速查表
常用元字符
| 代码 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
常用限定符
| 代码/语法 | 说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
常用反义词
| 代码/语法 | 说明 |
|---|---|
| \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |
转义字符(反斜杠\):
在正则中匹配特殊字符记得加转义符号,不然报错。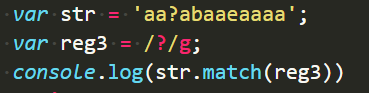


元字符
在引号字符串里边添加特殊字符
- 字符串换行符new line:\n
- 行结束符(回车符) return:\r
按回车键,在底层操作系统里正常情况下,一个回车代表的是 \r\n
但是在Linux里边就只有\n 没有\r
- 空格符 space:就是用空格键打一个空格即可
- 缩进/制表符tab:\t
是table或tab的缩写,一个缩进4个空格(依据操作系统的设定)
- 垂直制表符vertical tab:\v
- 换页符form feed: \f
测验:
console打印效果
可见,\n和\r\n在字符串强制换行中还是很有作用的。
但是document写到页面中谁也不起作用:
多行字符串:

字符串方法
match
str.match(reg)
特点:
- 返回结果是数组
- 有length
- 原型指向Array
- 不加g,如果匹配成功只返回一个,且返回结果的模式和exec返回的一样,一个伪数组

- 加g,如果匹配成功多个,就返回多个数组项,一个纯数组
- 把符合条件的字符片段全匹配出来并返回给你。比true和false更直观。
- 而且还能告诉你到底匹配了多少个。更直观一些。
- 在有反向引用和子表达式的时候:
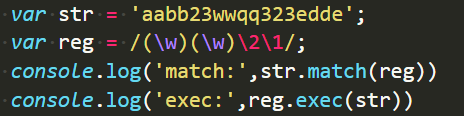
不加g时,match返回结果和exec无差: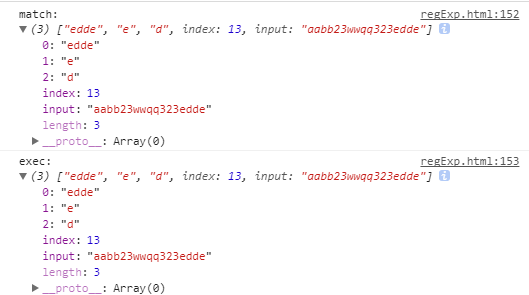

search
- 返回匹配到的字符片段所在的位置
- 如果没有匹配到字符片段,返回 -1
- 和lastIndex没有关系,不跟随游标的改变而改变返回的值。
有匹配结果时的正常情况,案例同上:

修改成匹配不到的情况: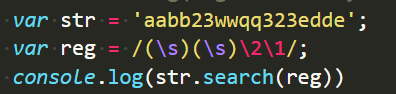
此时返回结果为-1:
split
传参除了字符串,还可以填正则表达式。
把字符串里边的数字全部切割完:
这里注意如果有子表达式,返回结果里还会有子表达式:
同上案例,只是多加了一个看似“无关紧要”的小括号,结果缺大跌眼镜:
replace
特点:
- 两个参数
- 第一个参数是要被替换掉的
- 可以传字符串或者正则规则
- 传字符串,只能改变一个,没有访问全局的能力
- 传正则,可以全局替换【全局是正则里边有全局替换修饰符g】。
- 第二个参数是替身本人,一定要是字符串,如果是其他,系统内部转成字符串。
- 第二个参数可以反向引用:$1、$2
- 第二个参数可以是回调函数,且匹配几次,回调就会触发几次。
- 不改变源字符串
正常应用:将一个字符片段替换成另一个字符片段:

