ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS), 来自俄罗斯最大的搜索公司Yandex
官网地址:https://clickhouse.tech
源码地址:https://github.com/ClickHouse/ClickHouse
1 安装部署
1.1 下载最新版本
export LATEST_VERSION=$(curl -s https://repo.clickhouse.tech/tgz/stable/ | \
grep -Eo ‘[0-9]+.[0-9]+.[0-9]+.[0-9]+’ | sort -V -r | head -n 1)
curl -O https://repo.clickhouse.tech/tgz/stable/clickhouse-common-static-$LATEST_VERSION.tgz
curl -O https://repo.clickhouse.tech/tgz/stable/clickhouse-common-static-dbg-$LATEST_VERSION.tgz
curl -O https://repo.clickhouse.tech/tgz/stable/clickhouse-server-$LATEST_VERSION.tgz
curl -O https://repo.clickhouse.tech/tgz/stable/clickhouse-client-$LATEST_VERSION.tgz
1.2 单机部署执行
1.2.1 服务端安装
tar -xzvf clickhouse-common-static-$LATEST_VERSION.tgz
sudo clickhouse-common-static-$LATEST_VERSION/install/doinst.sh
tar -xzvf clickhouse-common-static-dbg-$LATEST_VERSION.tgz
sudo clickhouse-common-static-dbg-$LATEST_VERSION/install/doinst.sh
tar -xzvf clickhouse-server-$LATESTVERSION.tgz
sudo clickhouse-server-$LATEST_VERSION/install/doinst.sh
执行成功将出现提示
_Created symlink from /etc/systemd/system/multi-user.target.wants/clickhouse-server.service to /etc/systemd/system/clickhouse-server.service.
Path to data directory in /etc/clickhouse-server/config.xml: /var/lib/clickhouse/
_
1.2.2 启动clickhouse服务
sudo /etc/init.d/clickhouse-server restart
1.2.3 客户端安装
tar -xzvf clickhouse-client-$LATEST_VERSION.tgz
sudo clickhouse-client-$LATEST_VERSION/install/doinst.sh
1.2.4 验证
clickhouse-client —query “select 1”
1.2.5 远程访问
修改/etc/clickhouse-server/config.xml 取消注释
1.2.6 修改请求端口
默认http访问端口8123,默认tcp访问端口9000
修改/etc/clickhouse-server/config.xml中对应的端口值
1.2.7 修改数据库数据文件路径
修改/etc/clickhouse-server/config.xml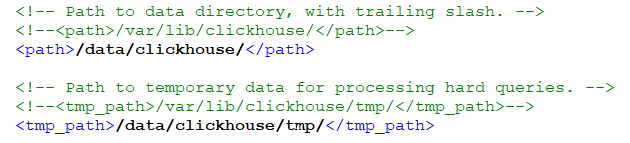
1.3 集群部署
1.3.1 机器信息
LTSR005 192.168.0.15
LTSR006 192.168.0.16
LTSR007 192.168.0.15
前提条件:3台上面安装部署好zk集群
1.3.2 创建配置文件/etc/metrika.xml
默认这个配置文件是不存在的,/etc/clickhouse-server/config.xml有提示,如下:
If element has ‘incl’ attribute, then for it’s value will be used corresponding substitution from another file.
By default, path to file with substitutions is /etc/metrika.xml. It could be changed in config in ‘include_from’ element.
Values for substitutions are specified in /yandex/name_of_substitution elements in that file.
