一、非kerberos环境下程序开发
1、测试环境
1.1、组件版本
- Intellij IDEA开发工具
- 未启用kerberos
2、环境准备
2.1、IDEA的Scala环境
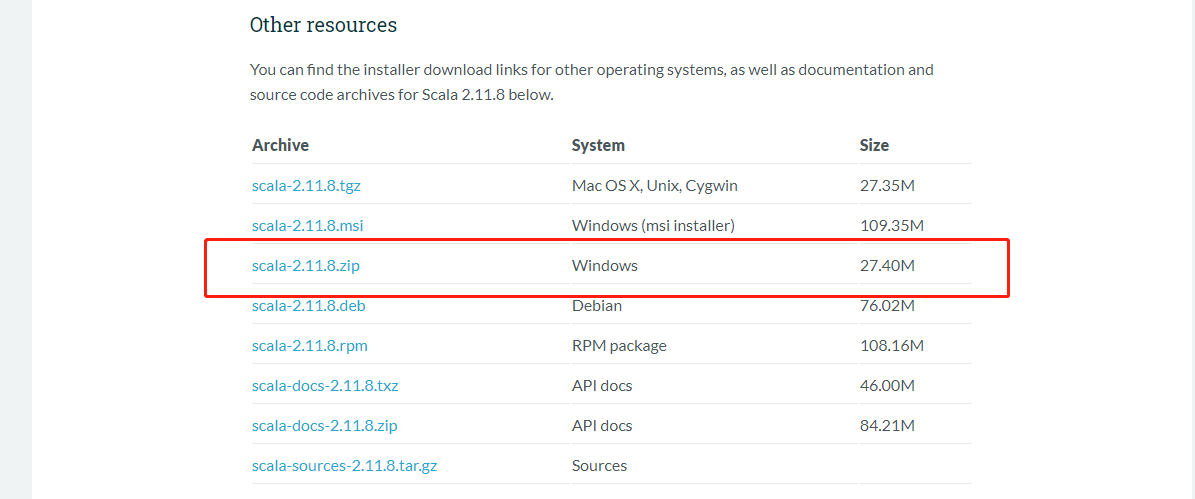
- 创建maven项目,导入Scala-sdk
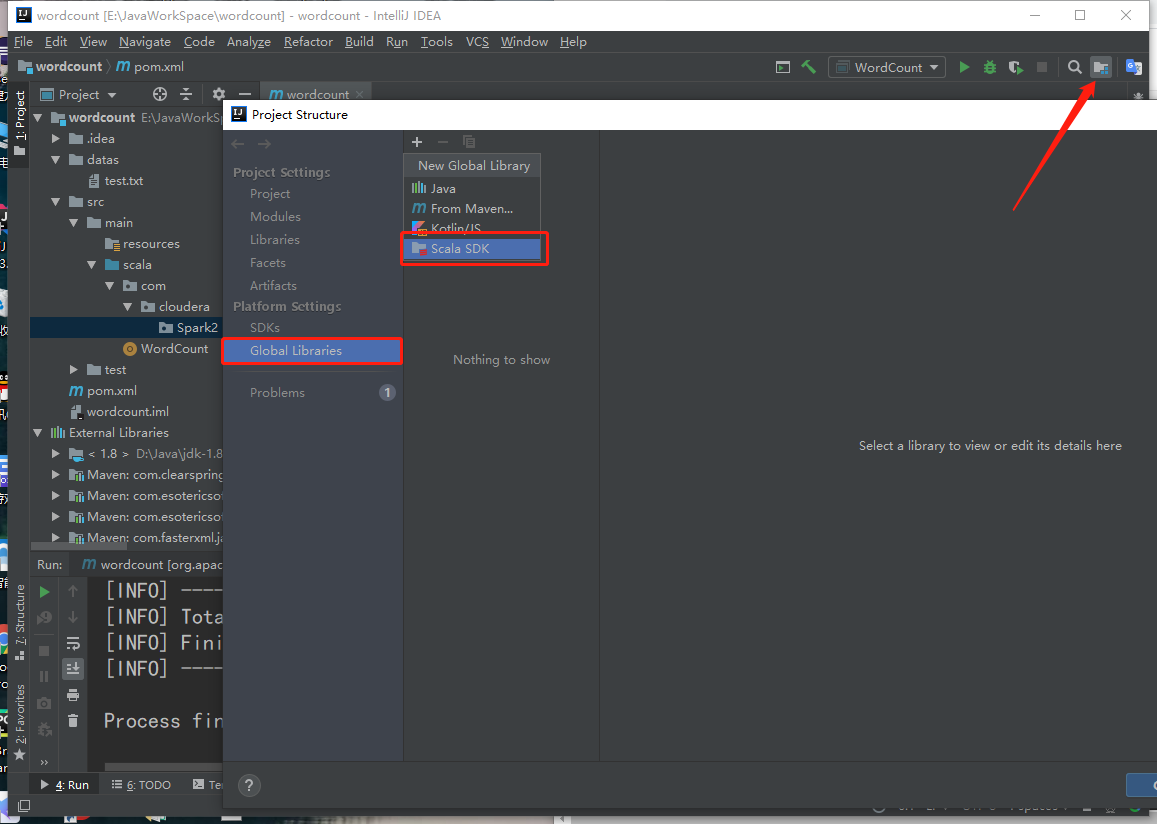
- 选择刚刚下载的scala,点击应用。如下:
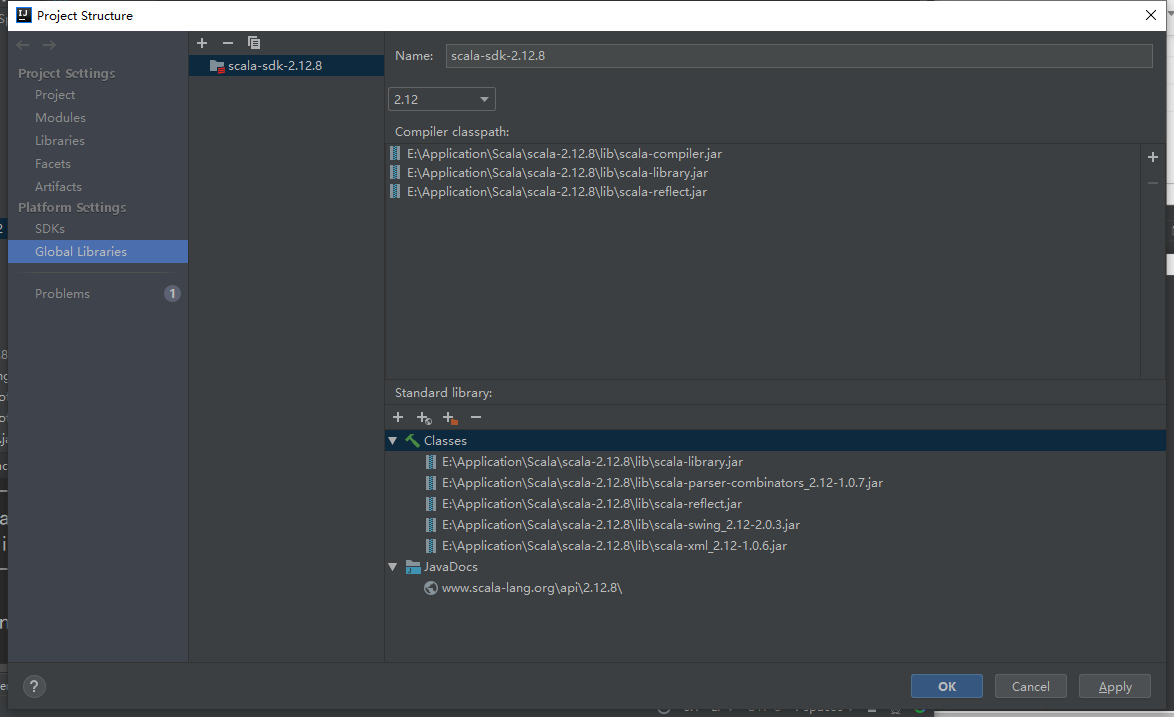
3、Spark应用开发
3.1、SparkWordCount
- 导入pom依赖
```xml
2.1.0 2.6.0
2. 创建Spark2_WordCount的Scala类3. 编写Spark的WordCount程序```javaimport org.apache.spark.{SparkConf, SparkContext}import org.apache.spark.rdd.RDDobject Spark_WordCount {def main(args: Array[String]): Unit = {//System.setProperty("HADOOP_USER_NAME","hdfs")val sparkConf = new SparkConf().setAppName("WordCount")//.setMaster("local[*]")val sc = new SparkContext(sparkConf)val rdd:RDD[String] = sc.textFile(args(0)) // "datas/test.txt"val flatRDD = rdd.flatMap(_.split(" "))val mapRDD = flatRDD.map((_,1))val groupRDD = mapRDD.groupByKey()val datasRDD = groupRDD.mapValues(_.size)datasRDD.collect().foreach(println)sc.stop()}}
- 使用maven自带plugins进行打包
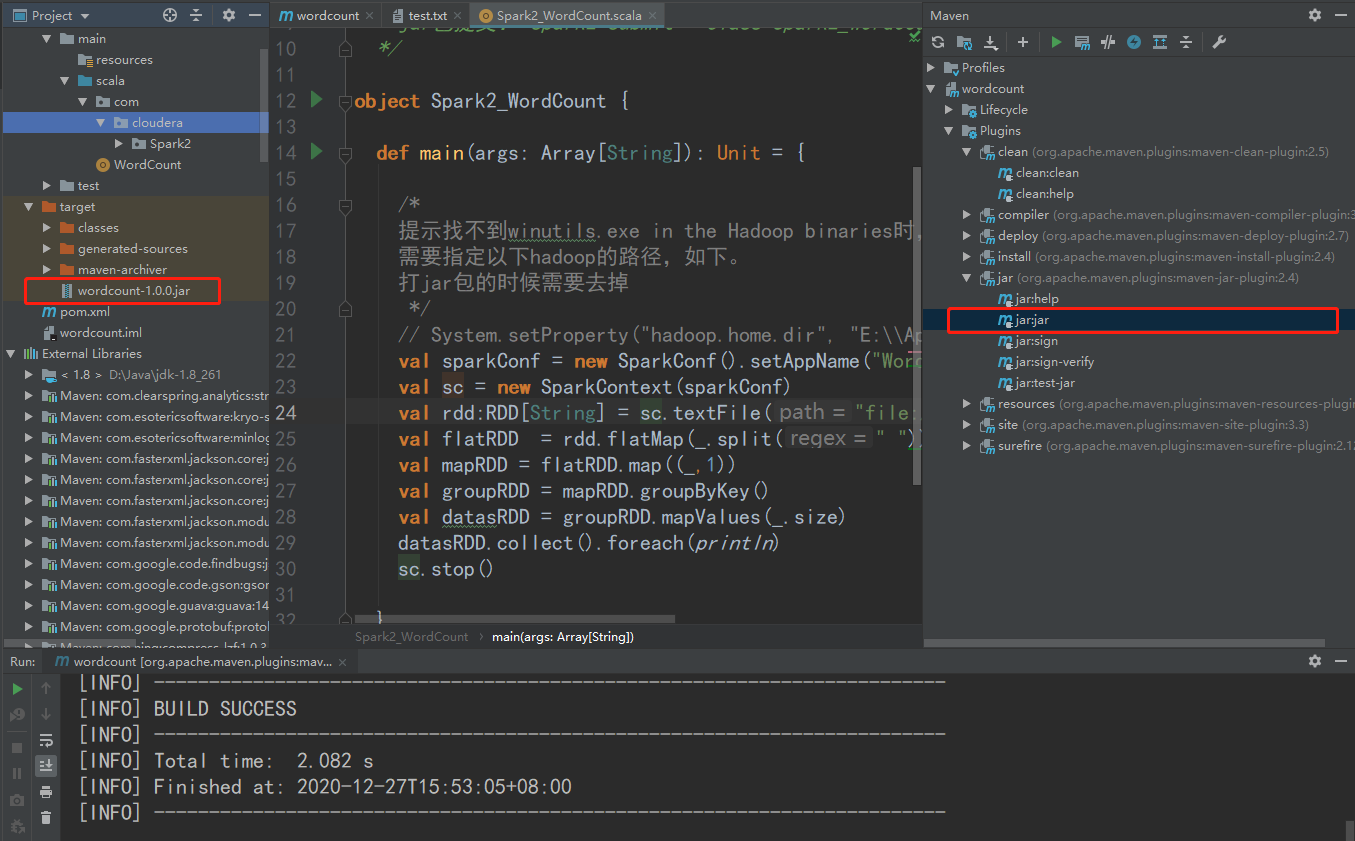
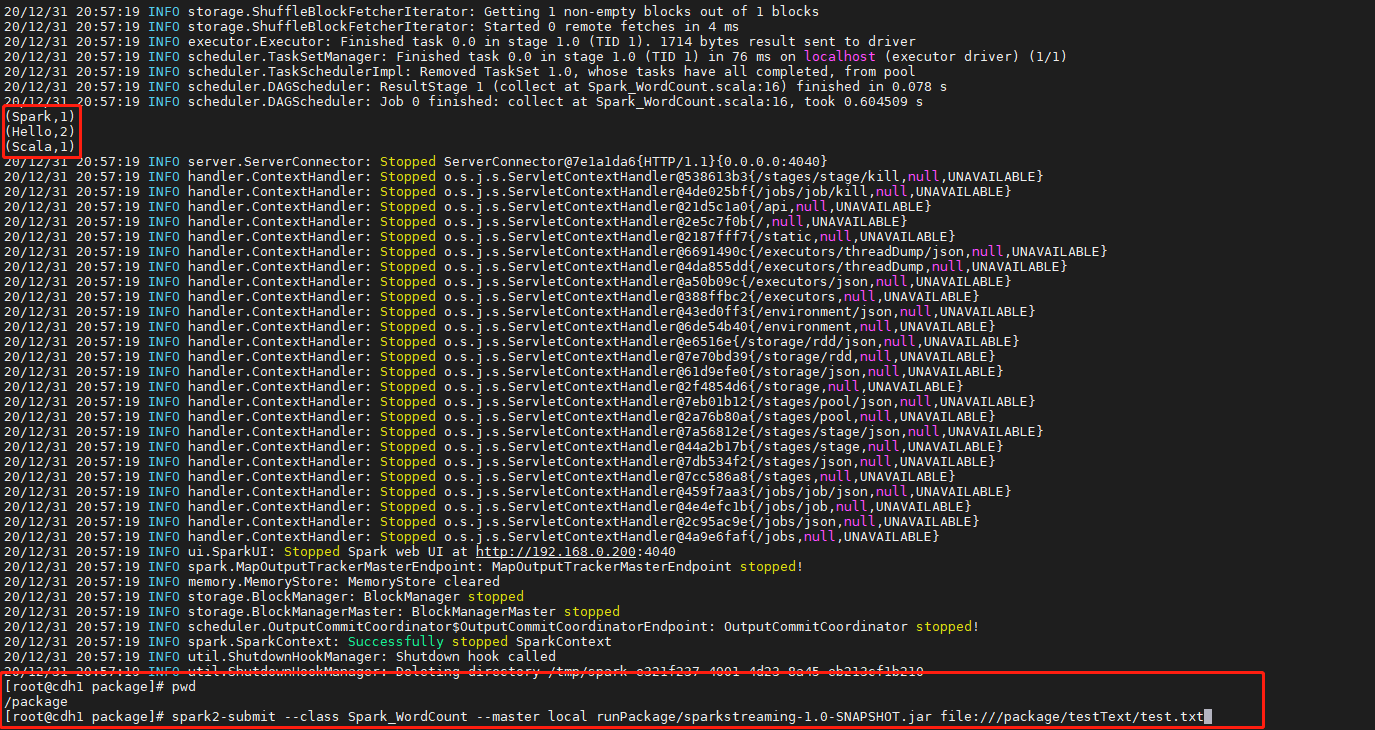
jar包导入linux中,准备需要count的文件,提交任务
spark2-submit --class Spark_WordCount --master local runPackage/sparkstreaming-1.0-SNAPSHOT.jar file:///package/testText/test.txt

执行结果如下:
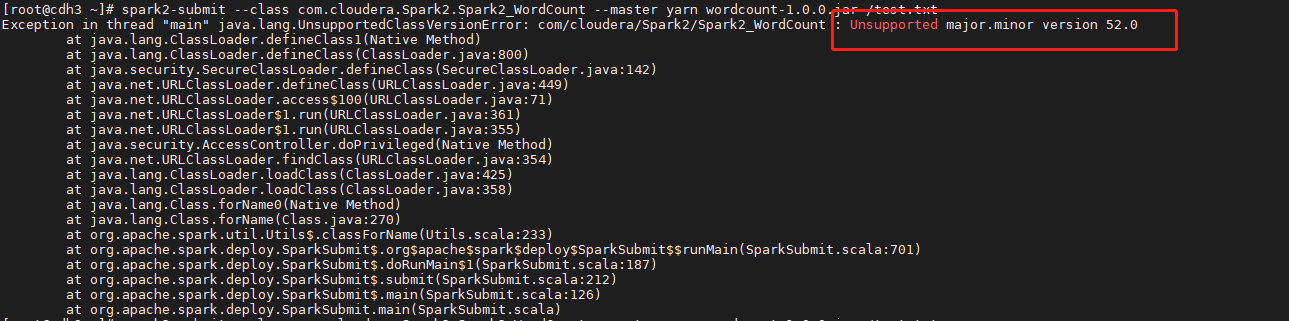
- 提示如下错误,class文件编译版本为jdk1.8,cdh环境jdk版本为1.7。,升级集群jdk版本或者在IDEA中以1.7版本编译WordCount
- spark可以读取本地数据文件,但是需要在所有的节点都有这个数据文件,文件格式为file://+本机路径
3.2、非Kerberos环境下Spark2Streaming拉取kafka2数据写入HBase
3.2.1、前置准备
- 准备模拟数据,编写java代码模拟kafka生产者向消费者发送数据 ```xml package test2;
import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig;
import java.io.*; import java.util.Properties;
public class MyProducer {
public static void main(String[] args) {// TODO 1.创建Kafka生产者的配置信息Properties properties = new Properties();// TODO 2.指定连接的kafka 集群,broker-listproperties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.0.222:9092");// TODO 3.ACK应答级别properties.put(ProducerConfig.ACKS_CONFIG, "all");// TODO 4.重复次数properties.put("retries", 1);// TODO 5.批次大小properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384); //16KB// TODO 6.等待时间properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);// TODO 7.RecordAccumulator 缓冲区大小(32MB)properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);// TODO 8.Key,Value的序列化类properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");// TODO 9.创建生产者对象KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);// TODO 10.发送数// 创建流对象BufferedReader br = null;try {br = new BufferedReader(new FileReader("datas/userInfo.txt"));// 定义字符串,保存读取的一行文字String line = null;// 循环读取,读取到最后返回nullwhile ((line = br.readLine()) != null) {System.out.println(line);//producer.send(new ProducerRecord<String, String>("kafka2_spark2", "Hello World" + line));}} catch (Exception e) {e.printStackTrace();}finally {// 释放资源if (br != null) {try {br.close();} catch (IOException e) {e.printStackTrace();}}}// TODO 11.关闭资源producer.close();}
