函数
1、内置函数
数学
SELECT ABS(-1); -- 1SELECT ABS(3); -- 3SELECT CEIL(1.23); -- 2SELECT CEIL(1.9); -- 2SELECT FLOOR(1.23); -- 1SELECT FLOOR(1.93); -- 1SELECT MOD(1,3); -- 1SELECT MOD(2,8); -- 2 2/8的余数SELECT MOD(3,1) -- 0SELECT PI(); -- 3.141593SELECT RAND(); -- 其中一次的随机值为 0.34172691809174316SELECT round(1.5); -- 2SELECT round(1.25); -- 1SELECT round(1.2355555, 3); -- 1.236SELECT round(1, 3); -- 1 // 整数即使传了第二个参数也是保留整数, 不会补足小数SELECT TRUNCATE(1.3234234,4); -- 1.3234SELECT TRUNCATE(34,4); -- 34 // 不会补足小数
聚合
聚合函数,查表用
特点,就像一个汇总,所有的行都会汇聚到一行。这样得到的结果表就不能查其他列了。
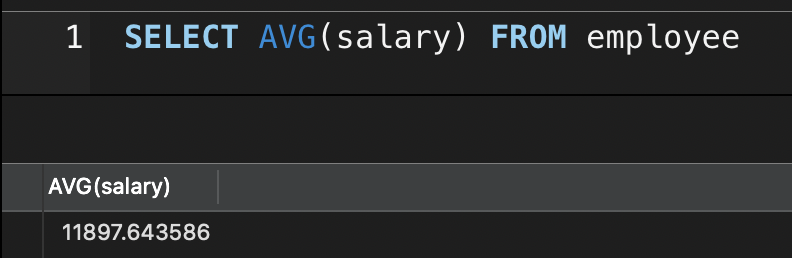
AVG() 平均值
SELECT AVG(salary) FROM employee;-- 别名定义SELECT AVG(salary) AS '平均薪资' FROM employee;
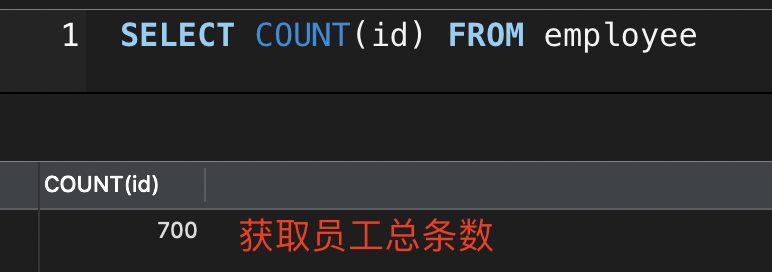
 COUNT() 计算非NULL个数
COUNT() 计算非NULL个数
SELECT COUNT(id) FROM employee; -- 查出employee.id不为NULL的总数SELECT COUNT(*) FROM employee; -- 【不推荐写法】* 的查法,就是先把employee表查出来,然后看这个表的每一行,只要每一行中至少一个单元格不为NULL,就算一个数。
MIN() 最小值获取
SELECT min(salary) FROM employee;
MAX() 最小值获取
SELECT MAX(salary) FROM employee;
SUM() 求和
SELECT SUM(salary) FROM employee;
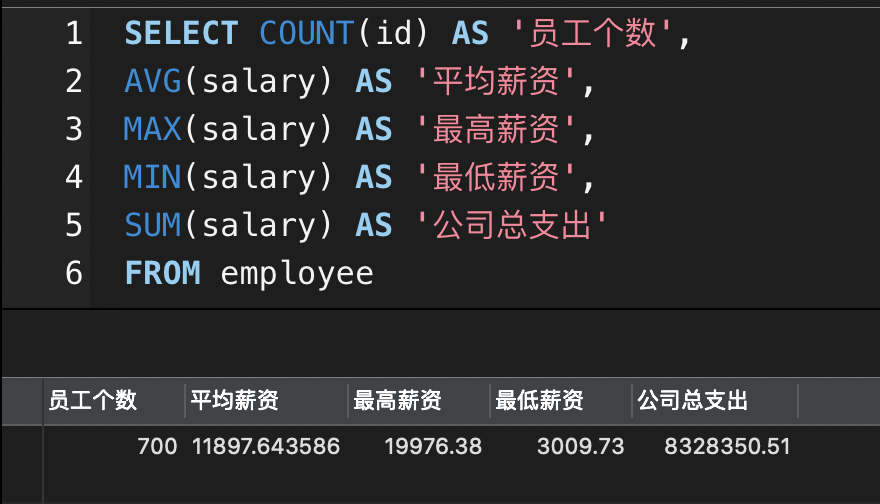
多个聚合查询
SELECT COUNT(id) AS '员工个数',AVG(salary) AS '平均薪资',MAX(salary) AS '最高薪资',MIN(salary) AS '最低薪资',SUM(salary) AS '公司总支出'FROM employee;
字符
CONCAT()
SELECT CONCAT(`name`, '_', id, '_', location) FROM employee; -- 涂萌紫_2_人民北路
CONCAT_WS()
SELECT CONCAT_WS('/',`name`, location, salary) FROM employee; -- 涂萌紫/人民北路/14684.16
TRIM()
