简介
【百度百科】:Apache Zeppelin是一个让交互式数据分析变得可行的基于网页的notebook。Zeppelin提供了数据可视化的框架。
Apache Zeppelin是一个让交互式数据分析变得可行的基于网页的开源框架。Zeppelin提供了数据分析、数据可视化等功能。
Zeppelin是一个提供交互数据分析且基于Web的笔记本。方便你做出可数据驱动的、可交互且可协作的精美文档,并且支持多种语言,包括 Scala(使用 Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等等。
初识
Apache Zeppelin是一个可以进行大数据可视化分析的交互式开发系统,可以承担数据接入、数据发现、数据分析、数据可视化、数据协作等任务,其前端提供丰富的可视化图形库,不限于SparkSQL,后端支持HBase、Flink等大数据系统以插件扩展的方式,并支持Spark、Python、JDBC、Markdown、Shell 等各种常用Interpreter,这使得开发者可以方便地使用SQL在Zeppelin中做数据开发。
对于机器学习算法工程师来说,他们可以在Zeppelin中可以完成机器学习的数据预处理、算法开发和调试、算法作业调度的工作,包括当前在各类任务中表现突出的深度学习算法,因为Zeppelin的最新的版本中增加了对TensorFlow、PyTorch等主流深度学习框架的支持,此外,Zeppelin将来还会提供算法的模型Serving服务、Workflow工作流编排等新特性,使得Zeppelin可以完全覆盖机器学习的全流程工作。
在平台部署和运维方面,Zeppelin还提供了单机 Docker、分布式、K8s、Yarn 四种系统运行模式,无论你是小规模的开发团队,还是Hadoop技术栈的大数据团队、K8s技术栈的云计算团队,Zeppelin都可以让数据科学团队轻松的进行部署和使用Zeppelin丰富的数据和算法的开发能力。
原理架构
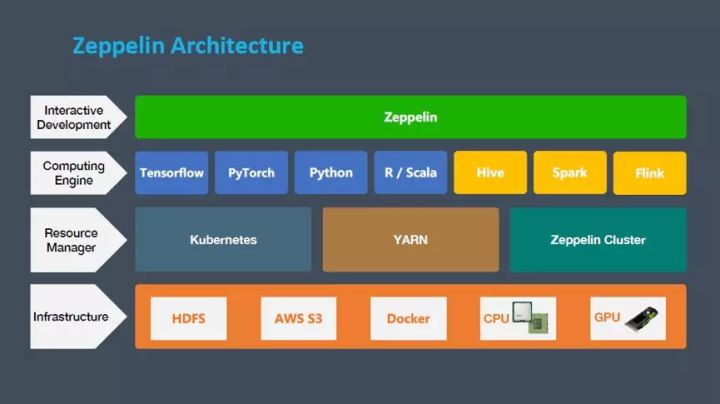
1. 基本架构
首先我们来了解下 Zeppelin的架构, Zeppelin主要分3层。
- Web前端
Zeppelin前端负责前端页面的交互,通过Rest API 和WebSocket的方式与Zeppelin Server进行交互。
- Zeppelin Server