}
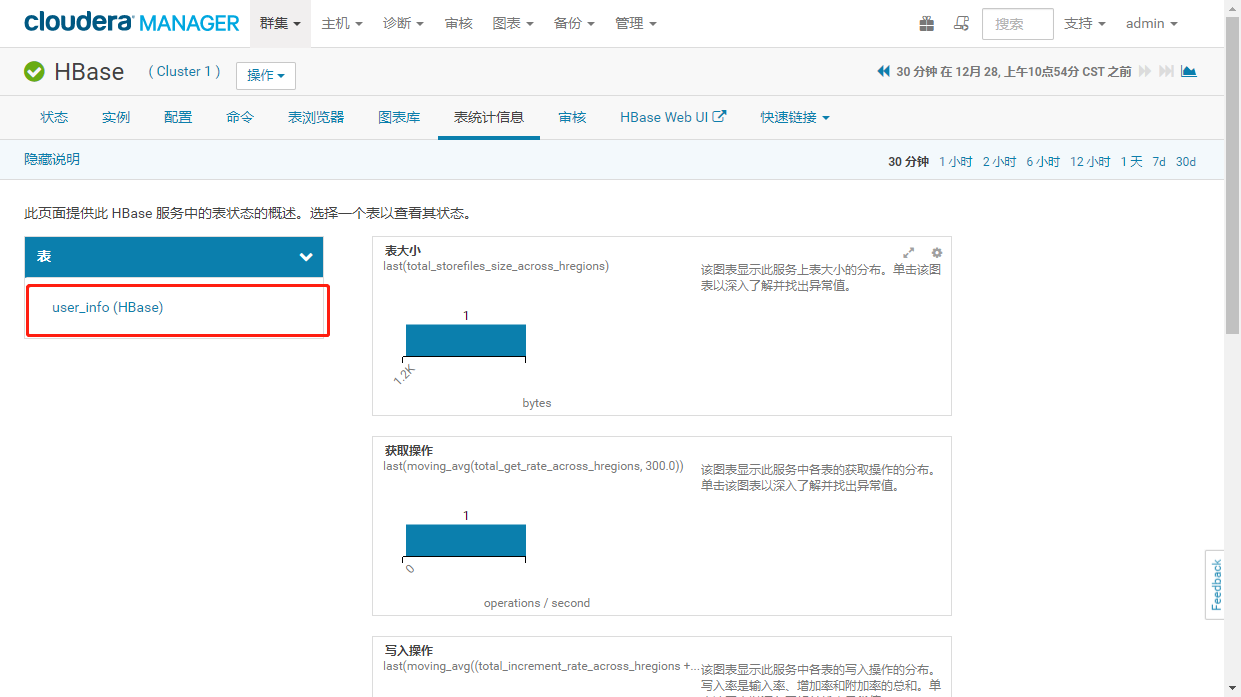
2. 创建hbase表-->user_info 测试表```shellhbase shell---------------------create 'user_info','info'
- CDH可视化界面查看创建成功
3.2.2、程序开发
- 使用maven创建scala语言的spark工程,pom.xml依赖如下
```xml
2.1.0 2.6.0
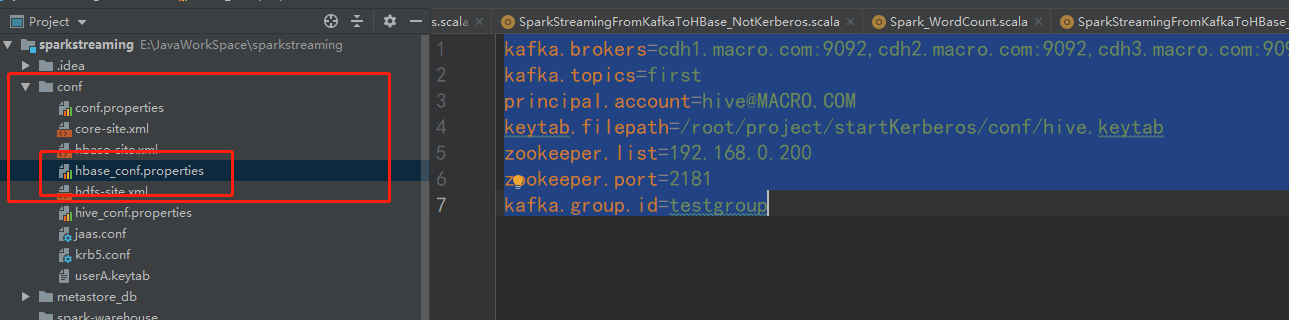
2. 在conf下创建hbase_conf.properties配置文件,内容如下:
kafka.brokers=cdh1.macro.com:9092,cdh2.macro.com:9092,cdh3.macro.com:9092
kafka.topics=kafka2_spark2
zookeeper.list=192.168.0.200
zookeeper.port=2181
kafka.group.id=testgroup
3. 创建SparkStreamingFromKafkaToHBase_NotKerberos.scala文件,内容如下:scala
import java.io.{File, FileInputStream}
import java.util.Properties
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.hadoop.hbase.client.{Connection, ConnectionFactory, Put}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import scala.util.Try
object SparkStreamingFromKafkaToHBase_NotKerberos {
// 非kerberos环境下
def getHBaseConn(zkList: String, port: String): Connection = {
val conf = HBaseConfiguration.create()
conf.set(“hbase.zookeeper.quorum”, zkList) //设置zookeeper为所有zookeeper
conf.set(“hbase.zookeeper.property.clientPort”, port)
val connection = ConnectionFactory.createConnection(conf)
connection
}
def main(args: Array[String]): Unit = {
// 加载配置文件
val properties = new Properties()
var confPath: String = System.getProperty(“user.dir”) + File.separator + “conf”+File.separator
val hbaseConfPath = new FileInputStream(new File(confPath+”hbase_conf.properties”))
if (hbaseConfPath == null) {
println(“找不到conf.properties配置文件”)
} else {
properties.load(hbaseConfPath)
println(“已加载配置文件”)
}
// 读取配置文件
val brokers = properties.getProperty(“kafka.brokers”)
val topics = properties.getProperty(“kafka.topics”)
val zkHost = properties.getProperty(“zookeeper.list”)
val zkport = properties.getProperty(“zookeeper.port”)
val groupId = properties.getProperty(“kafka.group.id”)
// 流式数据环境
val sparkConf = new SparkConf().setAppName(“Kafka2Spark2HBase”)//.setMaster(“local”)
val sc = new SparkContext(sparkConf)
val ssc = new StreamingContext(sc, Seconds(5)) //设置Spark时间窗口,每5s处理一次
// kafka配置
val kafkaPara: Map[String, Object] = MapString, Object
// 创建连接流式数据采集
val dStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStreamString, String, kafkaPara)
)
dStream.foreachRDD(