SELECT TRIM(' bar ');SELECT TRIM(LEADING 'x' FROM 'xxxbarxxx'); -- 删除指定的首字符x,得到「barxxx」SELECT TRIM(BOTH 'x' FROM 'xxxbarxxx'); -- 删除指定的首尾字符 x, 得到「bar」SELECT TRIM(TRAILING 'xyz' FROM 'barxxyz'); -- 删除指定的尾字符 x, 得到「barx」
LTRIM()
SELECT LTRIM(' guo '); -- 得到‘guo ’
RTRIM()
SELECT RTRIM(' guo '); -- 得到‘ guo’
日期
CURDATE()、CURRENT_DATE()
SELECT CURRENT_DATE(); -- 2021-01-19 得到今天
CURTIME()、CURRENT_TIME()
SELECT CURTIME(); -- 22:08:12 得到当前时间点
TIMESTAMPDIFF()
SELECT TIMESTAMPDIFF(MICROSECOND, '2019-2-25', '2021-1-19'); -- 相差毫秒值 59961600000000SELECT TIMESTAMPDIFF(SECOND, '2019-2-25', '2021-1-19'); -- 相差秒值 59961600SELECT TIMESTAMPDIFF(MINUTE, '2019-2-25', '2021-1-19'); -- 相差分钟值 999360SELECT TIMESTAMPDIFF(HOUR, '2019-2-25', '2021-1-19'); -- 相差小时值 16656SELECT TIMESTAMPDIFF(DAY, '2019-2-25', '2021-1-19'); -- 相差天数 694SELECT TIMESTAMPDIFF(WEEK, '2019-2-25', '2021-1-19'); -- 相差周 99SELECT TIMESTAMPDIFF(MONTH, '2019-2-25', '2021-1-19'); -- 相差月 22SELECT TIMESTAMPDIFF(QUARTER, '2019-2-25', '2021-1-19'); -- 相差季度 7SELECT TIMESTAMPDIFF(YEAR, '2019-2-25', '2021-1-19'); -- 相差年 1
应用
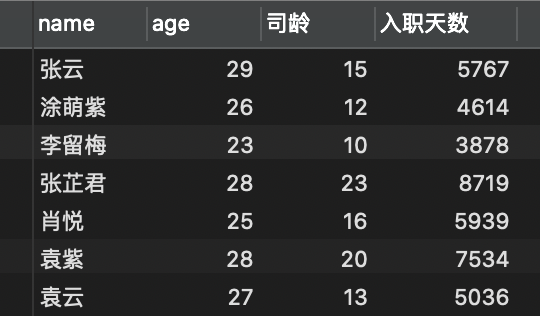
年龄、司龄、入职天数等跟日期相关的查询
SELECT `name`,TIMESTAMPDIFF(year, birthday, CURRENT_DATE) AS 'age',TIMESTAMPDIFF(year, joinDate, CURRENT_DATE) AS '司龄',TIMESTAMPDIFF(day, joinDate, CURRENT_DATE) AS '入职天数'FROM employee;
2、自定义函数
不讲了,自己学
分组【扩展】
用于比较复杂的查询场景。
但是注意,分组后,只能查询分组的列和聚合列
GROUP BY
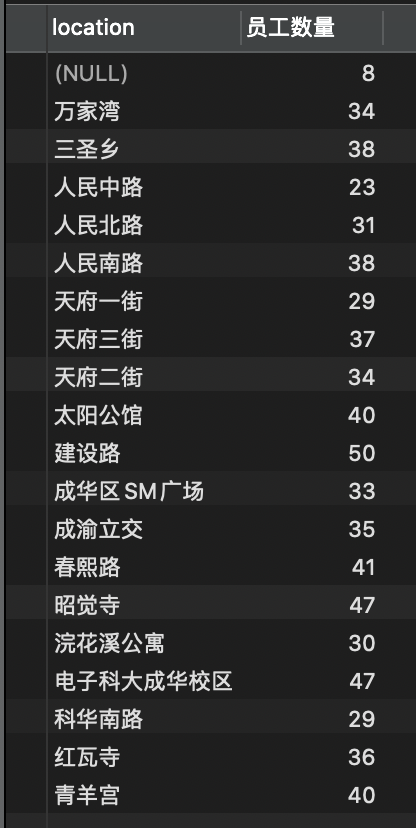
查询员工分布的居住地,以及每个居住地有多少名员工
-- 查询员工分布的居住地,以及每个居住地有多少名员工SELECT location, -- 分组后,只能查询分组的列和聚合列COUNT(id) AS '员工数量' -- 聚合列FROM employeeGROUP BY locationORDER BY location;
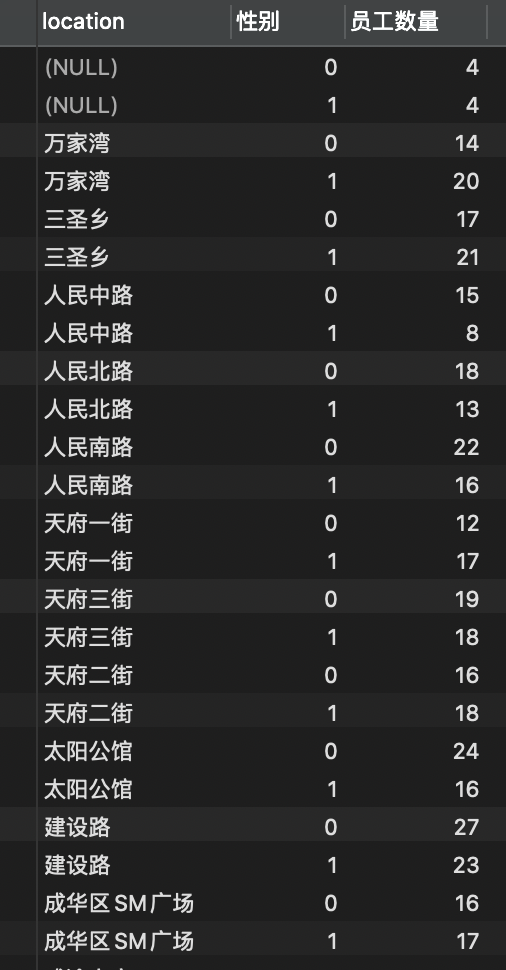