Zeppelin Server是一个Web server,负责管理所有的note,interpreter等等,Zeppelin Server不做具体的代码执行,会交给Interpreter来执行代码。
- Interpreter
Interpreter是一个独立的进程,负责具体前端用户提交的代码的执行(比如Spark Scala代码或者SQL代码等等)。Zeppelin Server与Interpreter之间是通过thrift来进行通信,而且是双向通信。Zeppelin中最核心的概念是Interpreter,一个插件允许用户使用一个指定的语言或数据处理器。每一个Interpreter都属于换一个InterpreterGroup,同一个InterpreterGroup的Interpreters可以相互引用,例如:SparkSqlInterpreter可以引用SparkInterpreter以获取SparkContext,因为他们属于同一个InterpreterGroup。当前已经实现的Interpreter有Spark解释器、Python解释器、SparkSQL解释器、JDBC、Markdown和shell等。下图是Zeppelin官网中介绍Interpreter的原理图。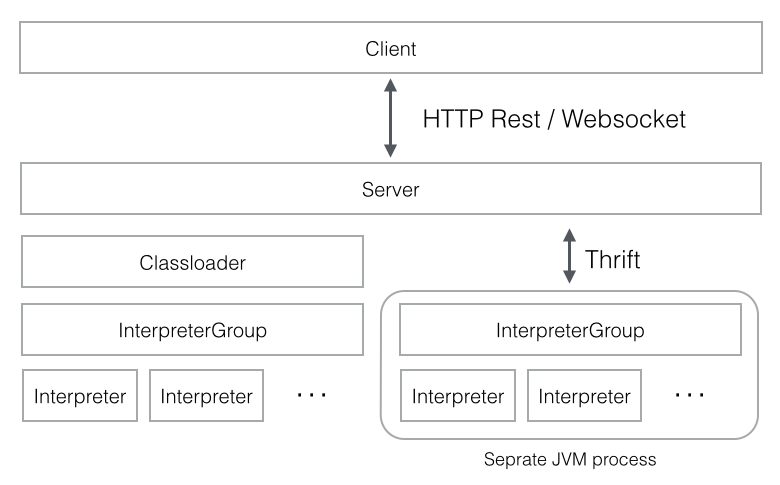
Zeppelin Server是独立的进程,进程日志在logs目录下的 zeppelin-{user}-{host}.log, 每个Interpreter也是一个独立的进程,进程日志是 logs目录下的 zeppelin-interpreter-{interpreter}-*.log, 所以如果碰到任何问题可以先去这两个log文件里去查找线索。
2. Flink on Zeppelin
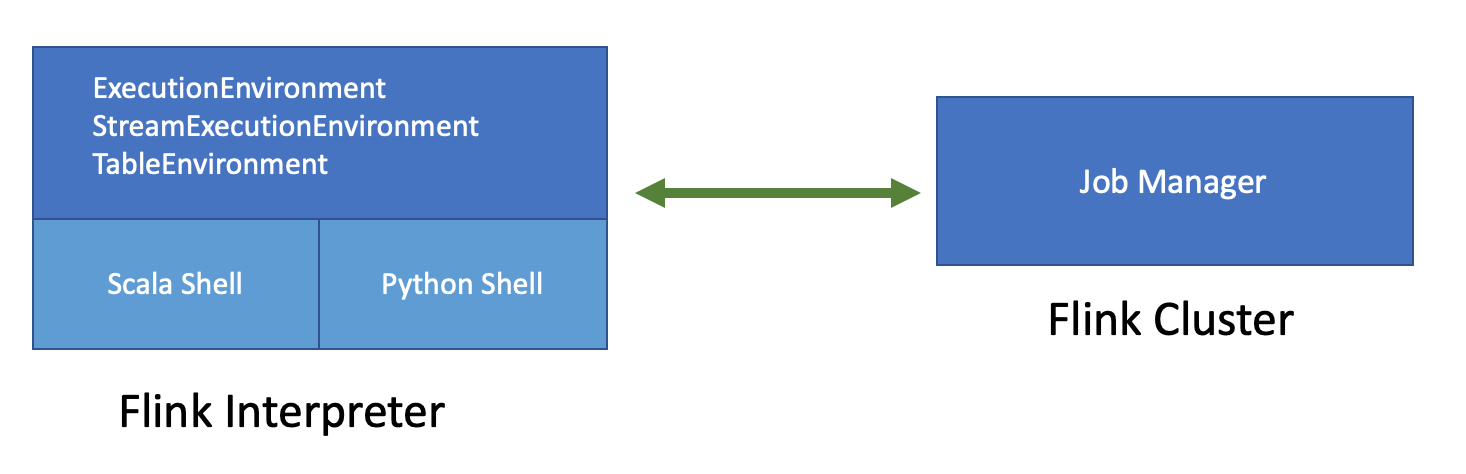
上图是Flink on Zeppelin的架构,左边的Flink Interpreter可以理解成Flink的客户端,负责Flink Job的编译,提交和管理(比如Cancel Job,记录Checkpoint等等)。右边的Flink Cluster就是真正运行Flink Job的地方,可以是一个MiniCluster(local 模式),Standalone Cluster (remote模式),Yarn Session Cluster (yarn 模式)。Flink Interpreter内部会有2个重要的组件:Scala Shell,Python Shell。