rdd => {
// 以分区为单位进行遍历
rdd.foreachPartition(
ps => {
// 获取Hbase连接
val connection = getHBaseConn(zkHost, zkport)
// 遍历每个分区的数据
ps.foreach(
line => {
// 得到数据
val datas = line.value().split(“ “)
val id = datas(0)
val name = datas(1)
val age = datas(2)
// 获取表
val tableName = TableName.valueOf(“user_info”)
val table = connection.getTable(tableName)
// 封装数据
val put = new Put(Bytes.toBytes(id))
put.addColumn(Bytes.toBytes(“info”), Bytes.toBytes(“name”), Bytes.toBytes(name))
put.addColumn(Bytes.toBytes(“info”), Bytes.toBytes(“age”), Bytes.toBytes(age))
// 写入数据
Try(table.put(put)).getOrElse(table.close()) //将数据写入HBase,若出错关闭table
// 关闭表
table.close()
})
// 关闭连接
connection.close()
})
})
ssc.start()
ssc.awaitTermination()
}
}
<a name="UB2H7"></a>
#### 3.2.3、程序测试
1. 使用maven工具打jar包后上传至hadoop环境
2. 执行提交xml
spark2-submit —class SparkStreamingFromKafkaToHBase_NotKerberos —master local runPackage/sparkstreaming-1.0-SNAPSHOT.jar
3. 结果如下:
4. 准备需要发送的数据,运行kafka生产者模拟向kafka2_spark2队列发送消息
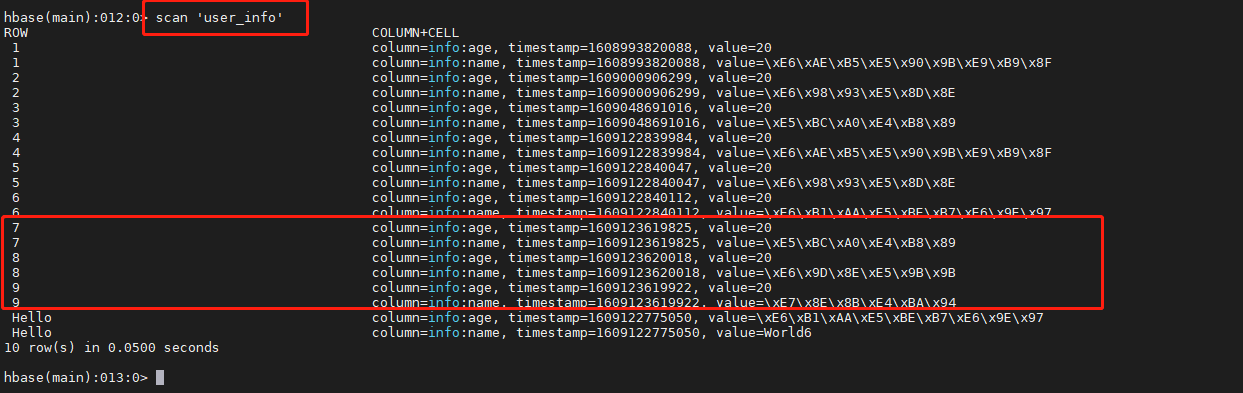
5. 成功发送消息后在linux运行hbase shell,执行scan 'user_info' 查看消息成功发送到hbase
<a name="5G0qm"></a>
#### 3.2.4、问题:
1. 提示找不到部分类
原因:因为打jar包的时候没有把依赖包打进去<br />解决方案:把构建项目所需要的jar包拷贝到/opt/cloudera/parcels/SPARK2/lib/spark2/jars目录下<br />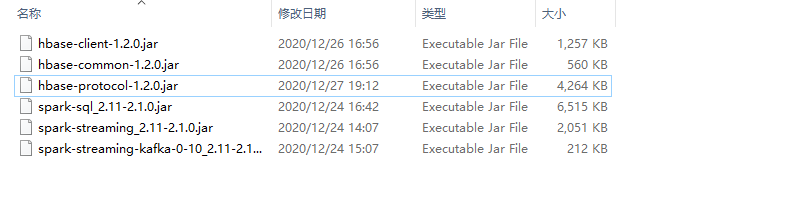<br />**注意:所有节点都要拷贝**
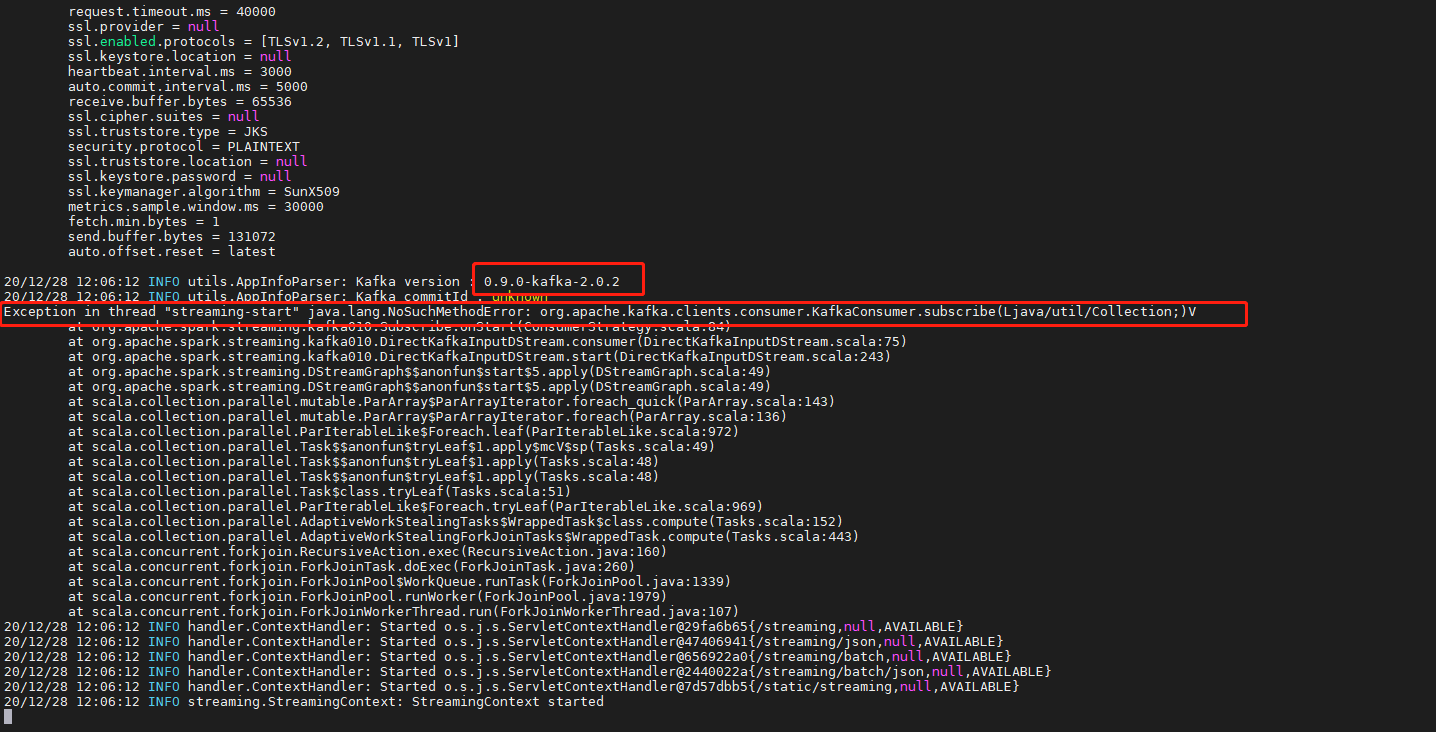
2. 提示kafka客户带版本过低截图如下:
<br />解决方案:登录CM进入SPARK2服务的配置项将spark_kafka_version的kafka版本修改为0.10。重启spark<br />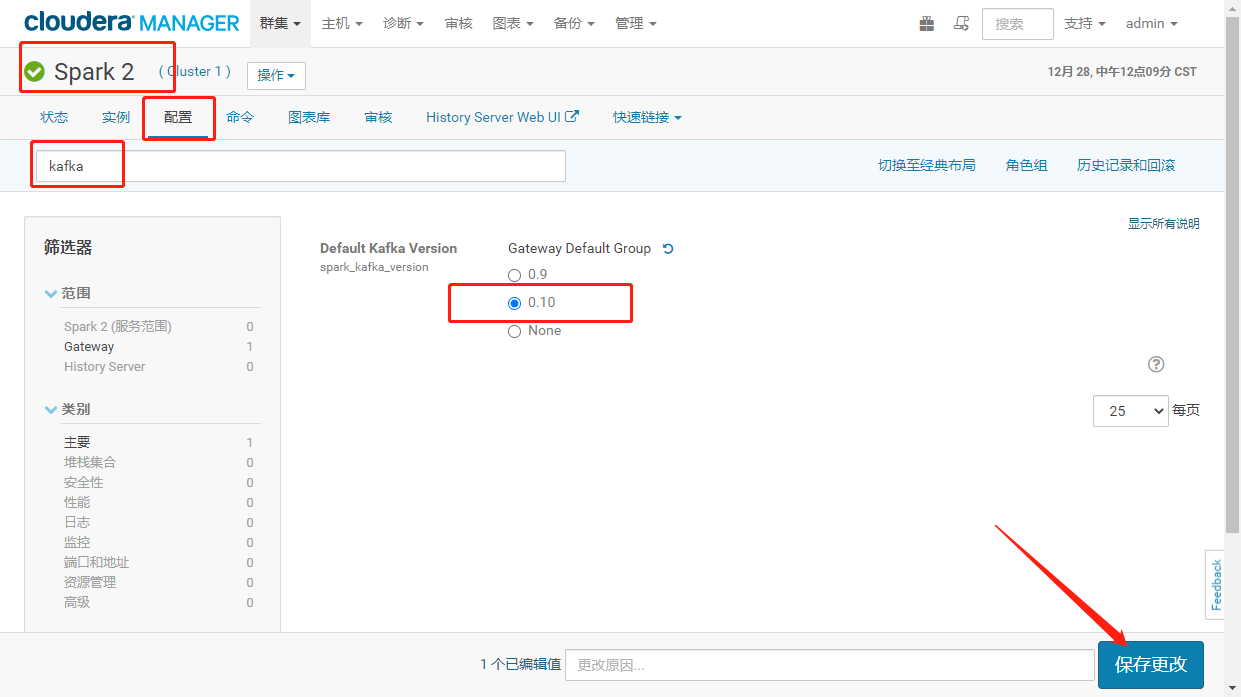
3. 提示NoClassDefFoundError: org/apache/htrace/Trace
- 对于用maven构建hadoop开发项目的时候,在加入了hadoop的依赖项之后,会出现无法更新htrace-core的现象,所以要自己单独拷贝。
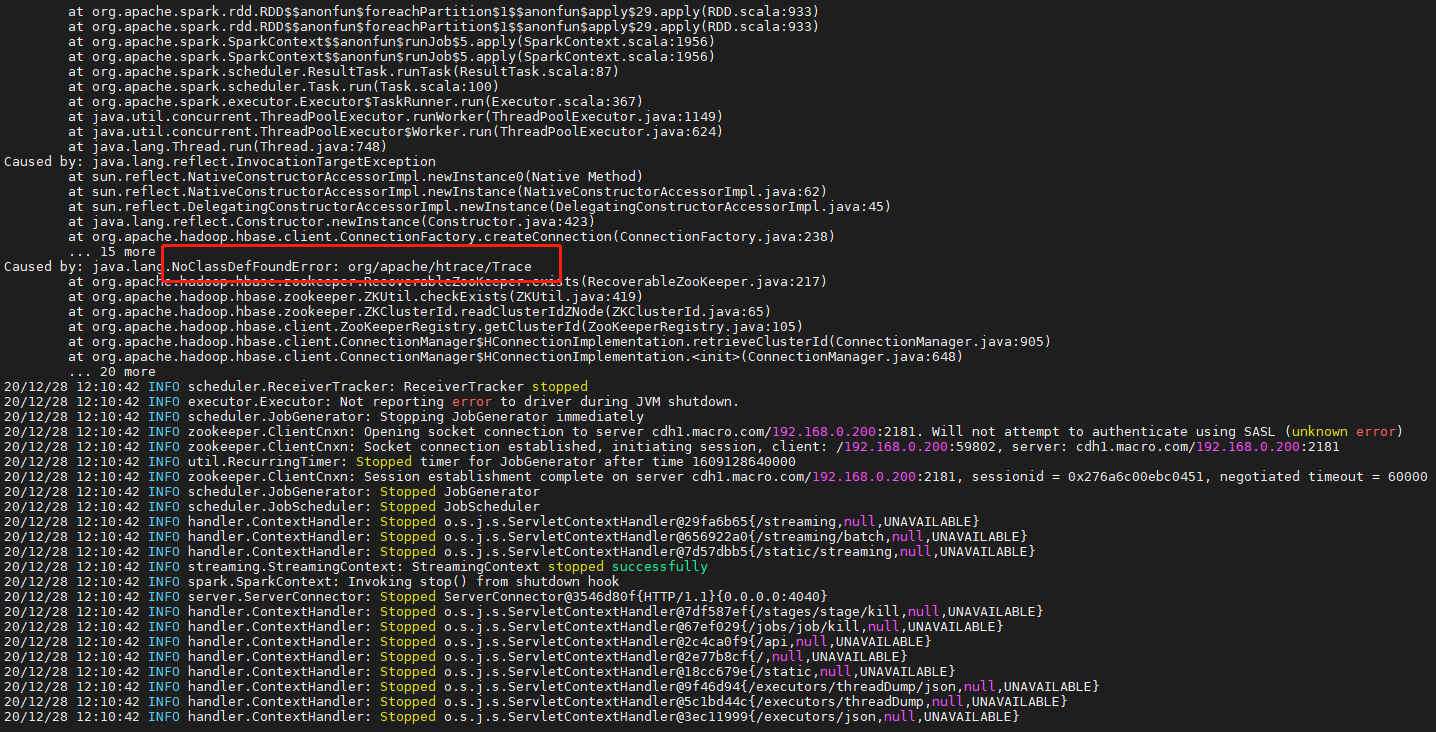<br />解决方案:拷贝如下htrace-core的jar包到每一个节点。<br />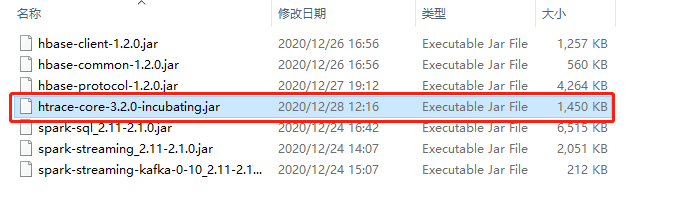
<a name="BjBBv"></a>
### 3.3、非Kerberos环境下Spark2Streaming拉取Kafka2数据写入Hive
<a name="DWVB7"></a>
#### 3.3.1、前置准备
1. 准备模拟数据,编写java代码模拟kafka生产者向消费者发送数据xml
package test2;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import java.io.*;
import java.util.Properties;
public class MyProducer {
public static void main(String[] args) {
// TODO 1.创建Kafka生产者的配置信息
Properties properties = new Properties();
// TODO 2.指定连接的kafka 集群,broker-list
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, “192.168.0.222:9092”);
// TODO 3.ACK应答级别
properties.put(ProducerConfig.ACKS_CONFIG, “all”);
// TODO 4.重复次数
properties.put(“retries”, 1);
// TODO 5.批次大小
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384); //16KB
// TODO 6.等待时间
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
// TODO 7.RecordAccumulator 缓冲区大小(32MB)
