测试时,我们使用jupyter notebook可以方便开发调试程序。但是,当我们实际生产过程中,需要执行一个计划作业时,该作业每小时都在运行,jupyter notebook就工作不了了。如何去利用可以重用的模块形式去编写脚本,打包好我们的Spark应用程序,直至最后提交Spark作业用于生产,这是需要我们掌握的一项技能。
1 spark-submit命令
# 一般级别的,语法如下:spark-submit [options] <python file> [app arguments]
提交作业到Spark的入口点(本地或集群)是spark-submit脚本,该脚本不仅可以提交作业,也可以终止作业或检查其状态。
spark-submit命令提供了一个统一的API把应用程序部署到各种Spark支持的集群管理器上(如YARN),从而免除了单独配置每个应用程序。
PySpark命令行参数
—master:用于设置主节点的URL参数。
(1)local 用于执行本地机器的代码。
如果你传递local参数,Spark会运行一个单一的线程(不会利用任何并行线程)。
在一个多核机器上,local[n]来为Spark指定一个具体使用的内核数,n指的是使用的内核数。
通过loacl[*]来制定运行和Spark机器内核一样多的复杂线程。
(2)spark://host:port 这是一个URL和一个Spark单机集群的端口(不运行任何作业调度,如Mesos或者Yarn)
(3)mesos://host:port 这是一个URL和一个部署在Mesos上的Spark集群端口
(4)yarn 作为一个负载均衡器,用于从运行Yarn的主节点提交作业。—deploy-mode:允许你决定是否在本地(使用client)启动Spark驱动程序的参数,或者在集群内(使用cluster)的任意一台机器上启动。此参数默认值为client。
—name:应用程序的名字,如果在创建SparkSession时,以编程方式指定应用程序名称,那么来自命令行的参数会被重写。
—py-files : .py、.egg或者.zip文件的逗号分隔列表,包括Python应用程序。这些文件将被交付给每一个执行器来使用。
—file :命令给出一个逗号分隔的文件列表,这些文件将被交付到每一个执行器来使用。
—conf : 参数通过命令行动态地更改应用程序的配置。语法是:
<Spark property>=<value for the property> 。例如:--conf spark.local.dir=/opt/Spark2.2.0/--conf spark.app.name=com.xxx.passengerflow.metro_jh
需要注意的是Spark有3个地方使用配置参数:
(1)最高优先级的是在SparkContext时,指定了SparkConf的参数获得最高优先权;
(2)第二优先权:spark-submit传递给的参数;
(3)第三优先权:conf/spark-default.conf文件中指定的参数。—properties-file :配置文件,它应该有和conf/spark-defaults.conf文件相同的属性设置,也是可读的。
—driver-memory:指定应用程序在驱动程序上分配多少内存的参数。允许的值有一个语法限制,类似于1000M,2G。默认值为1024M。
—executor-memory:参数指定每个执行器上为应用程序分配多少内存。默认值为1G。
—help:展示帮助信息和退出
—verbose:在运行应用程序时打印附加调试信息。
—version:打印spark版本
—driver-cores:(在spark单机cluster或者Yarn上部署cluster模式下),允许指定驱动程序的内核数量(默认值为1)
—kill:将完成的过程赋予submission_id
—status:如果指定了该命令,它将请求指定的应用程序的状态。
—total-executor-cores:(在spark单机或Mesos client部署模式下)该参数会为所有执行器(不是每一个)请求指定的内核数量。
在YARN集群提交时可以指定的:
—queue:该参数指定了YARN上的队列,以便于将该作业提交到队列(默认值是default)
—num-executors:指定需要多个执行器来请求该作业的参数。如果启动了动态分配,则执行器的初始数量至少是指定的数量。
2 以编程方式部署应用程序
如何创建和配置SparkSession?
如何对Spark使用外部模块?