只能替换一处,没有访问全局的能力。
第一个参数传正则规则:
用正则,让所有的数字替换成”锋”字。这也是强大之处——全局替换,让整个字符串中,所有符合条件的字符片段全部替换。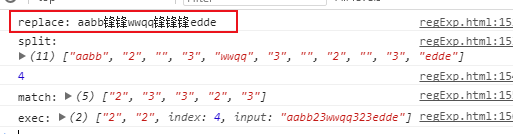
通过下边几条也可以看出来,是不改变源字符串的。
尝试,第二个参数传正则规则: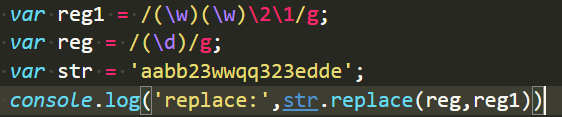
车祸了:直接把第二个正则当做的字符串处理。
第二个参数反向引用:
使用”$”
- $1 : 表示reg第一个子表达式里的内容
- $2 : 表示reg第二个子表达式里的内容
- $n : 以此类推…
将匹配出的字符串翻转
方法1,利用 “$” 拼接字符串
var str = ‘xxyy’;
var reg = /(\w)\1(\w)\2/g;
console.log(str.match(reg))
console.log(str.replace(reg,’$2$2$1$1’))
console.log(str.replace(reg,’$2$2-$1$1’))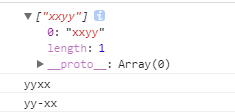
结果: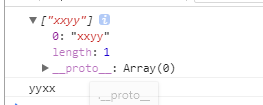
方法2,强大的回调函数:
- 系统自动给我们调用
- 匹配不到的时候,不自动调用回调,只是返回字符串参与匹配的内容体
- 匹配到的时候,自动调用,且参数强大:
- 并且参数齐全,应有尽有
- 当有两个表达式的时候
- 第一个参数:正则表达匹配的结果
- 第二个参数:匹配的第一个表达式
- 第三个参数:匹配的第二个表达式
- 第四个参数:索引位
- 第五个参数:源字符串
- 当有三个表达式的时候,从第四位处添加第三个表达式的返回值。
- n个表达式的时候,依次类推。
- 当有两个表达式的时候
- 替换引用:
- $i(i取值范围1~99):表示从左到右正则子表达式所匹配的文本
- $1 表示第一个表达式
- $2 表示第二个表达式
- … 以此类推
- 因$有了特殊含义,如果想纯用$符号的话,就写“$$”转义
案例: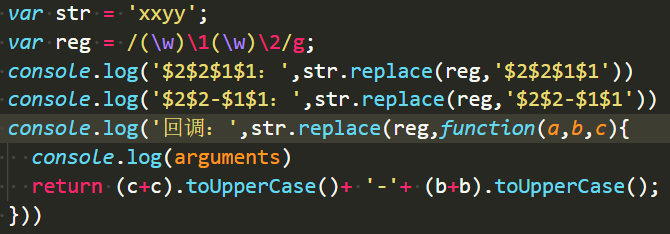
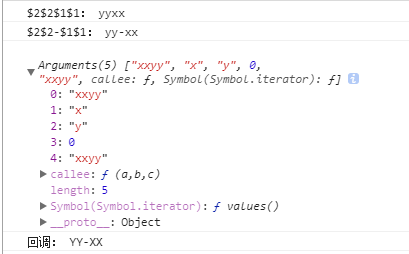
然后三个表达式的情况: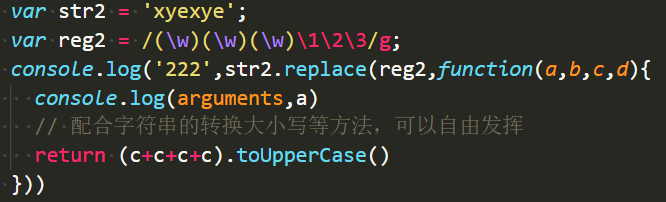

对应题目:
给你一个字符串“the-first-name”,处理后变成小驼峰写法。(见下边exp组件处)
返回值:
如果没匹配成功,replace执行后默认返回原字符串。并且replace的匿名函数里边也不会执行。
如果匹配成功,replace执行后默认返回undefined