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
// TODO 8.Key,Value的序列化类
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, “org.apache.kafka.common.serialization.StringSerializer”);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, “org.apache.kafka.common.serialization.StringSerializer”);
// TODO 9.创建生产者对象
KafkaProducer2. 登录CM进入SPARK2服务的配置项将spark_kafka_version的kafka版本修改为0.10。重启spark

3. 创建测试表sql
CREATE table kafka2_spark2_hive2(id String, name String, age String);

<a name="ITRVr"></a>
#### 3.3.2、程序开发
1. 使用maven创建scala语言的spark工程,pom.xml依赖如下xml
2. 在resources下创建conf.properties配置文件,内容如下:```xmlkafka.brokers=cdh1.macro.com:9092,cdh2.macro.com:9092,cdh3.macro.com:9092kafka.topics=kafka2_spark2zookeeper.list=cdh1.macro.com:2181zookeeper.port=2181
- 编写Spakr程序 ```scala import java.io.{File, FileInputStream} import java.util.Properties
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord} import org.apache.spark.SparkConf import org.apache.spark.rdd.RDD import org.apache.spark.sql.{SaveMode, SparkSession} import org.apache.spark.streaming.dstream.InputDStream import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies} import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreamingFromKafkaToHive_NotKerberos {
def main(args: Array[String]): Unit = {
// StreamingContext创建val sparkConf = new SparkConf().setAppName("SparkStreaming")val ssc = new StreamingContext(sparkConf,Seconds(3))// SparkSQLval spark = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()// 加载配置文件val properties = new Properties()var confPath: String = System.getProperty("user.dir") + File.separator + "conf"+File.separatorval hiveConfPath = new FileInputStream(new File(confPath+"hive_conf.properties"))if (hiveConfPath == null) {println("找不到hive_conf.properties配置文件")} else {properties.load(hiveConfPath)println("已加载配置文件")}// 读取配置文件val brokers = properties.getProperty("kafka.brokers")val topics = properties.getProperty("kafka.topics")val tableName = properties.getProperty("hive.table.name")val groupId = properties.getProperty("kafka.group.id")// kafka配置val kafkaPara: Map[String, Object] = Map[String, Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,ConsumerConfig.GROUP_ID_CONFIG -> groupId,"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer","value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer")val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent, //描述采集的节点跟计算的节点如何匹配ConsumerStrategies.Subscribe[String, String](Set(topics), kafkaPara))// 隐式引入import spark.implicits._kafkaDataDS.foreachRDD(rdd => {val unit: RDD[UserInfo] = rdd.map(line => {val a = line.value()val data = a.split(" ")val id = data(0)val name = data(1)val age = data(2)new UserInfo(id,name, age)})val userinfoDF = spark.sqlContext.createDataFrame(unit)userinfoDF.write.mode(SaveMode.Append).insertInto(tableName)})// 开始运行ssc.start()// 等待Streaming运行结束关闭资源ssc.awaitTermination()
