作为 YC w22 batch 巡礼 的第一篇,还是选择比较熟悉的数据库领域下手。

Hydra 是基于 PostgreSQL 的 Hybrid Transactional/Analytical Processing / HTAP 系统。基于 PostgreSQL 做AP 这个思路不算新,Greenplum, ParAccel (AWS Redshift 的前身) 都是基于 PostgreSQL 8.x 魔改的数仓系统。
当然 PostgreSQL 已经从 8.x 走到了 14.x,而整个 OLAP 领域也已经天翻地覆。所以 Hydra 的做法也是不一样的,并不自己做 OLAP,而是集成已有的 OLAP,比如 Snowflake,BigQuery。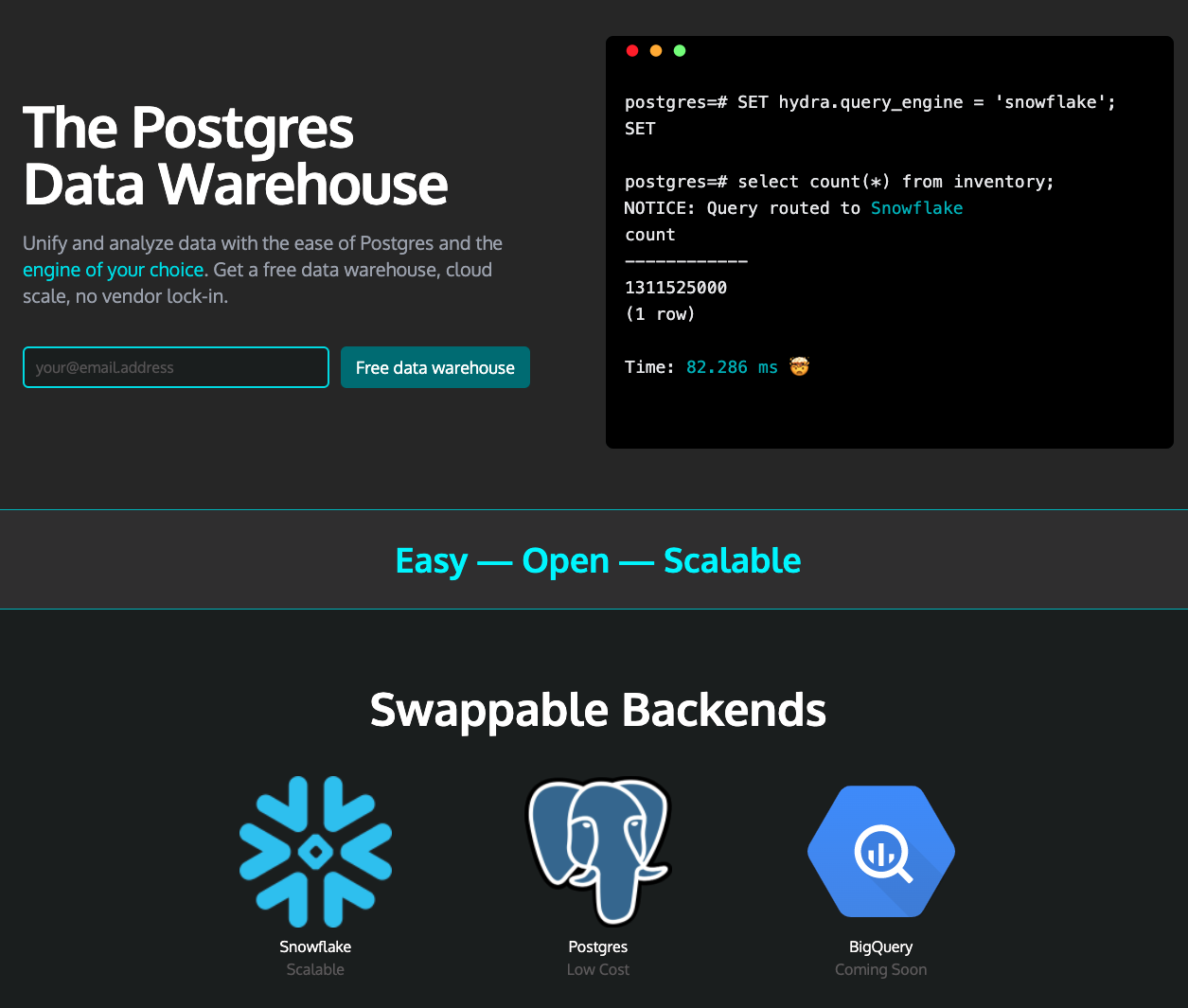
笔者看到此的第一反应,是想他用了 PostgreSQL 的 Foreign Data Wrapper / FDW,而其实并不是,Hydra 选择了类似 TimescaleDB 的方案,单独实现了一个 Extension。根据 CTO 的说法,主要是 FDW 仍然不能很好地支持计算下推 (push down),导致稍微复杂一点的 query 执行效率不佳。这个解释也是比较合理的,毕竟 FDW 属于外部数据源,在 PostgreSQL 里面毕竟属于二等公民,优化器难免顾及不到,但相信后续的版本,PostgreSQL 会逐步解决针对 FDW 的 query 优化问题。

Hydra 只提供公有云服务,没有私有化部署 (也有点废话,不然怎么能集成 Snowflake 和 BigQuery 呢)。现在国外出来的新数据库系统,Firebolt,PlanetScale 这些,也都只提供公有云版本了。而在国内,提供私有化部署版本应该还是一个必选项。
Hydra 提供了 HTAP 实现的另一种思路,把 OLAP 部分外包给了其他专门的 AP 系统。当然这也需要数据库本身扩展性足够才行,目前市面上也只有 PostgreSQL 可以了。
当然笔者对于这套架构持保留意见,虽然大大降低了实现的复杂度,但毕竟是嫁接来的 AP 系统,容易做成四不像。在数据库这个基础领域,任何走捷径的手段都是徒劳的,HTAP 的唯一路径还是数据库系统本身的原生支持。如果在 PostgreSQL 基础上做,光通过 extension 来实现是不够的,还需要魔改 PostgreSQL 的 Query 层和 Storage 层才行。而这也是笔者期待业界出现的方案,毕竟 PostgreSQL 从 8.x 早到 14.x,也已经铺了很多的路。
前路漫漫,让我们拭目以待吧。

若有收获,就点个赞吧
0 人点赞