 其他细则研究,跟字符串有关的见《字符串》篇章。
其他细则研究,跟字符串有关的见《字符串》篇章。 作业:string的其他方法研究
作业:string的其他方法研究
正则表达式:
作用
- 匹配特殊字符或有特殊搭配原则的字符
- 截取特定格式的字符串
- 检测字符格式是否正确
正则表达式和Date类似,都能创建一个对象
正则表达式不是一个规则,他是一个规则对象。其对象里边包含的规则是对象。
正则表达式创建
对象字面量、直接量
var reg = /pattern/attributes;
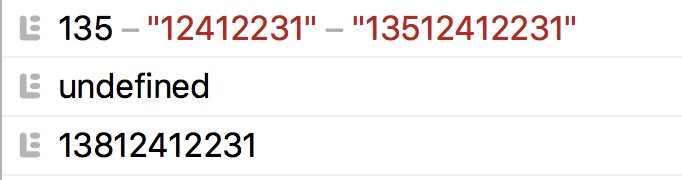
想加变量?
!!不存在的,出来还是一个字符串。
实例化创建RegExp对象
var reg1 = new RegExp(pattern, attributes);
这种写法的好处是,pattern里边可以添加变量: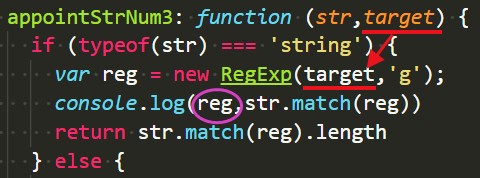
这样最终reg就是正常的正则表达式了: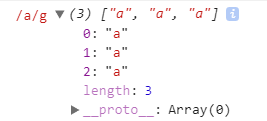
注意(上篇24分左右):
有new时,括号里也可以放对象字面量形式的变量。二者就是分开的两种情况。
比如:var reg1 = new RegExp(reg); 就算是正常的正则写法。reg和reg1是两个独立的表达式。给reg1加属性,reg不受影响。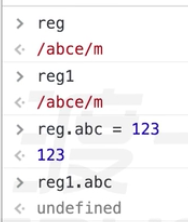
但是没有new时,括号里放对象字面量的变量创造出来的二者是一个正则表达式,因为此时括号里的参数只是当做一个引用而已。相当于普通的RegExp函数调用,并且传了一个引用值参数。
二者共用一个正则对象。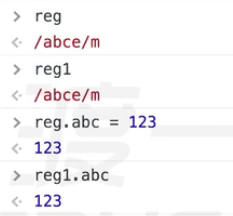
匹配规则:
通篇只扫描一遍:扫描字符串,左到右,逐字查询。扫描过后就不再回退看了。
贪婪匹配原则:能多匹配几个,就不在中间断开。(见下边*号量词处)
修饰符:
- i :忽略大小写 ignore case
- g :全局匹配 global 不甘心于只匹配一个,如果不加g,找到一个符合条件的就停止查找了。
- m :多行匹配(此多行不是页面样式上撑不下换行导致的看上去有好几行,而是在字符串里有换行转义符导致的)。一般和开头结尾匹配相结合使用
如下,后一个a才符合规则

表达式 - 方括号:[ ]
[]中括号内部填写表达式可以取到的范围。一个表达式代表一位,里边填的就是区间。(即使[ab]这样填写也是区间,是匹配a-b,也就是a或者b了,表示任意取一个字符)。
在正则规格中,匹配范围用[]包裹,且一个[]代表一位(即使里边写成[123456789]这样,也是只匹配1-9的任何一个且仅一个数字)。
符合[]设定范围的条件,该字符通过验证。
比如老师形象举例,三个连着的数字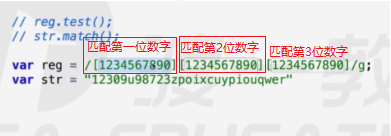
注意下边这种没有横杠的写法,特别注意表示区间,而不是要锁定两个字符,只取任意一个即可。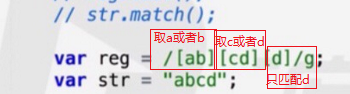
因此,这个结果是bcd
且这个区间可以填的很没有下限,怎么填都行。
甚至这样:[0-9A-z]
- [0-9]:从0-9
- [A-Z]:从A到Z
- [a-z]:从a到z
- [A-z]:从A到Z+从a到z
- [0-9A-z]:…意会…
 问题,在表达式里想匹配中横线 - 怎么办?
问题,在表达式里想匹配中横线 - 怎么办?
直接填中横线不就好了!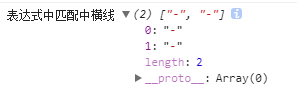
中括号内部的字符不用转义?【待测试,2019/11/19】
非 ^
- 放在表达式[]里时,读作”非”。表示取反,只要不是某个字符就符合条件。相当于js里边的!号取反一个道理。
如[^a]表示匹配字符不是a就行。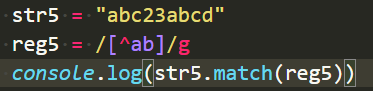
不是ab就行,结果
- 其他情况,表示匹配以这个字符开头的字符串片段:
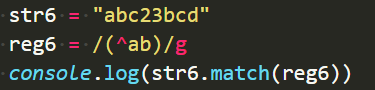
匹配以a开头的字符串片段“ab”;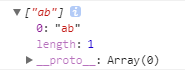
表达式 - 小括号:()
( ) 小括号,
作用一:在表达式里和数学的括号没啥区别,写了就有优先计算的作用。
作用二:子表达式(具体解析见下边:匹配符合某种格式的字符)
或 |
js中表示“或”,用“||”。
正则表示“或”,用“|”:
使用场景经常是放在圆括号,表示任取多个条件中的任意一个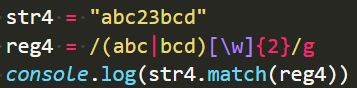
表示匹配abc后跟两位数字或者bcd后跟两位数字,因为bcd后边没数字,不符合条件,得: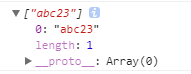
元字符
\w
world - 单词的意思,就是匹配字符,
\w === [0-9A-Za-z] 【记住特殊的多一个下滑线“”】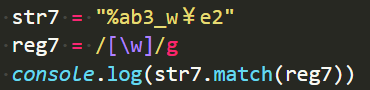