} case class UserInfo(id:String,name:String, age:String)
}
<a name="HTQtb"></a>#### 3.3.3、程序测试1. 使用maven工具打jar包后上传至hadoop环境2. 使用spark2-submit提交任务```sqlspark2-submit --class SparkStreamingFromKafka2ToHive2_NotKerberos --master local --jars sparkStreamingFromKafkaToHive-1.0.0.jar
注意:每个节点都需要有如下包
- java程序模拟kafka生产者发送消息
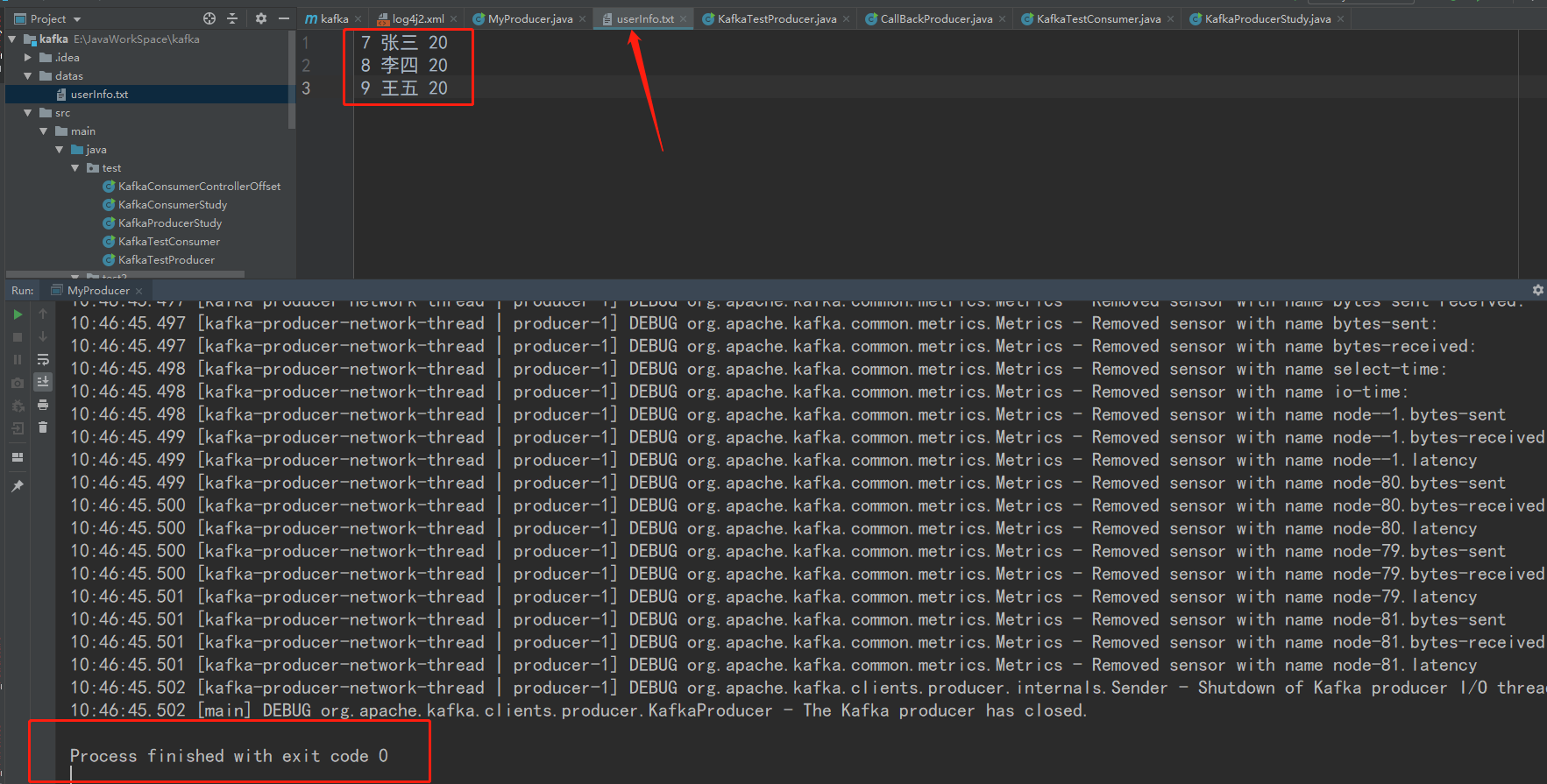
- 查询kafka2_spark2_hive2表,消息成功发送
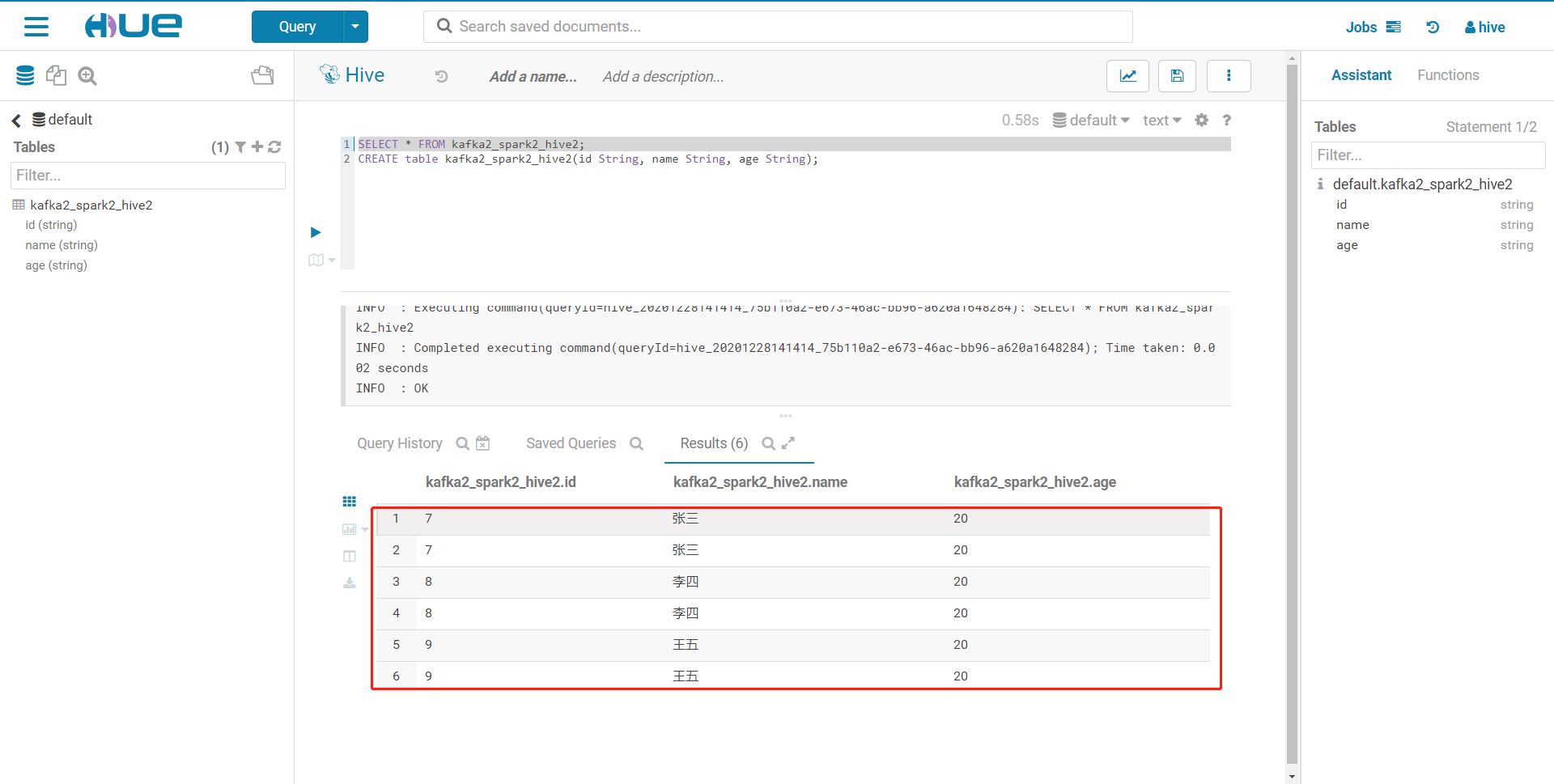
3.5、遇到的问题:
- 提示找不到视图或表(找不到元数据)
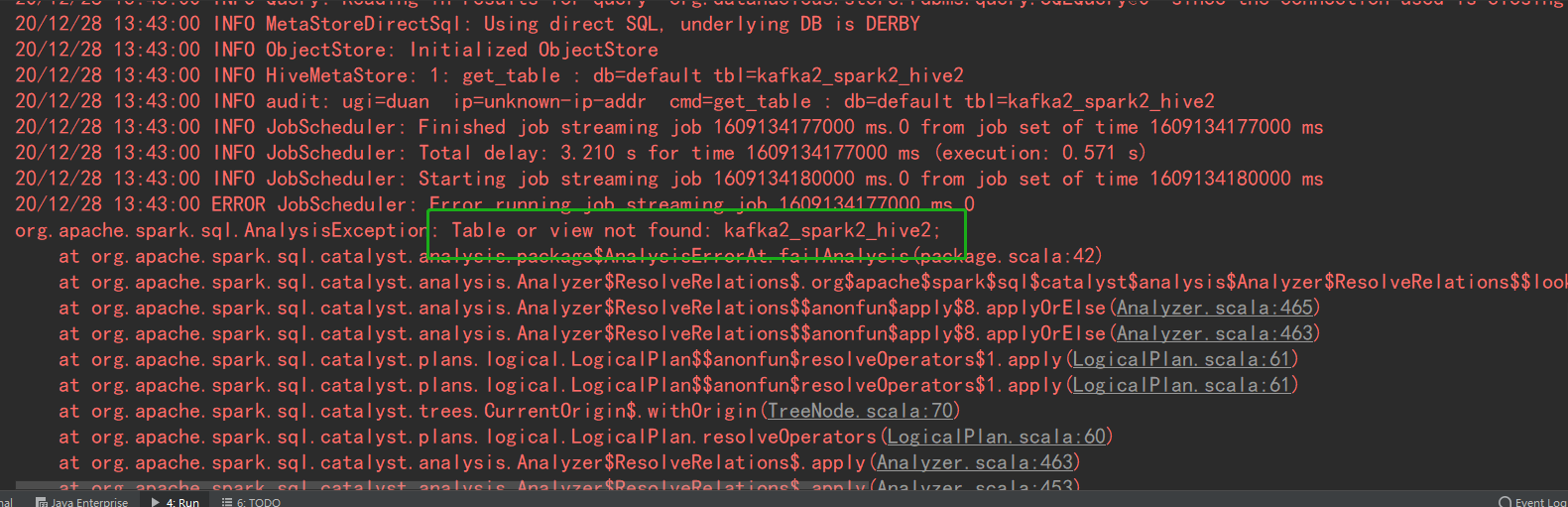
解决方案:
在hadoop环境中拷贝hive-site.xml文件到项目中的resource文件夹下(不知道路径用:find / -name hive-site.xml 搜索)

- 提示实例化错误,截图如下:
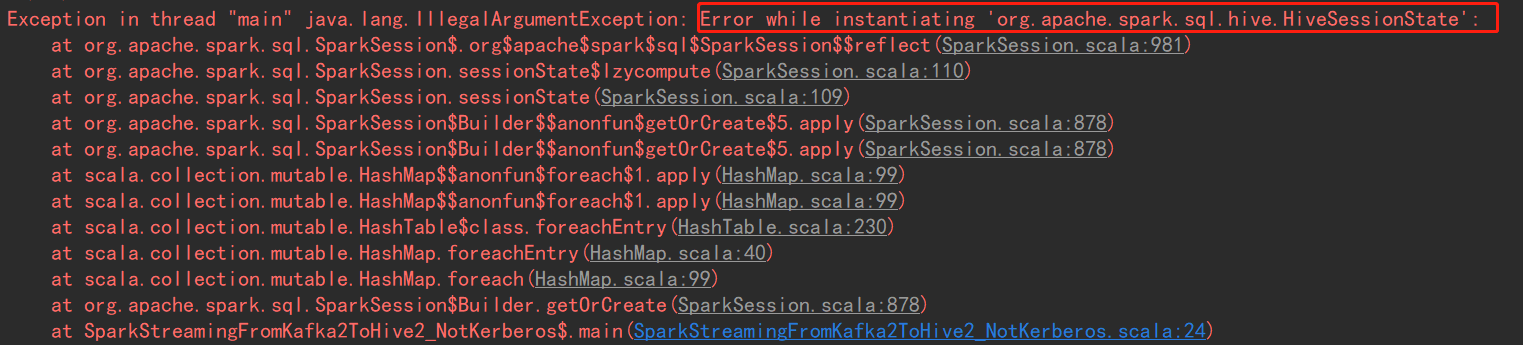
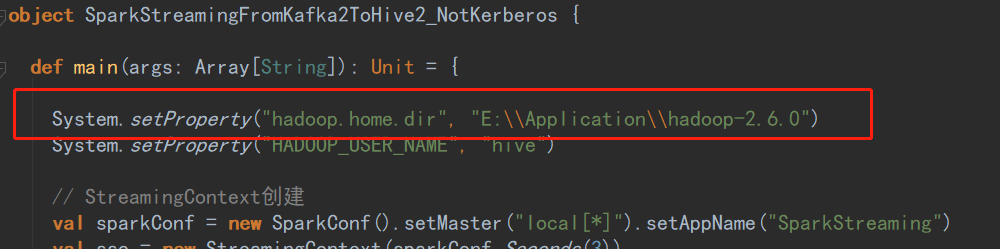
原因:window下需要安装hadoop环境
解决:
1、下载集群对应linux的hadoop版本 <—超链接
2、下载对应的window下的hadoop需要的bin目录 <—超链接
3、解压Linux,把bin目录替换为winutils的bin目录
4、在代码中引用这个地址
System.setProperty("hadoop.home.dir", "E:\\Application\\hadoop-2.6.0")
- java.lang.IllegalArgumentException: Missing application resource 找不到资源

3.4、kerberos环境模拟kafka生产者发送消息到队列
3.4.1、程序开发
- 采用keytab形式做安全认证
准备访问Kafka的Keytab文件,使用xst命令导出keytab文件
kadmin.localxst -norandkey -k userA.keytab userA@MACRO.COM
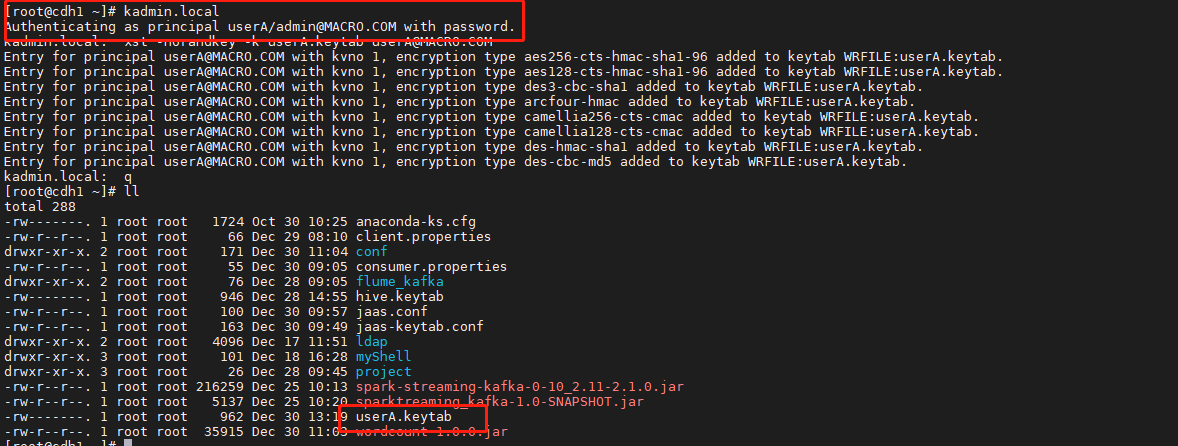
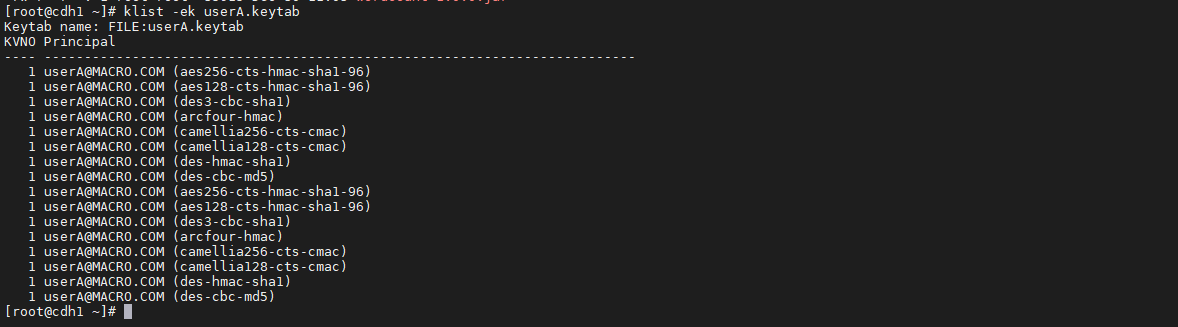
使用klist命令检查导出的keytab文件是否正确
klist -ek userA.keytab
导入keytab文件到java项目的resource文件下
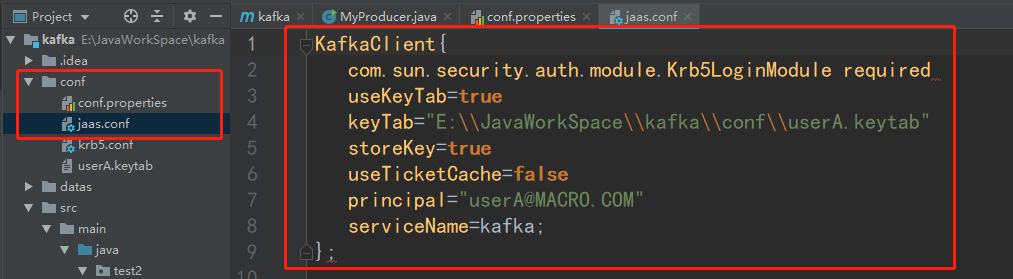
准备producer_jaas.cof文件内容如下:
KafkaClient{com.sun.security.auth.module.Krb5LoginModule requireduseKeyTab=truekeyTab="E:\\JavaWorkSpace\\kafka\\conf\\userA.keytab"storeKey=trueuseTicketCache=falseprincipal="userA@MACRO.COM"serviceName=kafka;};
导入linux的/etc目录下的brk5.conf文件到javaresource目录
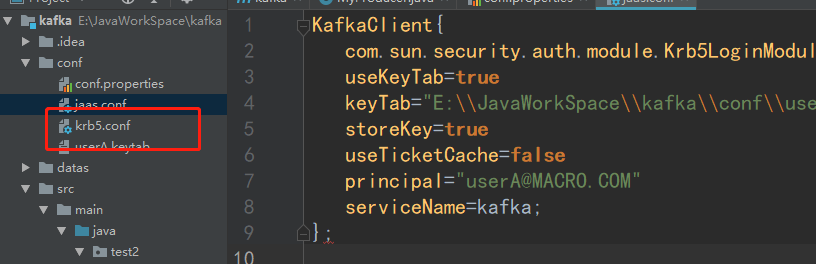
准备配置文件,放在项目根目录下的conf目录下
security.protocol=SASL_PLAINTEXTsasl.mechanism=GSSAPIsasl.kerberos.service.name=kafkabootstrap.servers=cdh1.macro.com:9092acks=allretries=1batch.size=16384linger.ms=1buffer.memory=33554432key.serializer=org.apache.kafka.common.serialization.StringSerializervalue.serializer=org.apache.kafka.common.serialization.StringSerializertopic=kafka2_spark2
编写生产者java代码用作发送消息 ```java import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord;
import java.io.*; import java.util.Properties; import java.util.logging.Level; import java.util.logging.Logger;
