客户端连接
TTU
- 建议安装功能列表
- ODBC Driver for Teradata *
- BTEQ *
- Teradata SQL Assistant *
- OLEDB Access Module *
- .NET Data Provider for Teradata
安装完成后菜单路径:C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Teradata Client *。
- 配置
- 配置ODBC数据源。
点击菜单“ODBC Administrator”,进入后“添加”数据源,配置如下: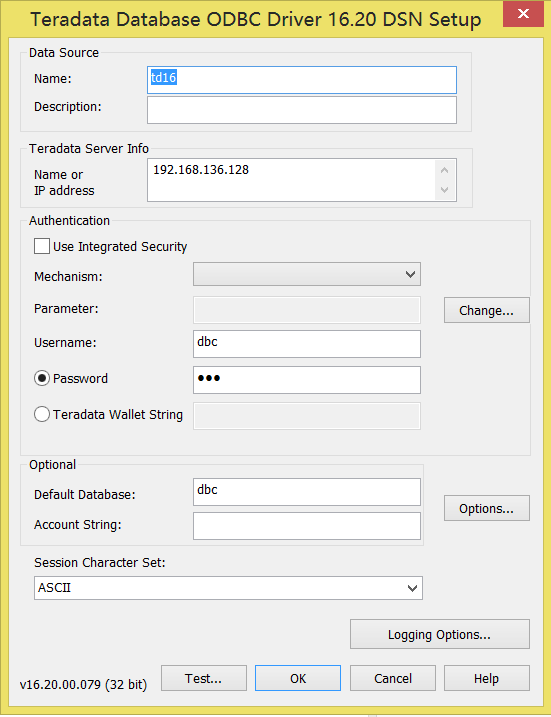
- 登录Teradata。
可以使用“Teradata BTEQ”、“Teradata BTEQwin”、“Teradata SQL Assistant”等客户端方式登录。“BTEQ”进入界面之后即可使用,“Teradata SQL Assistant”需要如下配置:
(1)“Data Provider”选择“ODBC”,点击“Connect….”,则之后选择已配置好的ODBC数据源即可。
(2)“Data Provider”选择“Teradata.N”,点击“Connect….”,则在弹出的界面需要如下配置: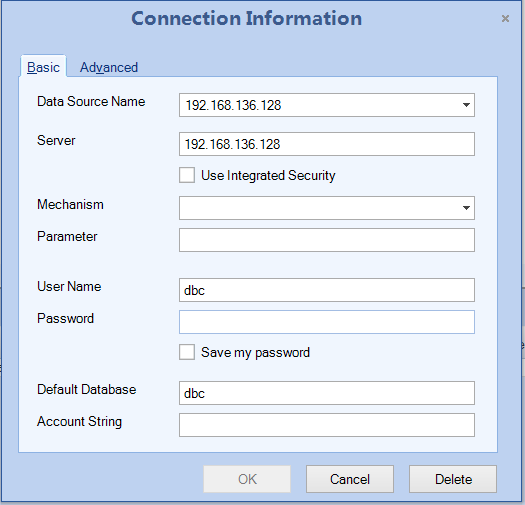
- 补充
如果安装失败,建议先安装TDNetDP(.NET Data Provider for Teradata),之后再重试。
https://downloads.teradata.com/download/connectivity/net-data-provider-for-teradata
BTEQ
客户端登录
bteq# dbc/dbc.LOGON 192.168.136.128/dbcSELECT * FROM "DBC".Indexes;
Perl调用
#!/usr/bin/perl# 通过管道调用BTEQmy $bteq_rc = open(BTEQ, "| bteq");unless ($bteq_rc) {print "Could not invoke BTEQ command\n";return -1;}print BTEQ <<ENDOFINPUT;.WIDTH 1024;.HELP BTEQ;ENDOFINPUT
JDBC
DBeaver如何连接Teradata数据库
https://jingyan.baidu.com/article/03b2f78cb45d751ea237aea8.html
基本SQL操作
用户操作
查看用户
select * from DBC.Databases where dbkind = 'U';
查看账户
SELECT UserId, AccountName, RowType FROM "DBC".Accounts;
创建用户
# 创建用户时,用户名,永久空间和密码的值是必需的。 其他字段是可选的。CREATE USER TD01ASPERMANENT = 1000000 BYTESPASSWORD = ABC$124TEMPORARY = 1000000 BYTESSPOOL = 1000000 BYTES;
创建用户(含账户)
CREATE USER TD02ASPERMANENT = 1000000 BYTESPASSWORD = abc$123TEMPORARY = 1000000 BYTESSPOOL = 1000000 BYTESACCOUNT = ('IT','Admin');
数据库操作
创建数据库 ```sql — 数据库perm大小为10G Create database testbase as perm=10E9,spool=10E9; DATABASE testbase;
/**
- 该命令创建了一个测试数据库testbase
- 其永久表空间为200mb,spool空间不超过100mb,语句中单位为bit
- 在Teradata数据库系统的缺省方式下,是不区分大小写字母的。 */ create database testbase as perm=200000000,spool=1000000000;
/**
- 改数据库的命令举例
- 该命令将 testbase 的永久表空间修改为300mb,spool空间不变 */ modify database testbase as perm=300000000; ```
删除数据库
-- 删除数据库,需要删除数据库中所有数据表,视图和宏。Delete database testbase;drop database testbase;
表操作
创建物理表
