CH1.pptx
生物信息学是生命科学,计算机科学,现代信息科学,数学,物理学以及化学等多个学科交叉结合形成的一门新学科,是利用信息技术和数学方法,对生命科学研究中的生物信息,进行储存检索和分析的科学。
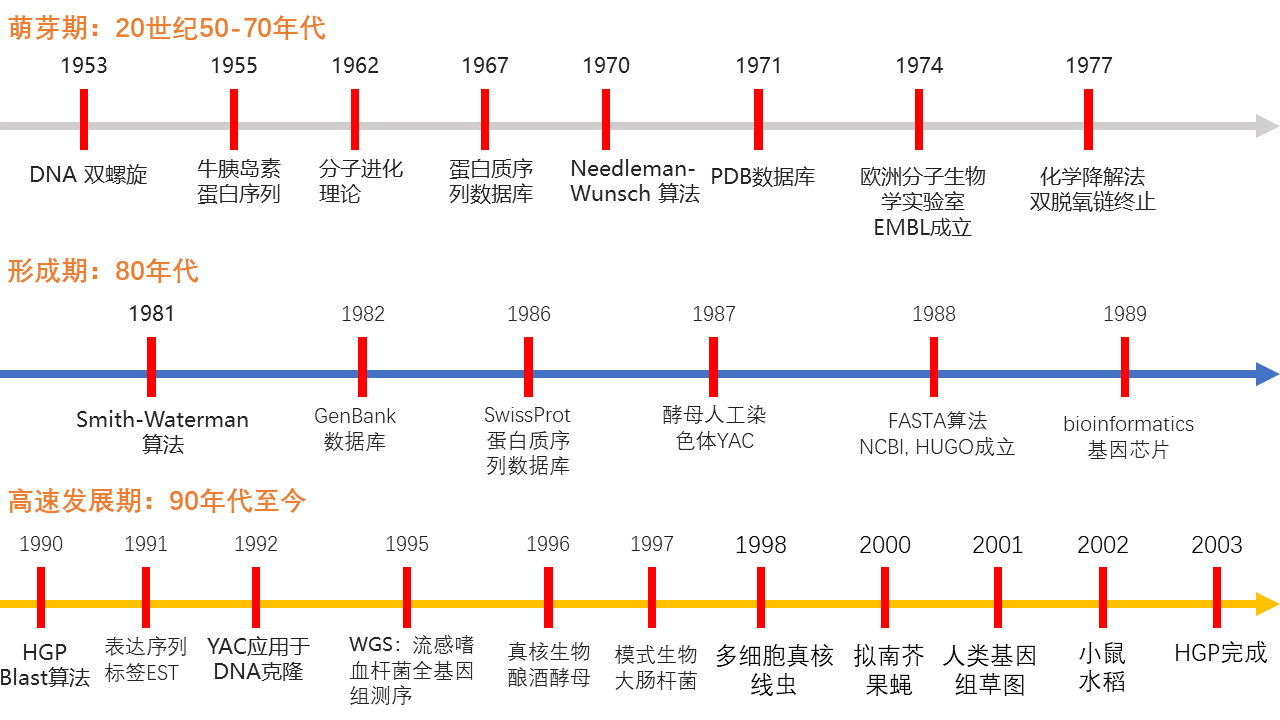
1. 生物信息学发展历史
:::tips
推荐公众号推文:测序发展史
视频1/2:生信发展史(个人觉得比书中全面具体)
:::
(1)萌芽期(20世纪50年代-70年代)
1953年,沃森和克里克根据富兰克林和威尔金斯的 X 晶体衍射数据提出了 DNA 双螺旋结构。
1955年,Sanger 发表了牛胰岛素的蛋白序列,是生物信息学发展的基础。
1962年,Pauling 提出了分子进化理论。
1967年,Dayhoff 构建了蛋白质序列数据库。
1970年,用于序列比较的 Needleman-Wunsch 算法发表。
1971年,蛋白质结构数据库(protein data bank,PDB)在美国创建。
1974年,欧洲分子生物学实验室(European molecular biology laboratory,EMBL)建立。
1977年,Maxam 和 Gilbert 发表了化学降解法,Sanger 和 Coulson 发表了双脱氧链终止,用于DNA测序,Sanger 等完成了第一个基因组序列——噬菌体。
(2)形成期(80年代)
1980年,Wuthrich 发明了利用核磁共振技术测定溶液中,生物大分子三维结构的方法;EMBL核酸数据库建立。
1981年,用于序列比对的 Smith-Waterman 算法发表。
1982年,创建 GenBank 数据库。
1986年,SwissProt 蛋白质序列数据库创立。R.Dulbecco 在《science》杂志上提出人类基因组计划的设想。美国能源部正式提出实施测定人类基因组全序列的计划。
1987年,克隆容量可大几百至几千 Kb 的酵母人工染色体(yeast artificial chromosome,YAC) 问世。
1988年,D.J.Pearson和W.R.Lipman发表FASTA算法。美国国立卫生研究院下属的国家生物技术信息中心(National Center for Biotechnology Information,NCBI)成立。国际人类基因组织(the Human Genome Organisation,HUGO)成立。欧洲分子生物学网络组织(European MolecularBiology Network,EMBnet)创立。GenBank、EMBL与DDBJ共同成立了国际核酸序列联合数据库中心,建立了合作关系。根据协议,这三个数据中心各自搜集世界各国有关实验室和测序机构所发布的序列数据,并通过计算机网络每天都将新发现或更新过的数据进行交换,以保证这三个数据库序列信息的完整性。
1989年,林华安首先采用“bioinformatics”一词。美国成立国家人类基因组研究中心,J.D.Watson出任第一任主任。美国Affymetrix公司研制出了世界首张基因芯片。
(3)高速发展期(90年代至今)
1990年,美国国会批准正式启动人类基因组计划(Human Genome Project,HGP)研究,计划用30亿美元的预算在15年的时间内完成人类30亿碱基对的测序和基因确定。S.F.Altschul 发表BLAST算法。