public class MyProducer {
public static void main(String[] args) {Logger.getLogger("org").setLevel(Level.INFO);// 获取当前路径String localPath = System.getProperty("user.dir") + File.separator;String krb5Path = localPath + "conf/krb5.conf";String jaasPath = localPath + "conf/jaas.conf";if (!new File(krb5Path).exists()) {System.out.println("未加载到krb5.conf配置文件,程序结束");System.exit(0);}if (!new File(jaasPath).exists()) {System.out.println("未加载到jaas.conf配置文件,程序结束");System.exit(0);}// kerberos必须添加krb5和jaas地址//在windows中设置JAAS,也可以通过-D方式传入System.setProperty("java.security.krb5.conf", krb5Path);System.setProperty("java.security.auth.login.config", jaasPath);System.setProperty("javax.security.auth.useSubjectCredsOnly", "false");// 创建Kafka生产者的配置信息Properties properties = new Properties();FileInputStream is = null;//InputStream ips = ClassLoader.getSystemClassLoader().getResourceAsStream("conf.properties");try {is = new FileInputStream(new File(localPath+"conf/conf.properties"));} catch (FileNotFoundException e) {e.printStackTrace();}try {properties.load(is);} catch (IOException e) {System.out.println("配置文件加载失败!");}finally {try {if (is != null) {is.close();}} catch (IOException e) {e.printStackTrace();}}// 创建生产者对象KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);// 发送数据// 创建流对象BufferedReader br = null;try {br = new BufferedReader(new FileReader("datas/userInfo.txt"));//args[0] //"datas/userInfo.txt"// 定义字符串,保存读取的一行文字String line = null;// 循环读取,读取到最后返回nullwhile ((line = br.readLine()) != null) {producer.send(new ProducerRecord<String, String>(properties.getProperty("topic"), line));}} catch (Exception e) {e.printStackTrace();} finally {// 释放资源if (br != null) {try {br.close();} catch (IOException e) {e.printStackTrace();}}}// 关闭资源producer.close();}
}
7. 准备datas/userInfo.txt文件,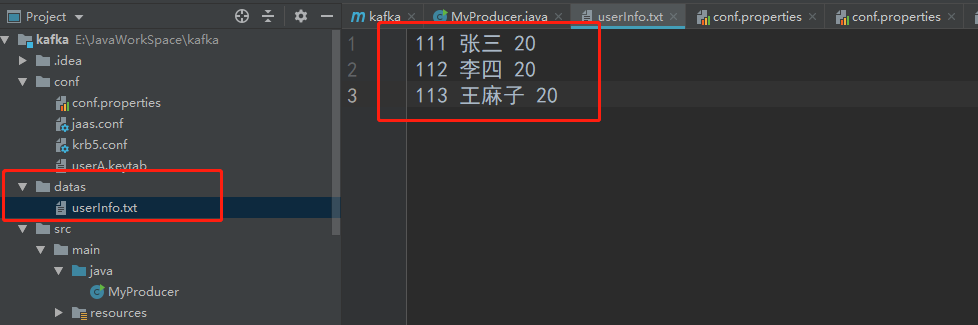8. 测试数据发送成功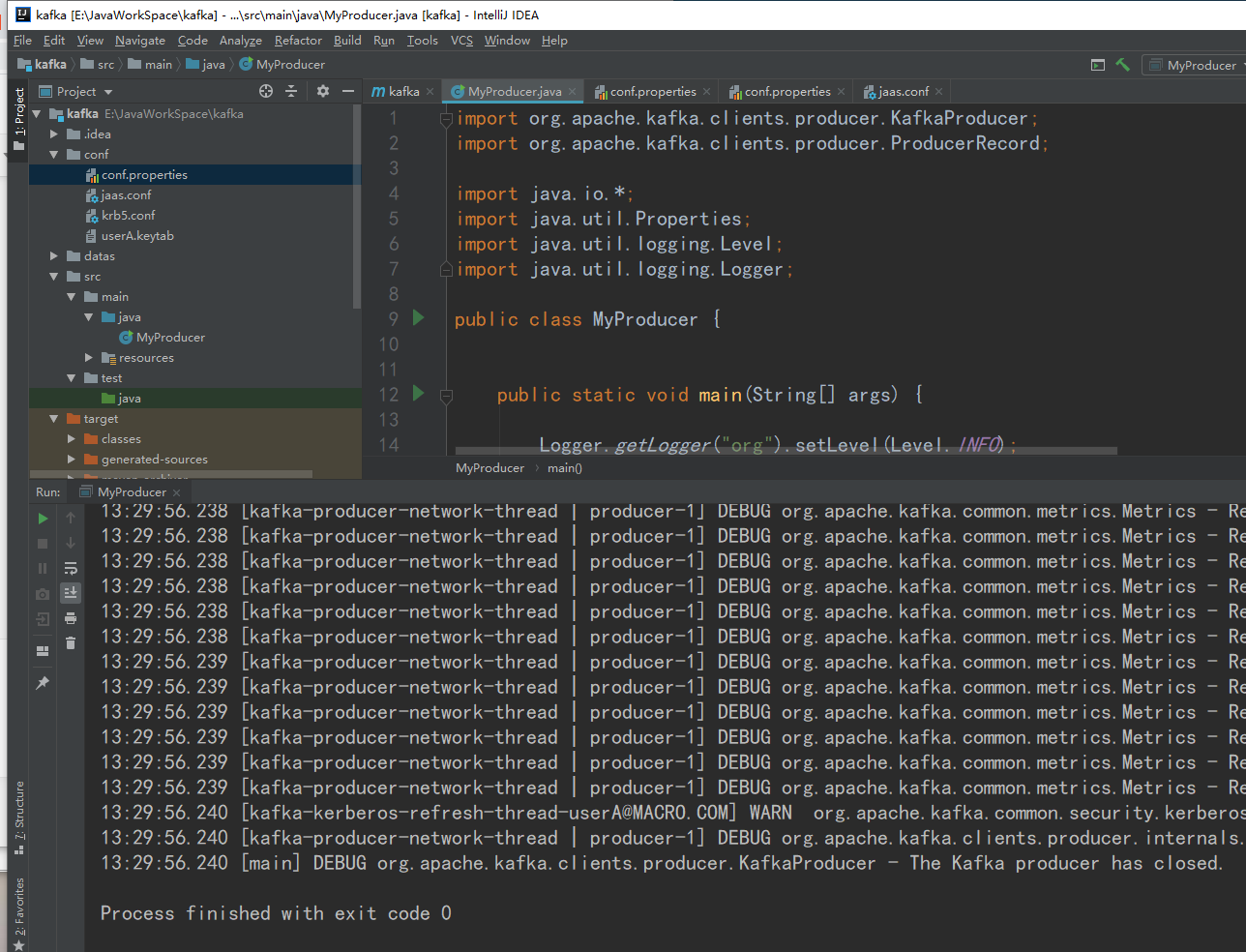9. 消费者端成功接收收据<a name="ofW12"></a>## 4.3、打成jar包编写脚本用做发送数据测试1. 打包之前修改代码,手动指定文件地址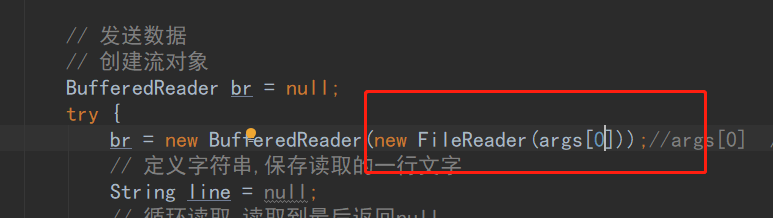2. maven自带工具打包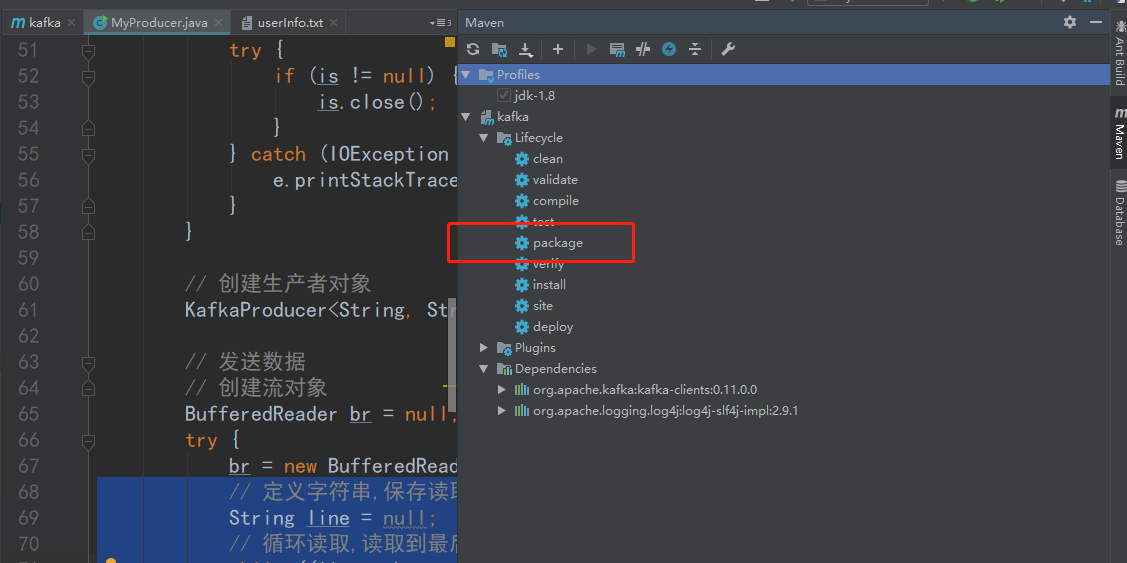3. 上传jar包到linux环境,编写shell脚本,脚本如下```shell#!/bin/bashJAVA_HOME=/usr/java/jdk1.8.0_144/read_file=$1for file in `ls lib/*jar`doCLASSPATH=$CLASSPATH:$filedoneexport CLASSPATH${JAVA_HOME}/bin/java -Xms1024m -Xmx2048m MyProducer $read_file
- 新建目录kafka_kerberos_producer,拷贝idea下conf目录,新建lib目录,移动jar包到lib,目录结构如下

- 运行会报错缺失部分类,移动对应目录到lib目录即可

- 运行效果如下,test是我们要发送的文件

- consumer成功接收数据

5、Kerberos环境SparkStreaming拉取kafka数据写入hive
5.1、环境准备
- 采用keytab形式做安全认证
准备访问Kafka的Keytab文件,使用xst命令导出keytab文件
