一、整体流程

二、ExecuteGroovyScript
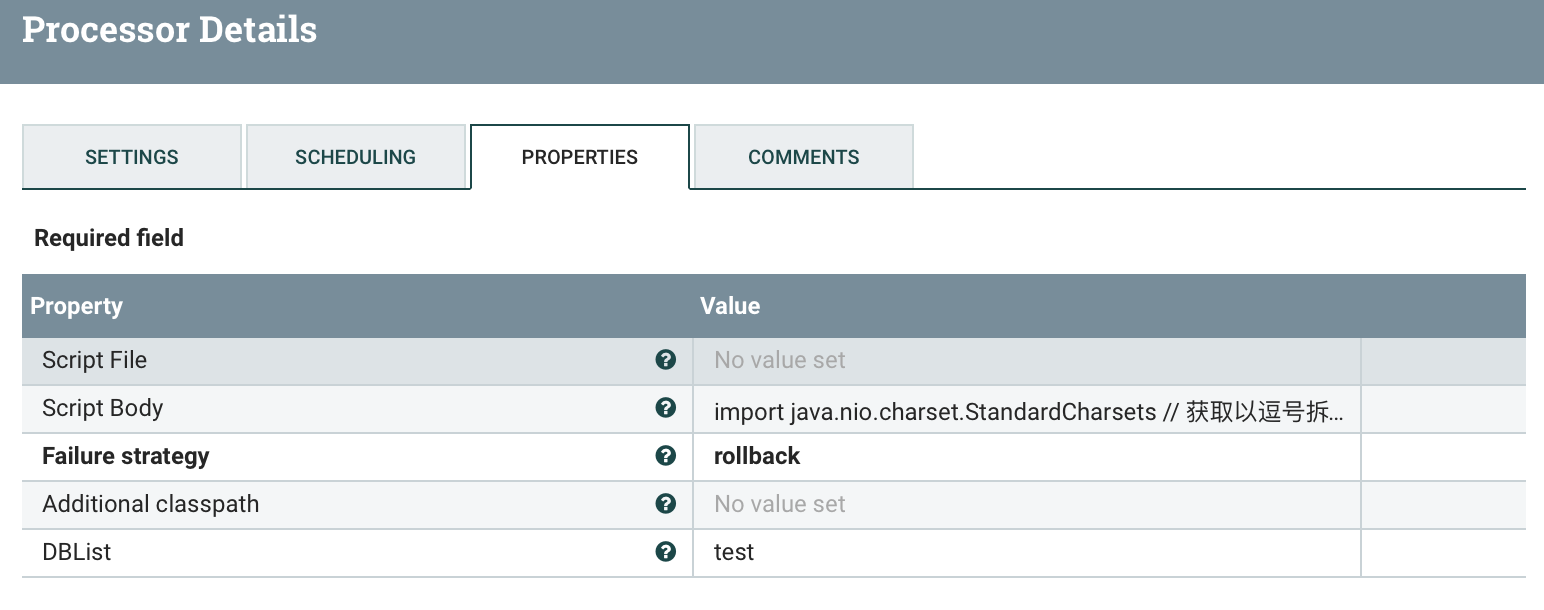
功能描述:用户输入库名列表(以逗号分隔),此脚本拆分库名并以一个库名为一个flowfile为单位传出。
输入属性:DBList
输出属性:DBName
输出内容:被拆分的数据库名(flowfile)
import java.nio.charset.StandardCharsets// 获取以逗号拆分的库名字符串String DBList = DBList// 拆分库名String[] data = DBList.split(",")// 获取数据长度int length = data.length;if (length==0){return}// 循环所有库for (Integer i = 0; i < length; i++) {if (data[i]==""){session.transfer(flowFile,REL_FAILURE)continue}flowFile = session.create()// 添加属性flowFile = session.putAttribute(flowFile, 'DBName', data[i])// 写入flowFile中session.write(flowFile, {outputStream ->outputStream.write(data[i].toString().getBytes(StandardCharsets.UTF_8))} as