- Scala Shell
整个Flink Interpreter的入口,ExecutionEnvironment,StreamExecutionEnvironment 以及所有类型的TableEnvironment都是在Scala Shell里创建,Scala shell负责Scala代码的编译和执行。
- Python Shell
3. Spark with Zeppelin
Spark是Zeppelin最重要的计算引擎,最开始的时候Zeppelin就是为了Spark而设计的。在Zeppelin上使用Spark NoteBook,有Spark和Livy两种方式。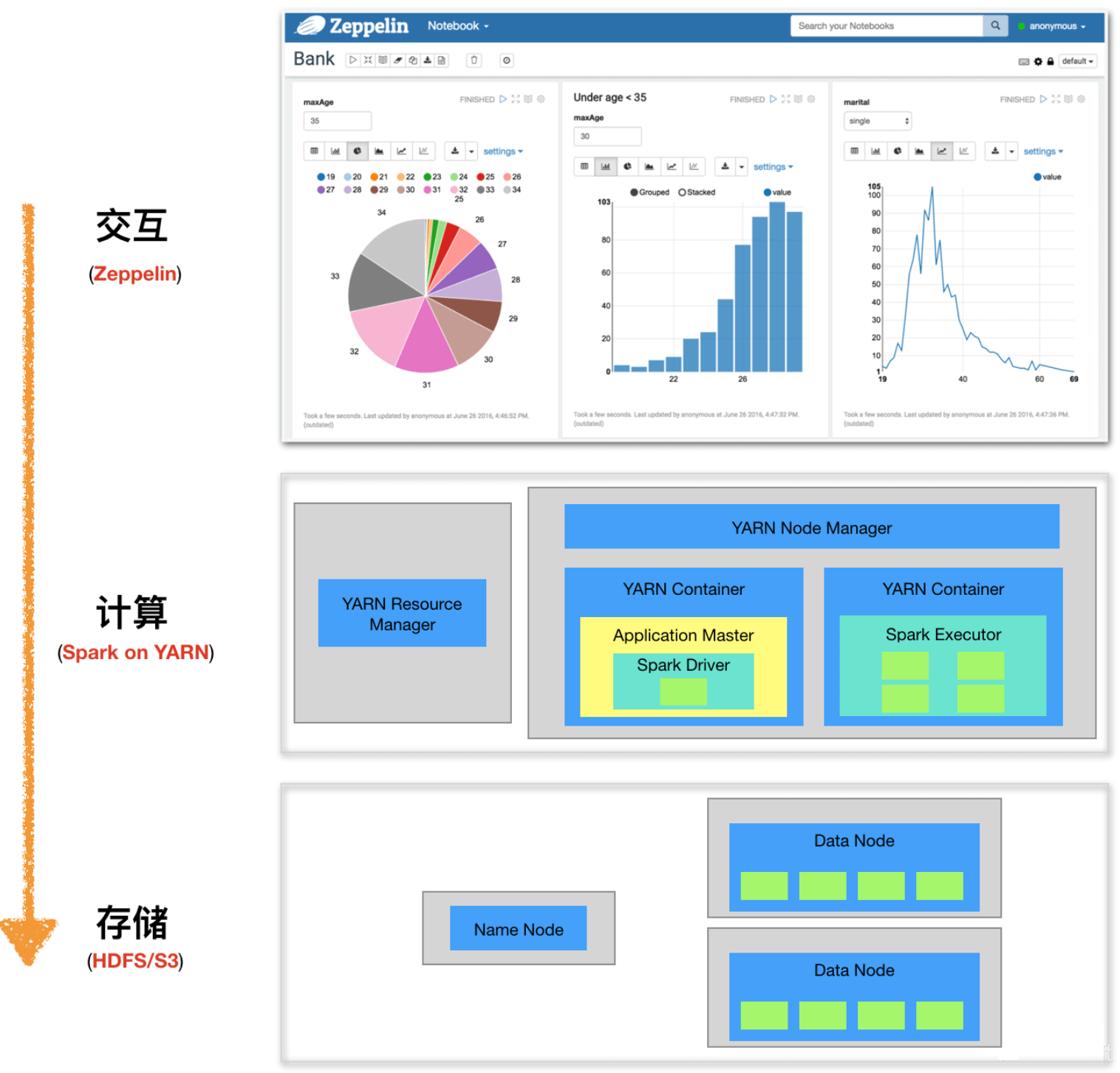
如下图所示,整个系统分为三块:Zeppelin Web Client、Zeppelin Server和 Spark,前两个为Zeppelin的前后端模块,第三个为计算引擎。要搞清楚整体的工作原理,需要搞清楚两个问题:第一,这三者之间是如何通信的?第二,Interpreter是如何被调用的?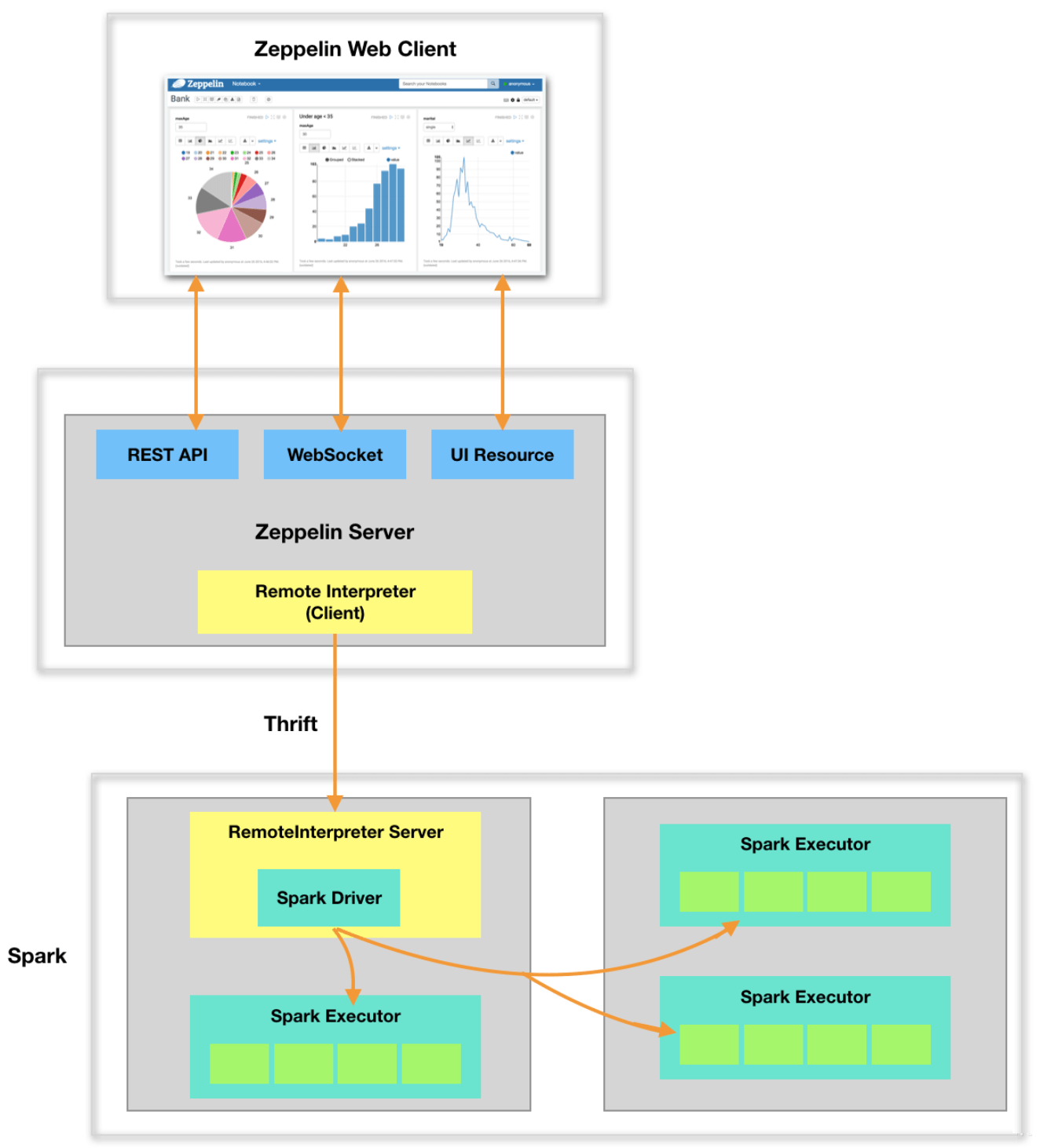
在Spark中,Driver负责任务的调度。在Zeppelin Web Client上编写的代码片段只有传送到Driver进程中,才能得以执行。首先,Zeppelin Web Client通过REST API与Server端进行交互,Server收到后将其提交到任务队列中顺序执行。其次,Zeppelin Server与Spark Driver是不同的进程,并且很可能不在同一台机器上,要实现这样的交互,自然少不了RPC通信,这里采用了Thrift。Spark Driver所在的进程本身是一个Thrift Server进程,由Zeppelin Server发起RPC调用,将相关信息传递过来。
每一个计算引擎都有自己对应的Interpreter类,实现了interpret(String st, InterpreterContext context) 方法,用于执行具体代码。对于每一个Paragraph的执行,都会根据NoteId和Interpreter名字来获取对应的Interpreter实例。