1、测试
- 移动package包到根目录下,cdc到package目录下开始执行代码
- 目录结构如下

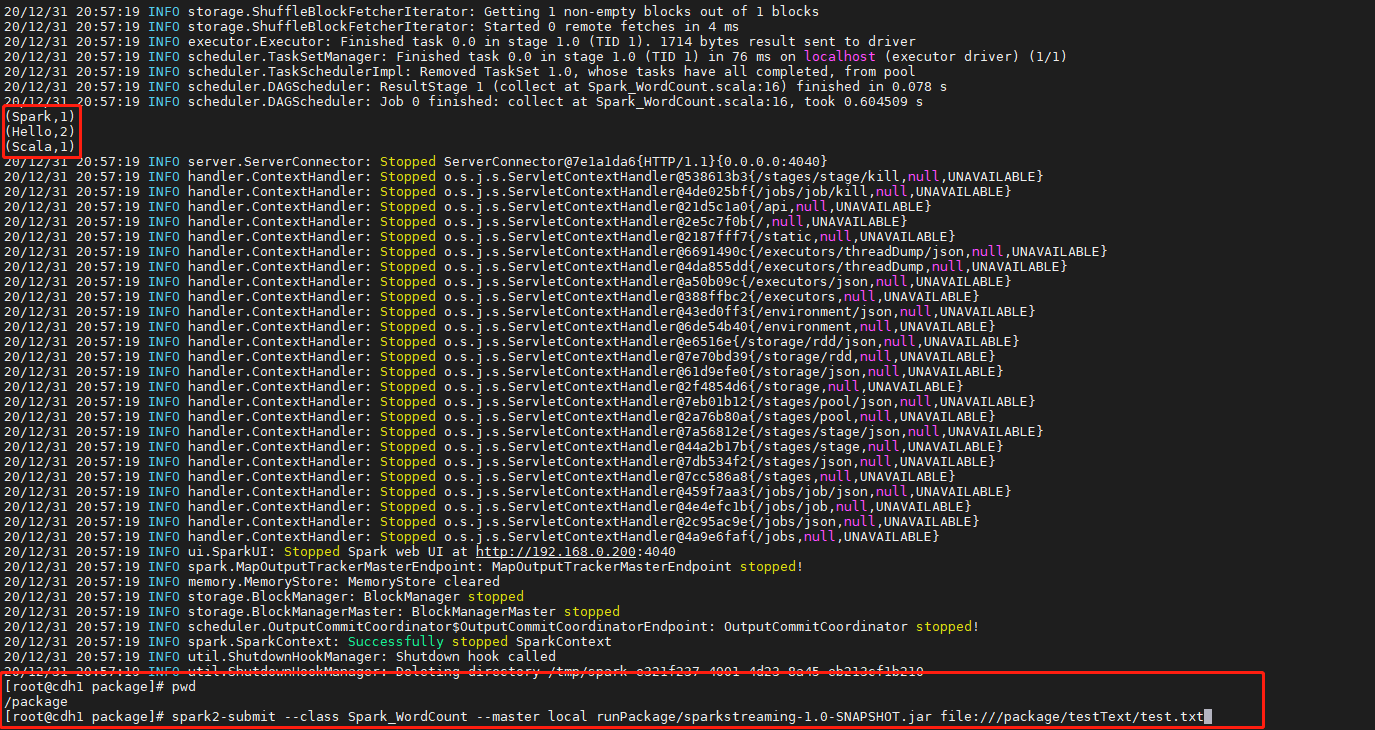
1.1、sparkwordcount运行
- 提交代码
(sparkWordCount的主类为:Spark_WordCount,jar包在/package/runPackage下。选择本地运行,运行的时候缺包每一台对应节点的指定目录都有要执行的文件)
spark2-submit --class Spark_WordCount --master local runPackage/sparkstreaming-1.0-SNAPSHOT.jar file:///package/testText/test.txt
-
1.2、非kerberos的spark拉去kafka数据向hive写数据
配置文件为/package/conf/hive_conf.properties,根据需求指定修改配置文件
kafka.brokers=cdh1.macro.com:9092,cdh2.macro.com:9092,cdh3.macro.com:9092kafka.topics=kafka2_spark2hive.table.name=kafka2_spark2_hive2kafka.group.id=testgroup