OutputStreamCallback)// flowFile --> successsession.transfer(flowFile, REL_SUCCESS)}
三、SelectHiveQL
功能描述:通过上一个process传入的DBName获取库下面的所有表名,以CSV格式不携表头不带引号传出
输入属性:
输出属性:DBName
输出内容:表名集合(flowfile)
配置详情: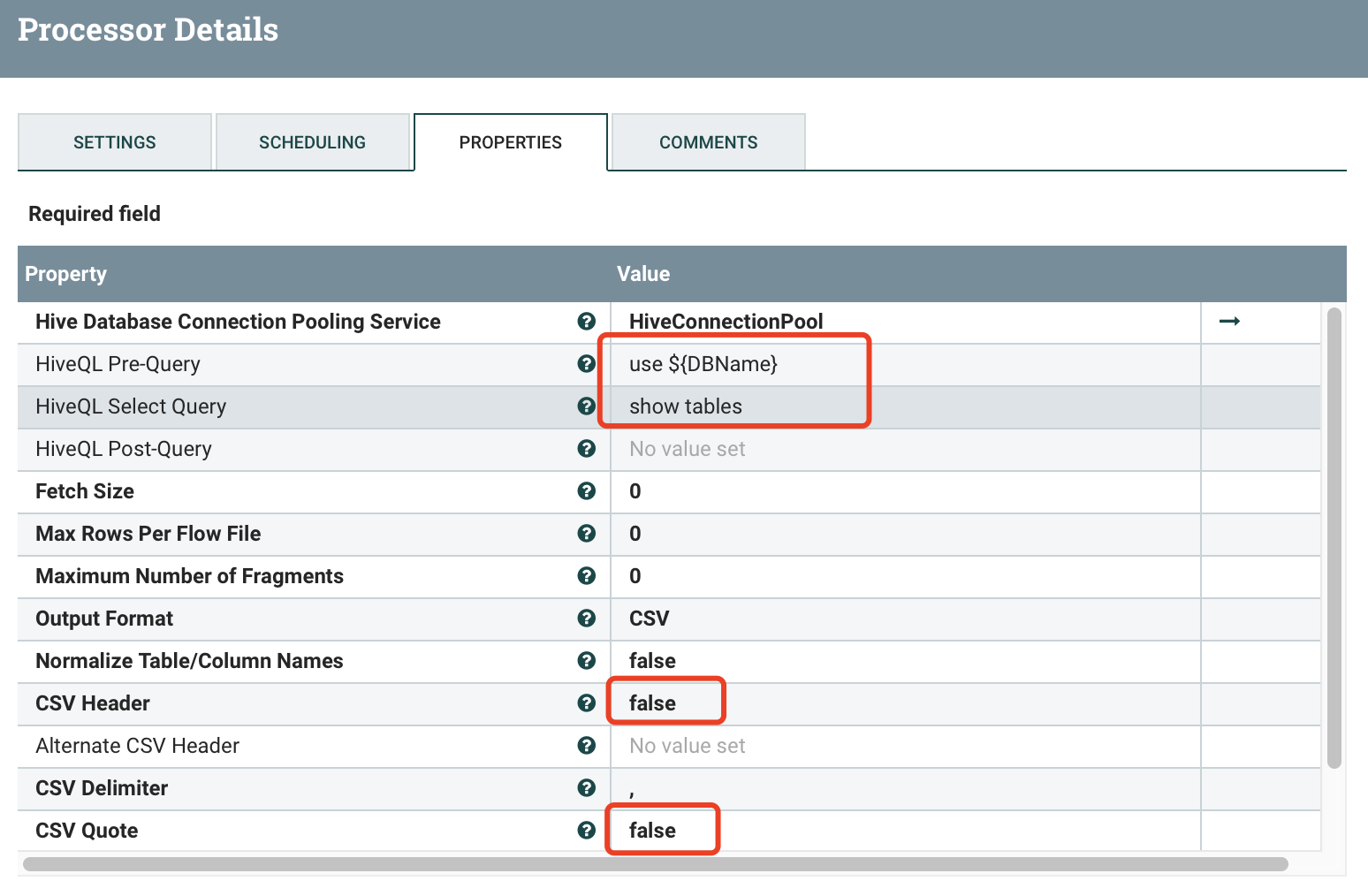
1、HiveConnectionPool
四、ExecuteGroovyScript
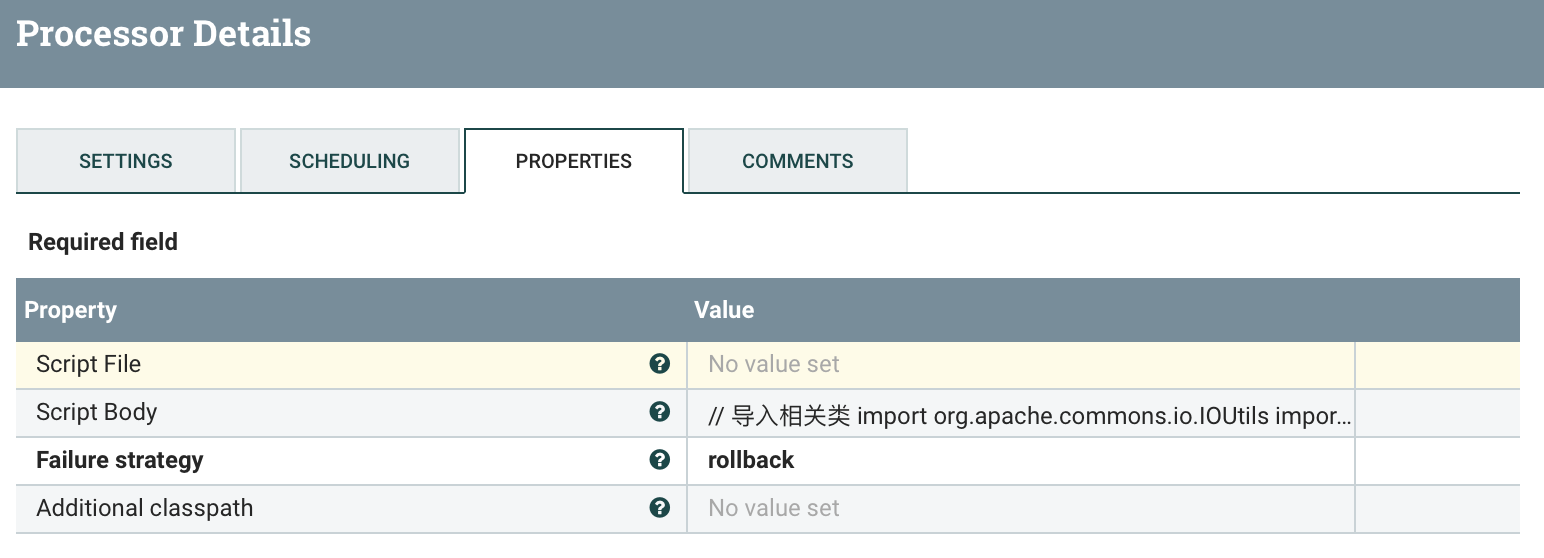
功能描述:通过上面获取到的库名加表名拆分组装json传出
输入属性:
输出属性:TBName、DBName
输出内容:TBName+DBName的json串(flowfile)
// 导入相关类import org.apache.commons.io.IOUtilsimport java.nio.charset.StandardCharsets// 获取流文件flowFile = session.get()// 读取文件内容def text = ''session.read(flowFile, {inputStream ->text = IOUtils.toString(inputStream, StandardCharsets.UTF_8)} as