一、源端
1、结构展示
1.1 外层
1.2 内层
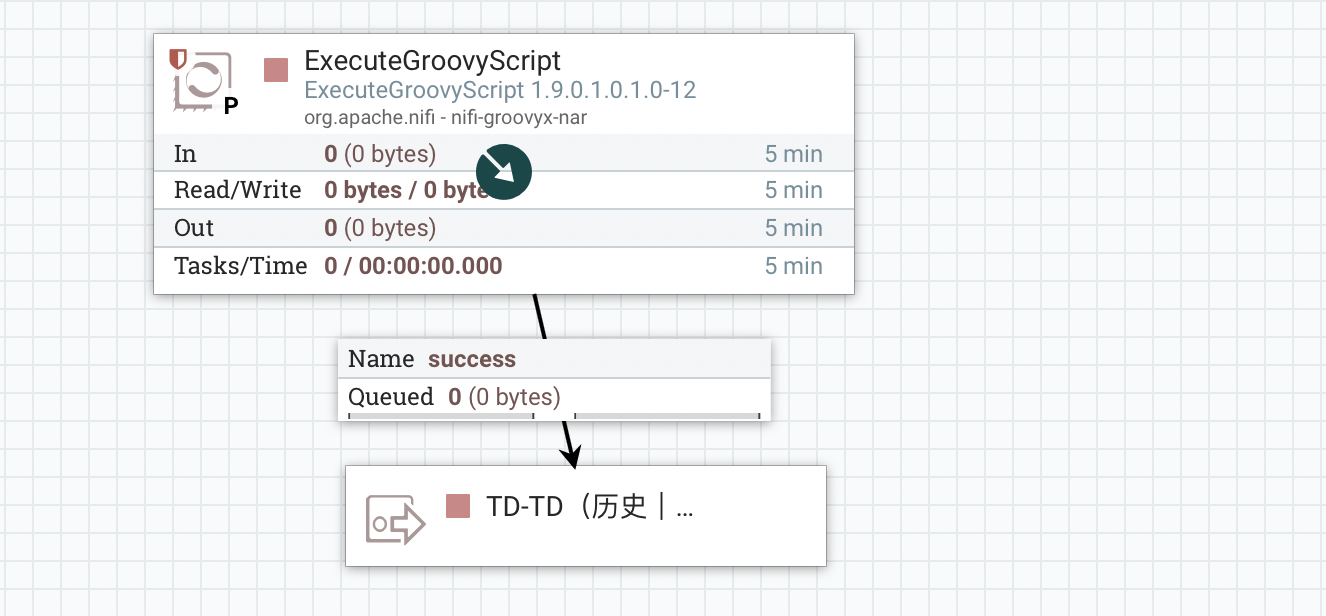
2、PROCESS
2.1 ExecuteGroovyScript
a)SETTINGS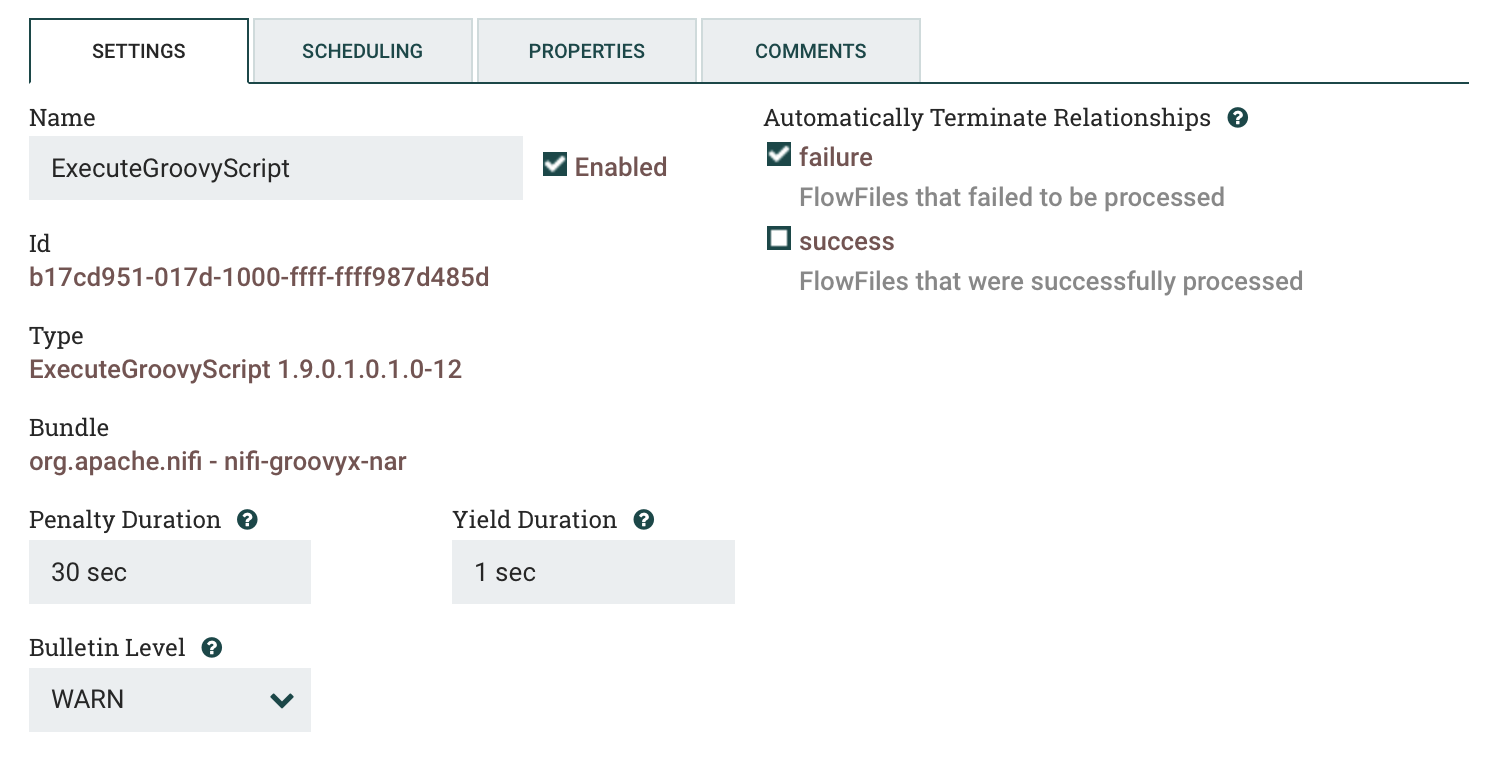
b)SCHEDULING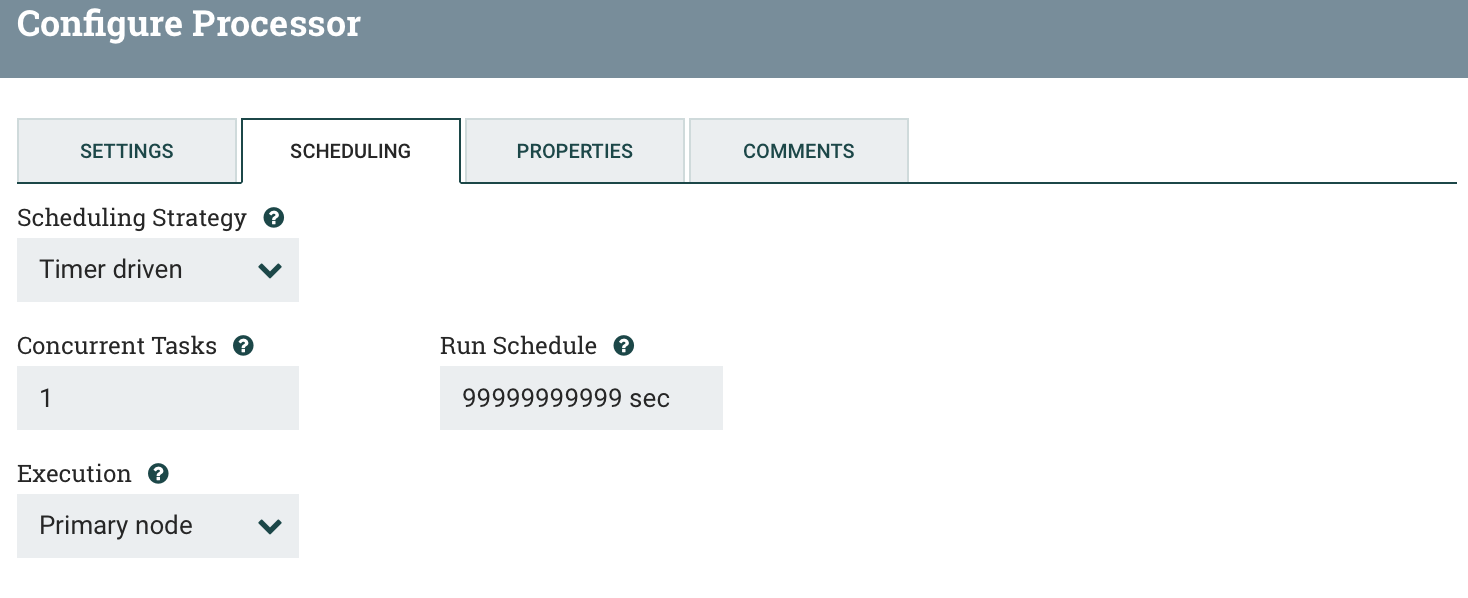
c)PROPERTIES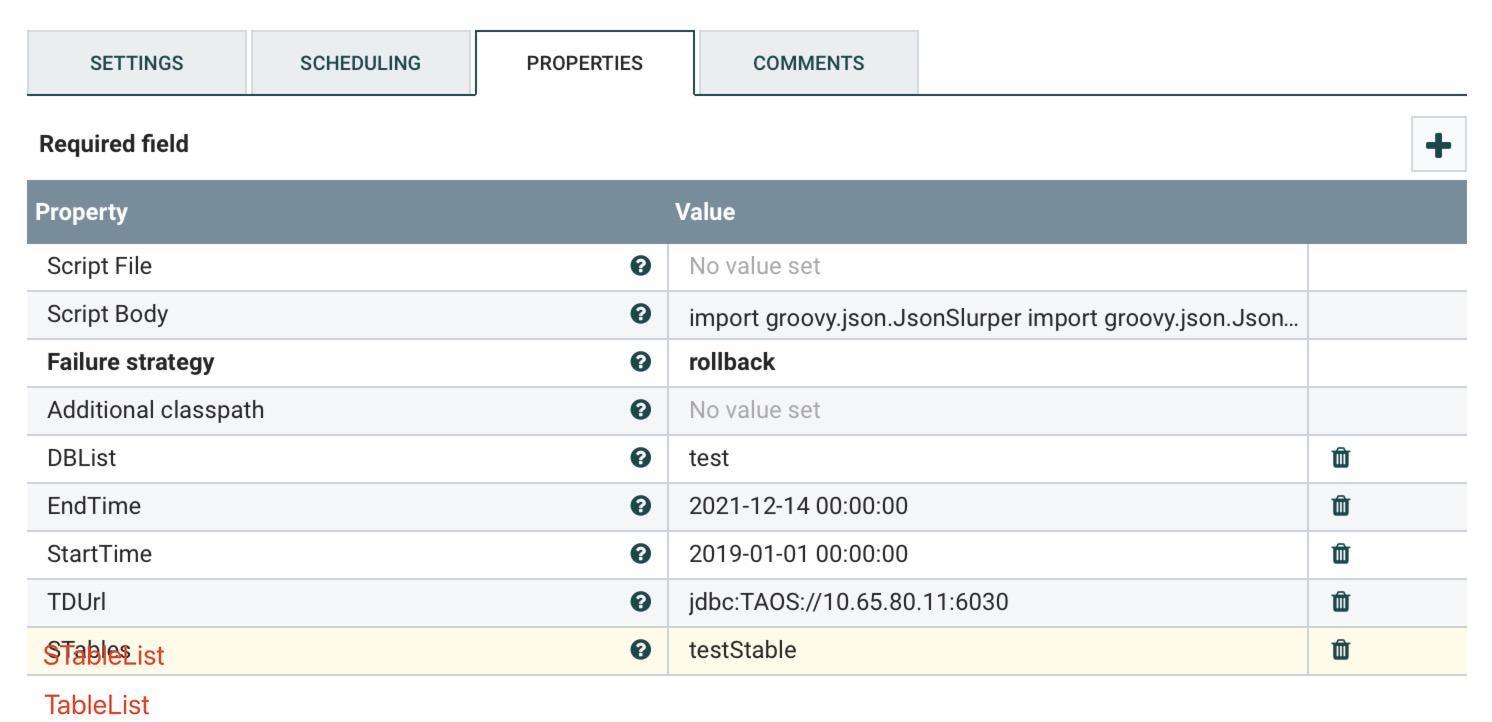
必填参数
DBList:库名(多个DB逗号分隔)
StartTime:开始时间
EngTime:结束时间
TDUrl:TD链接地址
可选参数
STableList:超级表名(多个超级表名以逗号分隔,多个超级表会交叉匹配多个库)
TableList:子表名(标签点名)(多个子表名逗号分隔,多个子表会交叉匹配多个库)
脚本内容见 附1
二、目标端
1、结构展示
1.1 外层
1.2 内层
2、PROCESS
2.1 ExecuteGroovyScript
a)PROPERTIES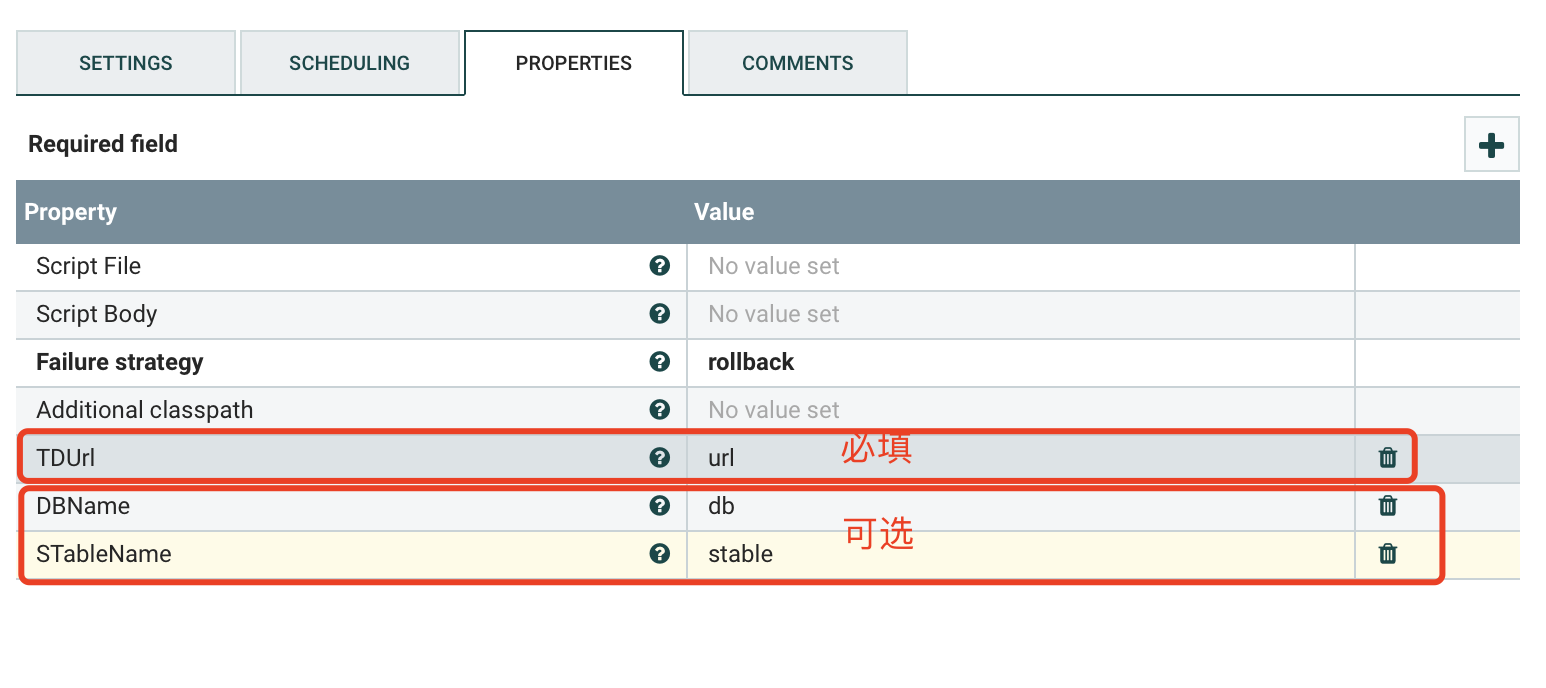
必填参数
TDUrl:TD链接地址
可选参数
DBName:库名,不指定默认以源端库名进行存储
STableName:超级表名,不指定默认以源端超级表名进行存储
三、附页:
1、附1:
// TD 到 TD// Groovy 1import groovy.json.JsonSlurperimport groovy.json.JsonOutputimport java.nio.charset.StandardCharsetsimport org.apache.commons.io.IOUtilsimport java.sql.Connectionimport java.sql.Statementimport java.sql.ResultSetimport com.alibaba.druid.pool.DruidDataSourceStringBuffer stringBuffer = new StringBuffer()JsonSlurper jsonSlurper = new JsonSlurper()JsonOutput jsonOutput = new JsonOutput()ResultSet rs = nullConnection conn = getConnect()Statement statement = conn.createStatement()ArrayList<String> inforList = getConnInfor(statement,rs)for ( text in inforList) {def data = jsonSlurper.parseText(text)String sql = getSQL(data)rs = statement.executeQuery(sql)if (rs == null) { return }ArrayList<String> values = new ArrayList<>()Integer count = 1while (rs.next()) {if ( count % 100000 == 0) {createNewFlowFile(values,data)values.clear();}String PointTime = rs.getTimestamp("point_time")Double ValueDouble = rs.getDouble("value_double")String TagName = getTagName(rs,data.TABLE)String json = JsonOutput.toJson(pointTime:PointTime,valueDouble:ValueDouble,tagName:TagName)values.add(json)count++}if (values != null){createNewFlowFile(values,data)values.clear();}count = 1}if (rs != null) {rs.close()}if (statement != null) {statement.close()}if (conn != null) {conn.close()}// 获取连接池Connection getConnect(){String url = TDUrlDruidDataSource dataSource = new DruidDataSource()// jdbc propertiesdataSource.setDriverClassName("com.taosdata.jdbc.TSDBDriver");dataSource.setUrl(url);dataSource.setUsername("root");dataSource.setPassword("taosdata");// pool configurationsdataSource.setInitialSize(10);dataSource.setMinIdle(10);dataSource.setMaxActive(10);dataSource.setMaxWait(30000);dataSource.setValidationQuery("select server_status()");return dataSource.getConnection()}// 获取连接信息ArrayList<String> getConnInfor(Statement