创建hive数据库kafka2_spark2_hive2
creat table kafka2_spark2_hive2(id String, name String, age String);
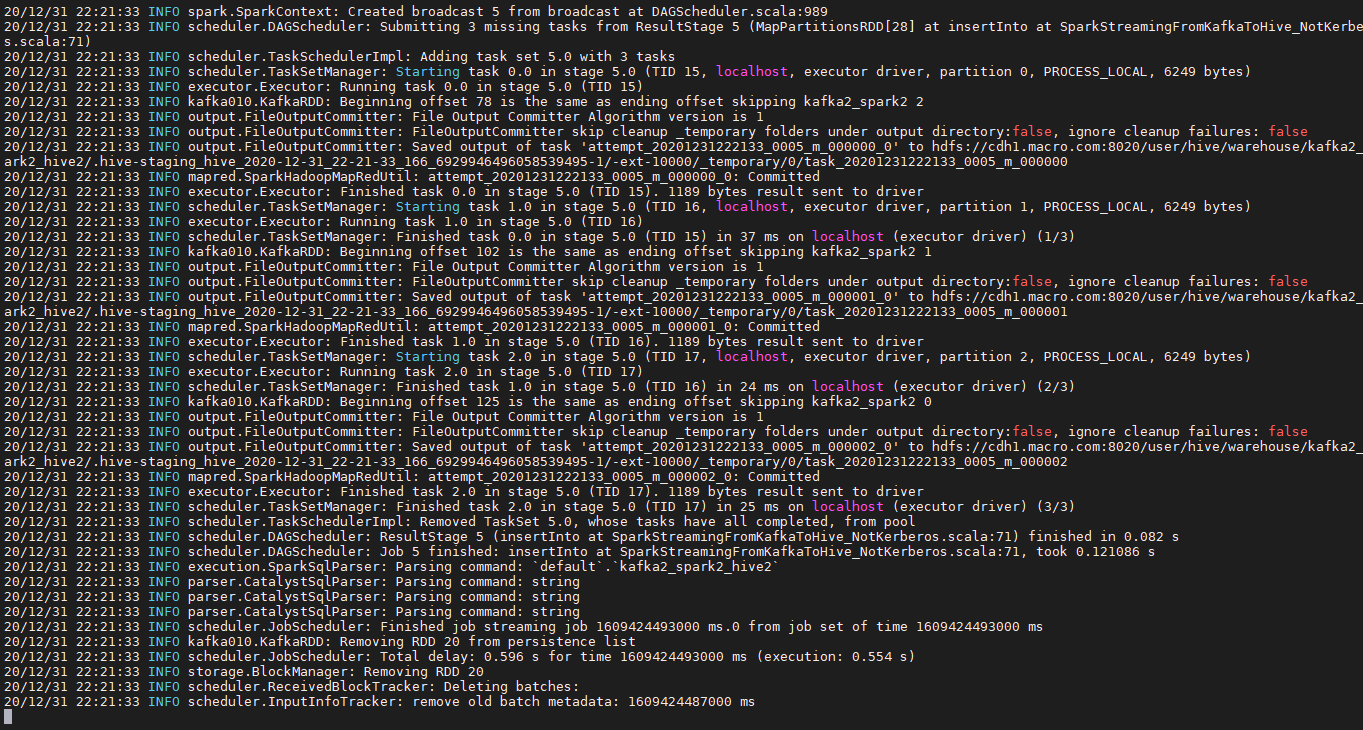
提交代码
(主类为:SparkStreamingFromKafkaToHive_NotKerberos,选择本地运行
spark2-submit --class SparkStreamingFromKafkaToHive_NotKerberos --master local runPackage/sparkstreaming-1.0-SNAPSHOT.jar
- 执行未报错,结果如下
- 模拟消费者向kafka2_spark2队列发送消息,代码如下
(/package/testText/testText/HiveAndHBaseTestText.txt文件中指定了我们需要发送的内容,运行脚本提交发送消息)
sh run_producer.sh MyProducerNotKerberos testText/HiveAndHBaseTestText.txt

- 消息成功发送,web界面查询信息结果如下