InputStreamCallback)// 获取DBNamedef DBName = flowFile.getAttribute('DBName')if (text == '') {session.transfer(flowFile, REL_FAILURE)return}// 拆分表名String[] data = text.split("\n")// 获取数据长度int length = data.length;// 循环所有库for (Integer i = 0; i < length; i++) {newFlowFile = session.create()// 添加属性newFlowFile = session.putAttribute(newFlowFile, 'DBName', DBName)// 添加属性newFlowFile = session.putAttribute(newFlowFile, 'TBName', data[i])// 声明容器存储结果StringBuffer stringBuffer = new StringBuffer()stringBuffer.append("{\"DBName\":\""+ DBName + "\",\"TBNaem\":\"" + data[i] + "\"}")// 写入flowFile中session.write(newFlowFile, {outputStream ->outputStream.write(stringBuffer.toString().getBytes(StandardCharsets.UTF_8))} as OutputStreamCallback)// flowFile --> successsession.transfer(newFlowFile, REL_SUCCESS)}// flowFile --> successsession.transfer(flowFile, REL_FAILURE)
五、SelectHiveQL
功能描述:通过获取到的库名加表名查询数据,以Avro格式输出。
输入属性:
输出属性:
输出内容:flowfile
配置详情: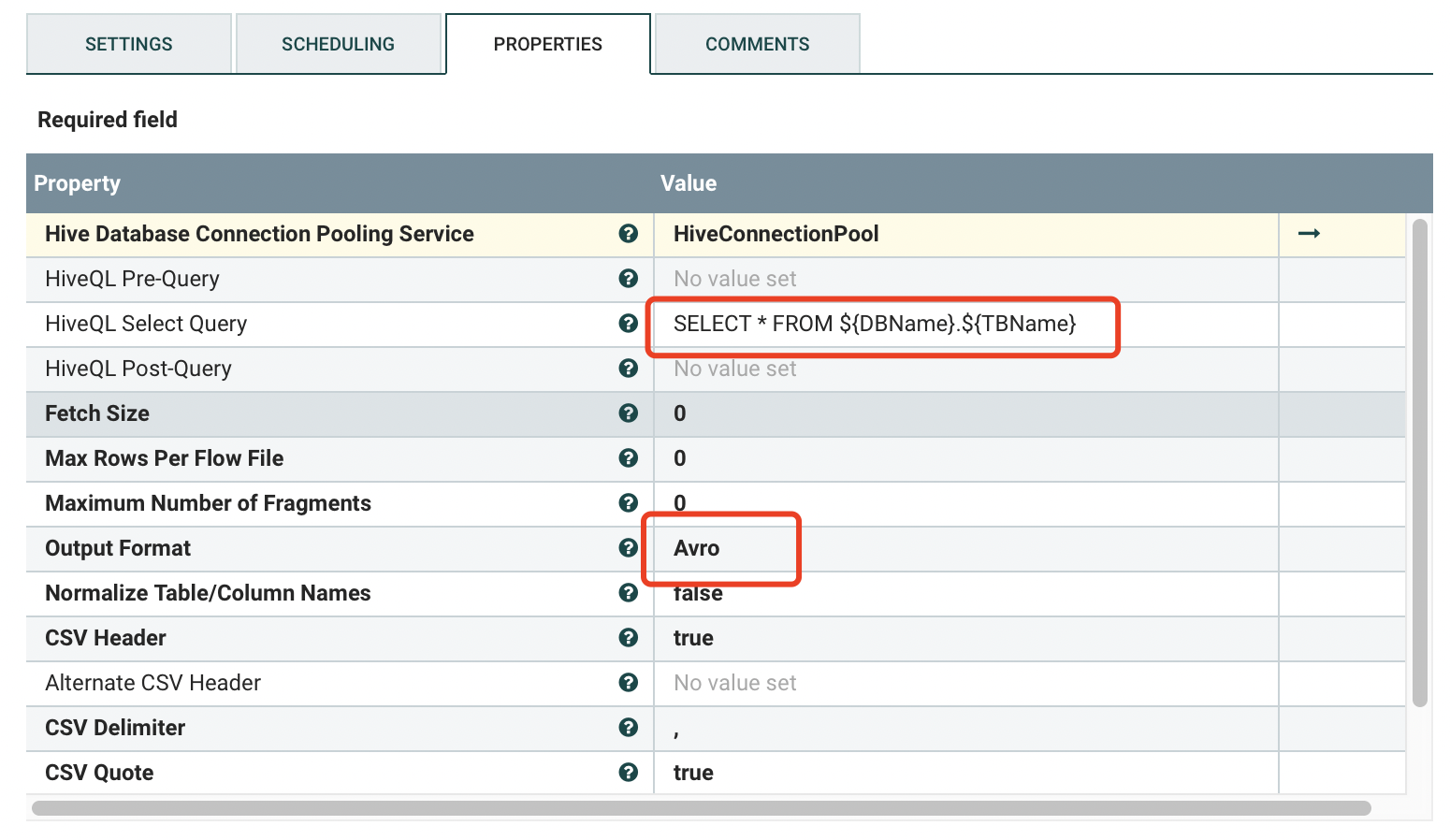
六、PutHiveStreaming
功能描述:解析SelectHiveQL输出的数据,存储数据到指定表。该处理器用于向hive表写 数据,数据要求是avro格式,要求使用者熟练使用hive。通过 thrift nifi连hive的问题有点复杂,Apache版NIFI对应的Apache版hive,HDP版NIFI对应的HDP版hive。连接HDP版hive时NIFI运行环境需配置hive HDFS的相关hosts,并且运行NIFI 的用户拥有hive表的读写权限。此处理器hive支持的版本为1.2.1,不支持hive2.x,hive3.x则使用别的处理器。
输入属性:
输出属性:
输出内容:flowfile