2.1 配置你的SparkSession(或者sc)
以编程方式使用Jupyter和提交作业的主要区别是,你必须创建Spark context上下文背景环境,而使用Jupyter运行Spark,上下文背景会自动开始。
2.2 创建SparkSession
Spark2.2.0
from pyspark.sql import SparkSessionspark = SparkSession \.builder \.appName('CalculatingGeoDistances') \.getOrCreate()print('Session created')如果此时你想创建一个SparkContext,可以直接使用:sc = spark.SparkContext
Spark1.6.2
from pyspark import SparkContextsc = SparkContext \.builder \.appName('CalculatingGeoDistances') \.getOrCreate()print('sc created')
2.3 模块化代码(重要重要!!!)
以模块化的形式构建代码,以便于以后重用该代码是一件值得做的事情。
例子:建立一个模块,并且在数据集上做一些计算,计算出上车和下车位置的直线距离(英里),并且将英里转换为公里。
(1)模块结构
在Python包的结构中,在顶层有一个setup.py文件,所以可以打包我们的模块。
setup.py文件内容如下:
from setuptools import setupsetup(name='PySparkUtilities',version='0.1dev',packages=['utilities', 'utilities/converters'],license='''Creative CommonsAttribution-Noncommercial-Share Alike license''',long_description='''An example of how to package code for PySpark''')
关于如何定义其他项目的setup.py文件,可以参考:
https://pythonhosted.org/an_example_pypi_project/setuptools.html
init.py文件内容如下:
from .geoCalc import geoCalc__all__ = ['geoCalc','converters']
(2)计算两点之间的距离
该代码位于该模块的geoCalc.py文件中
import mathclass geoCalc(object):@staticmethoddef calculateDistance(p1, p2):'''calculates the distance using Haversine formula'''R = 3959 # earth's radius in miles# get the coordinateslat1, lon1 = p1[0], p1[1]lat2, lon2 = p2[0], p2[1]# convert to radiansdeltaLat_radians = math.radians(lat2-lat1)deltaLon_radians = math.radians(lon2-lon1)lat1_radians = math.radians(lat1)lat2_radians = math.radians(lat2)# apply the formulahav = math.sin(deltaLat_radians / 2.0) * \math.sin(deltaLat_radians / 2.0) + \math.sin(deltaLon_radians / 2.0) * \math.sin(deltaLon_radians / 2.0) * \math.cos(lat1_radians) * \math.cos(lat2_radians)dist = 2 * R * math.asin(math.sqrt(hav))return distif __name__ == '__main__':p1 = {'address': '301 S Jackson St, Seattle, WA 98104','lat': 47.599200,'long': -122.329841}p2 = {'address': 'Thunderbird Films Inc 533, Smithe St #401, Vancouver, BC V6B 6H1, Canada','lat': 49.279688,'long': -123.119190}print(geoCalc.calculateDistance((p1['lat'], p1['long']), (p2['lat'], p2['long'])))
calculateDistance()是geoCalc类的静态方法,它需要两个地理位置,表示为一个元祖或者一个具有两个元素的列表(按照顺序排列的维度和经度),并且使用Haversine公式计算距离(英里)。
(3)转变距离单位
为了便于使用,作为converter实现的任何类都应该公开类似的窗口,查看base.py文件内容:
from abc import ABCMeta, abstractmethodclass BaseConverter(metaclass=ABCMeta):@staticmethod@abstractmethoddef convert(f, t):raise NotImplementedErrorif __name__ == '__main__':i = BaseConverter()