1991年,J.C.Venter在《科学》杂志上描述表达序列标签(expressed sequence tag,EST)的建立和使用。
1992年,J.C.Venter在美国马里兰州成立基因组研究所(the Institute of Genome Research,TIGR)成为细菌基因组测序研究的先驱;M.Simon和同事宣布细菌人工染色体(bacterial artificial chromosome,BAC)在DNA克隆中的应用。
1994年,欧洲生物信息学研究所(European Bioinformatics Institute,EBI)成立。
1995年,《科学》杂志首次刊登了TIGR采用其创立的全基因组鸟枪法(whole genome shot-gun,WGS)完成的流感嗜血杆菌全基因组测序的论文。这是人类完成的第一个单细胞微生物的基因组序列的测定,标志着基因组时代的真正开始。
1996年,第一个真核生物——酿酒酵母全基因组测序完成。
1997年,第一个重要的实验模式生物——大肠杆菌全基因组测序完成。S.F.Altschul 发表PSI-BLAST算法。
1998年,第一个多细胞真核生物——线虫全基因组测序完成。
2000年,第一个模式植物——拟南芥全基因组测序工作完成,成为被完整测序的物种。黑腹果蝇基因组测序完成。
2001年,国际人类基因组测序协作组和J.C.Venter领导的Celera公司分别在《自然》和《科学》杂志同时发表人类基因组草图。
2002年,小鼠、水稻基因组草图公布。
2003年,人类基因组测序计划完成。
2. 书本知识框架
目前的生物信息学研究,已从早期以数据库建立和DNA序列分析为主的阶段,转移到后基因组学时代以比较基因组学(comparative genomics)、功能基因组学(functional genomics)和整合基因组学(integrative genomics)为中心的新阶段。
(1)序列数据资源
序列数据资源存储了生物信息学研究的原始数据,是生物信息学存在和发展的基础。
(2)序列比对和比对搜索
序列相似性分析是生物信息学最早涉及的问题之一,常用的分析方法是序列比对(sequence alignment)(包括Needleman-Wunsch算法和Smith-Waterman算法等),以及目前广泛使用的序列比对工具(NCBI提供的BLAST等)。
(3)基因组结构注释
随着人类基因组测序计划完成及其它物种基因组测序工作的相继展开,公开数据库中已经积累了大量的基因组序列数据。为了充分发挥这些基因组序列的应用价值,一项极其重要的工作即是“翻译”出基因组序列中蕴含的生物学知识。
(4)分子系统发生分析
系统发生关系是表示,物种进化关系的参考依据。通过分析分子水平的序列数据,可以了解物种系统发生的关系,目前常用树的形式来表示不同物种间的进化关系。
(5)蛋白质结构
蛋白质的空间结构是其行使功能的基础。在进行蛋白质相关研究时,我们经常会遇到一些难题。例如矿膜蛋白如何控制矿么区域的开阖,并实现细胞内外分子的转运;又如一些被简单的化学修的蛋白质,其活性为何会发生如此巨大的变化;朊蛋白发生怎样的构象变化才能导致诸如疯牛病等。
(6)蛋白质序列分析与功能预测
蛋白质在生命过程中发挥着巨大的作用,它们执行者大部分生物学功能,包括结构功能、酶功能、以及在细胞内或细胞间转运物质的功能等。