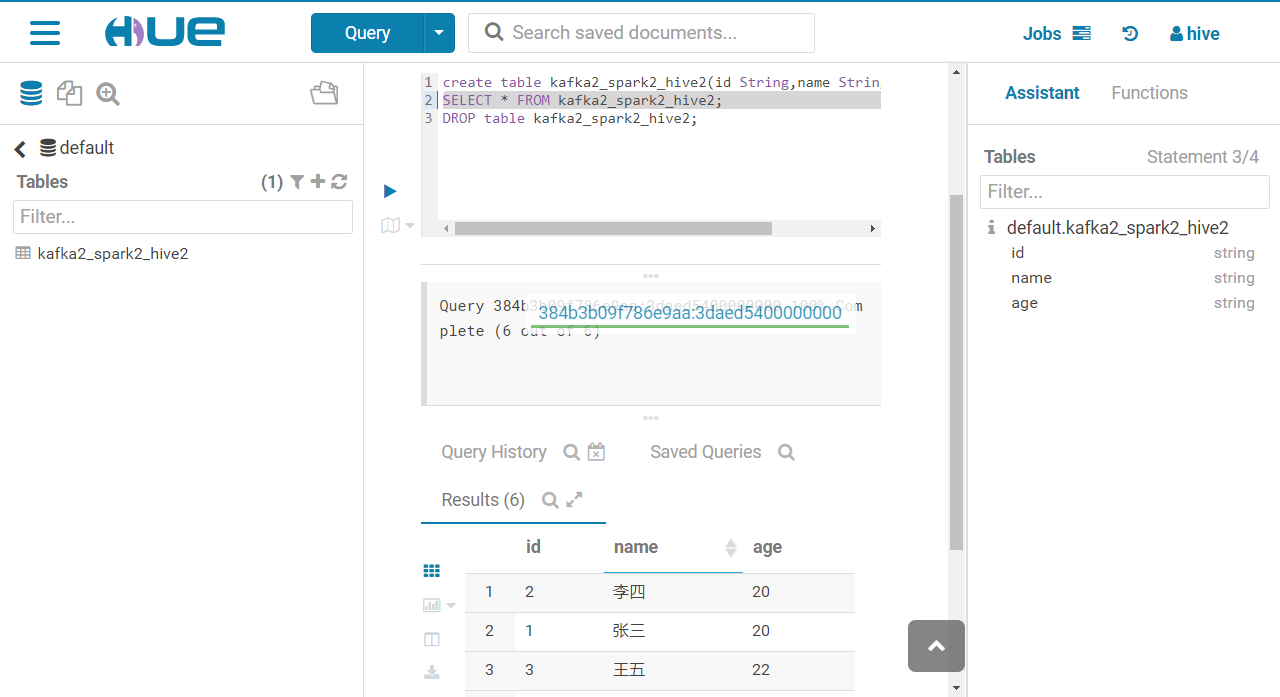
1.3、非kerberos下spark拉取kafka数据向HBase写数据
配置文件为:/package/conf/hbase_conf.properties
kafka.brokers=cdh1.macro.com:9092,cdh2.macro.com:9092,cdh3.macro.com:9092 //指定连接地址kafka.topics=kafka2_spark2 //消息队列principal.account=hive@MACRO.COM //登录用户keytab.filepath=/root/project/startKerberos/conf/hive.keytab // keytab文件zookeeper.list=192.168.0.200 //连接的zookeeper地址zookeeper.port=2181 // zookeeper端口kafka.group.id=testgroup //消费组
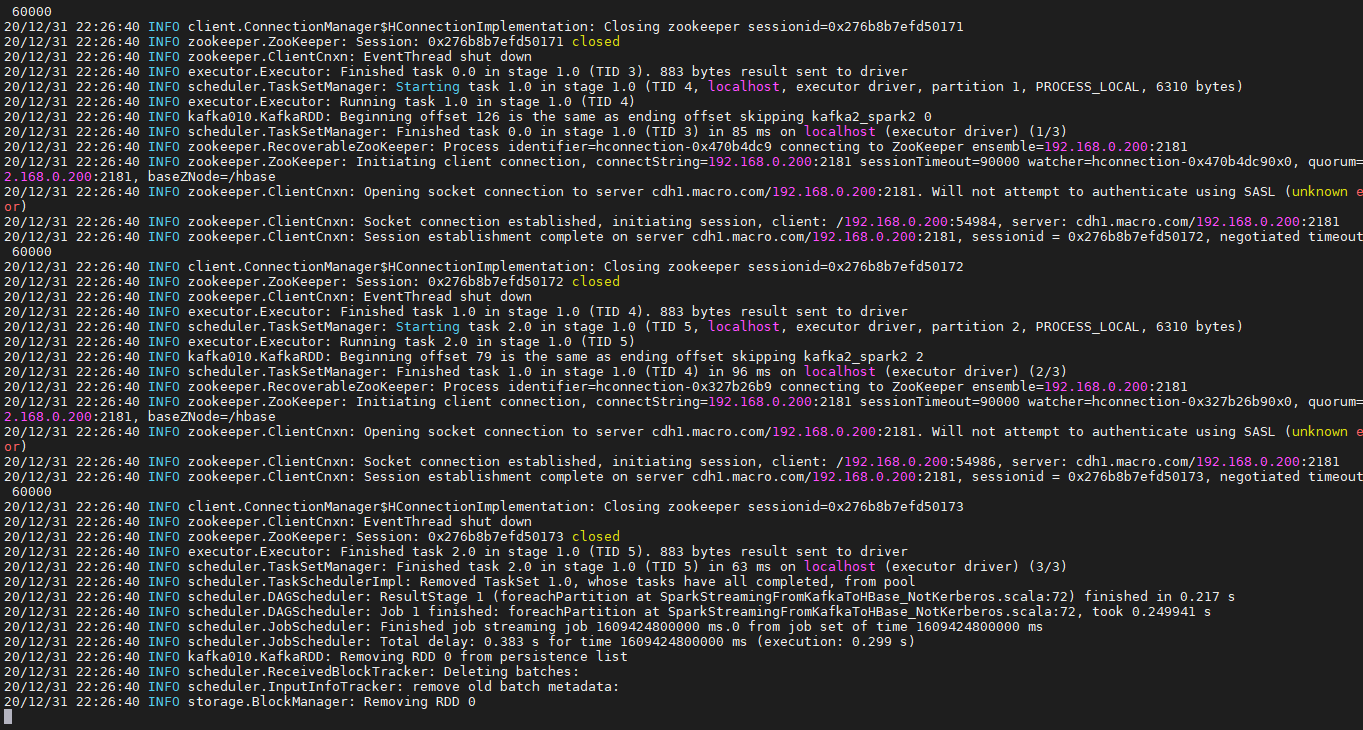
提交代码
(主类为:SparkStreamingFromKafkaToHBase_NotKerberos,选择本地运行,jar包为/package/runPackage/sparkstreaming-1.0-SNAPSHOT.jar