-- example-001create multiset table testbase.stg( stg decimal(18, 2) title '总贷款' ) no primary index ;-- example-002CREATE TABLE employee_bkup (EmployeeNo INTEGER,FirstName CHAR(30),LastName CHAR(30),DepartmentNo SMALLINT title '部门编号',NetPay INTEGER)Unique Primary Index(EmployeeNo);
创建可变临时表 ```sql — Database name, if specified, must be the login user name for a volatile table. — example-001 自定义表结构 create volatile multiset table dbc.vt_stg ,no log( stg decimal(18, 2)) no primary index on commit preserve rows; CREATE MULTISET VOLATILE TABLE employee_bkup_tmp3 ,NO FALLBACK , CHECKSUM = DEFAULT, NO LOG (
task_name VARCHAR(100) CHARACTER SET LATIN NOT CASESPECIFIC,count_num INTEGER,c3 VARCHAR(50) CHARACTER SET UNICODE NOT CASESPECIFIC)
PRIMARY INDEX ( task_name ) ON COMMIT PRESERVE ROWS ; — example-002 使用AS关键字按照指定库表结构创建易失性表 create multiset volatile table employee_bkup_tmp, NO FALLBACK, NO BEFORE JOURNAL, NO AFTER JOURNAL, NO LOG, CHECKSUM =DEFAULT AS testbase.employee_bkup WITH NO DATA ON COMMIT PRESERVE ROWS ;
— example-003 使用AS关键字按照指定库表结构创建易失性表,并扩展字段 — ext2、ext3定义的结构为:VARCHAR(1),即’ ‘的长度,如果需要特定长度,则需要CAST转变 create multiset volatile table employee_bkup_tmp29, NO FALLBACK, NO BEFORE JOURNAL, NO AFTER JOURNAL, NO LOG, CHECKSUM =DEFAULT as ( select t1.* ,cast(‘’ as varchar(50)) as ext1 ,’ ‘ as ext2 ,’ ‘ as ext3 from testbase.employee_bkup as t1 ) WITH NO DATA ON COMMIT PRESERVE ROWS ;
_**注意:易失性表不能修改表结构。**_- **添加表和字段注释**```sqlCOMMENT ON TABLE DMR_PT_ALT_CENTR_REPAY_ACCT_WHITE_LIST IS '集中还款账户白名单';COMMENT ON COLUMN DMR_PT_ALT_CENTR_PAY_ACCT_WHITE_LIST.Acct_Num IS '账户代号';
表结构更新(新增/删除)
-- 新增“BirthDate”,删除“NetPay”ALTER TABLE testbase.employee_bkupADD BirthDate DATE FORMAT 'YYYY-MM-DD',DROP NetPay;
表结构更新(修改)
因为不能通过“alter ”方式直接修改字段类型。要么先“alter drop”字段,再“alter add”字段。但是这样会丢失字段的数据。我们可以先通过“create tableA as (select … from tableB) with data; ” 再“drop table tableB”方式“曲线救国”。
create table access_log_1(CLIENT_IP,cost_time)as (select IP,cost_time (decimal(10,2)) from access_log)with data;drop table access_log;rename table acccess_log_1 to access_log;
表结构查看
show table "DBC".Acctg;
自增主键
- ID INTEGER GENERATED BY DEFAULT AS IDENTITY
- ID INTEGER GENERATED ALWAYS AS IDENTITY
示例:
CREATE TABLE test(ID INTEGER GENERATED BY DEFAULT AS IDENTITY(START WITH 100INCREMENT BY 1),CID INTEGER,PID INTEGER)-- 默认设定如下--(-- START WITH 100-- INCREMENT BY 1-- MINVALUE -2147483647-- MAXVALUE 2147483647-- NO CYCLE--)insert into test(CID,PID) values(1,1);insert into test(ID,CID,PID) values(1,1,1);insert into test(ID,CID,PID) values(110,1,1);-- GENERATED BY DEFAULT-- 运行成功,结果如下,可以插入指定的数值在列中1 1 1100 1 1110 1 1-- GENERATED ALWAYS-- 运行成功,结果如下,指定的数值会被忽略,转换为自动增长数值100 1 1101 1 1102 1 1
表查询
SELECT * FROM "DBC".Tables t2 where TableName like '%stg%';
字段查询
SELECT * FROM "DBC".columns where tablename like '%stg%';Select columnname,trim(columntitle) from dbc.columnsWhere databasename='DBC' and tablename like '%stg%'Order by columnid;
表数据查询
select * from testbase.stg;
数据转换
INSERT INTO employee_bkupSELECT a.EmployeeNo,a.FirstName,a.LastName,a.DepartmentNo,b.NetPayFROMEmployee a INNER JOIN Salary bON (a.EmployeeNo = b.EmployeeNo);
删除表
DROP TABLE employee_bkup;
视图操作
视图查询
SELECT * FROM "DBC".TablesV;
视图结构查看
show view "DBC".Tables;
取样查询
TOP N
select top x * from table;
Sample N
select * from table sample n;
进制转换
参考:https://www.cnblogs.com/badboy200800/p/10553695.html
SELECT from_bytes(HASHROW(khzhgxxlh), 'base10') from DIF_dev.DIF_KHKZGXB0527;
日期类型操作
抽取
-- 抽取年/月/日/时/分/秒SELECT EXTRACT (YEAR FROM CURRENT_DATE);SELECT EXTRACT (MONTH FROM CURRENT_DATE+90);SELECT EXTRACT (DAY FROM '1996-12-12');
差值计算
-- 日期差值(年/月/日)==只写day、month、year差值最大99天、99月、99年select (DATE'1995-02-02' - DATE'1995-01-01') day(4); -- 天数,差值最大9999天。select (date '1908-05-01' - date '1900-01-01') month(4); -- 月数,差值最大9999月。select (DATE'1999-02-02' - DATE'1995-01-01') year(4); -- 年数,差值最大9999年。-- 时间差值(小时/分/秒)select (TIMESTAMP '2009-08-25 19:14:59' - TIMESTAMP '2009-08-25 15:14:59') HOUR(4) -- 小时,差值最大9999hselect (TIMESTAMP '2009-08-25 19:14:59' - TIMESTAMP '2009-08-25 15:14:59') MINUTE(4) -- 分钟,差值最大9999mselect (TIMESTAMP '2009-08-25 15:15:59' - TIMESTAMP '2009-08-25 15:14:59') Second(4) -- 秒,差值最大9999sSELECT MONTHS_BETWEEN(DATE'1995-02-02', DATE'1995-01-01'); -- 月数SELECT ADD_MONTHS ('1999-08-15' , 1); -- 返回1999-09-15SELECT ADD_MONTHS ('1999-09-30' , -1); -- 返回1999-08-30
特定日期
