注:历史和实时采用同一套处理流程,区别在于POST请求的JSON格式以及JOLT解析规则
一、源端
1、详细流程结构
1.1 外层(Process Group)
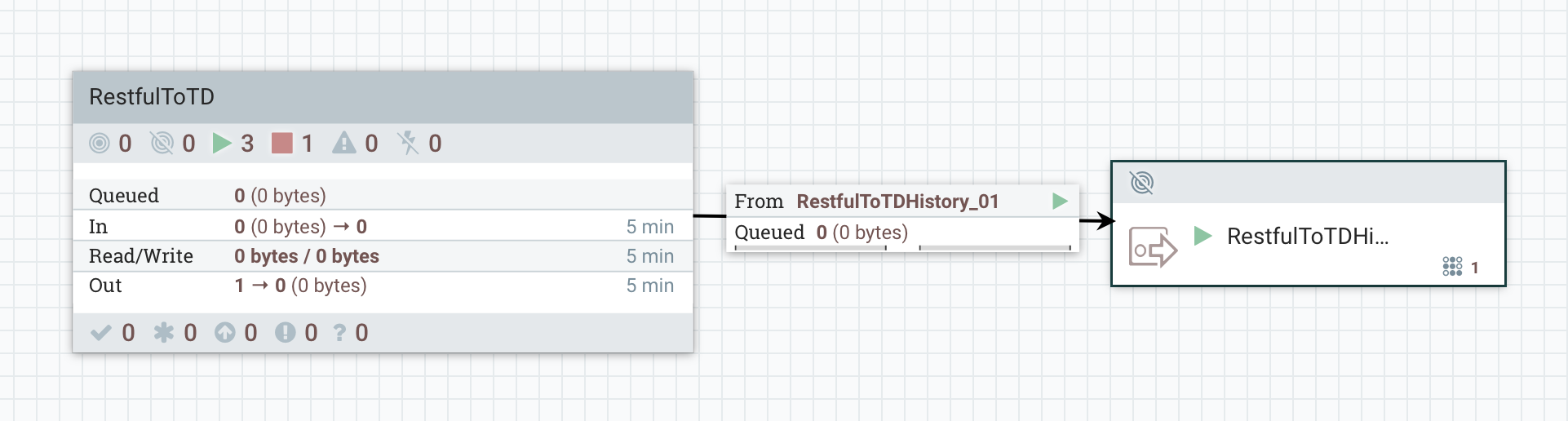
1.2 内层
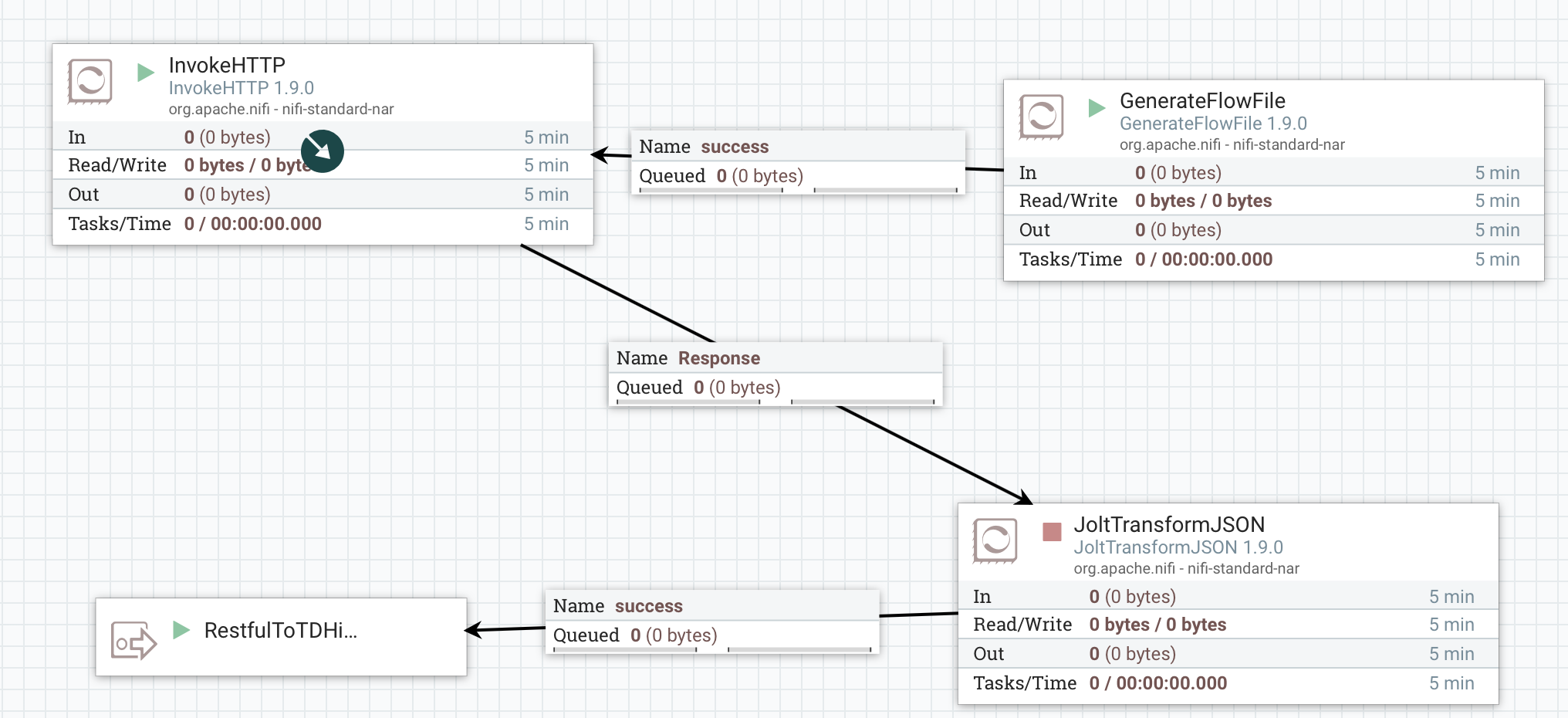
2、processor
2.1、GenerateFlowFile
a) 功能简介
指定文本(post请求),生成流文件,传入下一个处理器(InvokeHTTP)
b) SETTINGS
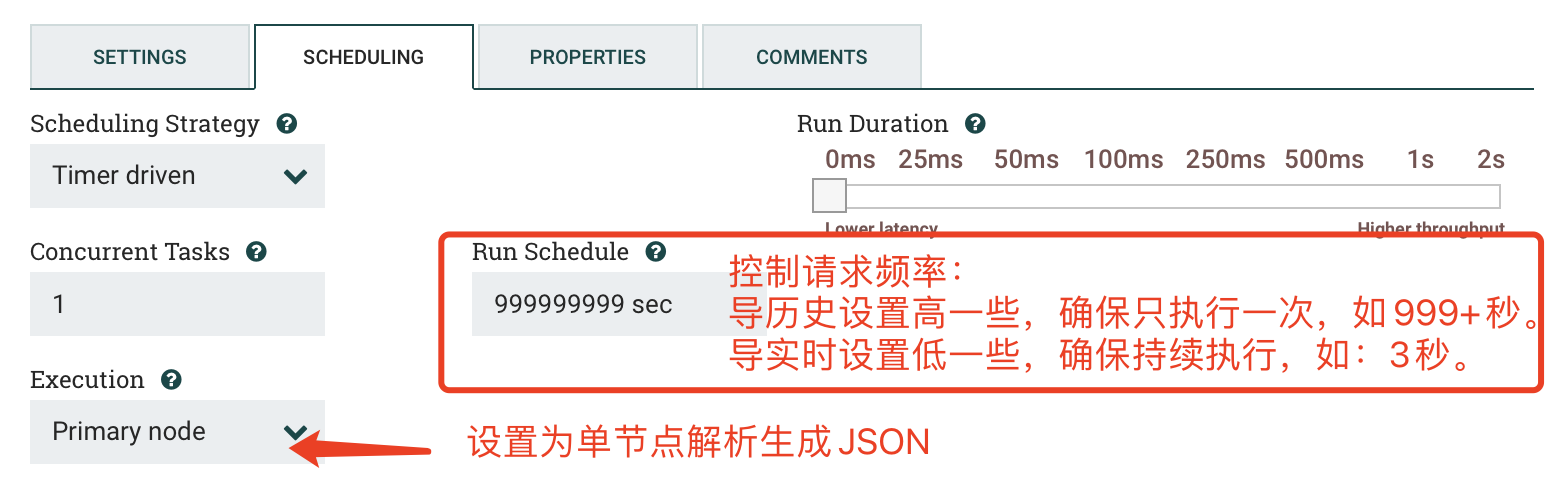
c) SCHEDULING
d) PROPERTIES
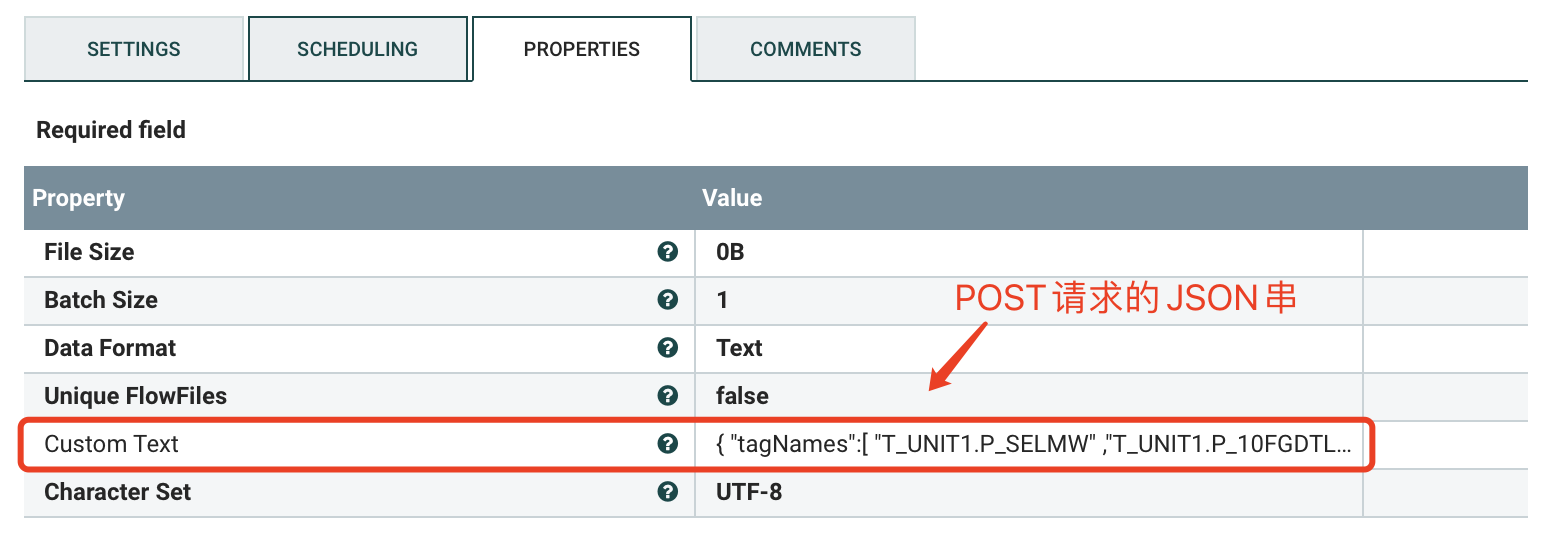 实时请求格式为:
实时请求格式为:
{"tagNames":["T_UNIT1.P_SELMW", // 标签点名"T_UNIT1.P_10FGDTL206Q"]}
历史请求格式为:
{"tagNames":["T_UNIT1.P_SELMW","T_UNIT1.P_10FGDTL206Q","T_UNIT1.P_10FGDTL205Q","T_UNIT1.P_10FGDTL204Q"],"count":4,"startTime":"2021-05-01 15:50:35.000","endTime":"2021-11-22 15:53:39.000"}
2.2、InvokeHTTP
a) 功能简介
指定POST方式请求,请求内容为上一个流的流文件。响应数据为结果数据集,以流的形式传入下游进行解析。
b) SETTINGS
c) SCHEDULING
d) PROPERTIES
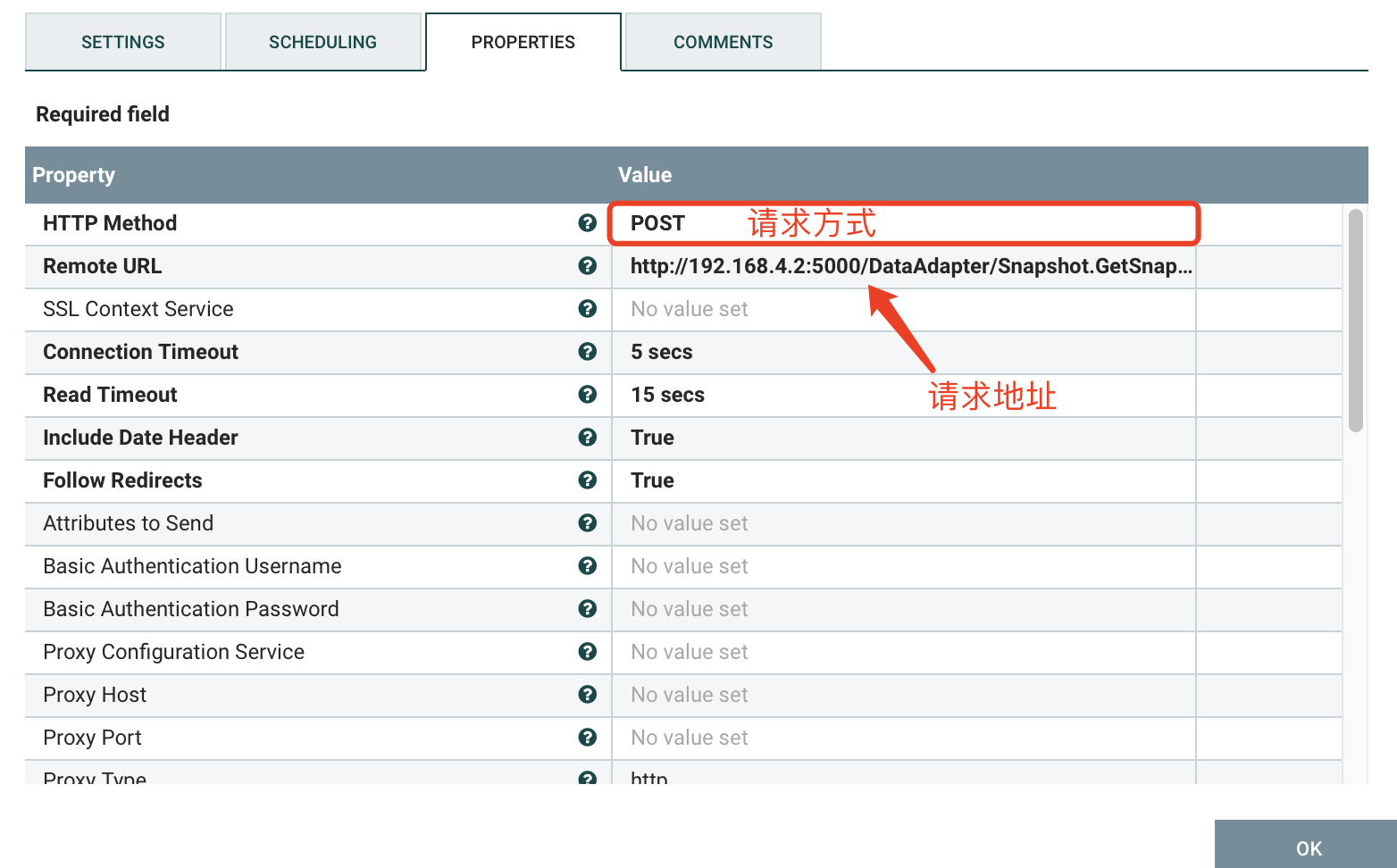
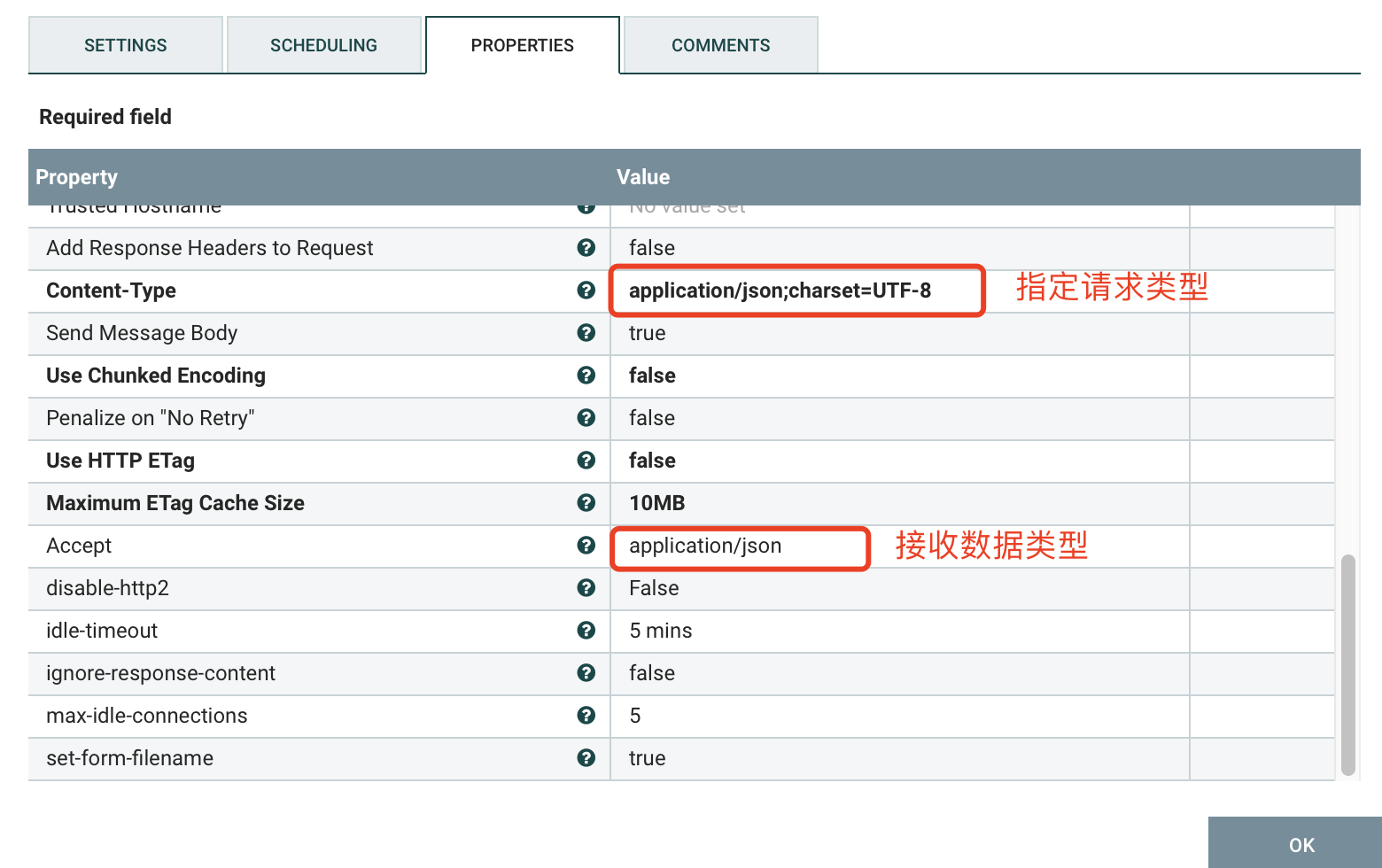
2.3、JoltTransformJSON
a) 功能简介
b) SETTINGS
c) SCHEDULING
d) PROPERTIES
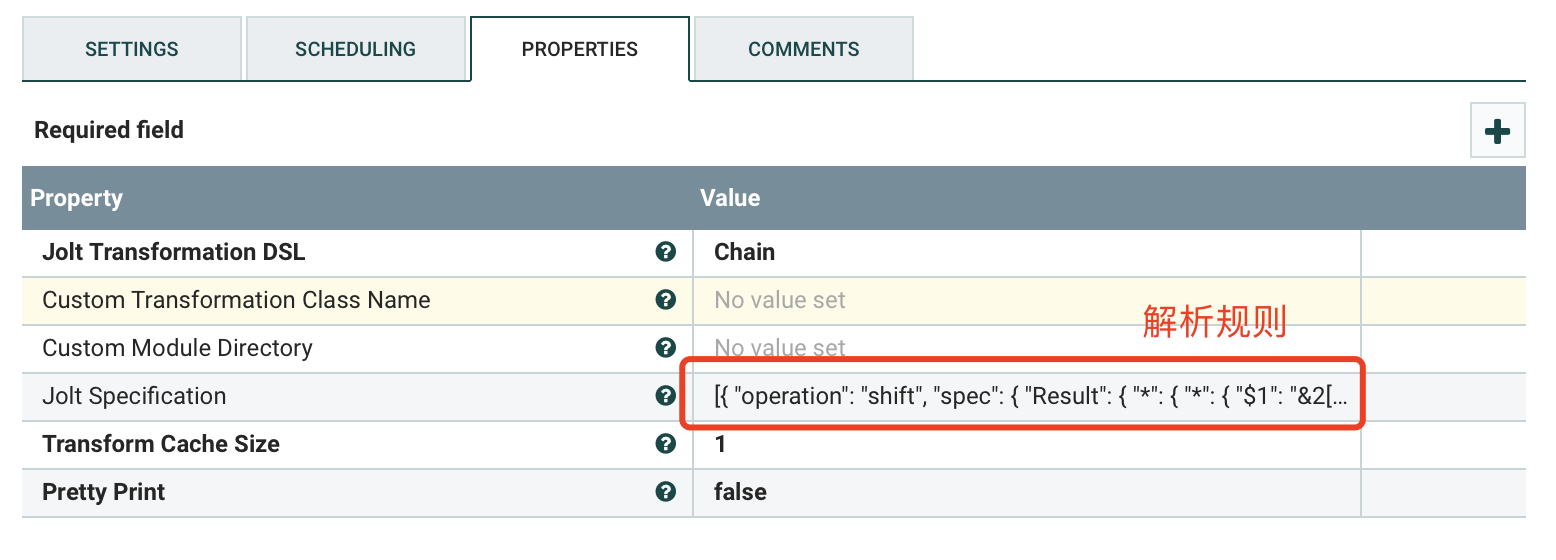
实时解析规则:
[{"operation": "shift","spec": {"Result": {"*": {"TagFullName": "&2[#2].tagName","Time": "&2[#2].pointTime","Value": "&2[#2].valueDouble"}}}}]
