sum', DoubleType(), True),StructField('onemonth_discnt_amt_sum', DoubleType(), True),StructField('is_prdc_mfr_pianhao', DoubleType(), True),StructField('sell_tm_erp', StringType(), True),StructField('shopgui_erp', StringType(), True),StructField('duration_erp', DoubleType(), True),StructField('is_shopgui_erp', DoubleType(), True),StructField('lvl_shopgui_erp', DoubleType(), True)])# 导入数据为dataframe格式,header=true表示第一行为字段名,schema定义字段类型,schema=None表示由系统自动识别data = spark.read.csv("./data/data.csv",header=True,schema=schema)vdata = spark.read.csv("./data/vdata.csv",header=True,schema=schema)# data.show(5)# vdata.groupBy("gender").count().show()# vdata.groupBy("is_nt_concn_webchat").count().show()# vdata.groupBy("erp_corp").count().show()def featureEngineering(data):# 用0填补is_nt_concn_webchat缺失值data0 = data.na.fill({'is_nt_concn_webchat': '0'})# data.groupBy("is_nt_concn_webchat").count().show()# 检查每一列中缺失数据的百分比# data.agg(*[(1-(fn.count(c)/fn.count('*'))).alias(c+'_null') for c in data.columns]).show()# data.agg(*[(fn.count('*')-fn.count(c)).alias(c+'_null') for c in data.columns]).show()# 用0.0填补double类型数据的缺失值data0 = data0.na.fill({'year_discnt_amt_sum': 0.0})data0 = data0.na.fill({'haftyear_recv_amt_sum': 0.0})data0 = data0.na.fill({'haftyear_discnt_amt_sum': 0.0})data0 = data0.na.fill({'threemonth_recv_amt_sum': 0.0})data0 = data0.na.fill({'threemonth_discnt_amt_sum': 0.0})data0 = data0.na.fill({'onemonth_recv_amt_sum': 0.0})data0 = data0.na.fill({'onemonth_discnt_amt_sum': 0.0})data0 = data0.na.fill({'is_prdc_mfr_pianhao': 0.0})data0 = data0.na.fill({'sell_tm_erp': 0.0})data0 = data0.na.fill({'shopgui_erp': 0.0})data0 = data0.na.fill({'duration_erp': 0.0})data0 = data0.na.fill({'is_shopgui_erp': 0.0})data0 = data0.na.fill({'lvl_shopgui_erp': 0.0})# 检查每一列中缺失数据的百分比# data.agg(*[(1-(fn.count(c)/fn.count('*'))).alias(c+'_null') for c in data.columns]).show()# 移除sell_tm_erp、shopgui_erpdata1 = data0.drop('sell_tm_erp').drop('shopgui_erp')# data1.dtypes# data2.describe(['year_count_erp','haft_year_count_erp','three_month_count_erp','one_month_count_erp']).show()# data2.where('haft_year_count_erp>10 and haft_year_count_erp<=20').count()# data2.describe(['year_recv_amt_sum','haftyear_recv_amt_sum','threemonth_recv_amt_sum','onemonth_recv_amt_sum']).show()# data2.where('year_recv_amt_sum<0').count()# data2.where('onemonth_recv_amt_sum>=50 and onemonth_recv_amt_sum<100').count()# data2.describe(['year_discnt_amt_sum','haftyear_discnt_amt_sum','threemonth_discnt_amt_sum','onemonth_discnt_amt_sum','duration_erp']).show()data2 = data1.where('year_count_erp<200 and year_recv_amt_sum>0')return data2# 连续数据离散化bucketizer1 = QuantileDiscretizer(numBuckets=5, inputCol='year_count_erp',outputCol='year_count_bucketed',relativeError=0.01, handleInvalid='error')bucketizer2 = QuantileDiscretizer(numBuckets=5, inputCol='haft_year_count_erp',outputCol='haft_year_count_bucketed',relativeError=0.01, handleInvalid='error')bucketizer3 = QuantileDiscretizer(numBuckets=5, inputCol='three_month_count_erp',outputCol='three_month_count_bucketed',relativeError=0.01, handleInvalid='error')bucketizer4 = QuantileDiscretizer(numBuckets=5, inputCol='one_month_count_erp',outputCol='one_month_count_bucketed',relativeError=0.01, handleInvalid='error')bucketizer5 = QuantileDiscretizer(numBuckets=5, inputCol='year_recv_amt_sum',outputCol='year_recv_bucketed',relativeError=0.01, handleInvalid='error')bucketizer6 = QuantileDiscretizer(numBuckets=5, inputCol='haftyear_recv_amt_sum',outputCol='haftyear_recv_bucketed',relativeError=0.01, handleInvalid='error')bucketizer7 = QuantileDiscretizer(numBuckets=5, inputCol='threemonth_recv_amt_sum',outputCol='threemonth_recv_bucketed',relativeError=0.01, handleInvalid='error')bucketizer8 = QuantileDiscretizer(numBuckets=5, inputCol='onemonth_recv_amt_sum',outputCol='onemonth_recv_bucketed',relativeError=0.01, handleInvalid='error')bucketizer9 = QuantileDiscretizer(numBuckets=5, inputCol='duration_erp',outputCol='duration_bucketed',relativeError=0.01, handleInvalid='error')# 把String类型的字段转化为double类型indexer1 = StringIndexer().setInputCol("gender").setOutputCol("gender_index")indexer2 = StringIndexer().setInputCol("is_nt_concn_webchat").setOutputCol("webchat_index")indexer3 = StringIndexer().setInputCol("erp_corp").setOutputCol("corp_index")# onehot编码encoder01 = OneHotEncoder().setInputCol("gender_index").setOutputCol("gender_vec").setDropLast(False)encoder02 = OneHotEncoder().setInputCol("webchat_index").setOutputCol("webchat_vec").setDropLast(False)encoder03 = OneHotEncoder().setInputCol("corp_index").setOutputCol("corp_vec").setDropLast(False)encoder1 = OneHotEncoder().setInputCol("year_count_bucketed").setOutputCol("year_count_vec").setDropLast(False)encoder2 = OneHotEncoder().setInputCol("haft_year_count_bucketed").setOutputCol("haft_year_count_vec").setDropLast(False)encoder3 = OneHotEncoder().setInputCol("three_month_count_bucketed").setOutputCol("three_month_count_vec").setDropLast(False)encoder4 = OneHotEncoder().setInputCol("one_month_count_bucketed").setOutputCol("one_month_count_vec").setDropLast(False)encoder5 = OneHotEncoder().setInputCol("year_recv_bucketed").setOutputCol("year_recv_vec").setDropLast(False)encoder6 = OneHotEncoder().setInputCol("haftyear_recv_bucketed").setOutputCol("haftyear_recv_vec").setDropLast(False)encoder7 = OneHotEncoder().setInputCol("threemonth_recv_bucketed").setOutputCol("threemonth_recv_vec").setDropLast(False)encoder8 = OneHotEncoder().setInputCol("onemonth_recv_bucketed").setOutputCol("onemonth_recv_vec").setDropLast(False)encoder9 = OneHotEncoder().setInputCol("duration_bucketed").setOutputCol("duration_vec").setDropLast(False)encoder10 = OneHotEncoder().setInputCol("lvl_shopgui_erp").setOutputCol("lvl_shopgui_vec").setDropLast(False)preprocessPipeline = Pipeline(stages=[bucketizer1, bucketizer2, bucketizer3, bucketizer4, bucketizer5, bucketizer6, bucketizer7, bucketizer8,bucketizer9, indexer1, indexer2, indexer3, encoder01, encoder02, encoder03, encoder1, encoder2, encoder3,encoder4, encoder5, encoder6, encoder7, encoder8, encoder9, encoder10])# (dt1, dt2) = data.randomSplit([0.9, 0.1], seed=1)data2 = featureEngineering(data)preP = preprocessPipeline.fit(data2)data3 = preP.transform(data2)data3.cache()dp = data3.where('label=1.0')dn = data3.where('label=0.0')# print(dp.count())# print(dn.count())samplerate = round(dn.count()/dp.count())# print(samplerate)# 将数据切分为训练集和测试集,按照训练集70%,测试集30%的比例(dp1, dp2) = dp.randomSplit([0.7, 0.3], seed=1)(dn1, dn2) = dn.randomSplit([0.7, 0.3], seed=2)df1 = dp1.union(dn1)df2 = dp2.union(dn2)df1.groupBy("label").count().show()df2.groupBy("label").count().show()data_p1 = df1.where('label=1.0')data_p1.show(5)data_n1 = df1.where('label=0.0')data_p2 = df2.where('label=1.0')data_n2 = df2.where('label=0.0')data_p11 = data_p1.rdd.sample(True,samplerate,100)data_p12 = spark.createDataFrame(data_p11)data_p21 = data_p2.rdd.sample(True,samplerate,100)data_p22 = spark.createDataFrame(data_p21)train_df = data_n1.union(data_p12)test_df = data_n2.union(data_p22)# print('train_df正负例比例:')# train_df.groupBy("label").count().show()# print('test_df正负例比例:')# test_df.groupBy("label").count().show()train_df.cache()test_df.cache()# 特征初步选择assemblerInputs = ['gender_vec', 'webchat_vec', 'corp_vec','is_nm'# assemblerInputs = ['gender_vec', 'webchat_vec', 'is_nm','is_tel','is_birth_dt','is_cert_num','is_handl_org','is_addr','year_count_vec','haft_year_count_vec','three_month_count_vec','one_month_count_vec','year_recv_vec','haftyear_recv_vec','threemonth_recv_vec','onemonth_recv_vec','is_prdc_mfr_pianhao','duration_vec','lvl_shopgui_vec','lvl_shopgui_erp']# 构建VectorAssembler转换器,用于把特征值转化为特征向量assembler = VectorAssembler(inputCols=assemblerInputs, outputCol='features')# 奇偶选择器 卡方检验,用于筛选重要特征,numTopFeatures=10表示筛选出最重要的10个特征,fpr=0.05假设检验的p值chiSqSelector = ChiSqSelector(featuresCol="features",fpr=0.05,outputCol="selectedFeatures", labelCol="label")# 构建模型验证相关参数的转换器evaluator = BinaryClassificationEvaluator(rawPredictionCol="rawPrediction", labelCol="label",metricName="areaUnderROC")lr = LogisticRegression(elasticNetParam=0.0,maxIter=30,regParam=0.001,featuresCol="selectedFeatures", labelCol="label")lr_pipeline = Pipeline(stages=[assembler, chiSqSelector, lr])lrModel = lr_pipeline.fit(train_df)# 模型保存lrModel.write().overwrite().save("./model/")# 加载模型samelrModel = PipelineModel.load("./model/")# 模型验证,评估分类效果result = samelrModel.transform(test_df)auc = evaluator.evaluate(result)print("AUC(AreaUnderROC)为:{}".format(auc))total_amount = result.count()correct_amount = result.filter(result.label == result.prediction).count()precision_rate = correct_amount / total_amountprint("预测准确率为:{}".format(precision_rate))positive_amount = result.filter(result.label == 1).count()negative_amount = result.filter(result.label == 0).count()print("正样本数:{},负样本数:{}".format(positive_amount, negative_amount))positive_precision_amount = result.filter(result.label == 1).filter(result.prediction == 1).count()negative_precision_amount = result.filter(result.label == 0).filter(result.prediction == 0).count()positive_false_amount = result.filter(result.label == 1).filter(result.prediction == 0).count()negative_false_amount = result.filter(result.label == 0).filter(result.prediction == 