\W
取反\w,非\w,只要不是0-9、A-z、_ 这些个,就能匹配。
\W === [^\w]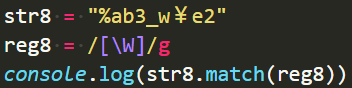
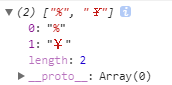
\d
digit - 数字的意思,就是匹配数字
\d === [0-9]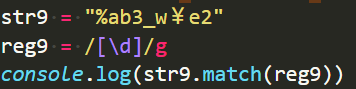

 问题:浮点数能匹配出来吗?小数点会不会给过滤掉?
问题:浮点数能匹配出来吗?小数点会不会给过滤掉?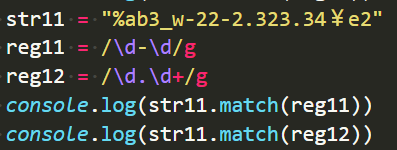
匹配错误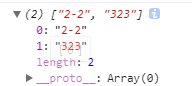
这样也是null,不成功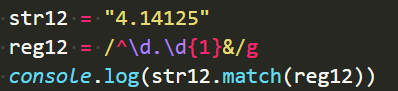
百度 - 需要将小数点转义: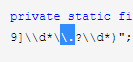
这样写,就把浮点数字字符匹配上了: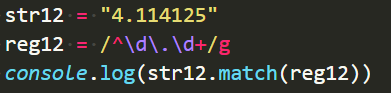
\D
取反\d,非\d,只要不是数字就行。
\D === [^\d]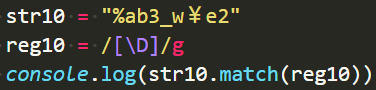

\s
space - 间隔、空白的意思,查找匹配空白字符
空白字符可以有:
也就是一个\s,表示最顶部的所有元字符(见最顶部)
\s === [\r\n\t\v\f ] 【最后空白是一个空格】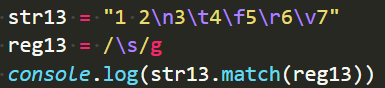

 连写\r\n也会分开匹配
连写\r\n也会分开匹配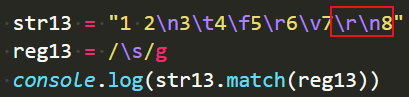
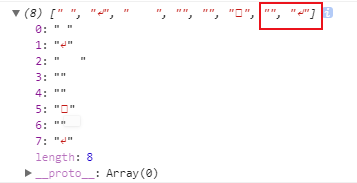
 注意,像“\t” 这类的空白转义符,需要直接写成\t才能匹配上
注意,像“\t” 这类的空白转义符,需要直接写成\t才能匹配上
结果匹配不上: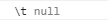
\S
取反\s,非\s,只要不是上边所列那六个空白转义符,就能匹配。
\S === [^\s]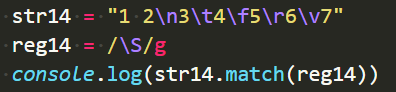

 匹配所有的字符,甚至JQKA扑克牌的花色。写法:(见下边exp组件库)
匹配所有的字符,甚至JQKA扑克牌的花色。写法:(见下边exp组件库)
\b
boundary? - 单词边界
匹配一个数字,且左边是单词边界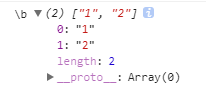
\B
取反\b,非\b,非单词边界
匹配一个数字,且左边不是单词边界,因为1和2左边都是单词边界,又因为8的单词边界在右边而非左边:
但如果这样:
左右都得是非单词边界,那么结果就是只有4和3
点 .
查找单个字符,除了换行和行结束符(因为点”.”在正则里也有特殊意义,所以平时查找浮点数时,要对点进行转义)
. === [^\r | ^\n]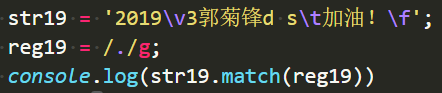