-- 返回当月月底日期SELECT LAST_DAY(DATE '2009-12-20'); -- 返回2019-12-31SELECT LAST_DAY(TIMESTAMP '2009-08-25 10:14:59'); -- 返回2009-08-31-- 返回下一个周几日期SELECT NEXT_DAY(DATE '2009-12-20', 'TUESDAY'); -- 返回2009-12-22SELECT NEXT_DAY(DATE '2009-12-20', 'FRIDAY'); -- 返回2009-12-20
日期转换
SELECT CAST('20131230' as date format 'YYYYMMDD');SELECT CAST(CURRENT_DATE as date format 'YYYYMMDD');
数据倾斜
Teradata是MPP架构的数据库,因此它也面临着“木桶效应”的问题。何为木桶效应,简单说就是一个木桶能装多少水并不是由这个木桶最长的那个木板决定,而是有最短的那个决定的。适用在Teradata上可以理解为整个数据库的性能并不由最先完成数据处理的节点决定的,而是由那个最慢的节点决定的。因此假设一个节点过慢必将 拖慢整个数据处理的任务。而,“数据倾斜”将引发“木桶效应”,因此我们必须将我们大表的倾斜度控制在一个指标之内。 利用TableSize 这个视图我们可以检索出我们仓库数据倾斜度不在我们指标之内的。
- 数据倾斜度计算。
Teradata数据倾斜度的计算方法为:Skew = (max-avg)/avg*100
SELECT T1.DATABASENAME, -- 库名T1.TABLENAME, -- 表名T1.SPACE_SUM, -- 表大小T1.SPACE_MAX, -- 最大AMP大小T1.SPACE_AVG, -- 平均AMP大小T1.SKEWFACTOR -- PI倾斜度FROM (SELECT DATABASENAME,TABLENAME,SUM(CURRENTPERM)*1.0000000 / 1000 / 1000 AS SPACE_SUM,MAX(CURRENTPERM)*1.0000000 / 1000 / 1000 AS SPACE_MAX,AVG(CURRENTPERM)*1.0000000 / 1000 / 1000 AS SPACE_AVG,(SPACE_MAX - SPACE_AVG) / SPACE_MAX * 100 AS SKEWFACTORFROM DBC.TABLESIZEWHERE DATABASENAME = 'DTEMP'AND UPPER(TABLENAME) NOT LIKE '%_MI_%'AND UPPER(TABLENAME) NOT LIKE '%_MS_%'GROUP BY 1, 2) T1WHERE T1.SKEWFACTOR >= 30ORDER BY SKEWFACTOR DESC;
数据分布查看。
SELECT HASHAMP(HASHBUCKET(HASHROW(khzhgxxlh))) AS "AMP",COUNT(HASHAMP(HASHBUCKET(HASHROW(khzhgxxlh)))) AS ROW_COUNTFROM DIF_dev.DIF_KHKZGXB0527GROUP BY 1ORDER BY 2;-- 函数说明--1. HASHROW (column(s)) # 计算row的hash值--2. HASHBUCKET (hashrow) # 根据hashrow计算hashbucket,代表了一个hashmap的入口--3. HASHAMP (hashbucket) # 根据hashbucket确定数据分布到哪一个AMP
基本函数
正则
regexp_similar函数
-- 功能:查看字符串是否包含某子串,包含则返回1,不包则含返回0。selectregexp_similar('iuh()87%^&6888','.*[0-9]{4}') --是以4个0-9的数字结尾的字符串,返回1,regexp_similar('iuh()87%^&6888dkfj','.*[0-9]{4}') --不是以4个0-9的数字结尾的字符串,返回0
regexp_instr函数
-- 功能:查看字符串包含某子串的位置,包含则返回首个匹配位置,不包含则返回0selectregexp_instr('我的998','app') --不包含app,返回0,regexp_instr('我的998app','app') --包含一个app,返回子串位置8,regexp_instr('我的apple998app','app') --包含两个app,返回第一个子串位置5
regexp_substr函数
-- 功能:返回第一个匹配的子串selectregexp_substr('我的apple998','[a-z]{5}') --返回第一个连续5个小写字母apple,regexp_substr('我的aaaae998我的apple008','[a-z]{5}') --返回第一个连续5个小写字母aaaae
regexp_replace函数