1).count()print("正样本预测准确数量:{},负样本预测准确数量:{}".format(positive_precision_amount, negative_precision_amount))print("正样本预测错误数量:{},负样本预测错误数量:{}".format(positive_false_amount, negative_false_amount))recall_rate1 = positive_precision_amount / positive_amountrecall_rate2 = negative_precision_amount / negative_amountprint("正样本召回率为:{},负样本召回率为:{}".format(recall_rate1, recall_rate2))prediction = result.select('label', 'prediction','rawPrediction', 'probability')print(result.show(5))print(prediction.show(5))spark.stop()
附2:基于分布式环境的Python代码
# coding: utf-8import loggingimport sysfrom pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType, StructField, StringType, DoubleTypeimport pyspark.sql.functions as fnfrom pyspark.sql.functions import regexp_extract,col # regexp_extract是pyspark正则表达式模块from pyspark.ml.feature import Bucketizer,QuantileDiscretizer, OneHotEncoder, StringIndexer, IndexToString, VectorIndexer, VectorAssemblerfrom pyspark.ml.feature import ChiSqSelector, StandardScalerfrom pyspark.ml import Pipeline, PipelineModelfrom pyspark.ml.classification import RandomForestClassifier, LogisticRegression,LogisticRegressionModelfrom pyspark.ml.evaluation import BinaryClassificationEvaluatorfrom pyspark.ml.tuning import CrossValidator, ParamGridBuilder, TrainValidationSplitif __name__ == '__main__':# 创建spark连接spark = SparkSession.builder.appName("usrLostModel").enableHiveSupport().master("yarn-client").getOrCreate()# 导入hive数据为dataframe格式data = spark.sql("select label,erp_code,gender,is_nt_concn_webchat,erp_corp,is_nm,is_tel,is_birth_dt,\is_cert_num,is_handl_org,is_addr,cast(year_count_erp as double),cast(haft_year_count_erp as double),\cast(three_month_count_erp as double),cast(one_month_count_erp as double),cast(year_avg_count_erp as double),\cast(haftyear_avg_count_erp as double),cast(threemonth_avg_count_erp as double),cast(onemonth_avg_count_erp as double),\cast(year_recv_amt_sum as double),cast(year_discnt_amt_sum as double),cast(haftyear_recv_amt_sum as double),\cast(haftyear_discnt_amt_sum as double),cast(threemonth_recv_amt_sum as double),cast(threemonth_discnt_amt_sum as double),\cast(onemonth_recv_amt_sum as double),cast(onemonth_discnt_amt_sum as double),cast(is_prdc_mfr_pianhao as double),\sell_tm_erp,shopgui_erp,duration_erp,is_shopgui_erp,lvl_shopgui_erp from spider.t06_wajue_data")data.show(5)def featureEngineering(data):# 用0填补is_nt_concn_webchat缺失值data0 = data.na.fill({'is_nt_concn_webchat': '0'})# data.groupBy("is_nt_concn_webchat").count().show()# 检查每一列中缺失数据的百分比# data.agg(*[(1-(fn.count(c)/fn.count('*'))).alias(c+'_null') for c in data.columns]).show()# data.agg(*[(fn.count('*')-fn.count(c)).alias(c+'_null') for c in data.columns]).show()# 用0.0填补double类型数据的缺失值data0 = data0.na.fill({'year_discnt_amt_sum': 0.0})data0 = data0.na.fill({'haftyear_recv_amt_sum': 0.0})data0 = data0.na.fill({'haftyear_discnt_amt_sum': 0.0})data0 = data0.na.fill({'threemonth_recv_amt_sum': 0.0})data0 = data0.na.fill({'threemonth_discnt_amt_sum': 0.0})data0 = data0.na.fill({'onemonth_recv_amt_sum': 0.0})data0 = data0.na.fill({'onemonth_discnt_amt_sum': 