PySpark is the Python API for Spark.
Public classes:
SparkContext:Main entry point for Spark functionality.
RDD:A Resilient Distributed Dataset (RDD), the basic abstraction in Spark.
Broadcast:A broadcast variable that gets reused across tasks.
Accumulator:An “add-only” shared variable that tasks can only add values to.
SparkConf:For configuring Spark.
SparkFiles:Access files shipped with jobs.
StorageLevel:Finer-grained cache persistence levels.
TaskContext:Information about the current running task, avaialble on the workers and experimental.
目前Spark2.2.0官网给出的pyspark.sql模块API主要如下:主要变化是用SparkSession代替了原来的SparkConf、SparkContext、SQLContext和HiveContext
pyspark.sql.SparkSessionMain entry point forDataFrameand SQL functionality. pyspark.sql.DataFrameA distributed collection of data grouped into named columns. pyspark.sql.ColumnA column expression in aDataFrame. pyspark.sql.RowA row of data in aDataFrame. pyspark.sql.GroupedDataAggregation methods, returned byDataFrame.groupBy(). pyspark.sql.DataFrameNaFunctionsMethods for handling missing data (null values). pyspark.sql.DataFrameStatFunctionsMethods for statistics functionality. pyspark.sql.functionsList of built-in functions available forDataFrame. pyspark.sql.typesList of data types available. pyspark.sql.WindowFor working with window functions
目前Spark1.6.2官网给出的pyspark.sql模块API主要如下:
pyspark.sql.SQLContext Main entry point for DataFrame and SQL functionality. pyspark.sql.DataFrame A distributed collection of data grouped into named columns. pyspark.sql.Column A column expression in a DataFrame. pyspark.sql.Row A row of data in a DataFrame. pyspark.sql.HiveContext Main entry point for accessing data stored in Apache Hive. pyspark.sql.GroupedData Aggregation methods, returned by DataFrame.groupBy(). pyspark.sql.DataFrameNaFunctions Methods for handling missing data (null values). pyspark.sql.DataFrameStatFunctions Methods for statistics functionality. pyspark.sql.functions List of built-in functions available for DataFrame. pyspark.sql.types List of data types available. pyspark.sql.Window For working with window functions.
下面将会介绍各种常用的函数,可以看到绝大多数与Python库中的函数非常类似,函数种类也非常丰富,可以满足我们各种需求的应用场景,在使用PySpark的时候,请读者尽量使用PySpark中内置的函数,因为这将会避免Python解释器到Spark解释器切换的开销,有利于性能优化。这点务必谨记。
1 SparkSession
SparkSession.createDataFrame(data, schema=None, samplingRatio=None, verifySchema=True)
(1)Creates a DataFrame from an RDD, a list or a pandas.DataFrame.
(2)When schema is a list of column names, the type of each column will be inferred from data.(每一个字段数据类型为推断模式infer schema)
(3)When schema is None, it will try to infer the schema (column names and types) from data, which should be an RDD of Row, or namedtuple, or dict.(当模式为None时,它将尝试从数据中推断出模式(列名和类型),数据应该是Row的RDD,或者是namedtuple,而不是dict。)
(4)When schema is pyspark.sql.types.DataType or a datatype string, it must match the real data, or an exception will be thrown at runtime. If the given schema is not pyspark.sql.types.StructType, it will be wrapped into a pyspark.sql.types.StructType as its only field, and the field name will be “value”, each record will also be wrapped into a tuple, which can be converted to row later.(当架构是pyspark.sql.types.DataType或数据类型字符串时,它必须匹配真实数据,否则将在运行时引发异常。 如果给定的模式不是pyspark.sql.types.StructType,它将被封装成一个pyspark.sql.types.StructType作为唯一的字段,字段名称将是“值”,每个记录也将被包装成一个 元组,可以稍后转换为行。)
If schema inference is needed, samplingRatio is used to determined the ratio of rows used for schema inference. The first row will be used if samplingRatio is None.(如果需要模式推断,则使用抽样比率来确定用于模式推断的行的比例。 如果采样比率为无,则使用第一行。)
Parameters:
data – an RDD of any kind of SQL data representation(e.g. row, tuple, int, boolean, etc.), or list, or pandas.DataFrame.
schema – a pyspark.sql.types.DataType or a datatype string or a list of column names, default is None. The data type string format equals to pyspark.sql.types.DataType.simpleString, except that top level struct type can omit the struct<> and atomic types use typeName() as their format, e.g. usebyte instead of tinyint for pyspark.sql.types.ByteType. We can also use int as a short name for IntegerType.
samplingRatio – the sample ratio of rows used for inferring
verifySchema – verify data types of every row against schema.
Returns:DataFrame
from pyspark.sql.types import *schema=StructType([StructField("name",StringType(),True),...,StructField("age",IntegerType(),True)])df3=spark.createDataFrame(rdd,schema)df3.collect()[Row(name=u'Alice', age=1)]spark.createDataFrame(df.toPandas()).collect()[Row(name=u'Alice', age=1)]spark.createDataFrame(pandas.DataFrame([[1,2]])).collect()[Row(0=1, 1=2)]
2 DataFrame
DataFrame相当于Spark SQL中的关系表,可以使用SQLContext中的各种函数创建
> people=sqlContext.read.parquet("...")
创建完成后,可以使用DataFrame,Column中定义的各种域特定语言(DSL)函数对其进行操作。例如要从数据框中选择一列,请使用apply方法:
> ageCol=people.age
一个案例:
> people=sqlContext.read.parquet("...")>> department=sqlContext.read.parquet("...")>> people.filter(people.age>30)\>> .join(department,people.deptId==department.id)\>> .groupBy(department.name,"gender")\>> .agg({"salary":"avg","age":"max"})
agg()方法:在没有组的情况下汇总整个数据框(df.groupBy.agg()的简写)。
> df.agg({"age":"max"}).collect()>> [Row(max(age)=5)]>> from pyspark.sqlimport functions as F>> df.agg(F.min(df.age)).collect()>> [Row(min(age)=2)]
alias()方法:返回一个带有别名集的新DataFrame。
> from pyspark.sql.functions import *>> df_as1=df.alias("df_as1")>> df_as2=df.alias("df_as2")>> joined_df=df_as1.join(df_as2,col("df_as1.name")==col("df_as2.name"),'inner')>> joined_df.select("df_as1.name","df_as2.name","df_as2.age").collect()>> [Row(name=u'Bob', name=u'Bob', age=5), Row(name=u'Alice', name=u'Alice', age=2)]> df.collect()>> df.columns>> df.count()>> df.distinct()>> df.first()>> df.take(2)>> df.head()>> df.head(2)>> df.limit(1).collect()>> df.printSchema()> df.describe(['age']).show()>> df.describe().show()> df.drop('age').collect()>> df.drop(df.age).collect()>> df.join(df2,df.name==df2.name,'inner').drop(df.name).collect()>> df.join(df2,df.name==df2.name,'inner').drop(df2.name).collect()>> df.join(df2,'name','inner').drop('age','height').collect()
dropDuplicates()方法:返回删除重复行的新DataFrame,可选地仅考虑某些列。
对于静态批量DataFrame,它只是丢弃重复的行。 对于流式DataFrame,它会将触发器中的所有数据保留为中间状态,以删除重复的行。 您可以使用with Watermark()来限制重复数据的时间,因此系统会限制状态。 另外,比Watermark()更早的数据将被丢弃以避免重复的可能性。drop_duplicates()是dropDuplicates()的别名。
> >>> from pyspark.sql import Row>> >>>df=sc.parallelize([Row(name='Alice',age=5,height=80),Row(name='Alice',age=5,height=80),Row(name='Alice',age=10,height=80)]).toDF()>> >>> df.dropDuplicates().show()>> +---+------+-----+>> |age|height| name|>> +---+------+-----+>> | 5| 80|Alice|>> | 10| 80|Alice|>> +---+------+-----+>> >>> df.dropDuplicates(['name','height']).show()>> +---+------+-----+>> |age|height| name|>> +---+------+-----+>> | 5| 80|Alice|>> +---+------+-----+
dropna(how=’any’, thresh=None, subset=None) 返回一个新的DataFrame,省略含有空值的行。how:如果“any”,如果它包含任何空值,则删除一行; 如果’all’,只有当所有的值都为空时才删除一行。thresh:默认值无如果指定,则删除行数小于非阈值的非空值。 这将覆盖how参数。subset :要考虑的列名称的可选列表。
> >>> df.dtypes>> [('age', 'int'), ('name', 'string')]> fillna(*value*, *subset=None*)>> **value**: int,long,float,string或dict。 用来替换空值的值。 如果值是字典,则子集将被忽略,值必须是从列名称(字符串)到替换值的映射。 替换值必须是int,long,float,boolean或string。**subset**:要考虑的列名称的可选列表。 子集中指定的不具有匹配数据类型的列将被忽略。 例如,如果value是一个字符串,并且子集包含一个非字符串列,那么非字符串列将被忽略。>> df4.fillna(50).show()>> df4.fillna({'age':50,'name':'unknown'}).show()
filter(condition):where()is an alias forfilter().
