方案背景
HBase的索引方案有很多,越来越多的人开始选择ES+HBase的方案,其实该方案并没有想象中那么完美,ES并发低,同时查询速度相对Hbase也慢很多,那为什么会选择它呢?HBase的写入比较快,如果一个宽表需要创建20个索引,在数据导入时,HBase每秒导入20W,那么ES压力就是每秒400W,Solr和HIndex(华为)都不能解决该问题。对并发高的业务场景,建议使用HIndex方案,也可以混合使用。
方案描述
ES+Hbase对接大致有两种方式,需要根据当前的业务场景做相应的选择。
方案1:
如果是对写入数据性能要求高的业务场景,那么一份数据先写到HBase,然后再写到ES中,两个写入流程独立,这样可以达到性能最大,目前某公安厅使用该方案,每天需要写入数据200亿,6T数据,每个记录建20左右的索引。缺点是可能存在数据的不一致性。
方案2:
这也是目前网上比较流行的方案,使用HBase的协处理器监听Hbase中的数据变动,实时更新ES中的索引。缺点是协处理器会影响HBase的性能
总体思路
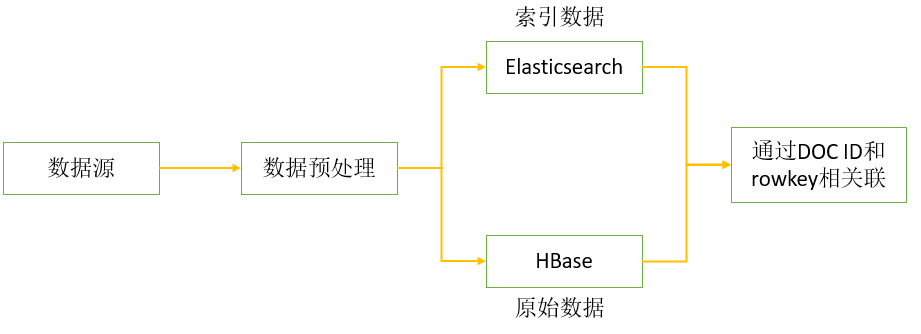
将源数据根据业务特点划分为索引数据和原始数据:
- 索引数据:指需要被检索的字段,存储在Elasticsearch集群中;
- 原始数据:指不需要被ES检索的字段,包括某些超长的文本数据等,存储在Hbase集群中。
将HBase的rowkey设定为ES的文档ID,搜索时根据业务条件先从ES里面全文检索出相对应的文档,从而获取出文档ID,即拿到了rowkey,再从HBase里面抽取数据。
优缺点
优点
- 发挥了Elasticsearch的全文检索的优势,能够快速根据关键字检索出相关度最高的结果;
- 同时减少了Elasticsearch的存储压力,这种场景下不需要存储检索无关的内容,甚至可以禁用_source,节约一半的存储空间,同时提升最少30%的写入速度;
- 避免了Elasticsearch大数据量下查询返回慢的问题,大数据量下Hbase的抽取速度明显优于Elasticsearch;
-
缺点
两个组件之间存在时效不一致的问题;
相对而言,Elasticsearch的入库速度肯定是要快于Hbase的,这是需要业务容忍一定的时效性,对业务的要求会比较高。
- 同时管理两个组件增加了管理成本;
案例
语雀:基于ES+HBase的文章检索
https://www.yuque.com/polaris-docs/bigdata/es_hbase_article
参考
CSDN:【Elasticsearch】优秀实践-ES+Hbase的实现
https://blog.csdn.net/wudingmei1023/article/details/103914052
CSDN:Elasticsearch+Hbase实现海量数据秒回查询
https://blog.csdn.net/sdksdk0/article/details/53966430
期刊网:基于HBase+ElasticSearch的海量交通数据实时存取方案设计
http://www.infocomm-journal.com/bdr/article/2017/2096-0271/2096-0271-3-1-00080.shtml
博客园:ES+Hbase对接方案概述
https://www.cnblogs.com/gaoxing/p/5267512.html

若有收获,就点个赞吧
0 人点赞