\xxx
查找以八进制数 xxx 规定的字符。
\xdd
查找以十六进制数 dd 规定的字符。
\uxxxx
查找以十六进制数 xxxx 规定的 Unicode 字符。
Unicode编码只是见《星海拾贝》
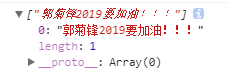
不过,直接匹配中文也可以的达到这个效果: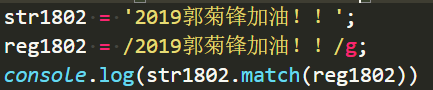
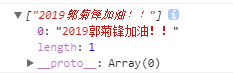
量词 - 代表数量的词
注意,量词是n的量词,不是n的结果的量词,比如下边这个例子: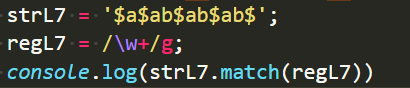

不是说匹配到a,然后取1到正无穷个a,而是1到正无穷个\w。
当然了,如果你非要匹配a那就另说了,比如这么写: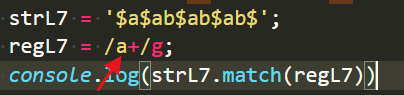
那结果肯定只匹配a。
具体目录:
n+ {1, infinity}
n为变量,n代表任何东西。
+代表n这个变量可以重复出现1次到无数次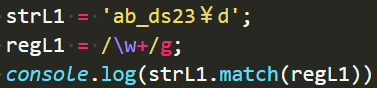
\w表示0-9A-z_这些字符,所以¥没有被匹配上,匹配了前边”ab_ds23”后在¥处断开,由于g,继续查找,匹配到”d“: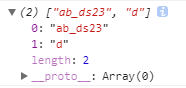
如果没有“+”号,就不能连续匹配,只能一次取一个字符:
如果没有g,就不能去两段字符片段,d也就取不出来了: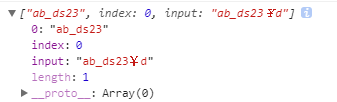
n* {0, infinity}
n为变量,n代表任何东西。
代表n这个变量可以重复出现0次到无数次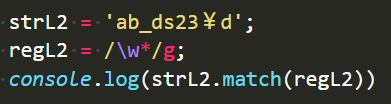
 “”需要注意的是,即使没有字符可以匹配也算匹配上了。
“”需要注意的是,即使没有字符可以匹配也算匹配上了。
最后的空也就被匹配上了。
这个例子更直观:
absd的左右,都没有数字,在光标停留的地方都进行了匹配,匹配不到,就抓出空:
 而前边的”ab_ds23”却没有被分开,这就是贪婪匹配原则(能多就不少)。能多匹配多个,就不中断。
而前边的”ab_ds23”却没有被分开,这就是贪婪匹配原则(能多就不少)。能多匹配多个,就不中断。
n? {0, 1}
n为变量,n代表任何东西。
?代表n这个变量可以重复出现0次到1次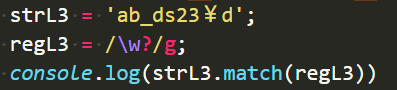

n{X} {x}
n为变量,n代表任何东西。
x个n,区间被定死了。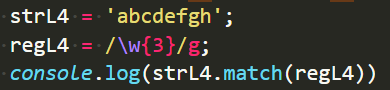
表示匹配3个连着的字符,连起来数量不够三个就不算了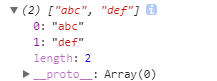
n{X,Y} {x, y}
n为变量,n代表任何东西。
最少x个,最多y个。如果填{0,1},相当于上边“n?”的功能: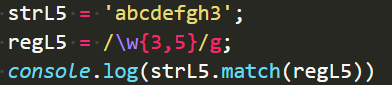
 贪婪匹配原则,能多不少:
贪婪匹配原则,能多不少: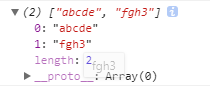
但是不够数,也不将就:
最后只剩一个9,因为不够两个。不匹配: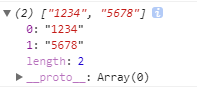
n{X, } {x, Infinity}
n为变量,n代表任何东西。
x表示最少多少个,
逗号后边不写数,表示正无穷了。
如果写{0,},相当于上边“n*”的功能:
如果写{1,},相当于上边“n+”的功能: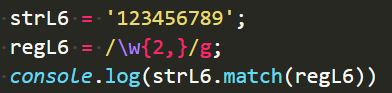
最少两个,最多不限制: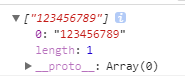
贪婪匹配:能多一定不少【默认情况下就是】
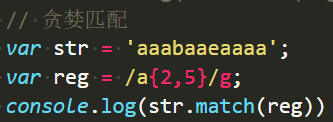