0.0})data0 = data0.na.fill({'is_prdc_mfr_pianhao': 0.0})# data0 = data0.na.fill({'sell_tm_erp': 0.0})data0 = data0.na.fill({'shopgui_erp': 0.0})data0 = data0.na.fill({'duration_erp': 0.0})data0 = data0.na.fill({'is_shopgui_erp': 0.0})data0 = data0.na.fill({'lvl_shopgui_erp': 0.0})# 检查每一列中缺失数据的百分比# data.agg(*[(1-(fn.count(c)/fn.count('*'))).alias(c+'_null') for c in data.columns]).show()# 移除sell_tm_erp、shopgui_erpdata1 = data0.drop('shopgui_erp')# data1.dtypes# data2.describe(['year_count_erp','haft_year_count_erp','three_month_count_erp','one_month_count_erp']).show()# data2.where('haft_year_count_erp>10 and haft_year_count_erp<=20').count()# data2.describe(['year_recv_amt_sum','haftyear_recv_amt_sum','threemonth_recv_amt_sum','onemonth_recv_amt_sum']).show()# data2.where('year_recv_amt_sum<0').count()# data2.where('onemonth_recv_amt_sum>=50 and onemonth_recv_amt_sum<100').count()# data2.describe(['year_discnt_amt_sum','haftyear_discnt_amt_sum','threemonth_discnt_amt_sum','onemonth_discnt_amt_sum','duration_erp']).show()data2 = data1.where('year_count_erp<200 and year_recv_amt_sum>0')return data2data2 = featureEngineering(data)# 连续数据离散化bucketizer1 = QuantileDiscretizer(numBuckets=5, inputCol='year_count_erp',\outputCol='year_count_bucketed',\relativeError=0.01, handleInvalid='error')bucketizer2 = QuantileDiscretizer(numBuckets=5, inputCol='haft_year_count_erp',\outputCol='haft_year_count_bucketed',\relativeError=0.01, handleInvalid='error')bucketizer3 = QuantileDiscretizer(numBuckets=5, inputCol='three_month_count_erp',\outputCol='three_month_count_bucketed',\relativeError=0.01, handleInvalid='error')bucketizer4 = QuantileDiscretizer(numBuckets=5, inputCol='one_month_count_erp',\outputCol='one_month_count_bucketed',\relativeError=0.01, handleInvalid='error')bucketizer5 = QuantileDiscretizer(numBuckets=5, inputCol='year_recv_amt_sum',\outputCol='year_recv_bucketed',\relativeError=0.01, handleInvalid='error')bucketizer6 = QuantileDiscretizer(numBuckets=5, inputCol='haftyear_recv_amt_sum',\outputCol='haftyear_recv_bucketed',\relativeError=0.01, handleInvalid='error')bucketizer7 = QuantileDiscretizer(numBuckets=5, inputCol='threemonth_recv_amt_sum',\outputCol='threemonth_recv_bucketed',\relativeError=0.01, handleInvalid='error')bucketizer8 = QuantileDiscretizer(numBuckets=5, inputCol='onemonth_recv_amt_sum',\outputCol='onemonth_recv_bucketed',\relativeError=0.01, handleInvalid='error')bucketizer9 = QuantileDiscretizer(numBuckets=5, inputCol='duration_erp',\outputCol='duration_bucketed',\relativeError=0.01, handleInvalid='error')# 把String类型的字段转化为double类型indexer1 = StringIndexer().setInputCol("gender").setOutputCol("gender_index")indexer2 = StringIndexer().setInputCol("is_nt_concn_webchat").setOutputCol("webchat_index")indexer3 = StringIndexer().setInputCol("erp_corp").setOutputCol("corp_index")# onehot编码encoder01 = OneHotEncoder().setInputCol("gender_index").setOutputCol("gender_vec").setDropLast(False)encoder02 = OneHotEncoder().setInputCol("webchat_index").setOutputCol("webchat_vec").setDropLast(False)encoder03 = OneHotEncoder().setInputCol("corp_index").setOutputCol("corp_vec").setDropLast(False)encoder1 = OneHotEncoder().setInputCol("year_count_bucketed").setOutputCol("year_count_vec").setDropLast(False)encoder2 = OneHotEncoder().setInputCol("haft_year_count_bucketed").setOutputCol("haft_year_count_vec").setDropLast(False)encoder3 = OneHotEncoder().setInputCol("three_month_count_bucketed").setOutputCol("three_month_count_vec").setDropLast(False)encoder4 = OneHotEncoder().setInputCol("one_month_count_bucketed").setOutputCol("one_month_count_vec").setDropLast(False)encoder5 = OneHotEncoder().setInputCol("year_recv_bucketed").setOutputCol("year_recv_vec").setDropLast(False)encoder6 = OneHotEncoder().setInputCol("haftyear_recv_bucketed").setOutputCol("haftyear_recv_vec").setDropLast(False)encoder7 = OneHotEncoder().setInputCol("threemonth_recv_bucketed").setOutputCol("threemonth_recv_vec").setDropLast(False)encoder8 = OneHotEncoder().setInputCol("onemonth_recv_bucketed").setOutputCol("onemonth_recv_vec").setDropLast(False)encoder9 = OneHotEncoder().setInputCol("duration_bucketed").setOutputCol("duration_vec").setDropLast(False)encoder10 = OneHotEncoder().setInputCol("lvl_shopgui_erp").setOutputCol("lvl_shopgui_vec").setDropLast(False)preprocessPipeline = Pipeline(stages=[bucketizer1, bucketizer2, bucketizer3, bucketizer4, bucketizer5, bucketizer6, bucketizer7, bucketizer8,bucketizer9, indexer1, indexer2, indexer3, encoder01, encoder02, encoder03, encoder1, encoder2, encoder3,encoder4, encoder5, encoder6, encoder7, encoder8, encoder9, encoder10])preP = preprocessPipeline.fit(data2)data3 = preP.transform(data2)data3.cache()dp = data3.where('label=1.0')dn = data3.where('label=0.0')print(dp.count())print(dn.count())samplerate = round(dn.count()/dp.count())# 将数据切分为训练集和测试集,按照训练集70%,测试集30%的比例(dp1, dp2) = dp.randomSplit([0.7, 0.3], seed=1)(dn1, dn2) = dn.randomSplit([0.7, 0.3], seed=2)df1 = dp1.union(dn1)df2 = dp2.union(dn2)df1.groupBy("label").count().show()df2.groupBy("label").count().show()data_p1 = df1.where('label=1.0')data_n1 = df1.where('label=0.0')data_p1.show(5)data_p2 = df2.where('label=1.0')data_n2 = df2.where('label=0.0')data_p11 = data_p1.rdd.sample(True,samplerate,100)data_p12 = spark.createDataFrame(data_p11)data_p21 = data_p2.rdd.sample(True,samplerate,100)data_p22 = spark.createDataFrame(data_p21)train_df = data_n1.union(data_p12)test_df = data_n2.union(data_p22)# print('train_df正负例比例:')# train_df.groupBy("label").count().show()# print('test_df正负例比例:')# test_df.groupBy("label").count().show()train_df.cache()test_df.cache()# 特征初步选择assemblerInputs = ['gender_vec', 'webchat_vec', 'corp_vec','is_nm'# assemblerInputs = ['gender_vec', 'webchat_vec', 'is_nm','is_tel','is_birth_dt','is_cert_num','is_handl_org','is_addr','year_count_vec','haft_year_count_vec','three_month_count_vec','one_month_count_vec','year_recv_vec','haftyear_recv_vec','threemonth_recv_vec','onemonth_recv_vec','is_prdc_mfr_pianhao','duration_vec','lvl_shopgui_vec','lvl_shopgui_erp']# 构建VectorAssembler转换器,用于把特征值转化为特征向量assembler = VectorAssembler(inputCols=assemblerInputs, outputCol='features')# 