Filters rows using the given condition.
Parameters:condition – a Column of types.BooleanType or a string of SQL expression.
> >>> df.filter(df.age>3).collect()>> [Row(age=5, name=u'Bob')]>> >>> df.where(df.age==2).collect()>> [Row(age=2, name=u'Alice')]>> >>> df.filter("age > 3").collect()>> [Row(age=5, name=u'Bob')]>> >>> df.where("age = 2").collect()>> [Row(age=2, name=u'Alice')]
foreach(func):将func函数应用于DataFrame的每一行Row,df.rdd.foreach()是一种简要写法。类似的有foreachPartition(func): 将func函数应用于DataFrame的每一个Partition.
> def func(person):>> print(person.name)>> df.foreach(func)>> def func(person):>> for person in people:>> print(person.name)>> df.foreach(func)
groupBy(*cols):使用指定的列对DataFrame进行分组,所以我们可以对它们进行聚合。 groupby()是groupBy()的别名。 参数:cols ——要分组的列的列表。 每个元素应该是列名(字符串)或表达式(列)。
> >>> df.groupBy().avg().collect()>> [Row(avg(age)=3.5)]>> >>> sorted(df.groupBy('name').agg({'age':'mean'}).collect())>> [Row(name=u'Alice', avg(age)=2.0), Row(name=u'Bob', avg(age)=5.0)]>> >>> sorted(df.groupBy(df.name).avg().collect())>> [Row(name=u'Alice', avg(age)=2.0), Row(name=u'Bob', avg(age)=5.0)]>> >>> sorted(df.groupBy(['name',df.age]).count().collect())>> [Row(name=u'Alice', age=2, count=1), Row(name=u'Bob', age=5, count=1)]
join(other, on=None, how=None) 非常重要
Join作为SQL中一个重要语法特性,几乎所有稍微复杂一点的数据分析场景都离不开Join,如今Spark SQL(Dataset/DataFrame)已经成为Spark应用程序开发的主流,作为开发者,我们有必要了解Join在Spark中是如何组织运行的。
在阐述Join实现之前,我们首先简单介绍SparkSQL的总体流程,一般地,我们有两种方式使用SparkSQL,一种是直接写sql语句,这个需要有元数据库支持,例如Hive等,另一种是通过Dataset/DataFrame编写Spark应用程序。如下图所示,sql语句被语法解析(SQL AST)成查询计划,或者我们通过Dataset/DataFrame提供的APIs组织成查询计划,查询计划分为两大类:逻辑计划和物理计划,这个阶段通常叫做逻辑计划,经过语法分析(Analyzer)、一系列查询优化(Optimizer)后得到优化后的逻辑计划,最后被映射成物理计划,转换成RDD执行。
join:使用给定的连接表达式与另一个DataFrame进行连接.
Parameters:
- other – Right side of the join
- on :连接列名称的字符串,列名称列表,连接表达式(列)或列列表。 如果on是一个字符串或者一个表示连接列名的字符串列表,那么这个列必须存在于两边,并且执行一个等连接。
- how :默认inner。可选的有inner, cross, outer, full, full_outer, left, left_outer, right, right_outer, left_semi, and left_anti。
以下执行df和df2之间的连接。
> df.join(df2,df.name==df2.name,'outer').select(df.name,df2.height).collect()> df.join(df2,'name','outer').select('name','height').collect()>> **cond=[df.name==df3.name,df.age==df3.age]**>> **df.join(df3,cond,'outer').select(df.name,df3.age).collect()**>> df.join(df2,'name').select(df.name,df2.height).collect()>> df.join(df4,['name','age']).select(df.name,df.age).collect()
Join基本要素
如下图所示,Join大致包括三个要素:Join方式、Join条件以及过滤条件。其中过滤条件也可以通过AND语句放在Join条件中。
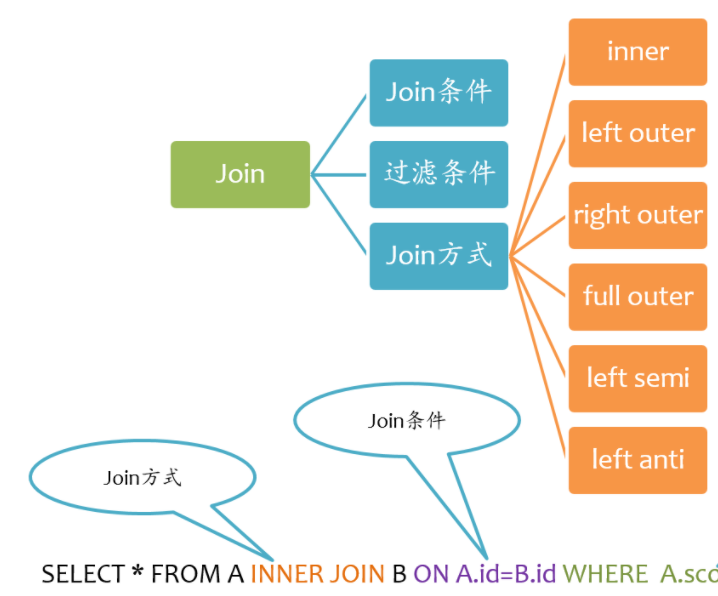
Spark支持所有类型的Join,包括:
inner join
left outer join
right outer join
full outer join
left semi join
left anti join
下面分别阐述这几种Join的实现。
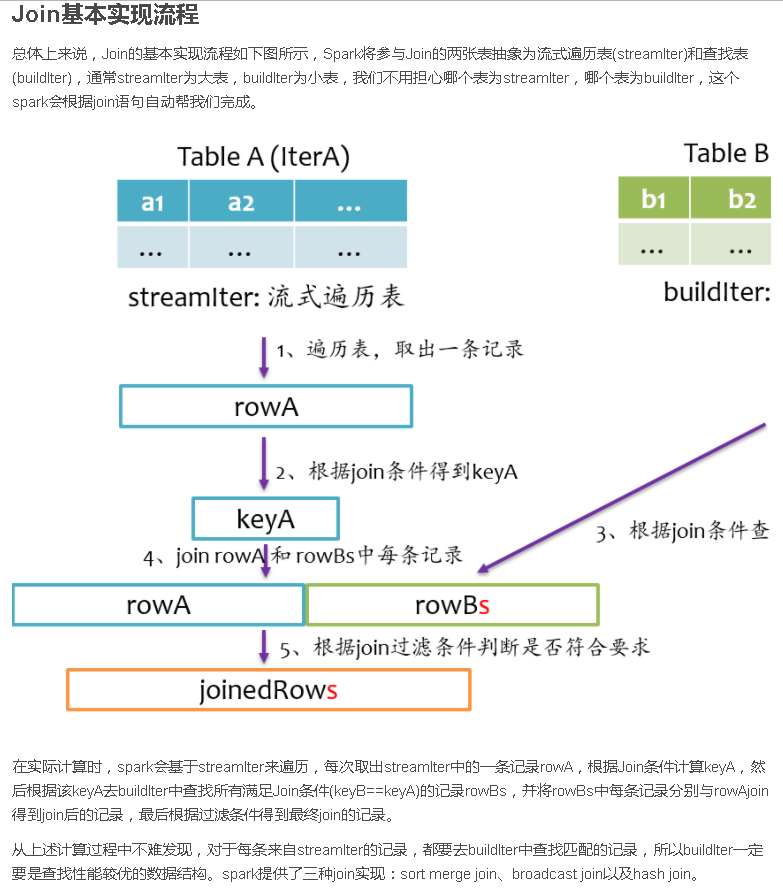
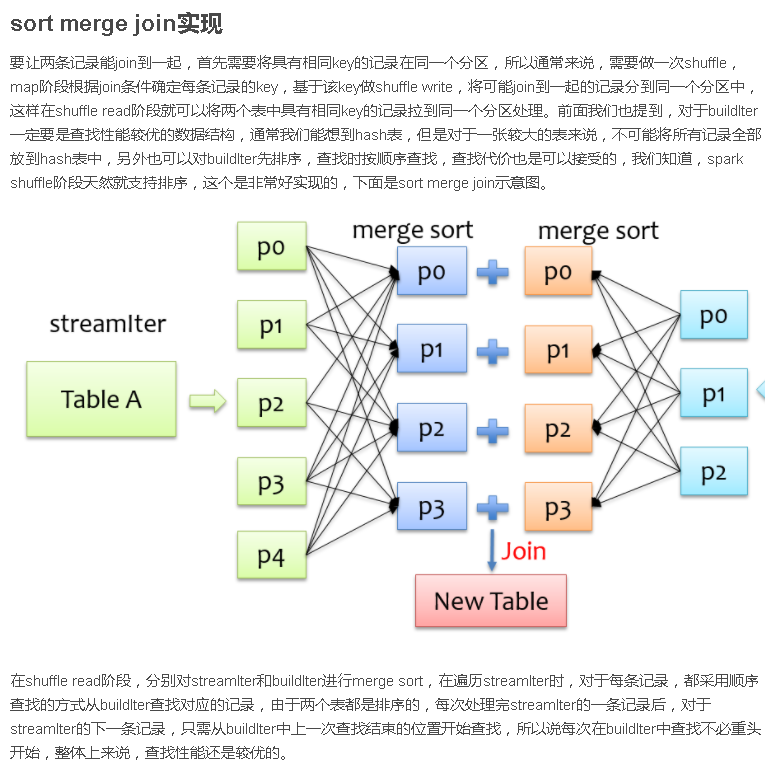
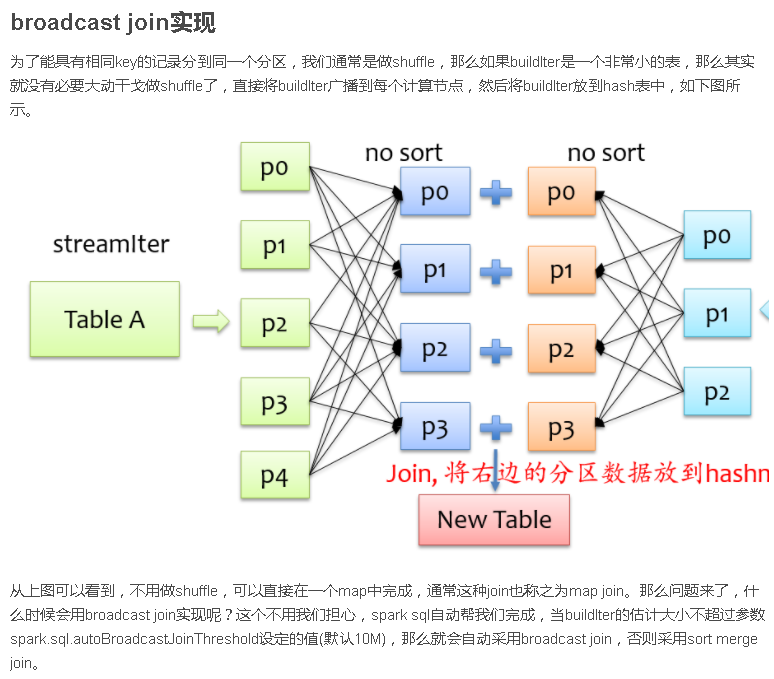
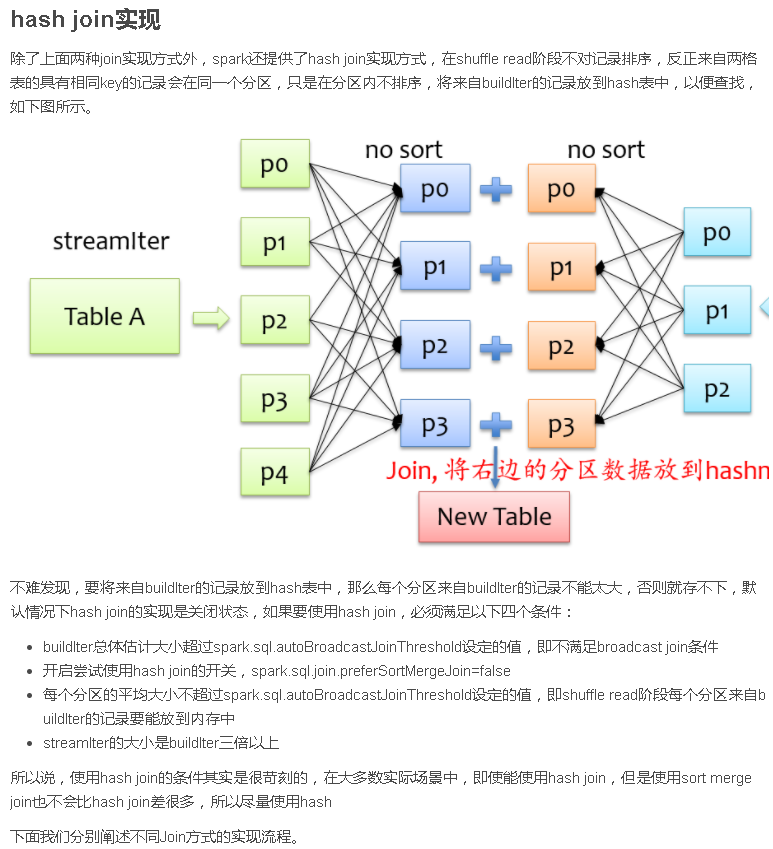
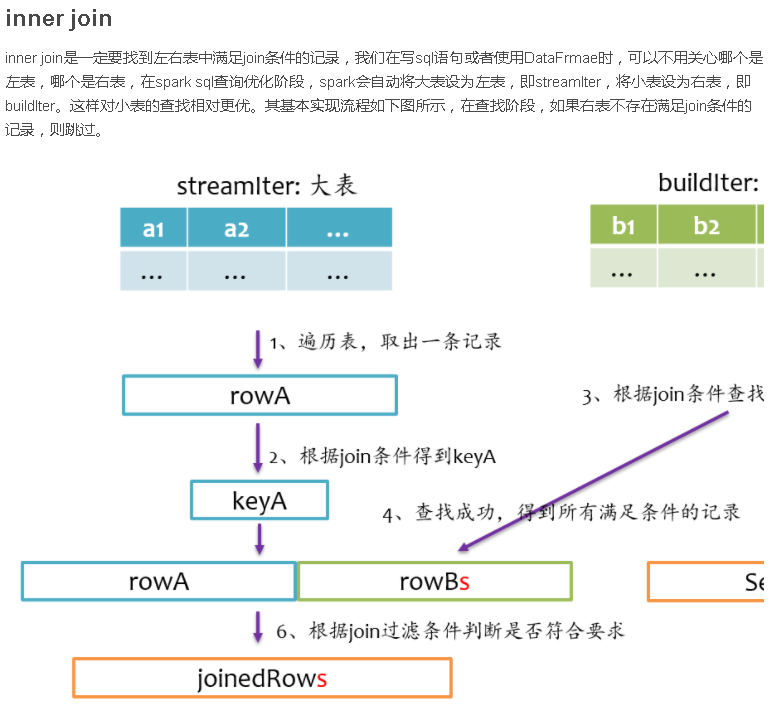
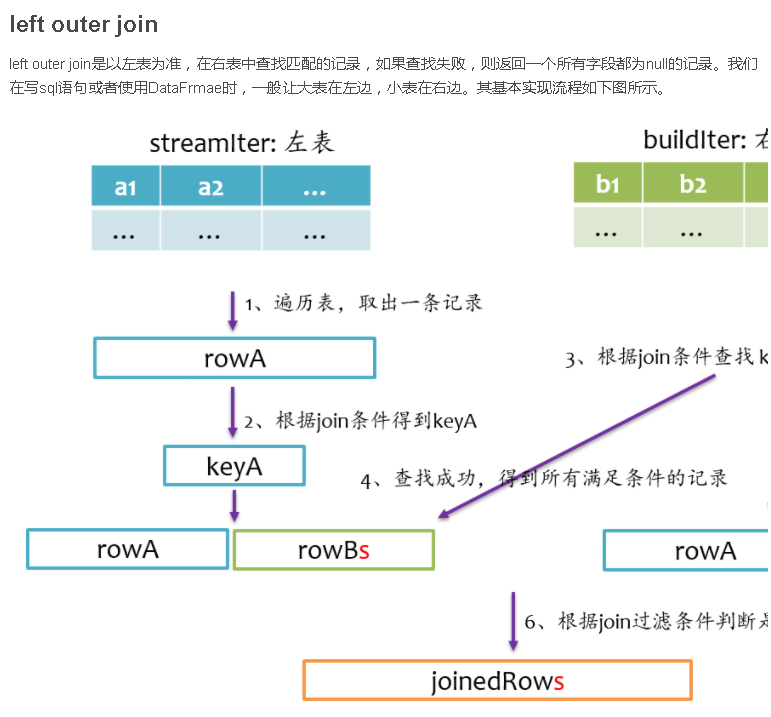
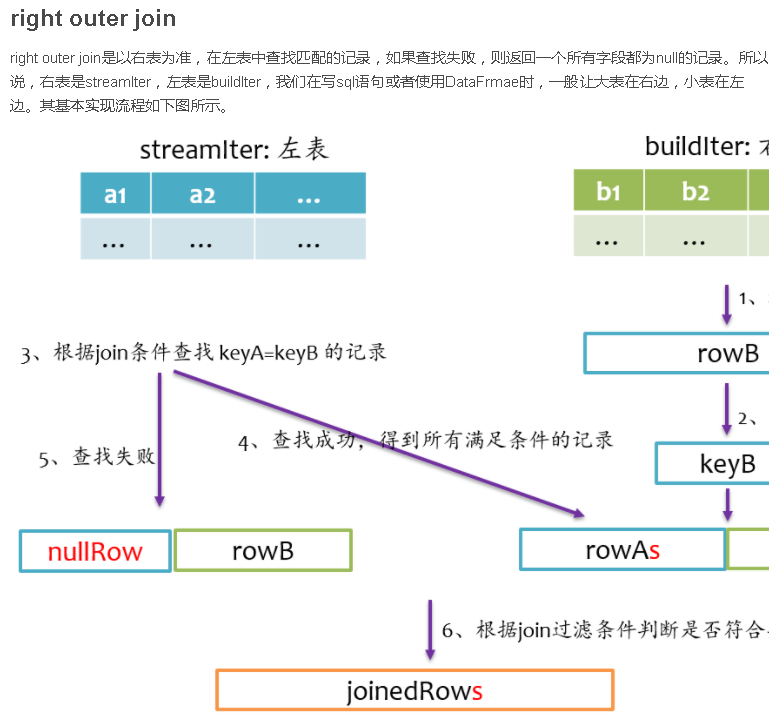
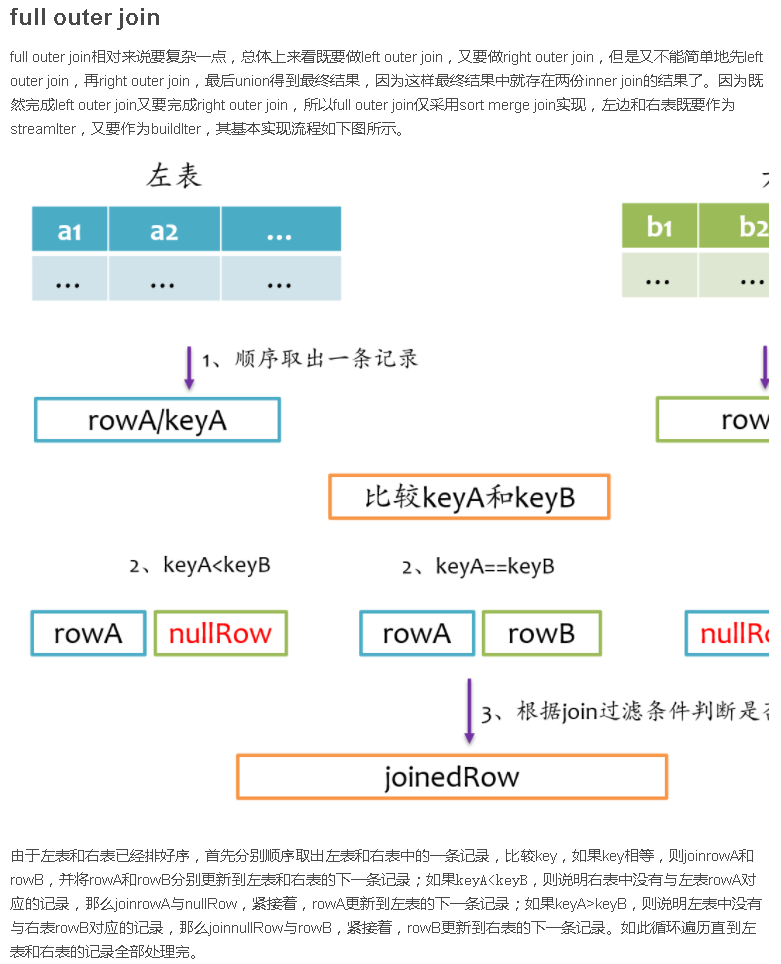
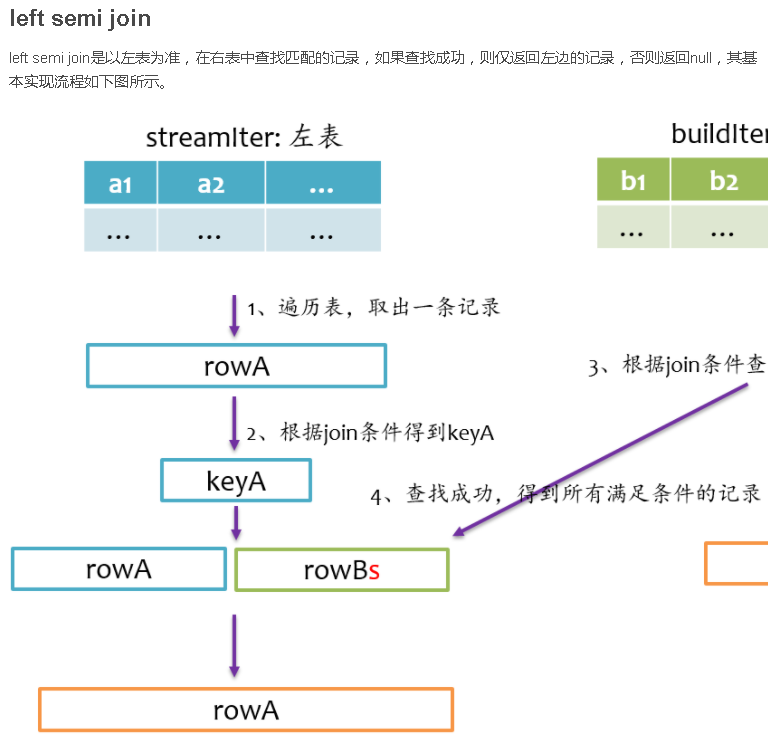
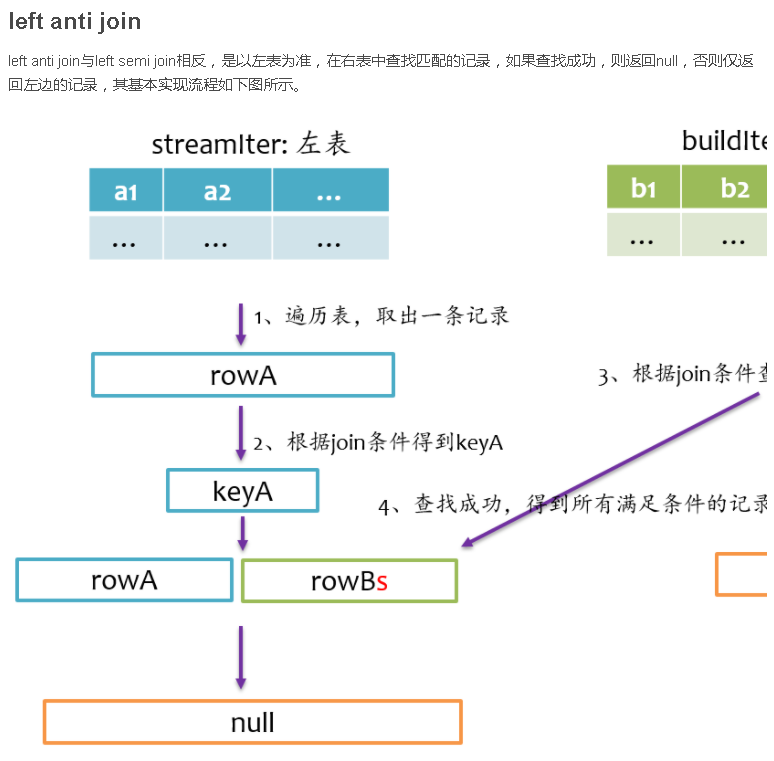
总结
Join是数据库查询中一个非常重要的语法特性,在数据库领域可以说是“得join者的天下”,SparkSQL作为一种分布式数据仓库系统,给我们提供了全面的join支持,并在内部实现上无声无息地做了很多优化,了解join的实现将有助于我们更深刻的了解我们的应用程序的运行轨迹。
orderBy(cols*, kwargs)
sort(cols*, kwargs)
返回按指定列排序的新DataFrame。cols:要排序的列或列名称的列表。ascending:布尔值或布尔值列表(默认值为True)。 按升序排列与降序排列指定多个排序顺序的列表。 如果列表被指定,列表的长度必须等于列的长度。
> df.sort(df.age.desc()).collect()>> df.sort("age",ascending=False).collect()>> df.orderBy(df.age.desc()).collect()>> from pyspark.sql.functions import *>> df.sort(asc("age")).collect()>> df.orderBy(desc("age"),"name").collect()>> df.orderBy(["age","name"],ascending=[0,1]).collect()
repartition(numPartitions, *cols):返回由给定分区表达式分区的新DataFrame,生成的DataFrame是散列分区的。numPartitions可以是一个int来指定目标分区数量或一个Column。 如果它是一个列,它将被用作第一个分区列。 如果未指定,则使用默认的分区数量。在版本1.6中进行了更改:添加了可选参数来指定分区列。 如果指定了分区列,也使numPartition成为可选项。