{2,5}是匹配最少2个,最多5个。但是能匹配四个,绝对不匹配2个。
非贪婪匹配:能少一定不多。
触发条件:在任何一个量词后边加一个“?”号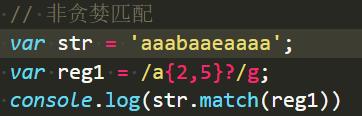

{2,5}是匹配最少2个,最多5个。只要够2个就停手,不多匹配。懒癌晚期。 特殊:??
特殊:??
第一个?代表量词,第二个?表示取消贪婪匹配
?在量词里是{0,1},匹配0个或1个。
如果取消了贪婪匹配,会全是0个匹配了: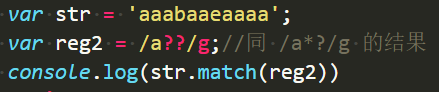

?:
?: 是 不想被捕获的时候使用 可以提高程序执行速度
比如 ([a-z][0-9])+
这个正则表达式里 ( ) 里面的内容被捕获了, 反向引用的时候可以用上 。
一般正则替换的时候用的多 像UBB代码
但是 如果写成 (?:[a-z][0-9])+
跟上面 正则表达式 整体匹配是一样的 就是 不会捕获 ( )里内容了。
也就是不能使用 反向引用
如果还是不太理解, 那就先了解一下 反向引用吧。
?的用法大总结:
| 单独的“?” | 匹配前边的字表达式 0-1 次。 | n? - 匹配n,0-1次 |
|---|---|---|
| “量词?” | 非贪婪匹配原则。 | n{2,5}? - 匹配n,2-5个,能匹配2个不匹配5个 |
| “??” | 第一个?代表两次,第二个?解除非贪婪匹配原则 | a?? - 匹配a,0-1次,开了非贪婪匹配,匹配0个也可以 |
| “?:” | 非获取匹配,匹配冒号后的内容但不获取匹配结果,不进行存储供以后使用 |
强制条件 - 结束和开头