statement,ResultSet rs){ArrayList<String> dataList = new ArrayList<>()String startTime = StartTimeString endTime = EndTimeString dbStr,sTableStr,tableStrString[] dbList,stbList,tbListtry { dbStr = DBList;dbList = dbStr.split(",")} catch (Exception e) { e.printStackTrace()}try { sTableStr = STableList;stbList = sTableStr.split(",") } catch (Exception e) { e.printStackTrace() }try {tableStr = TableList;tbList = tableStr.split(",") } catch (Exception e) { e.printStackTrace() }if (!dbStr) {return}for (db in dbList) {if (tableStr) {if (sTableStr){for (stb in stbList) {for (tb in tbList) {String json = JsonOutput.toJson([DBNAME:db, STABLE:stb, TABLE:tb, STARTTIME:startTime, ENDTIME: endTime])dataList.add(json.toString())}}} else {for (tb in tbList) {String json = JsonOutput.toJson([DBNAME:db, STABLE:"default", TABLE:tb, STARTTIME:startTime, ENDTIME: endTime])dataList.add(json.toString())}}} else if (sTableStr) {for (stb in stbList) {String json = JsonOutput.toJson([DBNAME:db, STABLE:stb, STARTTIME:startTime, ENDTIME: endTime])dataList.add(json.toString())}} else if (dbStr) {String sql = String.format("show %s.stables;",db)rs = statement.executeQuery(sql)if (rs == null) { continue }while (rs.next()) {String sTable = rs.getString(1)String json = JsonOutput.toJson([DBNAME:db, STABLE:sTable, STARTTIME:startTime, ENDTIME: endTime])dataList.add(json.toString())}}}return dataList}// 获取sqlString getSQL (def data) {String sqlif (data.TABLE) {sql = String.format("SELECT * FROM %s.%s WHERE point_time >= '%s' AND point_time <= '%s' ",data.DBNAME,data.TABLE,data.STARTTIME,data.ENDTIME)} else {sql = String.format("SELECT * FROM %s.%s WHERE point_time >= '%s' AND point_time <= '%s' ",data.DBNAME,data.STABLE,data.STARTTIME,data.ENDTIME)}return sql}// 获取tagNameString getTagName(ResultSet rs,String jsonTagName) {if (jsonTagName) {return jsonTagName}return rs.getString("tagName")}// 创建流文件def createNewFlowFile(ArrayList<String> values,def data){newFlowFile = session.create()session.write(newFlowFile, {outputStream ->outputStream.write(Arrays.toString(values.toArray()).getBytes(StandardCharsets.UTF_8))} as OutputStreamCallback)newFlowFile = session.putAttribute(newFlowFile, 'DBNAME', data.DBNAME)newFlowFile = session.putAttribute(newFlowFile, 'STABLE', data.STABLE)session.transfer(newFlowFile, REL_SUCCESS)}
2、附2:
import groovy.json.JsonSlurperimport java.nio.charset.StandardCharsetsimport org.apache.commons.io.IOUtilsimport java.sql.Connectionimport java.sql.Statementimport java.sql.SQLExceptionimport java.sql.DriverManagerimport com.alibaba.druid.pool.DruidDataSourcedef flowFileList=session.get(1000)if (!flowFileList)returnConnection conn = nullStatement statement = null//StringBuffer stringBuffer = new StringBuffer()def jsonSlurper = new JsonSlurper()String url = TDUrlconn = getConnect(url)Integer count = 1String sql = "INSERT INTO "String sTabledef getConnect(String jdbcUrl){DruidDataSource dataSource = new DruidDataSource()// jdbc propertiesdataSource.setDriverClassName("com.taosdata.jdbc.TSDBDriver");dataSource.setUrl(jdbcUrl);dataSource.setUsername("root");dataSource.setPassword("taosdata");// pool configurationsdataSource.setInitialSize(10);dataSource.setMinIdle(10);dataSource.setMaxActive(10);dataSource.setMaxWait(30000);dataSource.setValidationQuery("select server_status()");return dataSource.getConnection()}try{sTable=STABLE}catch(Exception e){e.printStackTrace()}for (flowFile in flowFileList) {if ( flowFile == null ) { continue }String AttributeSTable = flowFile.getAttribute('STABLE')String content = ""session.read(flowFile, {inputStream ->content = IOUtils.toString(inputStream, StandardCharsets.UTF_8)} as