distance.py内容:
from ..base import BaseConverterclass metricImperial(BaseConverter):pass@staticmethoddef convert(f, t):conversionTable = {'in': {'mm': 25.4, 'cm': 2.54, 'm': 0.0254,'km': 0.0000254}, 'ft': {'mm': 304.8, 'cm': 30.48, 'm': 0.3048,'km': 0.0003048}, 'yd': {'mm': 914.4, 'cm': 91.44, 'm': 0.9144,'km': 0.0009144}, 'mile': {'mm': 1609344, 'cm': 160934.4, 'm': 1609.344,'km': 1.609344}}f_val, f_unit = f.split(' ')f_val = float(f_val)if f_unit in conversionTable.keys():if t in conversionTable[f_unit].keys():conv = 1 / conversionTable[f_unit][t]else:raise KeyError('Key {0} not found...' \.format(t))elif t in conversionTable.keys():if f_unit in conversionTable[t].keys():conv = conversionTable[t][f_unit]else:raise KeyError('Key {0} not found...' \.format(f_unit))else:raise KeyError('Neither {0} nor {1} key found'\.format(t, f_unit))return f_val / convif __name__ == '__main__':f = metricImperial()print(f.convert('10 mile', 'km'))
(4)打包:创建一个egg文件
PySpark文档指出,可以用逗号来分隔传递.py文件给spark-submit脚本。其实最方便的是把模块打包进一个.zip或者一个.egg。当setup.py文件方便使用时,调用additionalCode文件夹里的内容:
python setup.py bdist_egg
可以看到3个文件夹:PySparkUtilities.egg-info、build和dist
dist文件夹有:PySparkUtilities-0.1.dev0-py3.5.egg
(5)Spark中用户定义函数
为了对在PySpark中的DataFrame执行操作,有两个选择:使用内置函数来处理数据(大多数情况下都足以达到你的需求,且作为更高性能的代码而被推荐使用);但是有的时候需要自定义函数去实现若干功能选项。
为了定义一个UDF,必须把Python函数封装在.udf()方法中,并且定义它的返回值类型。以下是我们如何在脚本中实现
calculatingGeoDistance.py文件
import utilities.geoCalc as geofrom utilities.converters import metricImperialfrom pyspark.sql import SparkSessionfrom pyspark.sql.types import *import pyspark.sql.functions as funcdef geoEncode(spark):# read the data inuber = spark.read.csv('uber_data_nyc_2016-06_3m_partitioned.csv',header=True,inferSchema=True)\.repartition(4) \# .select('VendorID','tpep_pickup_datetime', 'pickup_longitude', 'pickup_latitude','dropoff_longitude','dropoff_latitude','total_amount')# prepare the UDFsgetDistance = func.udf(lambda lat1, long1, lat2, long2:geo.calculateDistance((lat1, long1),(lat2, long2)))convertMiles = func.udf(lambda m:metricImperial.convert(str(m) + ' mile', 'km'))# create new columnsuber = uber.withColumn('miles',getDistance(func.col('pickup_latitude'),func.col('pickup_longitude'),func.col('dropoff_latitude'),func.col('dropoff_longitude')))uber = uber.withColumn('kilometers',convertMiles(func.col('miles')))# print 10 rows# uber.show(10)# save to csv (partitioned)uber.write.csv('uber_data_nyc_2016-06_new.csv',mode='overwrite',header=True,compression='gzip')if __name__ == '__main__':spark = SparkSession \.builder \.appName('CalculatingGeoDistances') \.getOrCreate()print('Session created')try:geoEncode(spark)finally:spark.stop()