按照居住地、性别进行分组和查询
-- 可以按照多列分组、这种情况下,也就可以查分组的多列SELECT location, ismale, -- 多列查询COUNT(id) AS '员工数量'FROM employeeGROUP BY location, ismale -- 多列分组ORDER BY location;
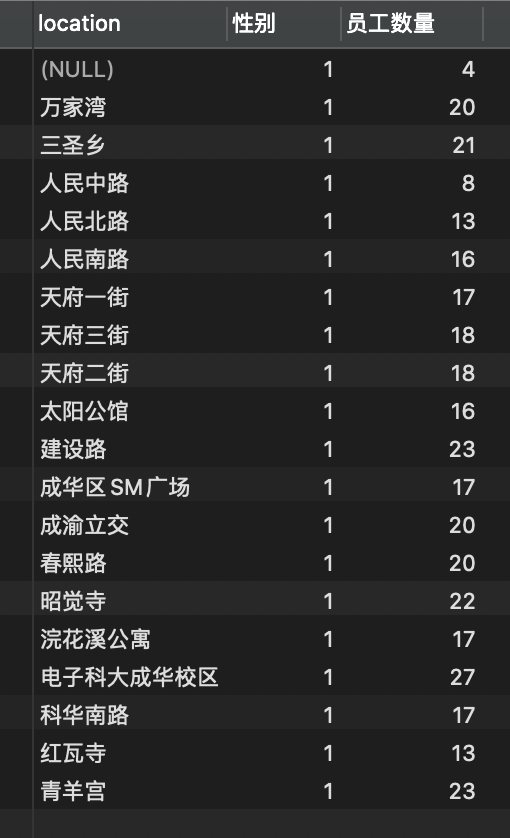
HAVING
在GROUP BY分组的基础上进行筛选
-- 查询员工分布的居住地、性别,以及每个居住地不同性别有多少名员工SELECT location, ismale,COUNT(id) AS '员工数量'FROM employeeGROUP BY location, ismaleHAVING ismale = 1 -- 分组后进行筛选,只展示男员工ORDER BY location;
HAVING可以使用SELECT的别名
- 根据数据库而定,有的数据库不支持(因为having的顺序滞后于select)
- having 过滤未分组的字段是不支持的。
-- 查询员工分布的居住地、性别,以及每个居住地不同性别有多少名员工SELECT location,ismale AS sex, -- 定义别名「sex」COUNT(id) AS '员工数量'FROM employeeGROUP BY location, ismaleHAVING sex = 1 -- 使用别名进行筛选-- HAVING id > 10 -- 这样写报错,因为id没有被分组ORDER BY location;
运行顺序:
注意:不同的数据库对于HAVING的处理不同,执行顺序不同。有的是放在SELECT之前,有的是之后。HAVING + WHERE
SELECT location,ismale AS sex,COUNT(id) AS '员工数量'FROM employeeWHERE location LIKE '%天府%'GROUP BY location, ismaleHAVING sex = 1ORDER BY location;
练习题
1. 查询渡一每个部门的员工数量
SELECT d.name AS '所属部门',COUNT(e.id) AS '员工数量'FROM employee AS eINNER JOIN department AS d ON e.deptId = d.idinner JOIN company AS c ON d.companyId = c.idWHERE c.`name` LIKE '%渡一%'GROUP BY d.name;
老师
SELECT d.`name`, COUNT(e.id) AS numberFROM company as c INNER JOIN department as d on c.id = d.companyIdINNER JOIN employee as e on d.id = e.deptIdWHERE c.`name` LIKE '%渡一%'GROUP BY d.id, d.`name`
2. 查询每个公司的员工数量
-- 我这里根据原题做了进一步的扩展:根据性别进行了分组SELECT c.name AS '企业',CASE e.ismaleWHEN 1 THEN '男'ELSE '女'END '性别',COUNT(e.id) AS '员工数量'FROM employee AS eINNER JOIN department AS d ON d.id = e.deptIdINNER JOIN company AS c ON c.id = d.companyIdGROUP BY c.name, e.ismale
