前言
Flink提供的Metrics可以在Flink内部收集一些指标,通过这些指标让开发人员更好地理解作业或集群的状态。由于集群运行后很难发现内部的实际状况,跑得慢或快,是否异常等,开发人员无法实时查看所有的Task日志,比如作业很大或者有很多作业的情况下,该如何处理?此时Metrics可以很好的帮助开发人员了解作业当前状况。对于很多大中型企业来讲,我们对进群的作业进行管理时,更多的是关心作业精细化实时运行状态。例如,实时吞吐量的同比环比、整个集群的任务运行概览、集群水位,或者监控利用 Flink 实现的 ETL 框架的运行情况等,这时候就需要设计专门的监控系统来监控集群的任务作业情况。
Flink Metric架构
Flink Metrics是Flink实现的一套运行信息收集库,我们不但可以收集Flink本身提供的系统指标,比如CPU、内存、线程使用情况、JVM垃圾收集情况、网络和IO等,还可以通过继承和实现指定的类或者接口打点收集用户自定义的指标。
通过使用Flink Metrics我们可以轻松地做到:
- 实时采集Flink中的Metrics信息或者自定义用户需要的指标信息并进行展示;
- 通过Flink提供的Rest API收集这些信息,并且接入第三方系统进行展示。
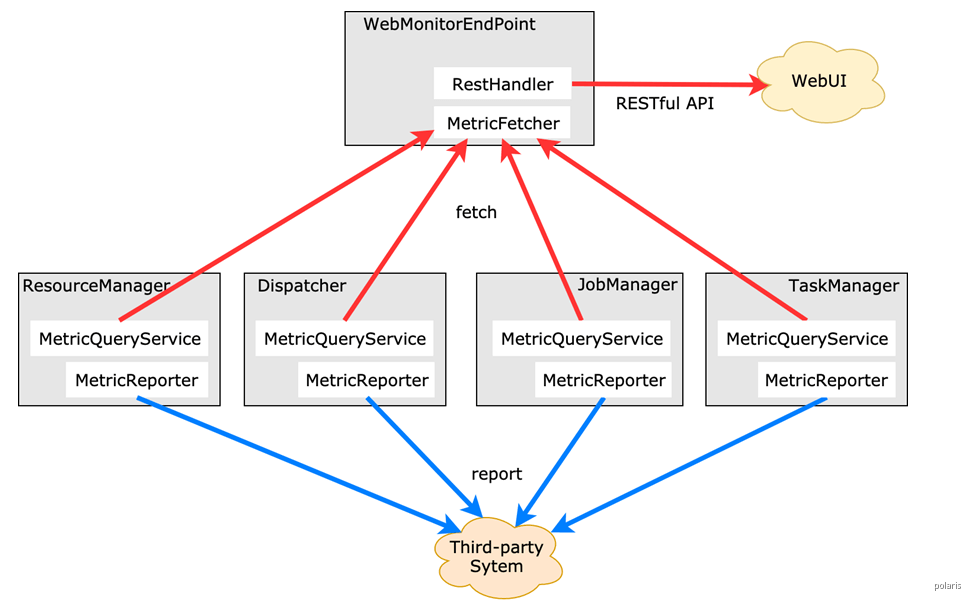
监控架构
从Flink Metrics架构来看,指标获取方式有两种。一是REST-ful API,Flink Web UI中展示的指标就是这种形式实现的。二是reporter,通过reporter可以将metrics发送给外部系统。Flink内置支持JMX、Graphite、Prometheus等系统的reporter,同时也支持自定义reporter。
由于Flink Web UI所提供的metrics数量较少,也没有时序展示,无法满足实际生产中的监控需求。Prometheus+Grafana是业界十分普及的开源免费监控体系,上手简单,功能也十分完善。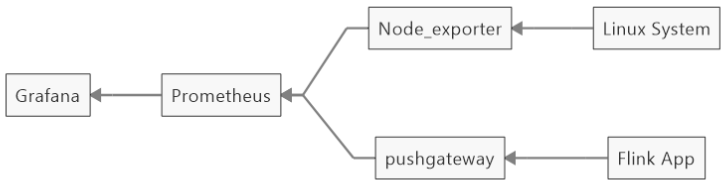
方案实施
Flink内置有两种支持Prometheus的reporter,PrometheusReporter和PrometheusPushGatewayReporter。
PrometheusReporter是开放端口给Prometheus拉取,PrometheusPushGatewayReporter是将metrics推送给Prometheus下的一个插件PushGateway,Prometheus从PushGateway拉取metrics。实际操作中,PrometheusReporter提供的metrics比较有限,不建议使用。要使用PrometheusPushGatewayReporter或PrometheusReporter,需要将flink-metrics-prometheus-..*.jar上传至lib目录下,然后修改配置文件flink-conf.yaml。
资源规划
| 组件 | bigdata-node1 | bigdata-node2 | bigdata-node3 |
|---|---|---|---|
| OS | centos7.6 | centos7.6 | centos7.6 |
| JDK | jvm | jvm | jvm |
| Flink | StandaloneSessionClusterEntrypoint | TaskManagerRunner | TaskManagerRunner |
| Prometheus | prometheus/pushgateway | N.A | N.A |
安装介质
版本:flink-1.10.0-src.tgz
下载:https://archive.apache.org/dist/flink
环境准备
安装JDK
安装Flink
安装Prometheus
参考:《CentOS7.6-安装Prometheus-2.10.0》
实施步骤
1. 添加依赖jar包
| 依赖包 | 下载站点 |
|---|---|
| flink-metrics-prometheus-1.10.0.jar | Flink安装包/opt目录下 |
依赖jar包准备,将jar包直接复制到$FLINK_HOME/lib目录下:
# 注意:所有flink节点执行sudo cp /share/flink/flink-metrics-prometheus-1.10.0.jar ~/modules/flink-1.10.0/lib
2. 修改Flink配置
更新配置文件:
vi ~/modules/flink-1.10.0/conf/flink-conf.yaml
内容如下:
metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReportermetrics.reporter.promgateway.host: 192.168.0.101metrics.reporter.promgateway.port: 9091metrics.reporter.promgateway.jobName: pushgatewaymetrics.reporter.promgateway.randomJobNameSuffix: truemetrics.reporter.promgateway.deleteOnShutdown: true
分发配置:
scp -r ~/modules/flink-1.10.0/conf/flink-conf.yaml vagrant@bigdata-node2:~/modules/flink-1.10.0/conf/scp -r ~/modules/flink-1.10.0/conf/flink-conf.yaml vagrant@bigdata-node3:~/modules/flink-1.10.0/conf/
3. Prometheues配置
sudo vi /usr/local/prometheus/prometheus.yml
配置如下(scrape_configs节点):
- job_name: 'pushgateway'static_configs:- targets: ['192.168.0.101:9091']labels:instance: 'pushgateway'
重启Prometheus服务:
sudo systemctl restart prometheus.service
仪表板制作
前提:
- 启动Flink集群;
- 启动Grafana;
- 启动Prometheus(包含:Pushgateway);
- 登录Grafana;(http://192.168.0.101:3000)
- 添加Prometheus数据源;(http://192.168.0.101:9090)
- 展示Flink Metric;(https://grafana.com/grafana/dashboards,搜索flink模板并下载,推荐:Linux主机监控模板:9276;Flink集群监控模板:11049、8966、10369)
附录
附录:A.Flink Metric配置说明
| Key | Default | Description | | :—- | :—- | :—- | | deleteOnShutdown | true | Specifies whether to delete metrics from the PushGateway on shutdown. | | filterLabelValueCharacters | true | Specifies whether to filter label value characters. If enabled, all characters not matching [a-zA-Z0-9:_] will be removed, otherwise no characters will be removed. Before disabling this option please ensure that your label values meet the Prometheus requirements. | | host | (none) | The PushGateway server host. | | jobName | (none) | The job name under which metrics will be pushed | | port | -1 | The PushGateway server port. | | randomJobNameSuffix | true | Specifies whether a random suffix should be appended to the job name. |
- 参数说明
JobName可以理解为本次reporter推送任务的id,配合randomJobNameSuffix为true,不同集群推送到同一pushgateway的数据可以被区分。但randomJobNameSuffix为true也使得集群如果重启,JobName会不同,会识别为两个集群。建议“metrics.reporter.promgateway.randomJobNameSuffix: true”和“metrics.reporter.promgateway.deleteOnShutdown: true”配合使用。如果deleteOnShutdown为false,集群发生重启后,pushgateway里面会存在同一集群的两套metrics信息,并且之前的metrics信息会永不更新。

若有收获,就点个赞吧
0 人点赞