spark2-submit --class SparkStreamingFromKafkaToHBase_NotKerberos --master local runPackage/sparkstreaming-1.0-SNAPSHOT.jar
- 执行未报错,结图如下
运行脚本模拟消费者向kafka2_spark2队列发送消息,代码如下
sh run_producer.sh MyProducerNotKerberos testText/HiveAndHBaseTestText.txt
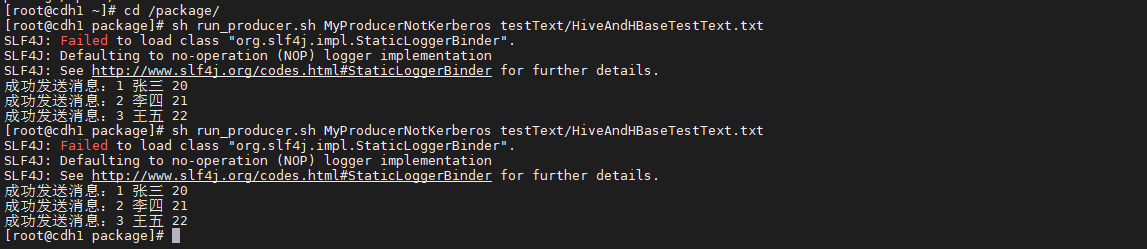
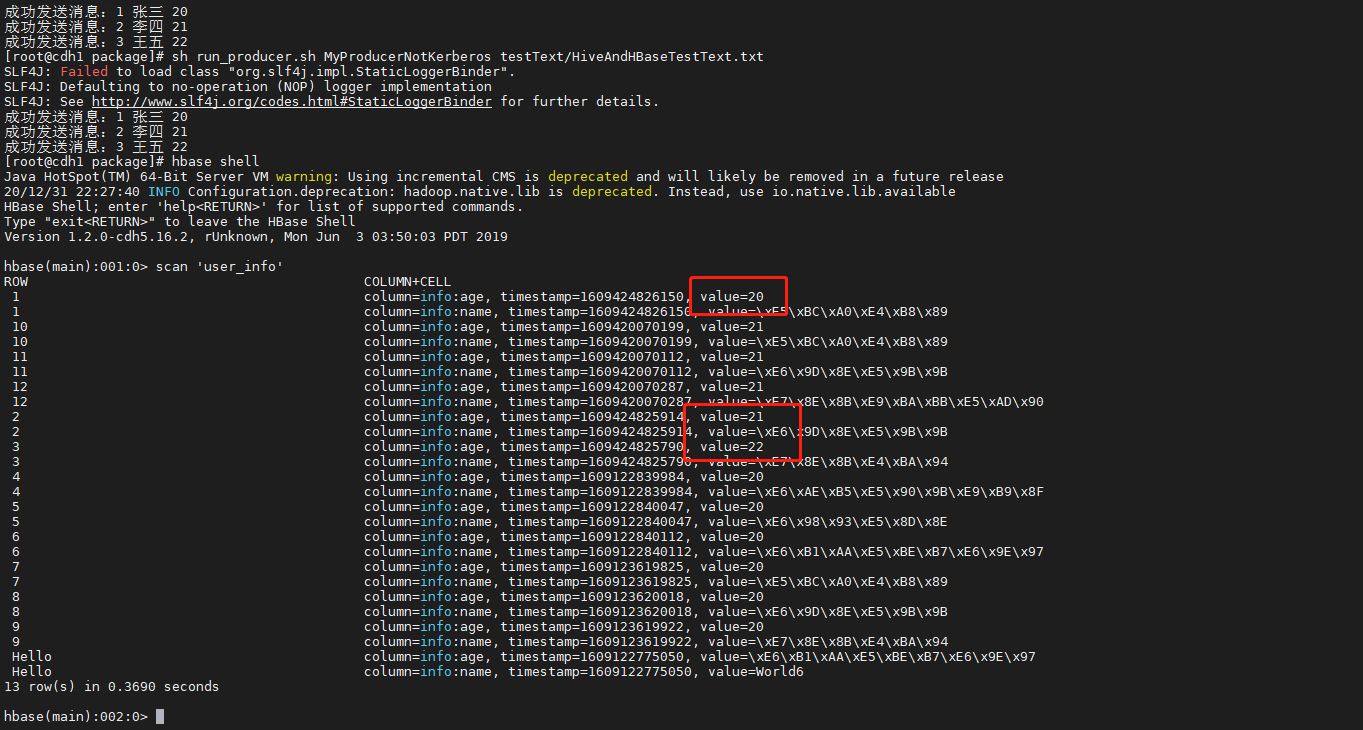
消息成功发送,查询信息结果如下
1.4、Kerberos下Spark拉取Kafka数据写入数据到hive
配置文件为/package/conf/hive_conf_Krb.properties
kafka.brokers=cdh1.macro.com:9092,cdh2.macro.com:9092,cdh3.macro.com:9092kafka.topics=kafka2_spark2group.id=testgrouphive.tableName=kafka2_spark2_hive2principal.account=hive@MACRO.COMkeytab.filepath=/package/conf/hive.keytab
提交代码
(提交时手动指定用户以及keytab文件和jaas.conf文件,所有配置文件都在/package/conf/下
spark2-submit --class SparkStreamingFromKafkaToHive_Kerberos --master local --deploy-mode client --executor-memory 1g --executor-cores 2 --driver-memory 2g --num-executors 2 --queue default --principal hive@MACRO.COM --keytab /package/conf/hive.keytab --files "/package/conf/jaas.conf" --driver-java-options "-Djava.security.auth.login.config=/package/conf/jaas.conf" --conf "spark.executor.extraJavaOptions=-Djava.security.auth.login.config=/package/conf/jaas.conf" runPackage/sparkstreaming-1.0-SNAPSHOT.jar
- 执行未报错,结果如下
- 运行kerberos下向kafka生产者向kafka2_spark2队列发送消息
(选择主类MyProducer,这个类里面指定了jaas.conf以及keytab文件等位置,直接写shell脚本进行运行)
sh run_producer.sh MyProducer testText/HiveAndHBaseTestText.txt
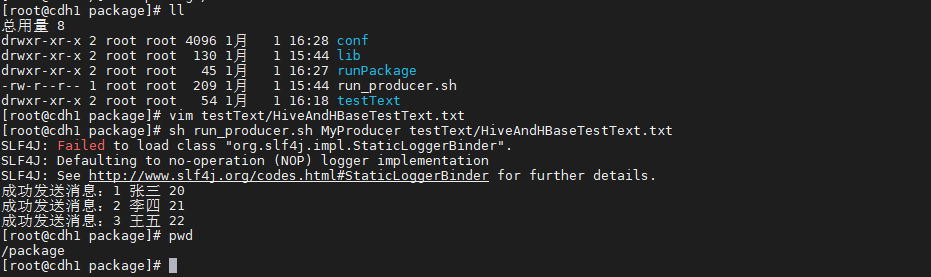
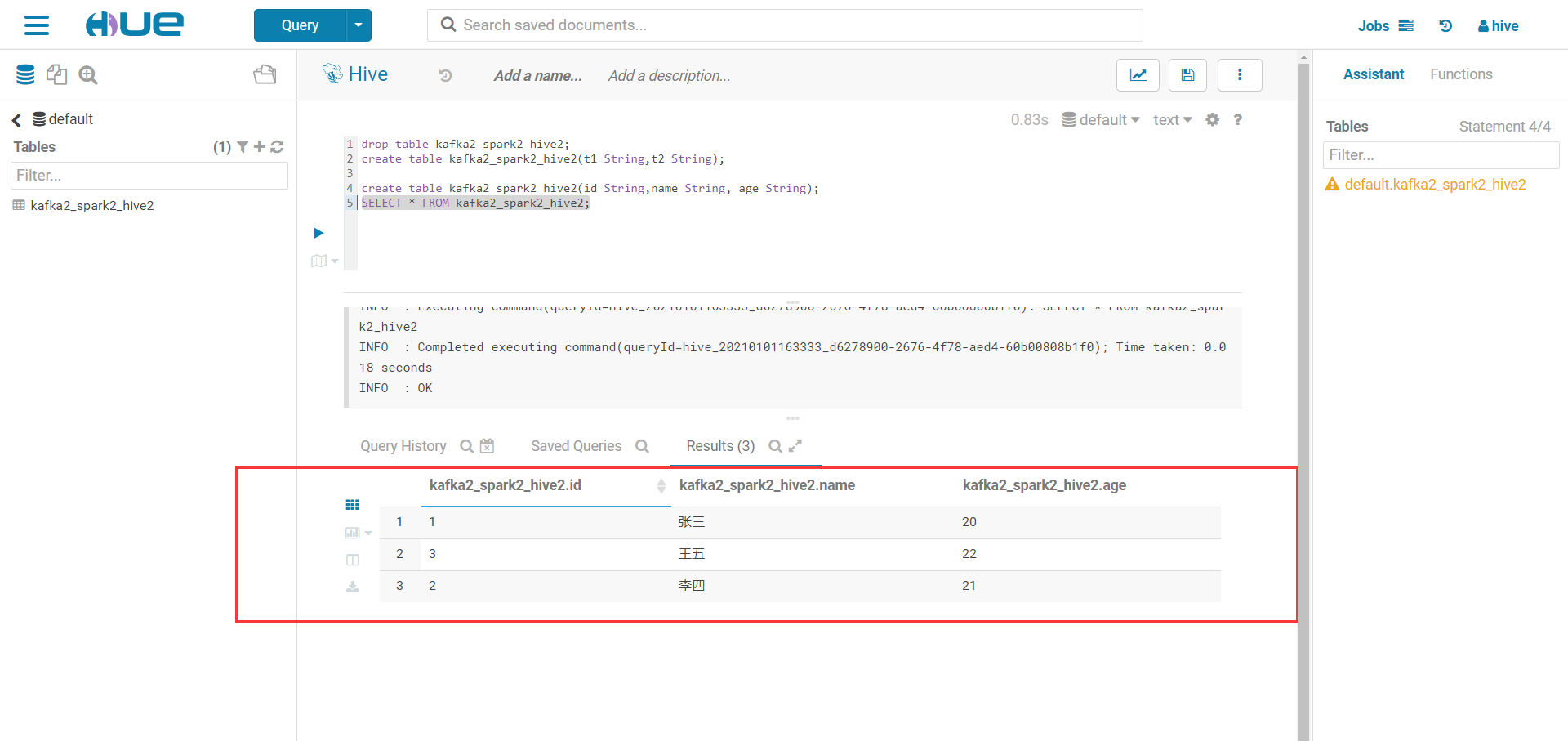
- 成功发送消息,登录客户端查询kafka2_spark2_hive2表,消息成功写入
1.5、Kerberos下Spark拉取Kafka数据写入数据到hbase
配置文件为/package/conf/hbase_conf_Krb.properties