配置详情: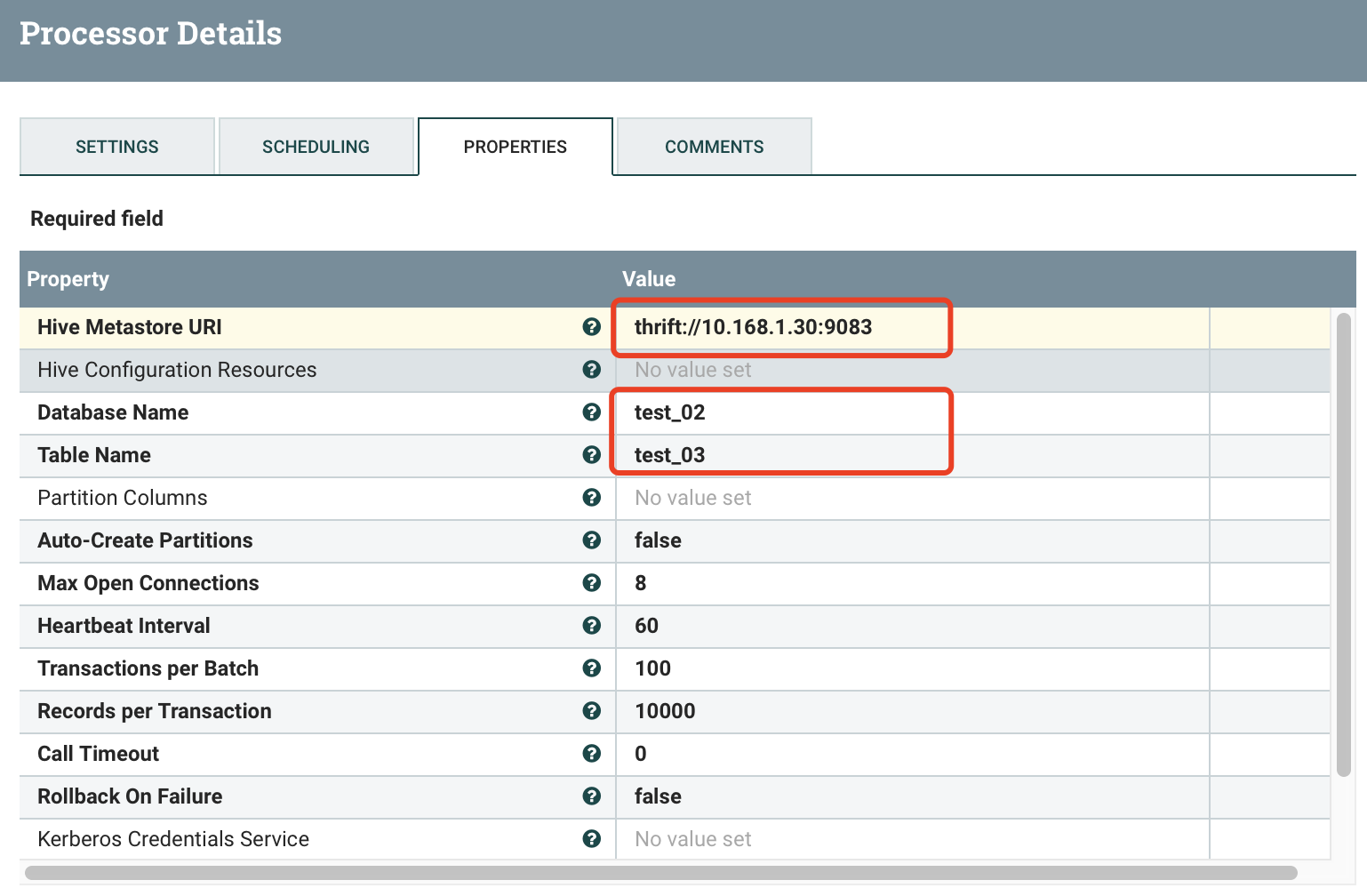
示例说明:
1、从数据库读取数据写入hive表(无分区),Apache NIFI 1.8 - Apache hive 1.2.1
建表语句:
CREATE TABLE test_03(table_name string)CLUSTERED BY (table_name) INTO 5 BUCKETSSTORED AS ORCTBLPROPERTIES('transactional'='true');
2、hive表只能是ORC格式。
3、默认情况下(1.2及以上版本)建表使用SQL2011关键字会报错,如果弃用保留关键字,还需另做配置。建表时必须指明transactional = “true”,建表时需”clustered by (colName) into (n) buckets”。详情请查看hive streaming 官方文档(https://cwiki.apache.org/confluence/display/Hive/Streaming+Data+Ingest)
七、问题
1、FAILED:SemanticException

FAILED:SemanticException [错误10265]:在具有非ACID事务管理器的ACID表test_db.test_table上不允许此命令。命令失败:null
4.1、必須将Hive事务管理器设置为org.apache.hadoop.hive.ql.lockmgr.DbTxnManager才能使用ACID表。