InputStreamCallback)if (content == "" ) { continue }def jsonList = jsonSlurper.parseText(content)for (data in jsonList) {if ( count % 200 == 0) {statement = conn.createStatement()statement.executeUpdate(sql)// stringBuffer.append(sql)sql = "INSERT INTO "}String tagName = data.tagNameString[] tagNameList = tagName.split("\\.")String newTagNameif (sTable) {newTagName = tagName.replace(".","_")} else {sTable = AttributeSTablenewTagName = tagName.replace(".","_")}String pointTime = data.pointTimeDouble valueDouble = data.valueDoubleString valueSql = String.format("%s USING %s TAGS (%s) VALUES ('%s',%s) ", newTagName, sTable, newTagName, pointTime, valueDouble )sql = sql.concat(valueSql)count ++}}if ( sql != "INSERT INTO ") {statement = conn.createStatement()statement.executeUpdate(sql)// stringBuffer.append(sql)}// closeif ( conn != null ) { conn.close() }if ( statement != null ) { statement.close() }//newFlowFile = session.create()//session.write(newFlowFile, {outputStream ->// outputStream.write(stringBuffer.toString().getBytes(StandardCharsets.UTF_8))//} as OutputStreamCallback)//session.transfer(newFlowFile, REL_SUCCESS)// flowFile --> successsession.transfer(flowFileList,REL_FAILURE)

若有收获,就点个赞吧
0 人点赞