> df.repartition(10).rdd.getNumPartitions()>> data=df.union(df).repartition("age")>> data.show()>> +---+-----+>> |age| name|>> +---+-----+>> | 5| Bob|>> | 5| Bob|>> | 2|Alice|>> | 2|Alice|>> +---+-----+>> data=data.repartition(7,"age")>> data.show()>> +---+-----+>> |age| name|>> +---+-----+>> | 2|Alice|>> | 5| Bob|>> | 2|Alice|>> | 5| Bob|>> +---+-----+>> data.rdd.getNumPartitions()>> 7>> data=data.repartition("name","age")
**select(cols):投影一组表达式并返回一个新的DataFrame。cols :列名(字符串)或表达式(列)的列表。 如果其中一个列名是’‘,则该列被展开以包括当前DataFrame中的所有列。
> df.select('*').collect()>> df.select('name','age').collect()>> df.select(df.name,(df.age+10).alias('age')).collect()
show(n=20, truncate=True):将前n行打印到控制台。
n :要显示的行数。
truncate:如果设置为True,则默认截断超过20个字符的字符串。 如果设置为大于1的数字,则截断长整数字符串以截断长度并将其右对齐。
> df.show()>> df.show(truncate = True)>> df.show(truncate = 10)
toDF(*cols):返回一个新的类:带有新的指定列名的DataFrame。cols:新列名称列表(字符串)
toJSON()
toPandas()
> df.toDF('f1','f2').collect()>> [Row(f1=2, f2=u'Alice'), Row(f1=5, f2=u'Bob')]>> df.toJSON().first()>> u'{"age":2,"name":"Alice"}'>> df.toPandas()>> age name>> 0 2 Alice>> 1 5 Bob
union(other):在这个和另一个框架中返回一个包含行联合的新DataFrame。这相当于SQL中的UNION ALL。 要做一个SQL风格的联合(做元素的重复数据删除),使用union(other)函数后跟一个distinct()函数。同样作为SQL中的标准,此函数按位置(而不是按名称)解析列。Spark2.0版本中的新功能。Spark1.6.2中可以使用unionAll()函数
withColumn(colName, col):通过添加列或替换具有相同名称的现有列来返回新的DataFrame。参数:colName ——字符串,新列的名称。col—— 生成新列的表达式。
> df.withColumn('age2',df.age+2).collect()>> [Row(age=2, name=u'Alice', age2=4), Row(age=5, name=u'Bob', age2=7)]
withColumnRenamed(existing, new)¶:通过重命名现有列来返回新的DataFrame。 如果模式不包含给定的列名,则这是一个无操作。参数:existing——要重命名的现有列的名称。new——列的新名称。
> df.withColumnRenamed('age','age2').collect()>> [Row(age2=2, name=u'Alice'), Row(age2=5, name=u'Bob')]
3 pyspark.sql.GroupedData
A set of methods for aggregations on a DataFrame, created by DataFrame.groupBy()
**agg(cols)
> >>> gdf=df.groupBy(df.name)>> >>> sorted(gdf.agg({"*":"count"}).collect())>> [Row(name=u'Alice', count(1)=1), Row(name=u'Bob', count(1)=1)]>> >>> from pyspark.sql import functions as F>> >>> sorted(gdf.agg(F.min(df.age)).collect())>> [Row(name=u'Alice', min(age)=2), Row(name=u'Bob', min(age)=5)]
_avg(_cols) :mean() is an alias for avg()*
参数:cols - 列名称列表(字符串)。 非数字列被忽略。
> >>> df.groupBy().avg('age').collect()>> [Row(avg(age)=3.5)]>> >>> df3.groupBy().avg('age','height').collect()>> [Row(avg(age)=3.5, avg(height)=82.5)]
count()
> sorted(df.groupBy(df.age).count().collect())> [Row(age=2, count=1), Row(age=5, count=1)]
max()
> >>> df.groupBy().max('age').collect()>> [Row(max(age)=5)]>> >>> df3.groupBy().max('age','height').collect()>> [Row(max(age)=5, max(height)=85)]
min()
> >>> df.groupBy().min('age').collect()>> [Row(min(age)=2)]>> >>> df3.groupBy().min('age','height').collect()>> [Row(min(age)=2, min(height)=80)]
sum()
> >>> df.groupBy().sum('age').collect()>> [Row(sum(age)=7)]>> >>> df3.groupBy().sum('age','height').collect()>> [Row(sum(age)=7, sum(height)=165)]
4 Column
1. Select a column out of a DataFrame
方法一:df.colName 方法二:df[“colName”]
2. Create from an expression
df.colName+1 1/df.colName
alias函数:在Spark 2.0中,name() is an alias for alias().
> >>> df.select(df.age.alias("age2")).collect()>> [Row(age2=2), Row(age2=5)]>> >>> df.select(df.age.alias("age3",metadata={'max':99})).schema['age3'].metadata['max']>> 99
betwen(lowerBound,upperBound):一个布尔表达式,如果此表达式的值位于给定列之间,则该表达式的值为true。
> >>> df.select(df.name,df.age.between(2,4)).show()>> +-----+---------------------------+>> | name|((age >= 2) AND (age <= 4))|>> +-----+---------------------------+>> |Alice| true|>> | Bob| false|>> +-----+---------------------------+
isNotNull()
如果当前表达式为null,则为真。 通常与DataFrame.filter()结合来选择具有非空值的行。
> from pyspark.sql import Row>> df2=sc.parallelize([Row(name=u'Tom',height=80),Row(name=u'Alice',height=None)]).toDF()>> df2.filter(df2.height.isNotNull()).collect()>> [Row(height=80, name=u'Tom')]
isNull()
如果当前表达式为null,则为真。 通常与DataFrame.filter()结合来选择具有空值的行。