SET hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
Additionally, Set these properties to turn on transaction support
4.2、此外,设置这些属性,以打开事务支持
Client Side
SET hive.support.concurrency=true;SET hive.enforce.bucketing=true;SET hive.exec.dynamic.partition.mode=nonstrict;
Server Side (Metastore)
服务器端(Metastore)
SET hive.compactor.initiator.on=true;SET hive.compactor.worker.threads=1;
参考:
https://www.itdaan.com/tw/787e68af21a78a511ccd5f3395fc79c6
https://blog.csdn.net/qq_25794453/article/details/78412338
2、UnknownHostException:nameservice1
配置/etc/hosts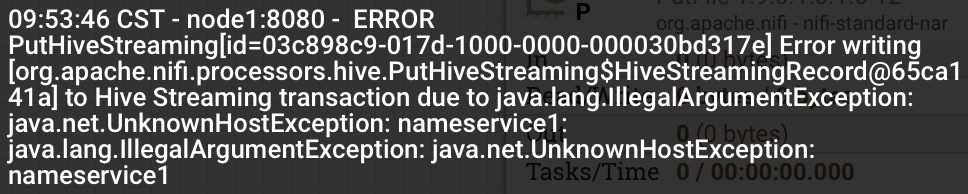
3、PutHiveStreaming 报错:
org.apache.nifi.util.hive.HiveWriterSConnectFailure:Failure connecting EndPoint ({metaStoreUri = ' thrift://10.65.80.2:9083',database='guohua',table="dwd_mm_gh_org_department_b", partitionVals=[2018]}
原因:目标段hive版本为1.1,nifi端hive依赖为1.2。版本不兼容
CDH本地有hive1.1的包和1.2的包,分别依赖nifi-hive-nar.jar(hive1.2)、nifi-hive-1_1-nar.jar(hive1.1),但是观察PutHiveStraming,使用的依赖nar为hive1.2的。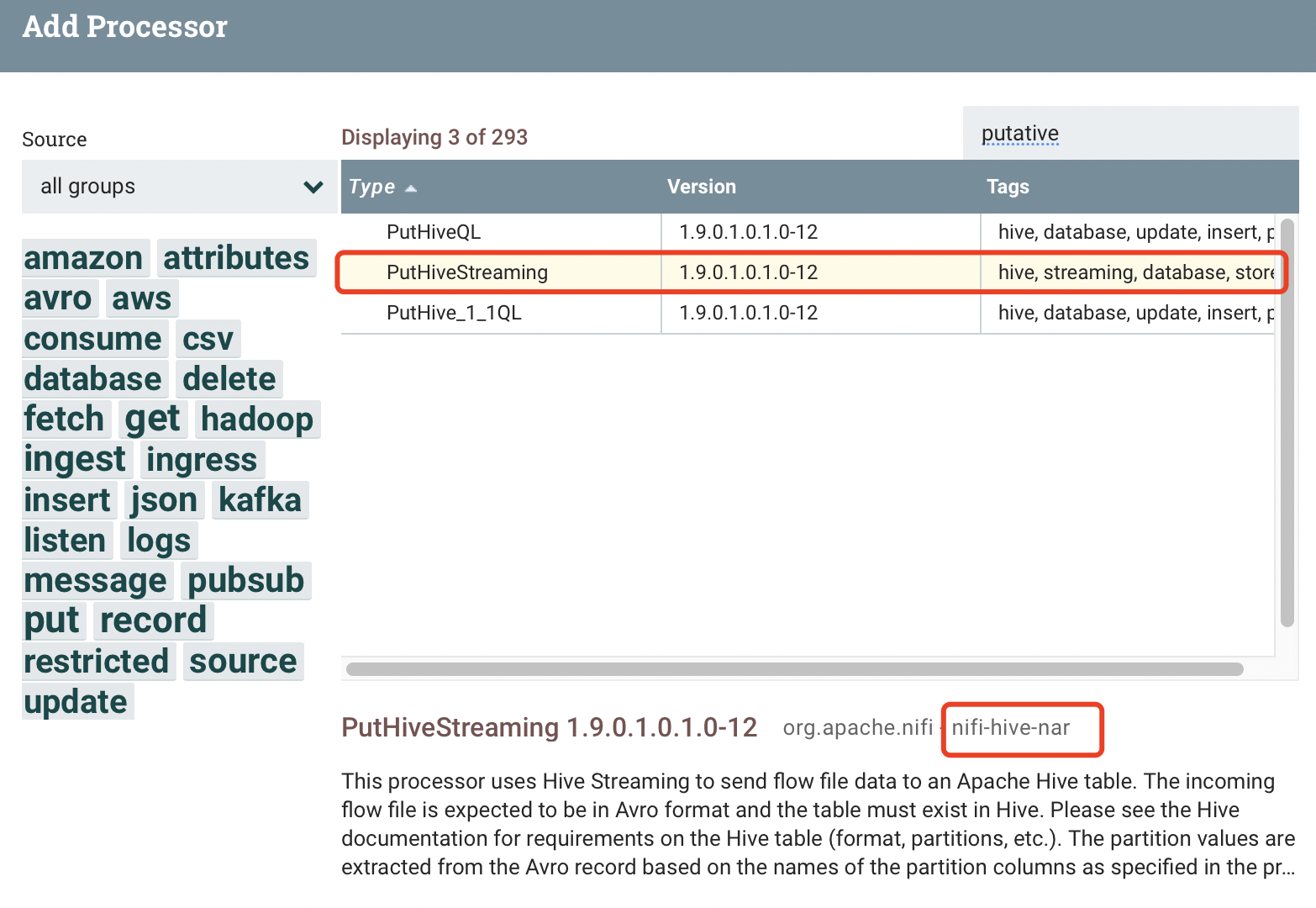
解决方案:
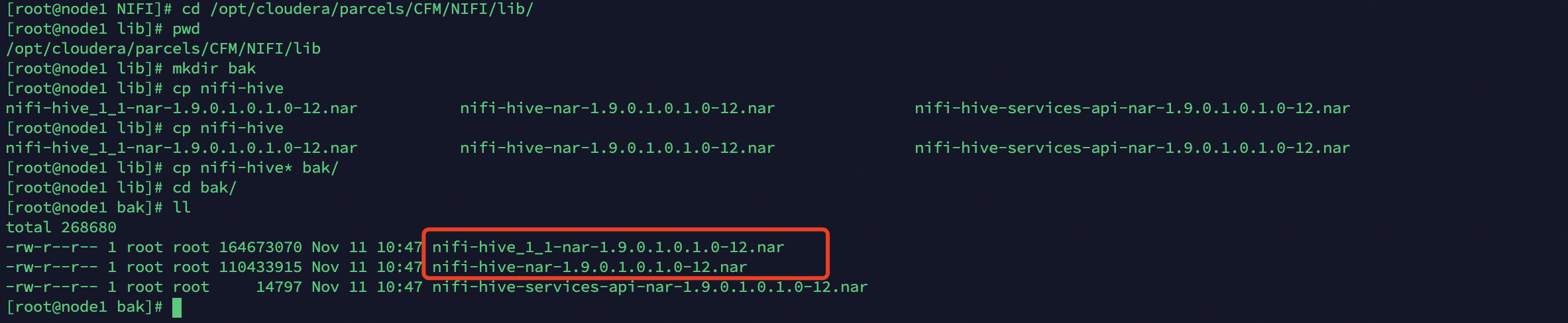
1、到${NIFI}\lib目录copy hive1.1和hive1.2的包
cd /opt/cloudera/parcels/CFM/NIFI/lib/mkdir bakcp nifi-hive* bak/cd bak/ll
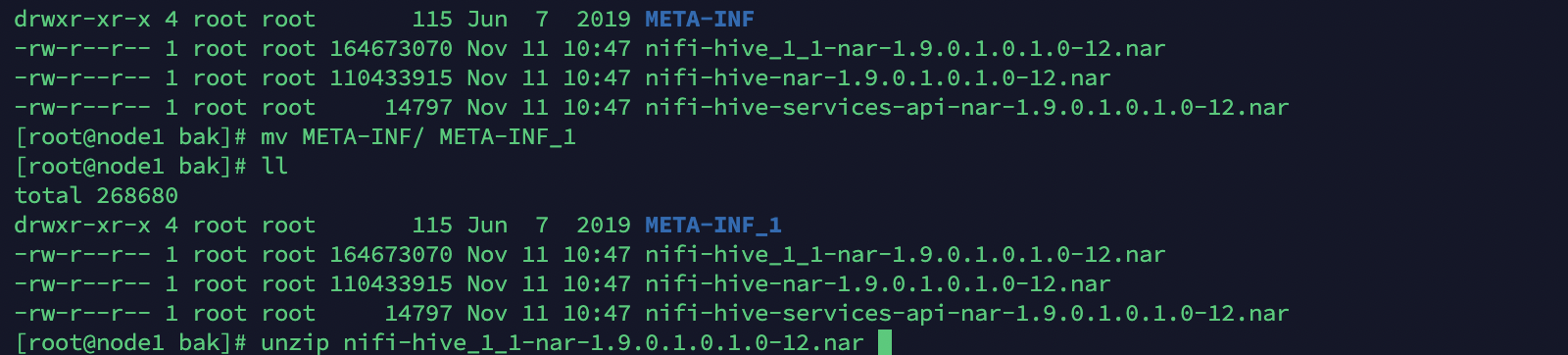
2、解压两个包分别为META-INF(2版本)、META-INF_1(1版本)