kadmin.localxst -norandkey -k hive.keytab hive@MACRO.COM

使用klist命令检查导出的keytab文件是否正确
klist -ek hive.keytab
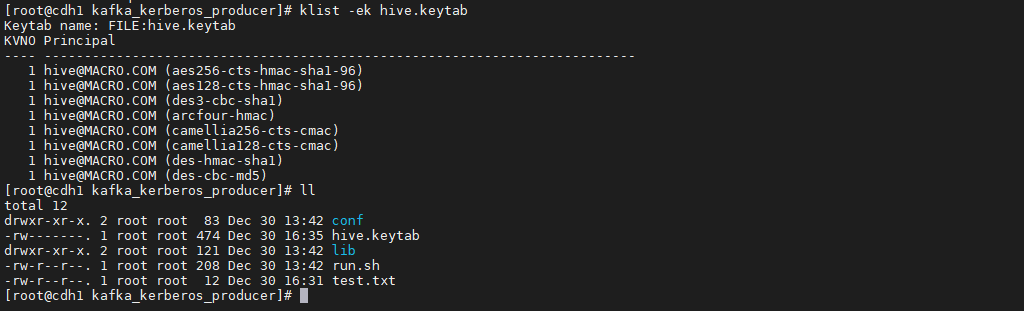
准备jaas.cof文件内容如下:
KafkaClient {com.sun.security.auth.module.Krb5LoginModule requireduseKeyTab=truekeyTab="/root/spark/conf/hive.keytab"principal="hive@MACRO.COM";};Client {com.sun.security.auth.module.Krb5LoginModule requireduseKeyTab=truestoreKey=truekeyTab="/root/spark/conf/hive.keytab"principal="hive@MACRO.COM";};
将hive.keytab和jaas.conf文件拷贝至集群的所有节点统一的/root/spark/conf目录下
- 准备刚刚编写的Kerberos环境发送数据的脚本
登录CM进入SPARK2服务的配置项将spark_kafka_version的kafka版本修改为0.10
5.2、程序开发
使用maven创建scala语言的spark2demo工程,pom.xml依赖如下
<dependencies><!-- Spark依赖关系 --><!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.1.0</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.11</artifactId><version>2.1.0</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-kafka-0-10 --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.11</artifactId><version>2.1.0</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>2.1.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.11</artifactId><version>2.1.0</version></dependency></dependencies>
在recource下创建conf.properties配置文件,内容如下:
kafka.brokers=cdh1.macro.com:9092,cdh2.macro.com:9092,cdh3.macro.com:9092kafka.topics=kafka2_spark2group.id=testgroup
编写spark代码如下: ```scala import java.io.{File, FileInputStream} import java.util.Properties
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord} import org.apache.spark.SparkConf import org.apache.spark.rdd.RDD import org.apache.spark.sql.{SaveMode, SparkSession} import org.apache.spark.streaming.dstream.InputDStream import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies} import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreamingFromKafkaToHive_Kerberos { var confPath: String = System.getProperty(“user.dir”) + File.separator + “conf” + File.separator
def main(args: Array[String]): Unit = { // StreamingContext创建 val sparkConf = new SparkConf().setAppName(“SparkStreaming”)//.setMaster(“local[*]”) val ssc = new StreamingContext(sparkConf, Seconds(3)) // SparkSQL val spark = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()
// 加载配置文件val properties = new Properties()val in = new FileInputStream(new File(confPath + "conf.properties"))if (in == null) {println("找不到conf.properties配置文件")} else {properties.load(in)//println("已加载配置文件")}// 读取配置文件val brokers = properties.getProperty("kafka.brokers")val topics = properties.getProperty("kafka.topics")val groupId = properties.getProperty("group.id")val tableName = properties.getProperty("hive.tableName")// kafka配置val kafkaPara: Map[String, Object] = Map[String, Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "latest","group.id" -> groupId,ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer","security.protocol" -> "SASL_PLAINTEXT","sasl.kerberos.service.name" -> "kafka")val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent, //描述采集的节点跟计算的节点如何匹配ConsumerStrategies.Subscribe[String, String](Set(topics), kafkaPara))// 隐式引入import spark.implicits._kafkaDataDS.foreachRDD(rdd => {val unit: RDD[UserInfo] = rdd.map(line => {val a = line.value()val data = a.split(" ")val name = data(0)val age = data(1)new UserInfo(name, age)})val userinfoDF = spark.sqlContext.createDataFrame(unit)userinfoDF.write.mode(SaveMode.Append).insertInto(tableName)})// 开始运行ssc.start()// 等待Streaming运行结束关闭资源ssc.awaitTermination()
}
case class UserInfo( name: String, age: String)
}
<a name="lKR9Q"></a>## 5.3、测试1. 通过maven自带工具打jar包,上传至linux环境根目录下,运行jar包```shellspark2-submit --class SparkStreamingFromKafkaToHive_Kerberos --master local --deploy-mode client --executor-memory 1g --executor-cores 2 --driver-memory 2g --num-executors 2 --queue default --principal hive@MACRO.COM --keytab /spark/conf/hive.keytab --files "/spark/conf/jaas.conf" --driver-java-options "-Djava.security.auth.login.config=/spark/conf/jaas.conf" --conf "spark.executor.extraJavaOptions=-Djava.security.auth.login.config=/spark/conf/jaas.conf" sparkstreaming-1.0-SNAPSHOT.jar
- 注意:如果用yarn运行,/spark/conf下一定要有jaar.conf和hive.keytab等文件配置文件
- 运行结果如下
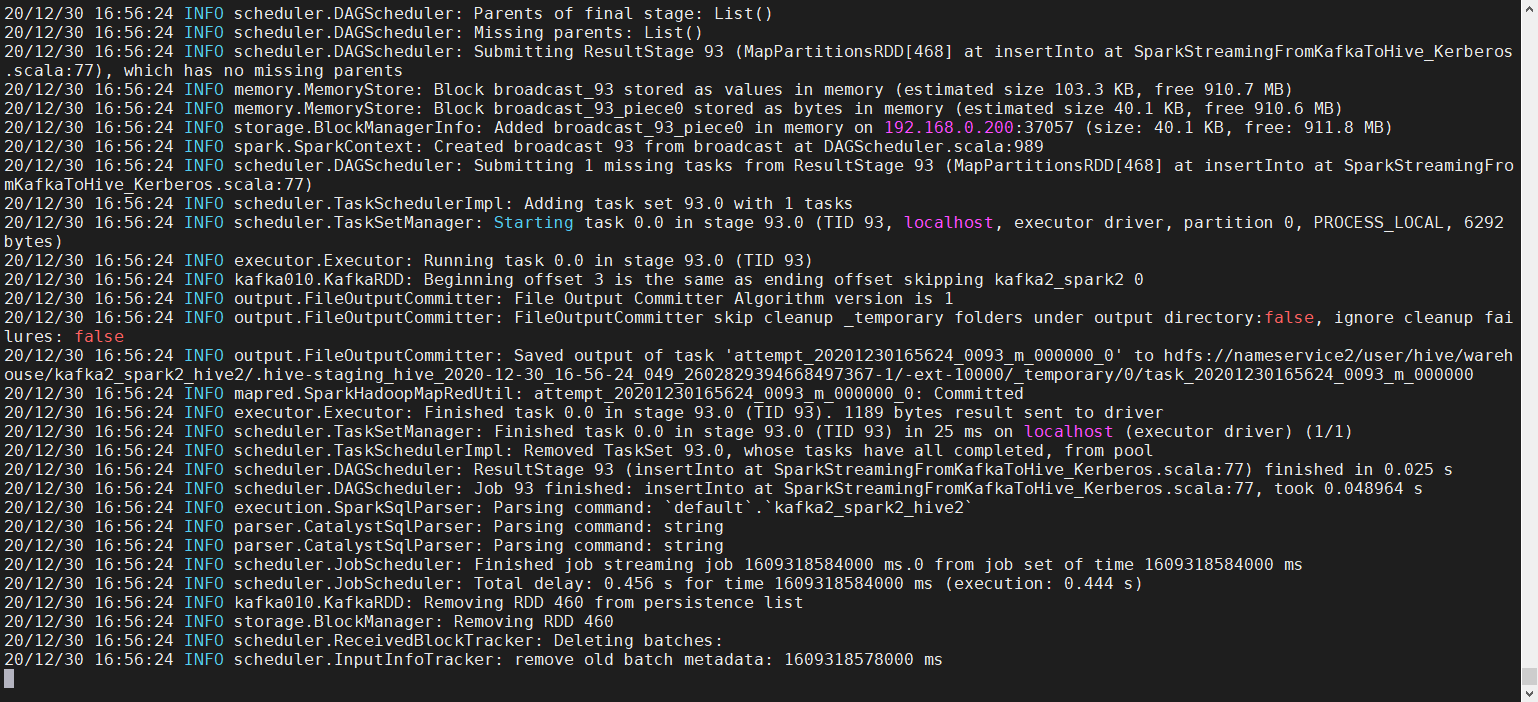
- 运行kafka的producer脚本向kafka2_spark2队列添加数据
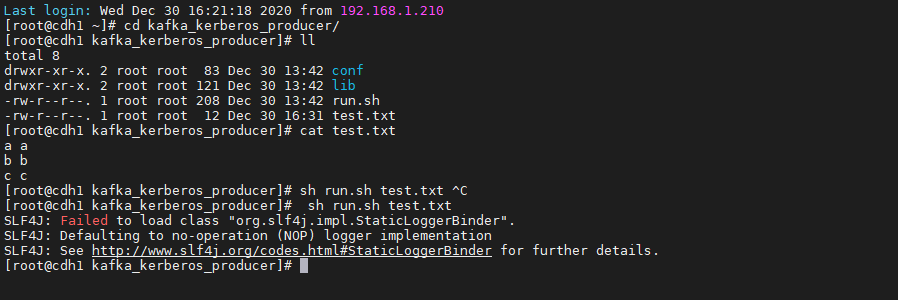
- 数据成功添加

6、Kerberos环境SparkStreaming拉取kafka数据写入
HBase
6.1、测试环境
6.2、环境准备
6.3、程序开发
6.4、测试
6.5、问题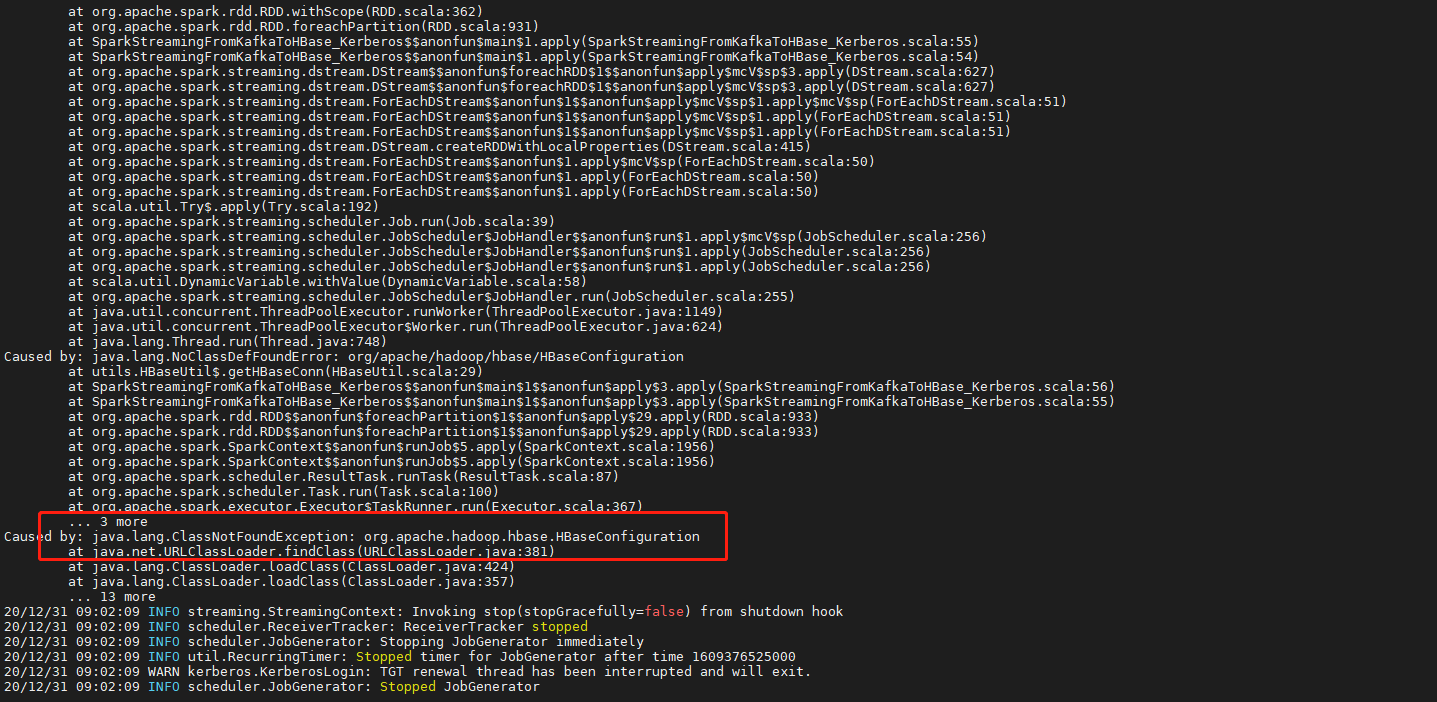
整合运行
- 为了方便运行,所有功能打到一个包下面
- 移动package包到根目录下
sparkwordcount运行
spark2-submit --class Spark_WordCount --master local runPackage/sparkstreaming-1.0-SNAPSHOT.jar file:///package/testText/test.txt
非kerberos的spark拉去kafka数据向hive写数据
spark2-submit --class SparkStreamingFromKafkaToHive_NotKerberos --master local runPackage/sparkstreaming-1.0-SNAPSHOT.jar
非kerberos下kafka模拟生产者发送数据
sh run_producer.sh MyProducerNotKerberos testText/HiveAndHBaseTestText.txt

非kerberos的spark拉去kafka数据向HBase写数据
spark2-submit --class SparkStreamingFromKafkaToHBase_NotKerberos --master local runPackage/sparkstreaming-1.0-SNAPSHOT.jar
非kerberos下kafka模拟生产者发送数据
sh run_producer.sh MyProducerNotKerberos testText/HiveAndHBaseTestText.txt

kerberos下spark拉去kafka数据向Hive写数据

若有收获,就点个赞吧
0 人点赞