> from pyspark.sql import Row>> df2=sc.parallelize([Row(name=u'Tom',height=80),Row(name=u'Alice',height=None)]).toDF()>> df2.filter(df2.height.isNull()).collect()>> [Row(height=None, name=u'Alice')]
like()
返回基于SQL LIKE匹配的布尔列,模糊匹配(%:0个,1个或多个,*:1个字符)。
> >>> df.filter(df.name.like('Al%')).collect()>> [Row(age=2, name=u'Alice')]startswith(*other*)> >>> df.filter(df.name.startswith('Al')).collect()>> [Row(age=2, name=u'Alice')]>> >>> df.filter(df.name.startswith('^Al')).collect()>> []
substr(startPos, length):返回一个列,它是该列的一个子字符串。startPos - 开始位置(int或者Column)。length - 子字符串的长度(int或者Column)
> >>> df.select(df.name.substr(1,3).alias("col")).collect()>> [Row(col=u'Ali'), Row(col=u'Bob')]
when(condition, value):评估条件列表并返回多个可能的结果表达式之一。 如果不调用Column.otherwise(),则不匹配条件返回None。
例如,请参阅pyspark.sql.functions.when()。
参数:
condition ——一个布尔列表达式。
value —— 一个文字值或一个列表达式。
> from pyspark.sql import functions as F>> df.select(df.name,F.when(df.age>4,1).when(df.age<3,-1).otherwise(0)).show()>> +-----+------------------------------------------------------------+>> | name|CASE WHEN (age > 4) THEN 1 WHEN (age < 3) THEN -1 ELSE 0 END|>> +-----+------------------------------------------------------------+>> |Alice| -1|>> | Bob| 1|>> +-----+------------------------------------------------------------+
5 Row
DataFrame中的一行。 其中的字段可以被访问:
像属性(row.key)
像字典值(行[键])
按键行将搜索行键。
Row行可以用来通过使用命名参数来创建一个行对象,这些字段将按名称排序。
不允许省略命名参数来表示值为None或者丢失。 在这种情况下,应将其明确设置为“无”。
> >>> row=Row(name="Alice",age=11)>> >>> row>> Row(age=11, name='Alice')>> >>> row['name'],row['age']>> ('Alice', 11)>> >>> row.name,row.age>> ('Alice', 11)>> >>> 'name' in row>> True>> >>> 'wrong_key' in row>> False
6 pyspark.sql.DataFrameReader
> >>> df=spark.read.format('json').load('python/test_support/sql/people.json')>> >>> df.dtypes>> [('age', 'bigint'), ('name', 'string')]
(1)format(source):指定输入数据源格式。
参数:source - 字符串,数据源的名称,例如 ‘json’,’parquet’。
(2)load(path=None, format=None, schema=None, **options)
从数据源加载数据并将其作为:classDataFrame返回。
参数:
path - 可选字符串或文件系统支持数据源的字符串列表。
format - 数据源格式的可选字符串。 默认为“镶木地板”。
schema - 输入模式的可选pyspark.sql.types.StructType。
options - 所有其他字符串选项
(3)直接spark.read.json的方法spark.read.csv 、spark.read.parquet和spark.read.text
> >>> df1=spark.read.json('python/test_support/sql/people.json')>> >>> df1.dtypes>> [('age', 'bigint'), ('name', 'string')]>> >>> rdd=sc.textFile('python/test_support/sql/people.json')>> >>> df2=spark.read.json(rdd)>> >>> df2.dtypes>> [('age', 'bigint'), ('name', 'string')]
(4)table(tableName):以DataFrame的形式返回指定的表。参数:tableName - 字符串,表的名称。
> >>> df = spark.read.parquet('python / test_support / sql / parquet_partitioned')>> #注册成一张表tmpTable>> >>> df.createOrReplaceTempView('tmpTable')>> >>> spark.read.table('tmpTable').dtypes>> [('name', 'string'), ('year', 'int'), ('month', 'int'), ('day', 'int')]
7 pyspark.sql.DataFrameWriter
> df.write.format('json').save(os.path.join(tempfile.mkdtemp(),'data'))>> df.write.json(os.path.join(tempfile.mkdtemp(),'data'))>> df.write.mode('append').parquet(os.path.join(tempfile.mkdtemp(),'data'))
**partitionBy(cols)
> **df.write.partitionBy('year', 'month').parquet(os.path.join(tempfile.mkdtemp(), 'data'))**
json(path, mode=None, compression=None, dateFormat=None, timestampFormat=None)
将DataFrame的内容以JSON格式(JSON行文本格式或换行符分隔的JSON)保存在指定的路径中。
Parameters:
path –任何Hadoop支持的文件系统中的路径
mode –指定数据已经存在时保存操作的行为。
append:追加此DataFrame的内容到现有的数据。
overwrite:覆盖现有数据。
ignore:如果数据已经存在,则默认忽略此操作。
error(默认情况下):如果数据已经存在,则抛出异常。
compression – 当保存到文件时使用压缩编解码器。 这可以是已知的不区分大小写缩写名称之一(none,bzip2,gzip,lz4,snappy和deflate)。
dateFormat – 设置指示日期格式的字符串。 自定义日期格式遵循java.text.SimpleDateFormat的格式。 这适用于日期类型。 如果设置为None,则使用默认值yyyy-MM-dd。
timestampFormat – 设置指示时间戳格式的字符串。 自定义日期格式遵循java.text.SimpleDateFormat的格式。 这适用于时间戳类型。 如果设置无,则使用默认值yyyy-MM-dd’T’HH:mm:ss.SSSXXX。
8 pyspark.sql.types