如果是第一次执行,便会根据配置创建对应的Interpreter Group及相关的Interpreter实例。在Zeppelin Server 中,Interpreter是由RemoteInterpreter来代理的(代理模式),其集成了Thrift Client相关接口,用于RPC调用。第一次执行时,Zeppelin Server会启动Spark,Spark的主进程(Driver)入口是RemoteInterpreterServer,其集成了Thrift Server相关接口,用于RPC调用。在RPC调用中,会获取对应的Interpreter实例来完成具体执行。
优缺点
| Zeppelin | 描述 |
|---|---|
| 优点 | 1. 提供restful和webSocket两种接口。 1. 使用spark解释器,用户按照spark提供的接口编程即可,用户可以自己操作SparkContext,不过用户不能自己去stop SparkContext。SparkContext可以常驻。 1. 包含更多的解释器,扩展性也很好,可以方便增加自己的解释器。 1. 提供了多个数据可视化模块,数据展示方便。 |
| 缺点 | 1. 没有提供jar包的方式运行spark任务。 1. 只有同步的方式运行,客户端可能需要等待较长时间。 |
新特性
为了支持机器学习工作负载,Zeppelin社区开发出了很多相关的特性,包括Zeppelin集群模式(Cluster Mode)、Zeppelin Cluster + Docker、Zeppelin On Yarn、多集群支持、动态配置、模型预测与增量训练、可视化调参和Zeppelin WorkFlow等重要特性。
- Zeppelin 集群模式(Cluster Mode)
非集群模式,即只有一个ZeppelinServer,解释器可以运行在这个Server上,但若算法工程师数量很多,用户对服务可用性的要求可能无法满足。集群模式下,我们可以同时启动多个Zeppelin Server,基于Raft算法选主(Master)、同步,共同对外提供服务。用户通过Nginx反向代理域名访问这些Zeppelin服务。同时,集群模式还提供了Cluster元数据管理的能力,集群中所有的Zeppelin Server的运行状况,以及所有的解释器进程,都会记录在元数据中,用户可以通过Nginx配置访问不同的Server,创建不同的解释器。