正则属性

global,表示写了修饰符g
ignoreCase,表示写了修饰符i
multiline,表示是否写了修饰符m
source,表示正则的内容体
 lastIndex,当前光标的位置(具体解释见下边exec方法的游标处)
lastIndex,当前光标的位置(具体解释见下边exec方法的游标处)
后期因为lastIndex 的原因,陷入的一个坑点: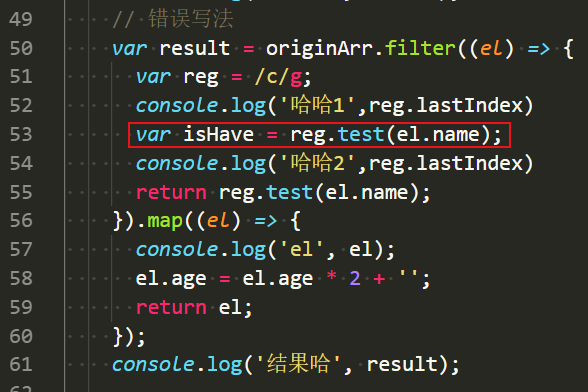
游标的位置不是每次从新开始的: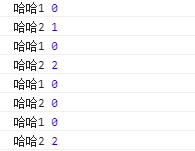
老师的讲解:
忠告
争取的写法: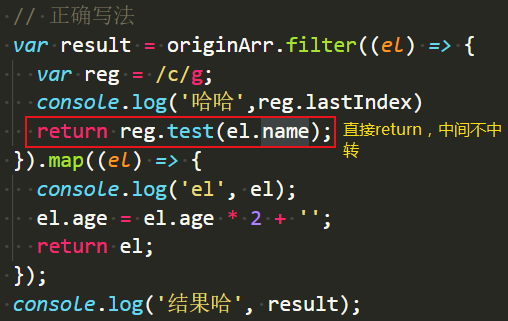
这样游标就每次都是重新开始的:
正则方法
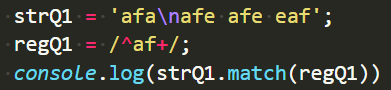
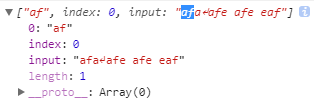
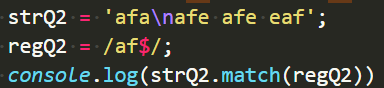
test()方法
 exec()方法
exec()方法
chief exective officer
先看一个现象:
结果如下: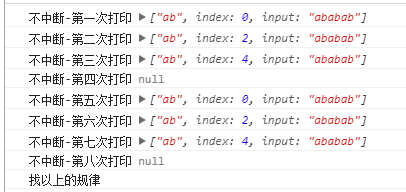
返回值:是一个类数组。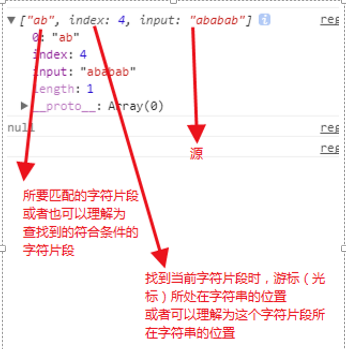
—————————————————————
Index值随游标修改
这里边,index的值在变化,他就是光标当前找到符合条件的字符片段时的起始位置。
在没有遍历完的时候,游标是一直向后走的。所得的index值也一直增加。
但是当找到字符串末尾时,由于没有了匹配值,返回null。
再次继续调用,光标将回到第0位起始位置重新开始游走。
因为游标的原因,把g修饰符去掉后,游标永远在第0位:

游标 - 就是上边的属性:lastIndex
返回值中的index的值对应的也就是lastIndex值,即是游标的位置值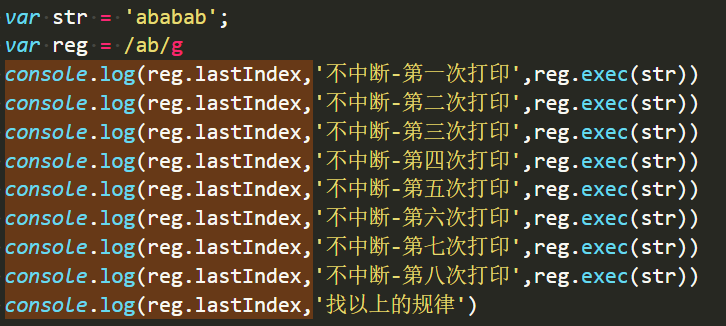