> pyspark.sql.types.NullType>> pyspark.sql.types.StringType>> pyspark.sql.types.BinaryType>> pyspark.sql.types.BooleanType>> pyspark.sql.types.DateType>> pyspark.sql.types.TimestampType>> pyspark.sql.types.DecimalType(*precision=10*, *scale=0*)>> pyspark.sql.types.DoubleType>> pyspark.sql.types.FloatType>> pyspark.sql.types.ByteType>> pyspark.sql.types.IntegerType>> pyspark.sql.types.LongType>> pyspark.sql.types.ShortType>> pyspark.sql.types.ArrayType(*elementType*, *containsNull=True*)
> pyspark.sql.types.StructField(*name*, *dataType*, *nullable=True*, *metadata=None*)>> StructType中的一个字段。>> 参数:>> **name** - 字符串,字段的名称。>> **dataType **- 字段的数据类型。>> **nullable** - 布尔值,该字段是否可以为null(None)。>> **metadata** - 从字符串字典到简单类型,可以自动内联到JSON
pyspark.sql.types.StructType(fields=None)
结构类型,由StructField的列表组成。这是表示一个行的数据类型。迭代一个StructType将迭代它的StructField。 一个包含:StructField类可以通过名字或者位置来访问。
> 一个关于 StructField和 StructType的实际应用案例>> rdd = sc.textFile('file:///root/ydzhao/Two_passengers_and_one_danger/20171219_20171219135232.txt',4)>> from datetime import datetime>> rdd_split= rdd.map(lambda x:(datetime.strptime(x.split("@@")[0], "%Y-%m-%d %H:%M:%S"),>> x.split("@@")[1],>> x.split("@@")[2],>> x.split("@@")[3],>> int(x.split("@@")[4])*0.000001,>> int(x.split("@@")[5])*0.000001,>> int(x.split("@@")[6]),>> int(x.split("@@")[7]),>> int(x.split("@@")[8]),>> x.split("@@")[9],>> int(x.split("@@")[10]),>> x.split("@@")[11],>> x.split("@@")[12]))>> from pyspark.sql.types import *>> schema = StructType([>> StructField("TimeStamp",TimestampType(),True),>> StructField("VehicleID",StringType(),True),>> StructField("VehiclePlateColor",StringType(),True),>> StructField("MessageSeq",StringType(),True),>> StructField("Lng",DoubleType(),True),>> StructField("Lat",DoubleType(),True),>> StructField("TerminalSpeed",IntegerType(),True),>> StructField("DrivingSpeed",IntegerType(),True),>> StructField("TotalMile",IntegerType(),True),>> StructField("Direction",StringType(),True),>> StructField("Altitude",IntegerType(),True),>> StructField("StatusBit",StringType(),True),>> StructField("AlarmStatus",StringType(),True)>> ])>> df2 = sqlContext.createDataFrame(rdd_split,schema)>> df2.registerTempTable("df2")>> df2.printSchema()>> root>> |-- TimeStamp: timestamp (nullable = true)>> |-- VehicleID: string (nullable = true)>> |-- VehiclePlateColor: string (nullable = true)>> |-- MessageSeq: string (nullable = true)>> |-- Lng: double (nullable = true)>> |-- Lat: double (nullable = true)>> |-- TerminalSpeed: integer (nullable = true)>> |-- DrivingSpeed: integer (nullable = true)>> |-- TotalMile: integer (nullable = true)>> |-- Direction: string (nullable = true)>> |-- Altitude: integer (nullable = true)>> |-- StatusBit: string (nullable = true)>> |-- AlarmStatus: string (nullable = true)
9 pyspark.sql.functions
pyspark.sql.functions.abs(*col*)pyspark.sql.functions.avg(*col*)pyspark.sql.functions.column(*col*)pyspark.sql.functions.col(*col*)pyspark.sql.functions.count(*col*)pyspark.sql.functions.asc(*col*):基于给定列名称的升序返回一个排序表达式
pyspark.sql.functions.addmonths(_start, months):返回开始后几个月的日期
> >>> df=spark.createDataFrame([('2015-04-08',)],['d'])>> >>> df.select(add_months(df.d,1).alias('d')).collect()>> [Row(d=datetime.date(2015, 5, 8))]
pyspark.sql.functions.dateadd(_start, days):返回开始后几天的日期
>>> df=spark.createDataFrame([('2015-04-08',)],['d'])>>> df.select(date_add(df.d,1).alias('d')).collect()[Row(d=datetime.date(2015, 4, 9))]
pyspark.sql.functions.approxcount_distinct(_col, rsd=None) :Spark 2.1后
pyspark.sql.functions.approxCountDistinct(col, rsd=None) :Spark1.6.2
> >>> df.agg(approx_count_distinct(df.age).alias('c')).collect()>> [Row(c=2)]
pyspark.sql.functions.array(*cols):创建一个新的数组列。
参数:cols - 具有相同数据类型的列名称列表(字符串)或列表达式列表。
> >>> df.select(array('age','age').alias("arr")).collect()>> [Row(arr=[2, 2]), Row(arr=[5, 5])]>> >>> df.select(array([df.age,df.age]).alias("arr")).collect()>> [Row(arr=[2, 2]), Row(arr=[5, 5])]
pyspark.sql.functions.bround(col, scale=0):如果scale> = 0,则使用HALF_EVEN舍入模式对给定值进行四舍五入以缩放小数点;如果scale <0,则将其舍入到整数部分。