unzip nifi-hive_1_1-nar-1.9.0.1.0.1.0-12.narmv META-INF META-INF_1unzip nifi-hive-nar-1.9.0.1.0.1.0-12.narll

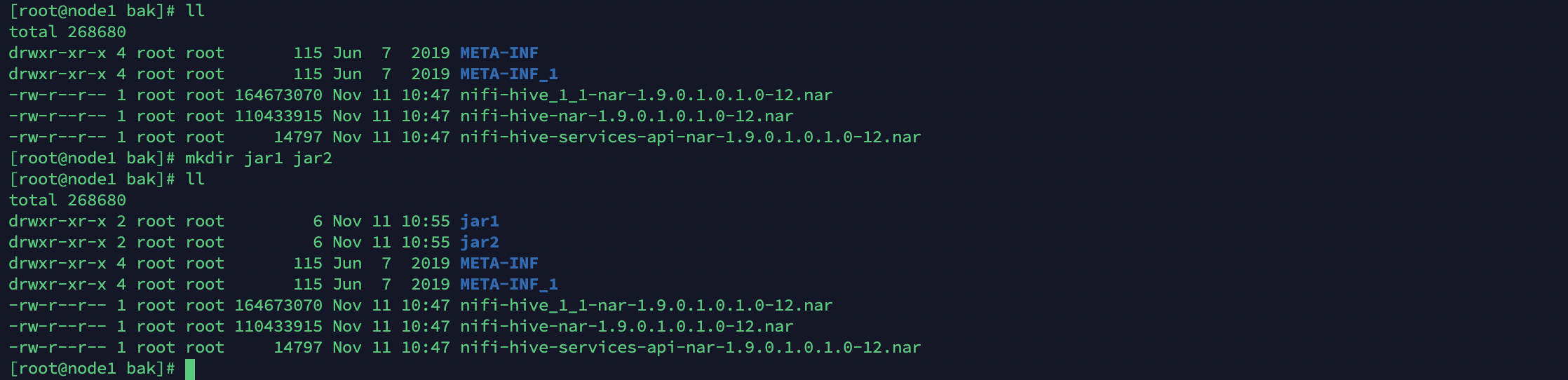
3、新建两个目录移动jar包
mkdir jar1 jar2ll
4、移动nar1和2的hive-.jar 和hadoop-mapreduce-client-.jar 分别到jar1和jar2
5、额外移动htrace-*.jar
6、查看两个jar
7、把jar1的jar包移动到META-INF(hive2)
cp jar1/* META-INF/bundled-dependencies/
8、压缩META-INFO
-- 压缩之前先备份nifi-hive-nar(hive2)mv nifi-hive-nar-1.9.0.1.0.1.0-12.nar nifi-hive-nar-1.9.0.1.0.1.0-12.nar.bakzip -r -q nifi-hive-nar-1.9.0.1.0.1.0-12.nar META-INF
9、移动替换后到jar包到${NIFI_HOME}\lib,覆盖原来hive2依赖的nar
mv nifi-hive-nar-1.9.0.1.0.1.0-12.nar /opt/cloudera/parcels/CFM/NIFI/lib/

10、重启nifi,问题解决。

若有收获,就点个赞吧
0 人点赞