解释器进程可以在集群中自动寻找资源最为富余的Server来运行,而当某个Server挂了且难以恢复,用户仍然可以通过元数据启动另外一个Server,继续未完成的工作。Zeppelin集群模式只需在参数中配置3个服务器的列表,并将其启动,即可自动组建Zeppelin 集群,不需要借助ZooKeeper。通过专门的集群管理页面,用户可以清晰看到集群中的服务器、解释器的数量和运行状态。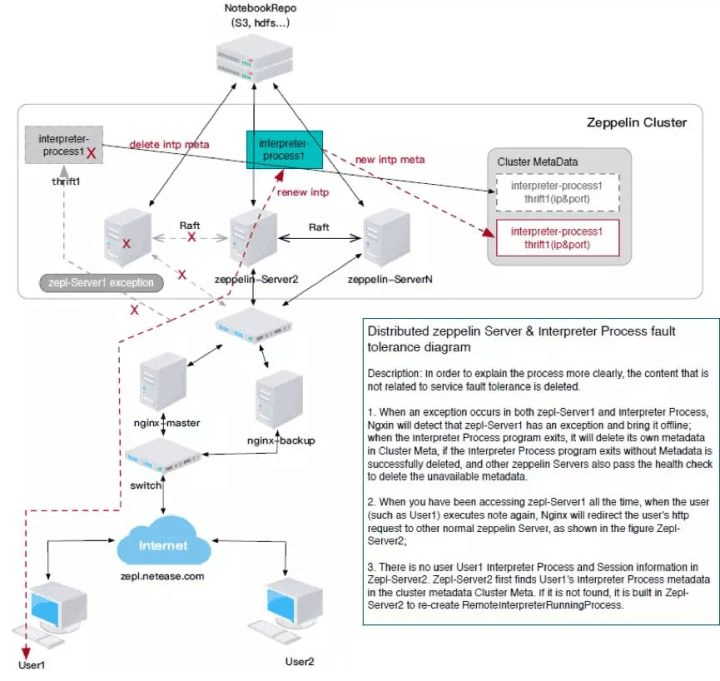
- 本机Docker
无论是单机模式还是集群模式,用户都可以在本机Docker上创建解释器进程。通过集群模式+Docker,用户不需要Yarn或者Kubernetes,即可创建Zeppelin集群,提供高可用服务,核心功能和Zeppelin On Yarn/ Kubernetes并无二致,而且部署和维护也很简单,无需复杂的网络配置。
- Zeppelin On Yarn
Zeppelin的解释器可以创建在Yarn的运行环境中,支持Yarn 2.7及以上的版本。Zeppelin容器的维护需要模拟终端,Zeppelin支持通过shell命令进入Docker进行维护,如安装所需的Python库、修改环境变量等。
- 多Hadoop集群
Zeppelin支持通过配置,即指定不同的Hadoop/Spark Conf文件,即可用一个Zeppelin集群,去连接所有的Hadoop集群,而无需为所有Hadoop集群分别创建多个Zeppelin服务,从而简化管理和维护的复杂度,同时保证服务的可靠性。
- 动态配置
Zeppelin提供服务接口,用户可以连接到自己的KDC或者LDAP认证系统,获取所需的信息,以便完成在不同的Hadoop集群上的操作。
- 模型预测与增量训练
Zeppelin支持通过Spark或者Flink的解释器,使用批处理或者流处理的方式,把用户新产生的数据结合后台的模型训练服务进行增量训练,并把训练出来的新模型保存到模型库中。
- 可视化调参
不同的机器学习框架有不同的参数配置,甚至不同的算法参数都不同,传统命令行的方式容易配置出错,Zeppelin基于其前端可视化展示能力,将支持针对每个算法自行设置一个参数调整界面,和模型一起发布,模型使用者可以使用该可视化界面,根据需要动态地调整参数。
- Zeppelin WorkFlow