历史解析规则:
[{"operation": "shift","spec": {"Result": {"*": {"*": {"$1": "&2[#2].tagName","Time": "&2[#2].pointTime","Value": "&2[#2].valueDouble"}}}}}]
2.4、OutPut
二、目标端
1、详细流程展示
1.1 外层(Process Group)
1.2 内层

2、Processor
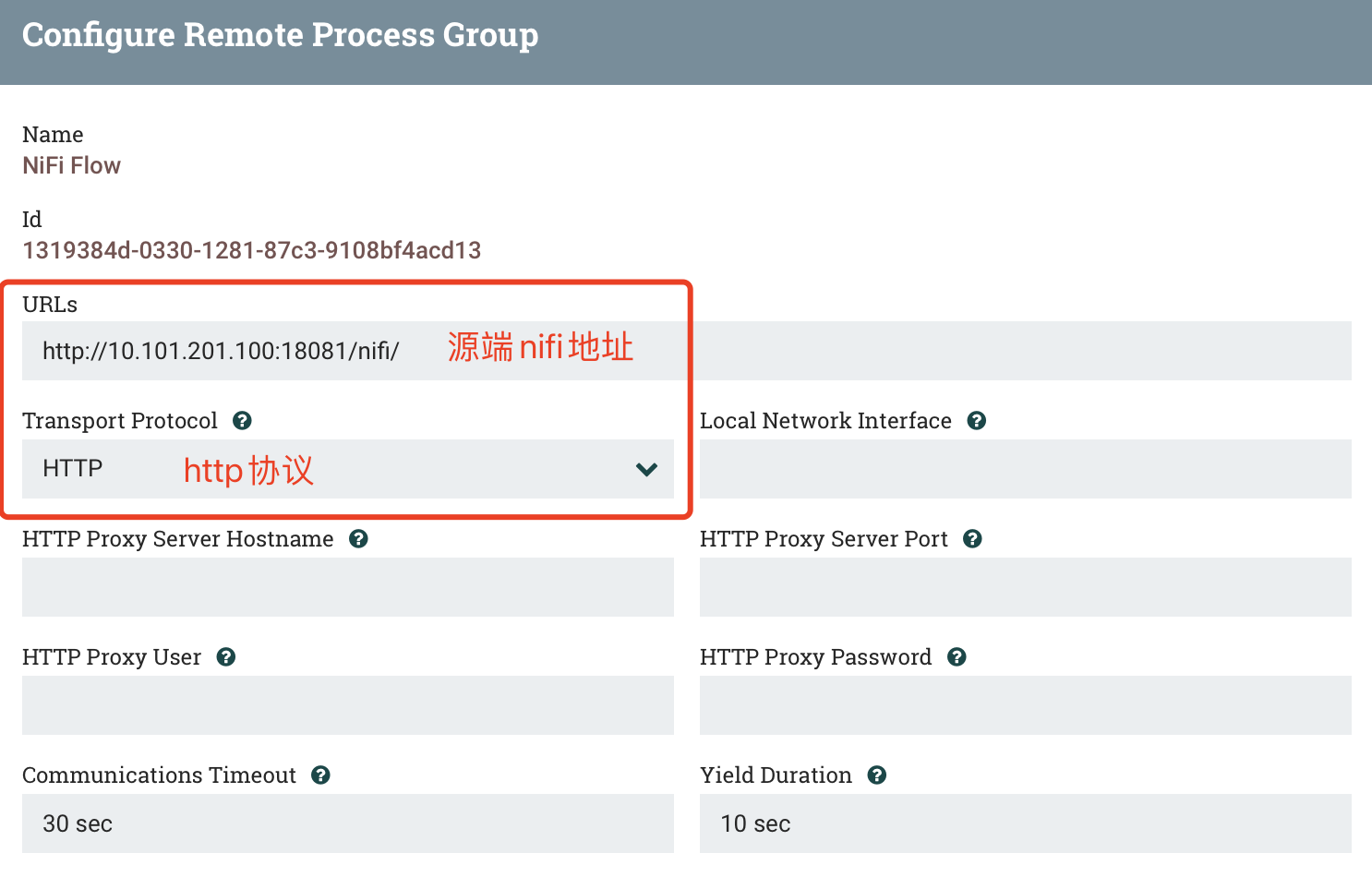
2.1、NifiFlow
a) 功能简介
b) SETTINGS
2.2、ExecuteGroovyScript
a) 功能简介
b) SETTINGS
c) SCHEDULING
d) PROPERTIES
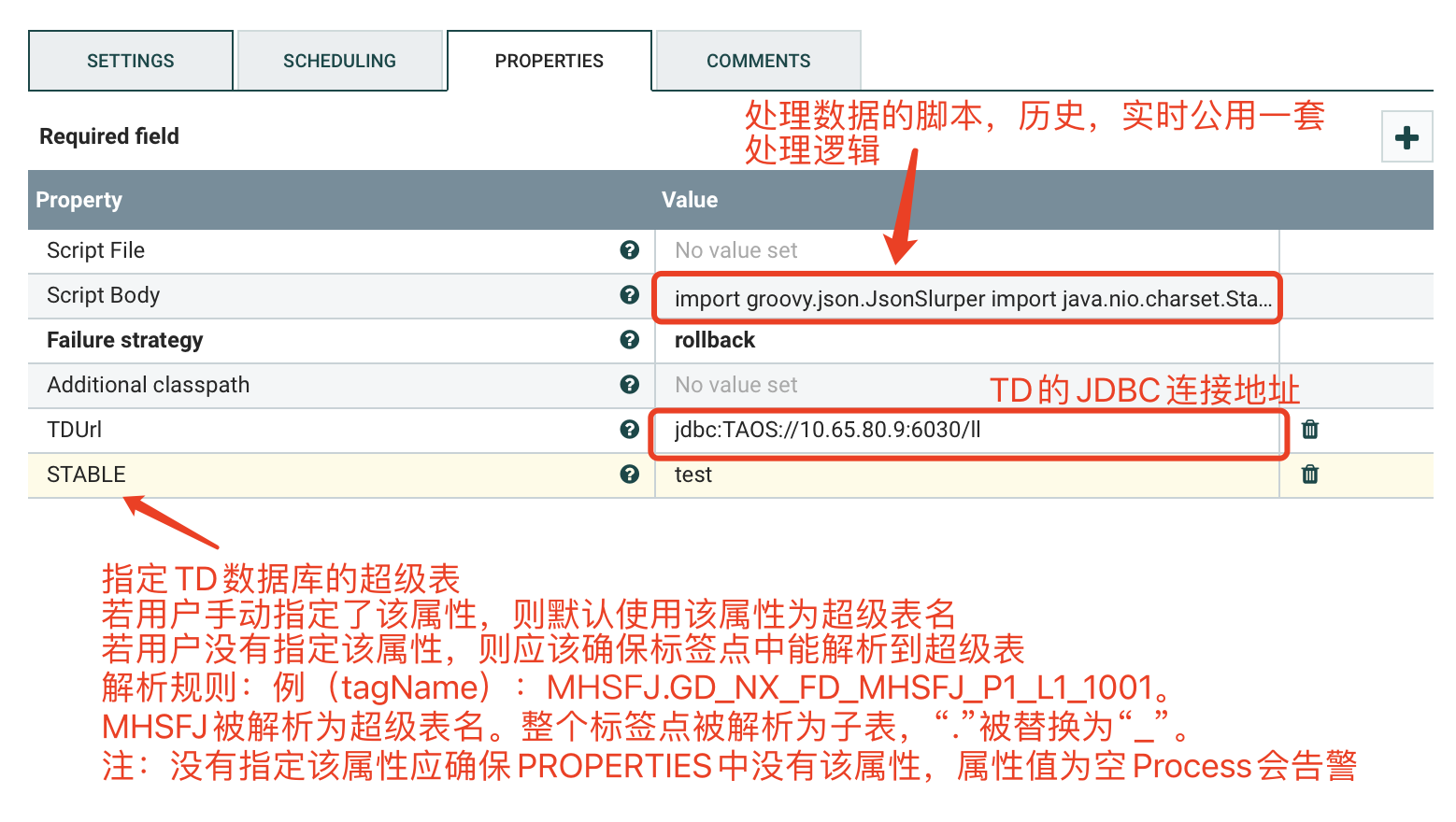
e) 处理脚本(Script Body),如下:
import groovy.json.JsonSlurperimport java.nio.charset.StandardCharsetsimport org.apache.commons.io.IOUtilsimport java.sql.Connectionimport java.sql.Statementimport java.sql.SQLExceptionimport java.sql.DriverManagerimport com.alibaba.druid.pool.DruidDataSource// 获取多个流文件def flowFileList=session.get(200)if (!flowFileList)returnConnection conn = nullStatement statement = null//StringBuffer stringBuffer = new StringBuffer()JsonSlurper jsonSlurper = new JsonSlurper()String url = TDUrlString sql = "INSERT INTO "Integer count = 1def getConnect(String jdbcUrl){DruidDataSource dataSource = new DruidDataSource()// jdbc propertiesdataSource.setDriverClassName("com.taosdata.jdbc.TSDBDriver");dataSource.setUrl(jdbcUrl);dataSource.setUsername("root");dataSource.setPassword("taosdata");// pool configurationsdataSource.setInitialSize(10);dataSource.setMinIdle(10);dataSource.setMaxActive(10);dataSource.setMaxWait(30000);dataSource.setValidationQuery("select server_status()");conn = dataSource.getConnection()if (!conn) {log.error(" connect error")session.transfer(flowFileList,REL_FAILURE)return}}// get connectgetConnect(url)for (flowFile in