(7)微阵列数据分析
在考察某个具体生命状态下的基因表达水平时,实验人员最想知道的问题是:在这个生命状态中,哪些基因相对于他们正常状态有较为明显的高或低表达。微阵列是一种重要的基因表达高通量检测技术。分析微阵列数据时,最大的挑战是如何使用相应的统计学手段,判定哪些基因确实存在改变。
(8)蛋白质组数据分析
高通量的蛋白质组工程能够大范围的确定蛋白质功能,能确定蛋白质在哪些特殊的生理条件下会出现,还能确定哪些蛋白质之间有相互作用。目前除了研究单独蛋白质外,同时还对数千个蛋白质进行高通量的分析已成为可能。
(9)疾病相关研究
寻找疾病相关基因是认识疾病发生机理、研制疾病的基因诊断与防治手段的基础,也是人类基因组研究的重要目标。现在一些与遗传病有关的重要基因,已被分离和测序,另一些常见病毒乳腺癌、结肠癌、高血压、糖尿病和阿尔茨海默只并等都具有遗传倾向的疾病的基因,已在染色体遗传图谱上精确定位,寻找致病基因的研究工作在不断的深入,这些工作为新药的发现和开发提供了可靠的信息和软件工具资源。
(10)SNP芯片及深度测序数据分析
后基因组时代一个典型的特征就是生物实验芯片化,深度测序技术的不断发展极大地促进了生物信息学的研究。
3. 贯穿书本例子
(1)视黄醇结合蛋白
视黄醇结合蛋白是一个相对分子质量小、被大量分泌的蛋白质,能结合血液中的视黄醇(维生素A)。视黄醇可从胡萝卜中以维生素A的形式获得,疏水程度大。RBP4 帮助转运这个配体到眼睛,为视觉系统所用。它有一系列有趣的性质:
- 在多个物种中有许多蛋白质和RBP4同源,包括人、小鼠和鱼(“直系同源”)中的蛋白质。
- 也有许多人类蛋白质和RBP4紧密相关(“旁系同源”),它们和RBP4的家族称为lipocalin家族——一群多样的小配体结合蛋白,它们倾向于分泌到细胞外空间。一些lipocalin蛋白具有的功能与RBP4不同,例如结合胆固醇(如apoliprotein D)、与妊娠相关(如pregnancy-associated lipocalin)、催欲(如仓鼠的催欲蛋白)和气味结合(如黏液中的气味结合蛋白)等。
- 有细菌的lipocalin蛋白,它们在对抗生素的抗性中起作用。编码细菌lipocalin的基因可能是一古老基因,它通过水平基因转移的过程进入真核生物基因组。
- 一些lipocalin蛋白的表达水平受到显著的调控。
- lipocalin蛋白小而丰富,并且是可溶性的,它们的生物化学性质已被详细研究,许多蛋白质的三维结构也以X线晶体衍射的方法被解析出来。
-
(2)人类免疫缺陷病毒(HIV)
HIV-1基因组仅编码9种蛋白质,包括pol。pol基因的特性、其蛋白质产物以及HIV-1基因组具有显著特点:
pol基因编码一种1003个氨基酸的蛋白质。该蛋白质是一多结构域蛋白质:单条肽链但有多个结构和功能不同的结构域。
- pol蛋白有反转录酶活性(即RNA依赖的DNA多聚酶),它也是天冬氨酸蛋白酶,并且还有整合酶(integrase)的活性。有多种活性是多结构域蛋白的典型特征。
- pol蛋白的模块化特点会影响数据库搜索和多序列比对。
- pol基因以相当快的速度发生碱基替换。一个典型的被HIV感染的个体可能会有百万种以上的pol变种。
总结
NCBI 下载书本案例序列

若有收获,就点个赞吧
0 人点赞