用户可以在按照Zeppelin提供的一种类似Azkaban的数据格式,编写Node之间的依赖,下方形成一个可视化的WorkFlow图,通过拖拽的方式可以编排整个工作流,设置每个节点的动作。结合参数的配置,用户可以编写一个复杂的Zeppelin工作流,在右边设置触发的条件,如按时间点、Rest接口手动触发,或者按照周期性时间、数据变化来设置。
总结
Apache Zeppelin覆盖机器学习全流程,让数据科学工作者能够以可视化的方式,方便地编写机器学习算法、调参和进行机器学习任务管理。针对大数据任务的特点,Zeppelin也做了分布式的优化。同时,Zeppelin还能与其他Apache大数据生态项目也能很好地集成,可以更好地满足不同团队的需求。
参考
官网:Zeppelin官网
http://zeppelin.apache.org
GitHub:Zeppelin源码地址
https://github.com/apache/zeppelin
JIRA:Zeppelin JIRA
https://issues.apache.org/jira/projects/ZEPPELIN/summary
知乎:Apache Zeppelin: 让大数据插上机器学习的翅膀
https://zhuanlan.zhihu.com/p/71136801
CSDN:当Spark遇上Zeppelin
https://bruce.blog.csdn.net/article/details/86417429
InfoQ**:Flink on Zeppelin文章教程
- Flink on Zeppelin (1) - 入门篇
- Flink on Zeppelin (2) - Batch篇
- Flink on Zeppelin (3) - Streaming篇
- Flink on Zeppelin (4) - 机器学习篇
- Flink on Zeppelin (5) - 高级特性篇
- Flink on Zeppelin (6) - Recovering
- Flink on Zeppelin (7) - Yarn interpreter模式
- Flink on Zeppelin (8) - 常见问题FAQ
- Flink on Zeppelin (9) - Checkpoint & Savepoint
B站:Flink on Zeppelin视频教程
- Flink on Zeppelin 01. 安装启动Zeppelin
- Flink on Zeppelin 01. 补充Zeppelin基本概念