lastIndex属性和exec()方法相协调匹配:
lastIndex能够影响exec()的查找进程:
中途被更改后,exec()根据游标的位置从头开始查找。
不过下次还是正常往后飘~
总结:exec()通过查找lastIndex游标的位置,来进行下次匹配。
exec与反向引用:
一、匹配符合某种格式的字符
比如,YY-MM、XXYY等格式的。
特色是,要求你知道前一个字符匹配的是啥,然后拿着这个字符去后边找紧邻的那个字符是不是一致的。(注意与量词区分,量词虽然也是重复,但后边重复的字符可以和前边的是某一类型,可以和前边一样都是符合条件的字符,但不一定和前边就是同一个字符。)
()小括号 —— 子表达式
作用之一就是:当我们用小括号把表达式括起来以后,这个小括号会记录里边匹配的内容。(比如你通过匹配得到符合条件的字符串片段为’abv’,那么小括号里边就会记住这个字符片段’abv’)。然后我们再通过反向引用(比如:\1,表示反向引用第一个子表达式里边匹配的内容)
示例: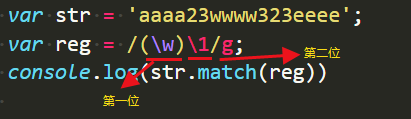
匹配结果:因为第0位a被\w匹配上,后边\1反向引用a,再次匹配到第二个a。然后因为g修饰符,要全局查找,所以第三个a被\w匹配上,后边\1再次反向引用a。以此类推…
反向引用
向左引用前一个子表达式里边匹配的内容
比如:
\1,表示反向引用第一个子表达式里边匹配的内容
\2,表示反向引用第二个子表达式里边匹配的内容
注意,这里一定要有“位”的概念:
就像个十百千万位数一样,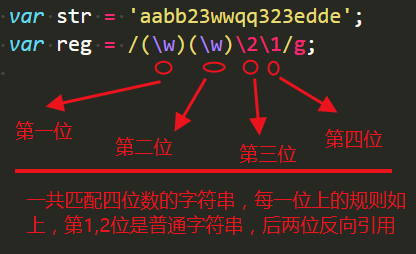
所以,我们想要得到类似“XXXX”的格式就这么匹配: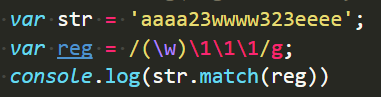
后边三位都反向引用第一位匹配的值:
所以,我们想要得到类似“XXYY”的格式就这么匹配: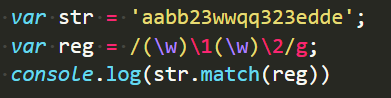
第二位的\1引用第一个在第一位的\w匹配的值,
第四位的\2引用第二个在第三位的\w匹配的值,
所以,我们想要得到类似“XYYX”的格式就这么匹配: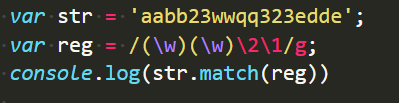
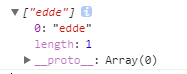
另外,如果反向引用的位数与表达式的个数不匹配时,不会报错返回”null”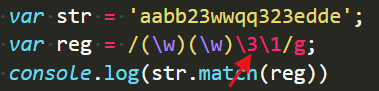
二、exec与反向引用共用
如果调用exec()方法的正则表示式中有反向引用,则exec的返回值会有变化: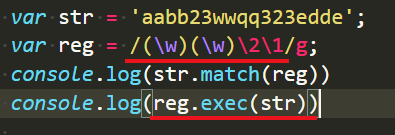
多出来e和d两位。多出来的就是两个子表达式匹配的内容。
这两位是正式的数据位,放在返回值的数组中,能够通过索引1||2获取。是伪数组内部的正规军。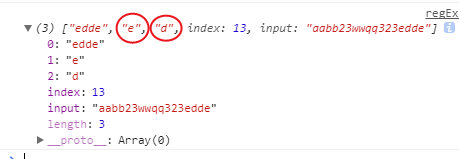
exec()在jq源码中的应用
 学到这里再补充。具体看jq篇章了吧。
学到这里再补充。具体看jq篇章了吧。
正向预查【正向断言】
选择某个字符x,需要字符y的修饰。但是最终选出来的只有x。
成哥小例子:查成哥,除了一个帅哥的修饰词,还有他有一个残疾的合伙人(邓哥)。就是有一个残疾合伙人的帅哥,定语是帅哥,但是修饰条件是残疾合伙人。
对应到题目中,如下:
找一个a,但是后边要跟着一个b。选出来的还要是a(不包含b),但是,需要b作为一个判断条件
所以,如果按照自己的思路,直接选’ab’,那选出来的不单是a,不符合正向预查的核心思想。
(?=n)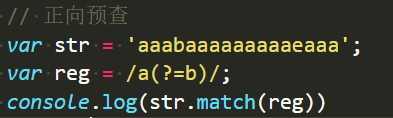
为了看游标位置,我特地去掉了正则中全局修饰符g,这样match返回的信息如下: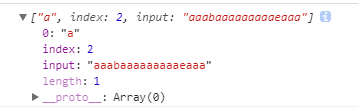
可以看出,他选择的不是第0位的a,而是下标为2(后边有b)的a
这个操作也是秀~!!
非正向预查
(?!n)
后边不跟着n的那个字符片段: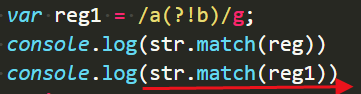
一共5个a,排除掉一个连着b的,还有四个,所以长度为4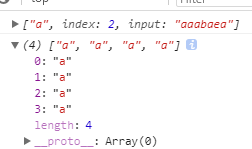
反向预查【反向断言】
(?<=n)m 代表前面紧跟着n的m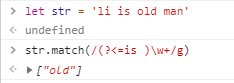
应用:可以取链接了:
取a标签中的地址
相关练习题
- 见《正则题目)篇章

若有收获,就点个赞吧
0 人点赞