-- 功能:替换所有匹配子串selectregexp_replace('我的apple998','[a-z]{5}','pp') --替换apple为pp,结果为"我的pp998",regexp_replace('我的aaaae998我的apple008','[a-z]{5}','pp') --替换aaaae和apple为pp,结果为"我的pp998我的pp008"
权限控制
-- 授予权限GRANT SELECT,INSERT,UPDATE ON Employee TO TD01;-- 撤销特权REVOKE INSERT,SELECT ON Employee FROM TD01;
自定义函数(UDF)
示例:(md5函数)
下载md5函数相关压缩包。
https://downloads.teradata.com/download/extensibility/md5-message-digest-udf
解压缩。
unzip md5_20080530.zip# 进入src目录,并在该目录下编辑UDF安装脚本或执行BTEQcd md5/srcvi mdt_install.pl
编写Perl安装UDF脚本(或进入BTEQ执行)。 ```perl
!/usr/bin/perl
my $bteq_rc = open(BTEQ, “| bteq”); unless ($bteq_rc) { print “Could not invoke BTEQ command\n”; return -1; } print BTEQ <<ENDOFINPUT; .LOGON 192.168.136.128/dbc,dbc; database syslib; .run file = hash_md5.btq; SELECT hash_md5(‘a’),hash_md5(‘b’); .LOGOFF; ENDOFINPUT
4. 执行脚本。```bashperl mdt_install.pl
运行结果。 ``` +————-+————-+————-+————-+————-+————-+————-+—— SELECT hash_md5(‘a’),hash_md5(‘b’);
Query completed. One row found. 2 columns returned. Total elapsed time was 2 seconds.
hash_md5(‘a’) hash_md5(‘b’)
0CC175B9C0F1B6A831C399E269772661 92EB5FFEE6AE2FEC3AD71C777531578F
+————-+————-+————-+————-+————-+————-+————-+——
6. 清理安装文件。```bashcd ../../rm -rf md5
导入导出
导入(FastLoad)
FastLoad实用程序用于将数据加载到空表。 由于它不使用临时日志,因此可以快速加载数据。 即使目标表是MULTISET表,它也不会加载重复行。
局限性
FastLoad如何工作
FastLoad在两个阶段执行。
- 阶段1
解析引擎从输入文件中读取记录,并向每个AMP发送一个块。每个AMP存储记录块。然后AMP散列每个记录,并将它们重新分配到正确的AMP。在阶段1结束时,每个AMP具有其行,但它们不在行哈希序列中。
- 阶段2
阶段2在FastLoad接收到END LOADING语句时启动。每个AMP对行散列上的记录进行排序,并将它们写入磁盘。释放目标表上的锁,并删除错误表。
示例
定长方式导入
LOGON 192.168.136.128/dbc,dbc;DATABASE DIF_dev;DROP TABLE DIF_dev.error_1;DROP TABLE DIF_dev.error_2;set record unformatted;DEFINEin_khzhgxxlh (CHAR(20)),delim0 (CHAR(1)),in_cjsj (CHAR(19)),delim1 (CHAR(1)),in_gxsj (CHAR(19)),newlinechar (CHAR(1))FILE = fast_export.txt;SHOW;BEGIN LOADING DIF_dev.DIF_KHKZGXB0527ERRORFILES error_1, error_2;locking table DIF_KHKZGXB0527 for accessINSERT INTO DIF_KHKZGXB0527 (khzhgxxlh,nbbsh,khzhlx,khkzdh,dqdh,pzzl,pzxh,pzdh,zhdh,qkfs,pzsyzt,xyklb,zjlx,zjhm,khxm,yxrybh,cjsj,jingdu1,cjgy,cjjg,cjxt,gxsj,jingdu2,gxgy,gxjg,gxxt,jlzt)VALUES (:in_khzhgxxlh,'','','','','','','','','','','','','','','',:in_cjsj,'','','','',:in_gxsj,'','','','','');END LOADING;LOGOFF;
可变长度导入
LOGON 192.168.136.128/dbc,dbc;DATABASE DIF_dev;DROP TABLE DIF_dev.error_1;DROP TABLE DIF_dev.error_2;BEGIN LOADING DIF_dev.DIF_KHKZGXB0527ERRORFILES error_1, error_2;SET RECORD VARTEXT ",";DEFINEin_khzhgxxlh (VARCHAR(20)),in_cjsj (VARCHAR(19)),in_gxsj (VARCHAR(19))FILE = fast_export.txt;SHOW;locking table DIF_KHKZGXB0527 for accessINSERT INTO DIF_KHKZGXB0527 (khzhgxxlh,nbbsh,khzhlx,khkzdh,dqdh,pzzl,pzxh,pzdh,zhdh,qkfs,pzsyzt,xyklb,zjlx,zjhm,khxm,yxrybh,cjsj,jingdu1,cjgy,cjjg,cjxt,gxsj,jingdu2,gxgy,gxjg,gxxt,jlzt)VALUES (:in_khzhgxxlh,'','','','','','','','','','','','','','','',:in_cjsj,'','','','',:in_gxsj,'','','','','');END LOADING;LOGOFF;
调用导入脚本:
fastload < fast_load.fl;
导出(FastExport)
FastExport实用程序用于将Teradata表中的数据导出为平面文件。 它还可以生成报告格式的数据。 可以使用Join从一个或多个表中提取数据。 由于FastExport导出64K块中的数据,因此它可用于提取大量数据。
- 编写导出脚本。
注意:.LOGTABLE DIF_dev.fast_export_log;.LOGON 192.168.136.128/dbc,dbc;DATABASE DIF_dev;.BEGIN EXPORT SESSIONS 2;.EXPORT OUTFILE fast_export.txtMODE RECORD FORMAT TEXT;SELECT CAST(khzhgxxlh AS CHAR(20)),CAST(',' AS CHAR(1)),CAST(cjsj AS TIMESTAMP(0) FORMAT 'YYYYMMDDHHMISS' ),CAST(',' AS CHAR(1)),CAST(gxsj AS TIMESTAMP(0) FORMAT 'YYYYMMDDHHMISS' )FROMDIF_KHKZGXB0527;.END EXPORT;.LOGOFF;
- 日志表(示例为:DIF_dev.fast_export_log)无需提前创建,FastExport程序将自动创建并删除。
- 数据卸载下来时如果要转型需要转换为char型,不支持转换为varchar。
- 字段分隔符需要自行拼接(如上:“,CAST(‘,’ AS CHAR(1))”),无相关参数配置。
调用导出脚本。
# 语法:fexp -b < inputfilename > outputfilename# -b : 输出简单的output# inputfilename : 导出脚本,一般以.fx为后缀# outputfilename : 输出日志fexp -b < fast_export.fx > fast_export.log
常见错误
“ [Error 3535] [SQLState 22003] A character string failed conversion to a numeric value.”
-- 解决方案1'${TX_DATE}' || ''-- 解决方案2CAST('${TX_DATE}' AS DATE FORMAT 'YYYYMMDD')-- 解决方案3TO_DATE('${TX_DATE}', 'YYYYMMDD')
DBeaver中文乱码。
解决方案:
URL添加配置:“CHARSET=ASCII,TMODE=TERA,CLIENT_CHARSET=GBK”,如:“jdbc:teradata://192.168.136.128/DATABASE=dbc,DBS_PORT=1025,CHARSET=ASCII,TMODE=TERA,CLIENT_CHARSET=GBK”
参考
bbsmax:【Teradata TTU】Windows TTU安装工具列表
https://www.bbsmax.com/A/o75Nv4EX5W
博客园:【Teradata SQL】十进制转换成二进制
https://www.cnblogs.com/badboy200800/p/10553695.html

若有收获,就点个赞吧
0 人点赞