2.4 提交作业
可以在命令行键入以下命令:
./launch_spark_submit.sh \--master local[4] \--py-files additionalCode/dist/PySparkUtilities-0.1.dev0-py3.5.egg \calculatingGeoDistance.py
其中launch_spark_submit.sh是spark-submit命令的封装,通过对jupyter设置了PYSPARK_DRIVER_PYTHON系统变量:
#!/bin/bashunset PYSPARK_DRIVER_PYTHONspark-submit $*export PYSPARK_DRIVER_PYTHON=jupyter
2.5 实际项目中,spark-submit的设置和打包
(1)命令行模式
集群模式:
读取的文件必须放在HDFS上:
spark-submit --master yarn \--deploy-mode cluster \--num-executors 25 \--executor-cores 2 \--driver-memory 4g \--executor-memory 4g \--conf spark.broadcast.compress=true \--jars "/data/spark/ojdbc6-11.2.0.3.jar" com.meihuichina.passengerflow.grid1km_laccell_grid100m.py > /home/ydzhao/log/.out 2>&1
(2)单节点模式
单节点启动PySpark Shell
(1)pyspark --jars "/data/spark/ojdbc6-11.2.0.3.jar"(2)pyspark --jars "/data/spark/ojdbc6-11.2.0.3.jar" \--num-executors 25 \--executor-cores 2 \--driver-memory 4g \--executor-memory 8g
单节点提交任务
spark-submit --jars "/data/spark/ojdbc6-11.2.0.3.jar" /pyspark_app/test.py./bin/spark-submit --master lcoal[*] /home/ydzhao/pyspark_app/com.meihuichina.passengerflow.grid1km_laccell_grid100m.py
(3)编辑打包成test.sh Shell脚本
#!/usr/bin/env bashspark-submit --master yarn \--deploy-mode cluster \--num-executors 25 \--executor-cores 2 \--driver-memory 4g \--executor-memory 4g \--conf spark.broadcast.compress=true \--conf spark.yarn.executor.memoryOverhead=900 \--conf spark.sql.shuffle.partitions=20 \--jars "/data/spark/ojdbc6-11.2.0.3.jar" com.meihuichina.passengerflow.grid1km_laccell_grid100m.py > /home/ydzhao/log/.out 2>&1# ./test.sh# 给test.sh相关权限chmod u+x test.sh
运行test.sh
./test.sh
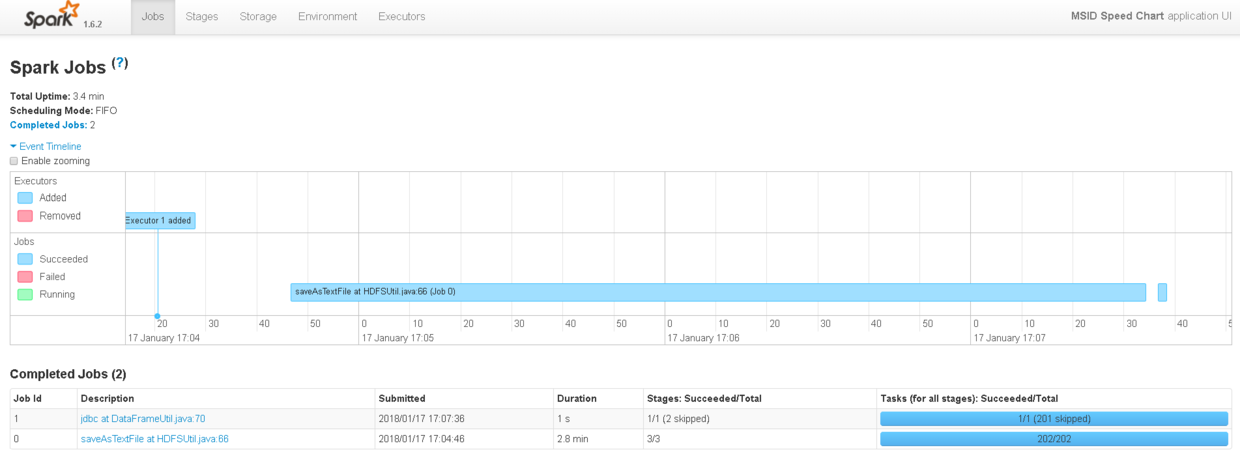
2.6 监控执行

3 PySpark实例——Spark On YARN将HDFS的数据写入Redis
首先把redis包引入工程,这样就不需要在集群里每台机器上安装redis客户端了。
$pip install redis$cd /usr/local/lib/python3.4/dist-packages$zip -r redis.zip redis/*$hadoop fs -put redis.zip /user/data/
然后就可以在代码里使用 addPyFile加载redis.zip了。

运行:$SPARK_HOME/bin/spark-submit--conf spark.yarn.submit.waitAppCompletion=true--master yarn-cluster--num-executors 4--driver-memory 32G--executor-memory 32G--executor-cores 4--queue root.default/opt/spark_redis.py

若有收获,就点个赞吧
0 人点赞