>>> spark.createDataFrame([(2.5,)],['a']).select(bround('a',0).alias('r')).collect()[Row(r=2.0)]
(横向拼接)
pyspark.sql.functions.concat(*cols):将多个输入字符串列连接成一个字符串列。
> >>> df=spark.createDataFrame([('abcd','123')],['s','d'])>> >>> df.select(concat(df.s,df.d).alias('s')).collect()>> [Row(s=u'abcd123')]
pyspark.sql.functions.concatws(_sep, *cols):使用给定的分隔符将多个输入字符串列连接到一个字符串列中。
> >>> df=spark.createDataFrame([('abcd','123')],['s','d'])>> >>> df.select(concat_ws('-',df.s,df.d).alias('s')).collect()>> [Row(s=u'abcd-123')]
pyspark.sql.functions.countDistinct(col, *cols):返回col或col的不同计数的新列。
> >>> df.agg(countDistinct(df.age,df.name).alias('c')).collect()>> [Row(c=2)]>> >>> df.agg(countDistinct("age","name").alias('c')).collect()>> [Row(c=2)]
pyspark.sql.functions.current_date()
pyspark.sql.functions.current_timestamp()
pyspark.sql.functions.dateformat(_date, format):将日期/时间戳/字符串转换为由第二个参数给定日期格式指定格式的字符串值。一个模式可能是例如dd.MM.yyyy,可能会返回一个字符串,如“18 .03.1993”。 可以使用Java类java.text.SimpleDateFormat的所有模式字母。注意尽可能使用像年份这样的专业功能。
> >>> df=spark.createDataFrame([('2015-04-08',)],['a'])>> >>> df.select(date_format('a','MM/dd/yyy').alias('date')).collect()>> [Row(date=u'04/08/2015')]
pyspark.sql.functions.datediff(end, start)
> >>> df=spark.createDataFrame([('2015-04-08','2015-05-10')],['d1','d2'])>> >>> df.select(datediff(df.d2,df.d1).alias('diff')).collect()>> [Row(diff=32)]
pyspark.sql.functions.dayofmonth(col)
> >>> df=spark.createDataFrame([('2015-04-08',)],['a'])>> >>> df.select(dayofmonth('a').alias('day')).collect()>> [Row(day=8)]
pyspark.sql.functions.dayofyear(col)
> >>> df=spark.createDataFrame([('2015-04-08',)],['a'])>> >>> df.select(dayofyear('a').alias('day')).collect()>> [Row(day=98)]
pyspark.sql.functions.weekofyear(col)
> >>> df = spark.createDataFrame([('2015-04-08',)], ['a'])>> >>> df.select(weekofyear(df.a).alias('week')).collect()>> [Row(week=15)]
pyspark.sql.functions.decode(col, charset)
使用提供的字符集(“US-ASCII”,“ISO-8859-1”,“UTF-8”,“UTF-16BE”,“UTF-16LE”之一)从二进制计算第一个参数’UTF-16’)。
pyspark.sql.functions.encode(col, charset)
使用提供的字符集(“US-ASCII”,“ISO-8859-1”,“UTF-8”,“UTF-16BE”,“UTF-16LE”之一)从字符串中计算第一个参数,’UTF-16’)。
pyspark.sql.functions.exp(col)
pyspark.sql.functions.formatnumber(_col, d)
> 将数字X格式化为像'#, - #, - #.-'这样的格式,用HALF_EVEN舍入模式四舍五入到小数点后的位置,并将结果作为字符串返回。>> 参数:>> col - 要格式化的数值的列名>> d - N个小数位数>> >>> spark.createDataFrame([(5,)],['a']).select(format_number('a',4).alias('v')).collect()[Row(v=u'5.0000')]
pyspark.sql.functions.formatstring(_format, cols)*
> 以print样式格式化参数,并将结果作为字符串列返回。>> 参数:>> col - 要格式化的数值的列名>> d - N个小数位数>> >>> df=spark.createDataFrame([(5,"hello")],['a','b'])>> >>> df.select(format_string('%d %s',df.a,df.b).alias('v')).collect()>> [Row(v=u'5 hello')]
Unix时间格式转换为正常时间格式,很有用 pyspark.sql.functions.fromunixtime(_timestamp, format=’yyyy-MM-dd HH:mm:ss’) 将来自unix时期(1970-01-01 00:00:00 UTC)的秒数转换为以给定格式表示当前系统时区中该时刻的时间戳的字符串。 pyspark.sql.functions.unix_timestamp(timestamp=None, format=’yyyy-MM-dd HH:mm:ss’) 使用默认时区和默认语言环境,将具有给定模式的时间字符串(默认为’yyyy-MM-dd HH:mm:ss’)转换为Unix时间戳(以秒为单位),如果失败则返回null。 如果时间戳记为“无”,则返回当前时间戳。 pyspark.sql.functions.fromutc_timestamp(_timestamp, tz) 给定一个时间戳,对应于UTC中的某个特定时间,返回对应于给定时区中同一时间的另一个时间戳。
> >>> df=spark.createDataFrame([('1997-02-28 10:30:00',)],['t'])>> >>> df.select(from_utc_timestamp(df.t,"PST").alias('t')).collect()[Row(t=datetime.datetime(1997, 2, 28, 2, 30))]
pyspark.sql.functions.to_utc_timestamp(timestamp, tz)
> 给定一个时间戳,它对应于给定时区中的特定时间,返回对应于UTC中同一时间的另一个时间戳。>> >>> df = spark.createDataFrame([('1997-02-28 10:30:00',)], ['t'])>> >>> df.select(to_utc_timestamp(df.t, "PST").alias('t')).collect() [Row(t=datetime.datetime(1997, 2, 28, 18, 30))]
pyspark.sql.functions.todate(_col, format=None):使用可选的指定格式将pyspark.sql.types.StringType或pyspark.sql.types.TimestampType的列转换为pyspark.sql.types.DateType。 默认格式是’yyyy-MM-dd’。 根据SimpleDateFormats指定格式。Spark2.2新增功能