奇偶选择器 卡方检验,用于筛选重要特征,numTopFeatures=10表示筛选出最重要的10个特征,fpr=0.05假设检验的p值chiSqSelector = ChiSqSelector(featuresCol="features",fpr=0.05,outputCol="selectedFeatures", labelCol="label")# 构建模型验证相关参数的转换器evaluator = BinaryClassificationEvaluator(rawPredictionCol="rawPrediction", labelCol="label",metricName="areaUnderROC")lr = LogisticRegression(elasticNetParam=0.0,maxIter=30,regParam=0.001,featuresCol="selectedFeatures", labelCol="label")lr_pipeline = Pipeline(stages=[assembler, chiSqSelector, lr])lrModel = lr_pipeline.fit(train_df)# 模型保存lrModel.write().overwrite().save("hdfs://nameservice1/BDP/model/usrLostModel")# 加载模型samelrModel = PipelineModel.load("hdfs://nameservice1/BDP/model/usrLostModel")# 模型验证,评估分类效果result = samelrModel.transform(test_df)# 获取logger实例,如果参数为空则返回root loggerlogger = logging.getLogger("usrLostModel")# 指定logger输出格式formatter = logging.Formatter('%(asctime)s %(levelname)-8s: %(message)s')# 文件日志file_handler = logging.FileHandler("/data/appdata/datamining/m01_usrLost_prediction/usrLostPredModel_pys_online.log")file_handler.setFormatter(formatter) # 可以通过setFormatter指定输出格式# 控制台日志console_handler = logging.StreamHandler(sys.stdout)console_handler.formatter = formatter # 也可以直接给formatter赋值# 为logger添加的日志处理器,可以自定义日志处理器让其输出到其他地方logger.addHandler(file_handler)logger.addHandler(console_handler)# 指定日志的最低输出级别,默认为WARN级别logger.setLevel(logging.INFO)auc = evaluator.evaluate(result)logger.info("AUC(AreaUnderROC)为:{}".format(auc))total_amount = result.count()correct_amount = result.filter(result.label == result.prediction).count()precision_rate = correct_amount / total_amountlogger.info("预测准确率为:{}".format(precision_rate))positive_amount = result.filter(result.label == 1).count()negative_amount = result.filter(result.label == 0).count()logger.info("正样本数:{},负样本数:{}".format(positive_amount, negative_amount))positive_precision_amount = result.filter(result.label == 1).filter(result.prediction == 1).count()negative_precision_amount = result.filter(result.label == 0).filter(result.prediction == 0).count()positive_false_amount = result.filter(result.label == 1).filter(result.prediction == 0).count()negative_false_amount = result.filter(result.label == 0).filter(result.prediction == 1).count()logger.info("正样本预测准确数量:{},负样本预测准确数量:{}".format(positive_precision_amount, negative_precision_amount))logger.info("正样本预测错误数量:{},负样本预测错误数量:{}".format(positive_false_amount, negative_false_amount))recall_rate1 = positive_precision_amount / positive_amountrecall_rate2 = negative_precision_amount / negative_amountlogger.info("正样本召回率为:{},负样本召回率为:{}".format(recall_rate1, recall_rate2))# 移除日志处理器logger.removeHandler(file_handler)# 模型验证,评估分类效果result0 = samelrModel.transform(data3)predictions = result0.select('label', 'erp_code','prediction', 'probability','erp_corp')predictions.registerTempTable("tempTable")spark.sql('insert overwrite table spider.t06_wajue_usrLostprediction select * from tempTable')# prediction = result0.select('label', 'prediction','rawPrediction', 'probability')# prediction.toPandas().to_csv('/data/appdata/pred.csv')spark.stop()

若有收获,就点个赞吧
0 人点赞