配置文件内容如下:
3台机器的配置文件都一样,唯一有区别的是:
1.3.3 重启三个节点clickhouse服务
sudo /etc/init.d/clickhouse-server restart
1.3.4 查询验证集群信息
clickhouse-client —query “select * from system.clusters”
1.3.5 创建本地表
CREATE TABLE ontime_local (FlightDate Date,Year UInt16) ENGINE = MergeTree(FlightDate, (Year, FlightDate), 8192);
注意3个节点上需要分别执行
1.3.6 创建Distributed 表
CREATE TABLE ontimeall AS ontime_local ENGINE = Distributed(perftest_3shards_1replicas, default, ontime_local, rand())
perftest_3shards_1replicas为集群的名称
default 为数据库名称
ontime_local 为本地表名
rand 数据分布方式(随机分布)
注意:
- 由于搭建的是Clickhouse集群环境,建表时需要在集群节点上创建一个Distributed的表,在每个分片节点创建MergeTree的表。在数据导入和查询时直接操作Distributed表,Distributed表会自动路由到相应的MergeTree表。
- Hive中的数据类型,在Clickhouse中都有对应的类型名称:比如bigint -> Int64, int -> Int32, float -> Float32,需要按照Clickhouse的类型定义各个字段。
- Clickhouse的字段默认是不允许为NULL的,如果数据有可能为NULL,需要将字段定义为类似Nullable(Int64)的类型。
- 创建MergeTree表,需要设置分区字段和排序字段,排序字段一般会选择将经常聚合的维度排在前面,如果不清楚常用查询场景的话,和分区字段一致就可以了。
- 创建Distributed表,不需要分区字段和排序字段,但要注意在Clickhouse的集群节点创建,不要在分片节点创建。
1.3.7 插入数据
insert into ontime_local (FlightDate,Year)values('2010-03-20',2010);insert into ontime_local (FlightDate,Year)values('2011-03-20',2011);insert into ontime_local (FlightDate,Year)values('2012-03-20',2012);
2 数据导入
将CSV文件导入到clickhouse数据库中
1、在数据库中建立相应的表
2、将csv文件进行导入
导入的CSV文件没有字段名称时:
cat /data/clickhouse/1.csv | clickhouse-client —query=”INSERT INTO 数据库.表名 FORMAT CSV”
导入的CSV文件有字段名称时
cat csv文件路径 | clickhouse-client —query=”INSERT INTO 数据库.表名 FORMAT CSVWithNames”
注意:
- 如果表的字段是Nullable的话,在csv文件中,对应列的值应该为\N,否则将无法导入。
- 由于将csv文件导入,执行的是INSERT语句,因此在导入前需要先Drop相应的分区,保证数据不会重复导入。但是Drop的操作需要直接在分片节点操作,因此需要找到分片节点。可以在每个分片节点的system.parts表中,查看该分片上包含哪些分区,如果存在的话则可以进行Drop操作。
- 参考代码
# 将csv中的NULL替换为\Nsed -i "s/NULL/\\\N/g" data.csv# drop分区已有的数据(需要找到对应的分片节点)clickhouse-client -h 10.128.184.59 --port 9000 -d ad_test -u ad_test --password adxxx --query="alter table t drop partition('2019-10-01')"# 导入数据到Clickhouse中cat data.csv | clickhouse-client -h 10.128.184.59 --port 8000 -d ad_test -u ad_test --password adxxx --format_csv_delimiter="|" --query="insert into t format CSV"
其他格式文件详见 https://zhuanlan.zhihu.com/p/161397267
- tabseparated系列格式
- tskv格式
- csv系列格式
- json系列格式
- parquet格式
- orc格式
- 其他常用的数据格式
3 适用场景和不适用场景
3.1 适用场景
- 绝大多数请求都是用于读访问的
- 数据需要以大批次(大于1000行)进行更新,而不是单行更新;或者根本没有更新操作
- 数据只是添加到数据库,没有必要修改
- 读取数据时,会从数据库中提取出大量的行,但只用到一小部分列
- 表很“宽”,即表中包含大量的列
- 查询频率相对较低(通常每台服务器每秒查询数百次或更少)
- 对于简单查询,允许大约50毫秒的延迟
- 列的值是比较小的数值和短字符串(例如,每个URL只有60个字节)
- 在处理单个查询时需要高吞吐量(每台服务器每秒高达数十亿行)
- 不需要事务
- 数据一致性要求较低
- 每次查询中只会查询一个大表。除了一个大表,其余都是小表
查询结果显著小于数据源。即数据有过滤或聚合。返回结果不超过单个服务器内存大小
3.2 不适用场景
不支持真正的删除/更新支持 不支持事务
- 不支持二级索引
- 有限的SQL支持,join实现与众不同
- 不支持窗口功能
- 元数据管理需要人工干预维护
4 注意事项
4.1 聚合指标不能同时出现在两个select字段中
SELECTsum(charged_fees) AS charged_fees,sum(conversion_count) AS conversion_count,(sum(charged_fees) / sum(conversion_count)) / 100000 AS conversion_costFROM tWHERE dt = '2019-07-01'Received exception from server (version 19.1.9):Code: 184. DB::Exception: Received from 10.128.184.59:9000. DB::Exception: Aggregate function sum(charged_fees) is found inside another aggregate function in query.0 rows in set. Elapsed: 0.041 sec.
需改写为
SELECTsum(charged_fees) AS charged_fees,sum(conversion_count) AS conversion_count,(charged_fees / conversion_count) / 100000 AS conversion_costFROM tWHERE dt = '2019-07-01'┌──charged_fees─┬─conversion_count─┬────conversion_cost─┐│ 3143142724482 │ 250537 │ 150.37090954370022 │└───────────────┴──────────────────┴────────────────────┘1 rows in set. Elapsed: 0.155 sec. Processed 32.56 million rows, 1.20 GB (210.00 million rows/s., 7.77 GB/s.)
4.2 要用大表 join 小表
4.3 如何快速地把HDFS中的数据导入ClickHouse
参考https://blog.csdn.net/huochen1994/article/details/83827587

若有收获,就点个赞吧
0 人点赞