> >>> df=spark.createDataFrame([('1997-02-28 10:30:00',)],['t'])>> >>> df.select(to_date(df.t).alias('date')).collect()>> [Row(date=datetime.date(1997, 2, 28))]>> >>> df=spark.createDataFrame([('1997-02-28 10:30:00',)],['t'])>> >>> df.select(to_date(df.t,'yyyy-MM-dd HH:mm:ss').alias('date')).collect()[Row(date=datetime.date(1997, 2, 28))]
pyspark.sql.functions.trunc(date, format):返回截断到格式指定单位的日期。
> 参数:format - 'year','YYYY','yy'>> 'month','mon','mm'>> >>> df=spark.createDataFrame([('1997-02-28',)],['d'])>> >>> df.select(trunc(df.d,'year').alias('year')).collect()>> [Row(year=datetime.date(1997, 1, 1))]>> >>> df.select(trunc(df.d,'mon').alias('month')).collect()>> [Row(month=datetime.date(1997, 2, 1))]
pyspark.sql.functions.hour(col):将给定日期的小时数提取为整数。
> >>> df=spark.createDataFrame([('2015-04-08 13:08:15',)],['a'])>> >>> df.select(hour('a').alias('hour')).collect()>> [Row(hour=13)]
pyspark.sql.functions.minute(col):提取给定日期的分钟数为整数。
> >>> df=spark.createDataFrame([('2015-04-08 13:08:15',)],['a'])>> >>> df.select(minute('a').alias('minute')).collect()>> [Row(minute=8)]>> **pyspark.sql.functions.month(*col*):将给定日期的月份提取为整数。**>> >>> df=spark.createDataFrame([('2015-04-08',)],['a'])>> >>> df.select(month('a').alias('month')).collect()>> [Row(month=4)]
pyspark.sql.functions.second(col):将给定日期的秒数提取为整数。
> >>> df = spark.createDataFrame([('2015-04-08 13:08:15',)], ['a'])>> >>> df.select(second('a').alias('second')).collect()>> [Row(second=15)]
pyspark.sql.functions.year(col):将给定日期的年份提取为整数。
> >>> df = spark.createDataFrame([('2015-04-08',)], ['a'])>> >>> df.select(year('a').alias('year')).collect()>> [Row(year=2015)]
pyspark.sql.functions.initcap(col)
>>> spark.createDataFrame([('ab cd',)],['a']).select(initcap("a").alias('v')).collect()[Row(v=u'Ab Cd')]
pyspark.sql.functions.lower(col)
pyspark.sql.functions.upper(col)
pyspark.sql.functions.isnan(col):如果列是NaN,则返回true的表达式。
> >>> df=spark.createDataFrame([(1.0,float('nan')),(float('nan'),2.0)],("a","b"))>> >>> df.select(isnan("a").alias("r1"),isnan(df.a).alias("r2")).collect()>> [Row(r1=False, r2=False), Row(r1=True, r2=True)]
pyspark.sql.functions.isnull(col):如果列为空,则返回true的表达式。
> >>> df=spark.createDataFrame([(1,None),(None,2)],("a","b"))>> >>> df.select(isnull("a").alias("r1"),isnull(df.a).alias("r2")).collect()>> [Row(r1=False, r2=False), Row(r1=True, r2=True)]
pyspark.sql.functions.length(col):计算字符串或二进制表达式的长度。
>>> spark.createDataFrame([('ABC',)],['a']).select(length('a').alias('length')).collect()[Row(length=3)]
pyspark.sql.functions.lpad(col, len, pad):用pad左填充字符串列的宽度len。
> >>> df=spark.createDataFrame([('abcd',)],['s',])>> >>> df.select(lpad(df.s,6,'#').alias('s')).collect()>> [Row(s=u'##abcd')]
pyspark.sql.functions.rpad(col,len,pad):用pad右填充字符串列的宽度len。
> >>> df = spark.createDataFrame([('abcd',)], ['s',])>> >>> df.select(rpad(df.s, 6, '#').alias('s')).collect()>> [Row(s=u'abcd##')]
pyspark.sql.functions.ltrim(col):从左端修剪指定字符串值的空格。
> >>> df = spark.createDataFrame([(' abcd ',)], ['s',])>> >>> df.select(ltrim(df.s).alias('s')).collect()>> [Row(s=u'abcd ')]
pyspark.sql.functions.rtrim(col):从右端修剪指定字符串值的空格。
> >>> df = spark.createDataFrame([(' abcd ',)], ['s',])>> >>> df.select(rtrim(df.s).alias('s')).collect()>> [Row(s=u' abcd')]
pyspark.sql.functions.trim(col): 从左右端修剪指定字符串值的空格。
> >>> df = spark.createDataFrame([(' abcd ',)], ['s',])>> >>> df.select(trim(df.s).alias('s')).collect()>> [Row(s=u' abcd')]
pyspark.sql.functions.max(col) pyspark.sql.functions.mean(col) pyspark.sql.functions.min(col) pyspark.sql.functions.sum(col) pyspark.sql.functions.sumDistinct(col)
pyspark.sql.functions.round(col, scale=0):如果scale> = 0,则使用HALF_UP舍入模式对给定值进行四舍五入以缩放小数点;如果scale <0,则将其舍入到整数部分。
> >>> spark.createDataFrame([(2.5,)],['a']).select(round('a',0).alias('r')).collect()>> [Row(r=3.0)]
pyspark.sql.functions.skewness(col)
pyspark.sql.functions.sqrt(col)
pyspark.sql.functions.stddev(col)
pyspark.sql.functions.split(str, pattern):分割模式(模式是正则表达式)。这个很有用!!!