flowFileList) {// get flowFile contentString content = ''session.read(flowFile, {inputStream ->content = IOUtils.toString(inputStream, StandardCharsets.UTF_8)} as InputStreamCallback)if (content == "" ) { continue }// format jsondef data = jsonSlurper.parseText(content)data.values().each{it.each {json ->if (json == null || json == "") { return true }Double value = json.valueDoubleString time = json.pointTimeString tagName = json.tagNameif (value==null || time == null || tagName == null) { return true }String newTagName = tagName.replace(".","_")String sTabletry {sTable = STABLE} catch(E) {try {sTable = tagName.split("\\.")[0]} catch (NullPointerException e) {log.error("用户未指定超级表名且未检测到标签点名中含有超级表名,(检测规则:超级表名.字表名),请指定超级表名!")e.printStackTrace()}}if ( count % 200 == 0) {statement = conn.createStatement()statement.executeUpdate(sql)//stringBuffer.append(sql)//stringBuffer.append("\r\n")sql = "INSERT INTO "}String valueSql = String.format("%s USING %s TAGS (%s) VALUES ('%s',%s) ", newTagName, sTable, newTagName, time, value )sql = sql.concat(valueSql)count ++}}if ( sql != "INSERT INTO ") {statement = conn.createStatement()statement.executeUpdate(sql)//stringBuffer.append(sql)//stringBuffer.append("\r\n")}}// closeif ( conn != null ) { conn.close() }if ( statement != null ) { statement.close() }//newFlowFile = session.create()//session.write(newFlowFile, {outputStream ->// outputStream.write(stringBuffer.toString().getBytes(StandardCharsets.UTF_8))//} as OutputStreamCallback)//session.transfer(newFlowFile, REL_SUCCESS)// flowFile --> successsession.transfer(flowFileList,REL_FAILURE)

若有收获,就点个赞吧
0 人点赞