老师
SELECT c.`name`, COUNT(e.id) AS numberFROM company as c INNER JOIN department as d on c.id = d.companyIdINNER JOIN employee as e on d.id = e.deptIdGROUP BY c.id, c.`name`
3. 查询所有公司五年内入职的居住在万家湾的女员工数量
按照下图的思路往下写,报错了,说什么不在子句中。。。1055 -表达式#1的SELECT列表不在GROUP BY子句中,包含非聚合列’company.e。id’在功能上不依赖于GROUP BY子句中的列;与sql_mode=only_full_group_by, Time: 0.00000不兼容
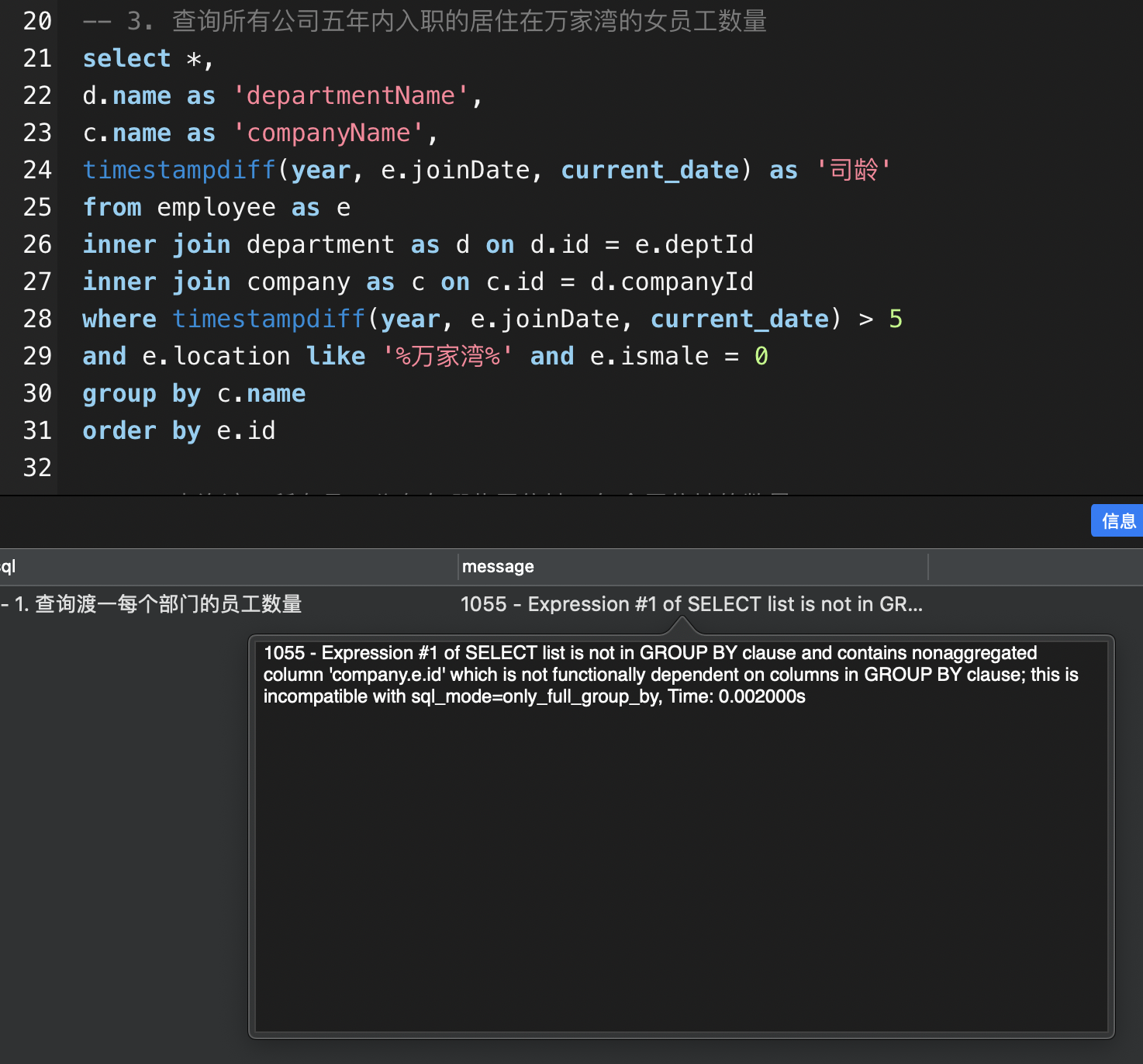
SELECT companyName AS '企业名称',COUNT(result_table.id) AS '员工数量'FROM (-- SQL子句select e.id,e.location, e.ismale,-- d.name as 'departmentName',c.name as 'companyName',timestampdiff(year, e.joinDate, current_date) as '司龄'from employee as einner join department as d on d.id = e.deptIdinner join company as c on c.id = d.companyIdwhere timestampdiff(year, e.joinDate, current_date) > 5and e.location like '%万家湾%' and e.ismale = 0order by e.id) as result_tablegroup by result_table.companyName
老师
第一种方法:查出来的之后有数据的公司,没数据的公司不展示(where那里筛选掉了)
SELECT c.`name`, COUNT(e.id) AS 数量FROM company as c INNER JOIN department as d on c.id = d.companyIdINNER JOIN employee as e on d.id = e.deptIdWHERE TIMESTAMPDIFF(YEAR, e.joinDate, CURDATE()) <= 6 -- 20年卡5,21年卡6AND e.location LIKE '%万家湾%'AND e.ismale = 0GROUP BY c.id, c.`name`
期望没数据的公司,number列展示0。于是需要用子句