> >>> df=spark.createDataFrame([('ab12cd',)],['s',])>> >>> df.select(split(df.s,'[0-9]+').alias('s')).collect()>> [Row(s=[u'ab', u'cd'])]
pyspark.sql.functions.substring(str, pos, len):子字符串从pos开始,长度为len,当str是字符串类型或返回从字节pos开始的字节数组的片段,当str是二进制类型时,长度为len。
> >>> df = spark.createDataFrame([('abcd',)], ['s',])>> >>> df.select(substring(df.s, 1, 2).alias('s')).collect()>> [Row(s=u'ab')]
pyspark.sql.functions.struct(cols):*创建一个新的结构列。参数:cols - 列名称列表(字符串)或列表达式列表
> >>> df.select(struct('age','name').alias("struct")).collect()>> [Row(struct=Row(age=2, name=u'Alice')), Row(struct=Row(age=5, name=u'Bob'))]>> >>> df.select(struct([df.age,df.name]).alias("struct")).collect()>> [Row(struct=Row(age=2, name=u'Alice')), Row(struct=Row(age=5, name=u'Bob'))]
UDF(User Definition Function)
pyspark.sql.functions.udf(f=None, returnType=StringType):由于是自定义函数,尽量少用
创建一个表示用户定义函数(UDF)的列表达式。说明用户定义的函数必须是确定性的。 由于优化,可能会消除重复的调用,甚至可能会调用该函数的次数超过查询中的次数。
参数:如果用作独立函数,则使用f - python函数
returnType - 一个pyspark.sql.types.DataType对象
> from pyspark.sql.types import IntegerType>> slen=udf(lambdas:len(s),IntegerType())>> :udf>> def to_upper(s):>> if s is not None:>> return s.upper()>> :udf(returnType=IntegerType())>> def add_one(x):>> if x is not None:>> return x+1>> df=spark.createDataFrame([(1,"John Doe",21)],("id","name","age"))>> df.select(slen("name").alias("slen(name)"),to_upper("name"),add_one("age")).show()>> +----------+--------------+------------+>> |slen(name)|to_upper(name)|add_one(age)|>> +----------+--------------+------------+>> | 8| JOHN DOE| 22|>> +----------+--------------+------------+
pyspark.sql.functions.when(condition, value)
评估条件列表并返回多个可能的结果表达式之一。
如果不调用Column.otherwise(),则不匹配条件返回None。
参数:
condition - 一个布尔列表达式。
value - 一个文字值或一个列表达式。
> >>> df.select(when(df['age']==2,3).otherwise(4).alias("age")).collect()>> [Row(age=3), Row(age=4)]>> >>> df.select(when(df.age==2,df.age+1).alias("age")).collect()>> [Row(age=3), Row(age=None)]
pyspark.sql.functions.window(timeColumn, windowDuration, slideDuration=None, startTime=None)
Bucketize rows into one or more time windows given a timestamp specifying column. Window starts are inclusive but the window ends are exclusive, e.g. 12:05 will be in the window [12:05,12:10) but not in [12:00,12:05). Windows can support microsecond precision. Windows in the order of months are not supported.
The time column must be of pyspark.sql.types.TimestampType.
Durations are provided as strings, e.g. ‘1 second’, ‘1 day 12 hours’, ‘2 minutes’. Valid interval strings are ‘week’, ‘day’, ‘hour’, ‘minute’, ‘second’, ‘millisecond’, ‘microsecond’. If the slideDuration is not provided, the windows will be tumbling windows.
The startTime is the offset with respect to 1970-01-01 00:00:00 UTC with which to start window intervals. For example, in order to have hourly tumbling windows that start 15 minutes past the hour, e.g. 12:15-13:15, 13:15-14:15… provide startTime as 15 minutes.
The output column will be a struct called ‘window’ by default with the nested columns ‘start’ and ‘end’, where ‘start’ and ‘end’ will be of pyspark.sql.types.TimestampType.
在给定时间戳指定列的情况下,将行缩减为一个或多个时间窗口。窗口开始是包含的,但窗口结束是唯一的,例如, 12:05将在窗口[12:05,12:10],但不在[12:00,12:05]。 Windows可以支持微秒精度。按月份顺序的Windows不受支持。
时间列必须是pyspark.sql.types.TimestampType。
持续时间以字符串形式提供,例如“1秒”,“1天12小时”,“2分钟”。有效的时间间隔字符串为“星期”,“日”,“小时”,“分钟”,“秒”,“毫秒”,“微秒”。如果没有提供slideDuration,窗户将翻滚窗户。
startTime是1970-01-01 00:00:00 UTC的偏移量,用于启动窗口间隔。例如,为了使每小时开始15分钟的小时翻滚窗口,例如12:15-13:15,13:15-14:15提供15分钟的startTime。
输出列默认是一个名为’window’的结构,嵌套列’start’和’end’,其中’start’和’end’是pyspark.sql.types.TimestampType
>>> df=spark.createDataFrame([("2016-03-11 09:00:07",1)]).toDF("date","val")>>> w=df.groupBy(window("date","5 seconds")).agg(sum("val").alias("sum"))>>> w.select(w.window.start.cast("string").alias("start"),w.window.end.cast("string").alias("end"),"sum").collect()[Row(start=u'2016-03-11 09:00:05', end=u'2016-03-11 09:00:10', sum=1)

若有收获,就点个赞吧
0 人点赞