- Flink on Zeppelin 02. Local模式
- Flink on Zeppelin 03. 多语言支持
- Flink on Zeppelin 04. Remote模式
- Flink on Zeppelin 05. Yarn模式
- Flink on Zeppelin 06. Interpreter bind mode(Per Note Isolated)
- Flink on Zeppelin 07. Interpreter bind mode(Per User Isolated)
- Flink on Zeppelin 08. Inline Configuration
- Flink on Zeppelin 09. Hive Integration
- Flink on Zeppelin 10. SQL 入门
- Flink on Zeppelin 11. Streaming 数据可视化 Single模式
- Flink on Zeppelin 12. Streaming 数据可视化 Update模式
- Flink on Zeppelin 13. Streaming 数据可视化 Append模式
- Flink on Zeppelin 14. 连接kafka数据源
- Flink on Zeppelin 15. Streaming ETL
- Flink on Zeppelin 16. Scala UDF
- Flink on Zeppelin 17. Python DUF
- Flink on Zeppelin 18. UDF via flink.udf.jars
- Flink on Zeppelin 19. PyFlink 入门
- Flink on Zeppelin 20. Flink 最佳实践(1)
- Flink on Zeppelin 21. Flink 最佳实践(2)
- Flink on Zeppelin 22. Recovering
- Flink on Zeppelin 23. Yarn Interpreter模式
- Flink on Zeppelin 24. 架构和原理
- Flink on Zeppelin 25. Zeppelin Client API(1)
- Flink on Zeppelin 26. Zeppelin Client API(2)

若有收获,就点个赞吧
0 人点赞