SELECT company.`name`,-- 当显示null时换成0CASEWHEN result_table.number IS NULL THEN0ELSEresult_table.numberEND AS 符合条件的员工数量-- 将上边的结果表当成一张表,左连接到company表。FROM company LEFT JOIN (SELECT c.id, c.`name`, COUNT(e.id) AS numberFROM company as c INNER JOIN department as d on c.id = d.companyIdINNER JOIN employee as e on d.id = e.deptIdWHERE TIMESTAMPDIFF(YEAR, e.joinDate, CURDATE()) <= 6 -- 20年卡5,21年卡6AND e.location LIKE '%万家湾%'AND e.ismale = 0GROUP BY c.id, c.`name`) AS result_table ON result_table.id = company.id
4. 查询渡一所有员工分布在哪些居住地,每个居住地的数量
SELECT location AS '居住地',COUNT(location) AS '居住人数',-- companyName AS '企业名称'FROM (-- SQL子句select e.id, e.location,c.name as 'companyName'from employee as einner join department as d on d.id = e.deptIdinner join company as c on c.id = d.companyIdwhere c.name like '%渡一%') as result_tableGROUP BY location,companyName
老师
SELECT e.location, COUNT(e.id) AS numberFROM company AS c INNER JOIN department AS d ON c.id = d.companyIdINNER JOIN employee AS e ON d.id = e.deptIdWHERE c.`name` LIKE '%渡一%'GROUP BY e.location
5. 查询员工人数大于200的公司信息
SELECT c2.*FROM (-- -- SQL子句select c.idfrom employee as einner join department as d on d.id = e.deptIdinner join company as c on c.id = d.companyIdGROUP BY c.idHAVING count(e.id) > 200) AS result_tableINNER JOIN company AS c2 ON c2.id = result_table.id
老师
在第二题的基础上,加上having过滤即可
SELECT c.`name`, COUNT(e.id) AS numberFROM company as c INNER JOIN department as d on c.id = d.companyIdINNER JOIN employee as e on d.id = e.deptIdGROUP BY c.id, c.`name`HAVING number > 200
但是这样查出来的表,只显示了公司的名称,不显示其他详细信息。
期望和第三题一样做一个子句查询,补充公司的数据
SELECT * FROM companyWHERE id in (SELECT c.idFROM company as c INNER JOIN department as d on c.id = d.companyIdINNER JOIN employee as e on d.id = e.deptIdGROUP BY c.id, c.`name`HAVING COUNT(e.id) >= 200)
6. 查询渡一公司里比他平均工资高的员工
SELECT e2.id,e2.`name`,salary,result_table.name AS 'company',avgSalaryFROM (-- SQL子句select c.id, c.`name`, AVG(e.salary) as avgSalaryfrom employee as einner join department as d on d.id = e.deptIdinner join company as c on c.id = d.companyIdwhere c.name like '%渡一%'GROUP BY c.id, c.`name`) AS result_tableINNER JOIN employee AS e2WHERE e2.salary > avgSalaryORDER BY e2.salary
老师
SELECT e.*FROM company as c INNER JOIN department as d on c.id = d.companyIdINNER JOIN employee as e on d.id = e.deptIdWHERE c.`name` LIKE '%渡一%' ANDe.salary > (-- 子句SELECT avg(e.salary)FROM company as c INNER JOIN department as d on c.id = d.companyIdINNER JOIN employee as e on d.id = e.deptIdWHERE c.`name` LIKE '%渡一%')ORDER BY e.salary
7. 查询渡一所有名字为两个字和三个字的员工对应人数
-- 写不出来。。
老师:
SELECT CHAR_LENGTH(e.`name`) as 姓名长度, COUNT(e.`name`) as 员工数量FROM company as c INNER JOIN department as d on c.id = d.companyIdINNER JOIN employee as e on d.id = e.deptIdWHERE c.`name` LIKE '%渡一%'GROUP BY CHAR_LENGTH(e.`name`) -- 按照姓名长度分组HAVING 姓名长度 in (2,3) -- 这里要么写聚合,要么写别名,已经娶不到e.`name`了
8. 查询每个公司每个月的总支出薪水,并按照从低到高排序
SELECT companyId, companyName, SUM(salary) as salaryFROM three_table_join -- 用了视图GROUP BY companyId, companyNameORDER BY salary
老师:
SELECT c.`id`, c.`name`, SUM(e.salary) AS sumSalaryFROM company as c INNER JOIN department as d on c.id = d.companyIdINNER JOIN employee as e on d.id = e.deptIdGROUP BY c.`name`, c.idORDER BY sumSalary -- ORDER BY 顺序最后,所以需要别名

若有收获,就点个赞吧
0 人点赞