kafka.brokers=cdh1.macro.com:9092,cdh2.macro.com:9092,cdh3.macro.com:9092kafka.topics=kafka2_spark2principal.account=hive@MACRO.COMkeytab.filepath=/package/conf/hive.keytabzookeeper.list=cdh1.macro.com,cdh2.macro.com,cdh3.macro.comzookeeper.port=2181kafka.group.id=testgroup
提交代码:
(选择手动指定jaas以及keytab文件)
spark2-submit --class SparkStreamingFromKafkaToHBase_Kerberos --master local[*] --deploy-mode client --executor-memory 1g --executor-cores 1 --driver-memory 1g --num-executors 1 --queue default --principal hive@MACRO.COM --keytab /package/conf/hive.keytab --files "/package/conf/jaas.conf" --driver-java-options "-Djava.security.auth.login.config=/package/conf/jaas.conf" --conf "spark.executor.extraJavaOptions=-Djava.security.auth.login.config=/package/conf/jaas.conf" runPackage/sparkstreaming-1.0-SNAPSHOT.jar
执行结果:
- 运行kerberos下向kafka生产者向kafka2_spark2队列发送消息

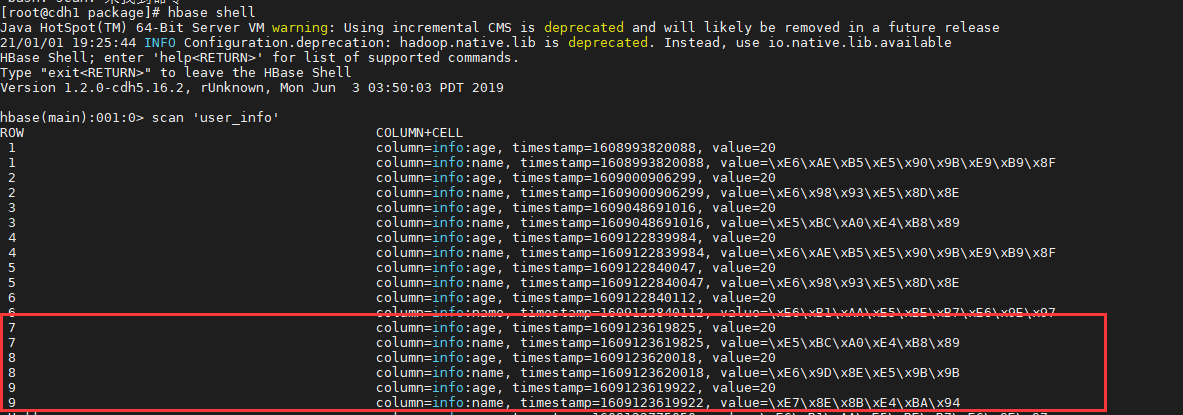
- 查询hbase的表,消息成功写入,结果如下:
2、问题及解决方法
- 运行jar包提示找不到部分类
原因:因为打jar包的时候没有把依赖包打进去
解决方案:把构建项目所需要的jar包拷贝到/opt/cloudera/parcels/SPARK2/lib/spark2/jars目录下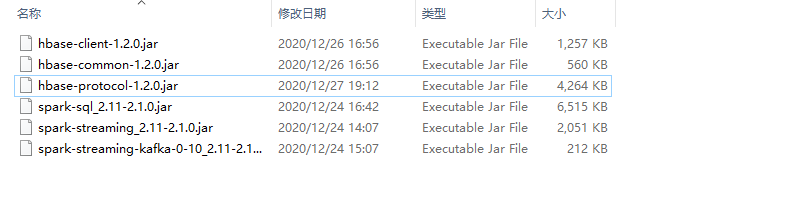
注意:所有节点都要拷贝
- 提示kafka客户带版本过低截图如下:
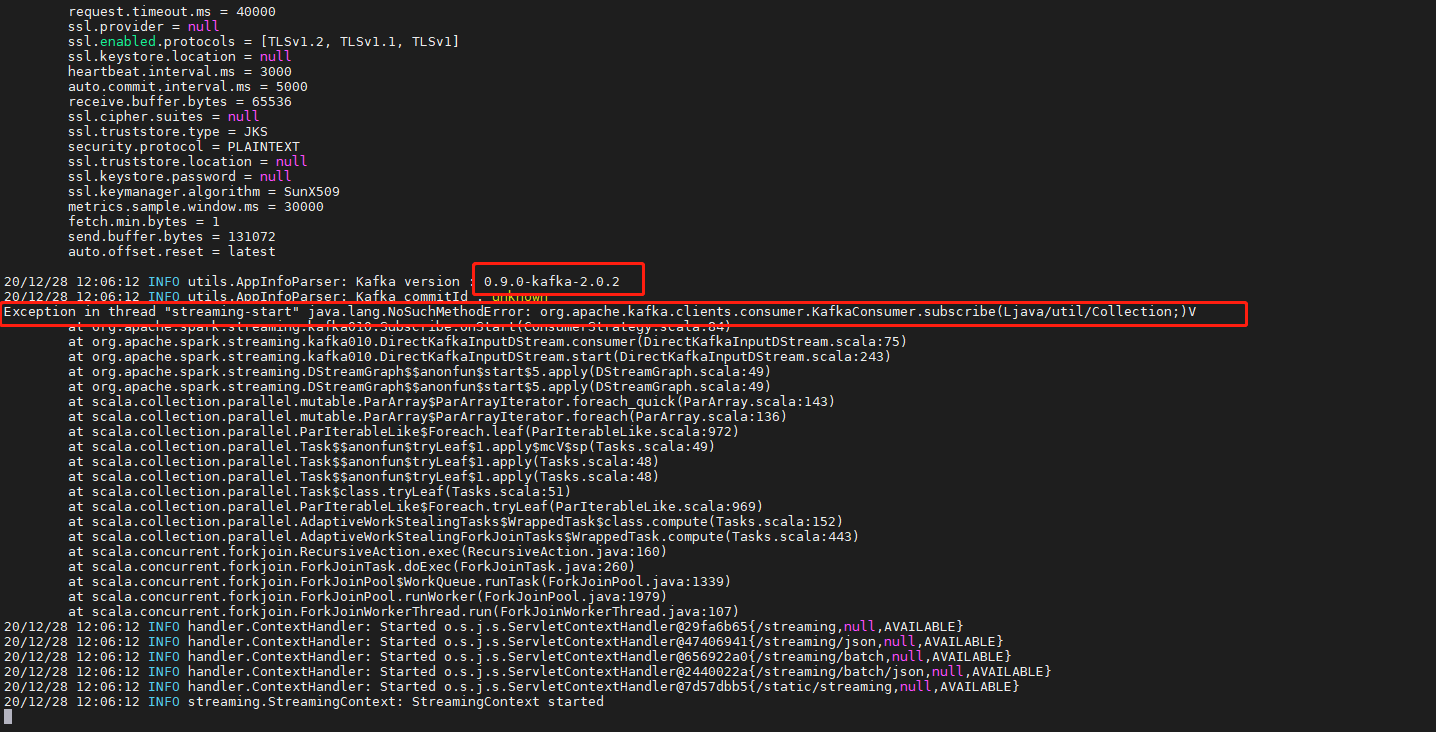
解决方案:登录CM进入SPARK2服务的配置项将spark_kafka_version的kafka版本修改为0.10。重启spark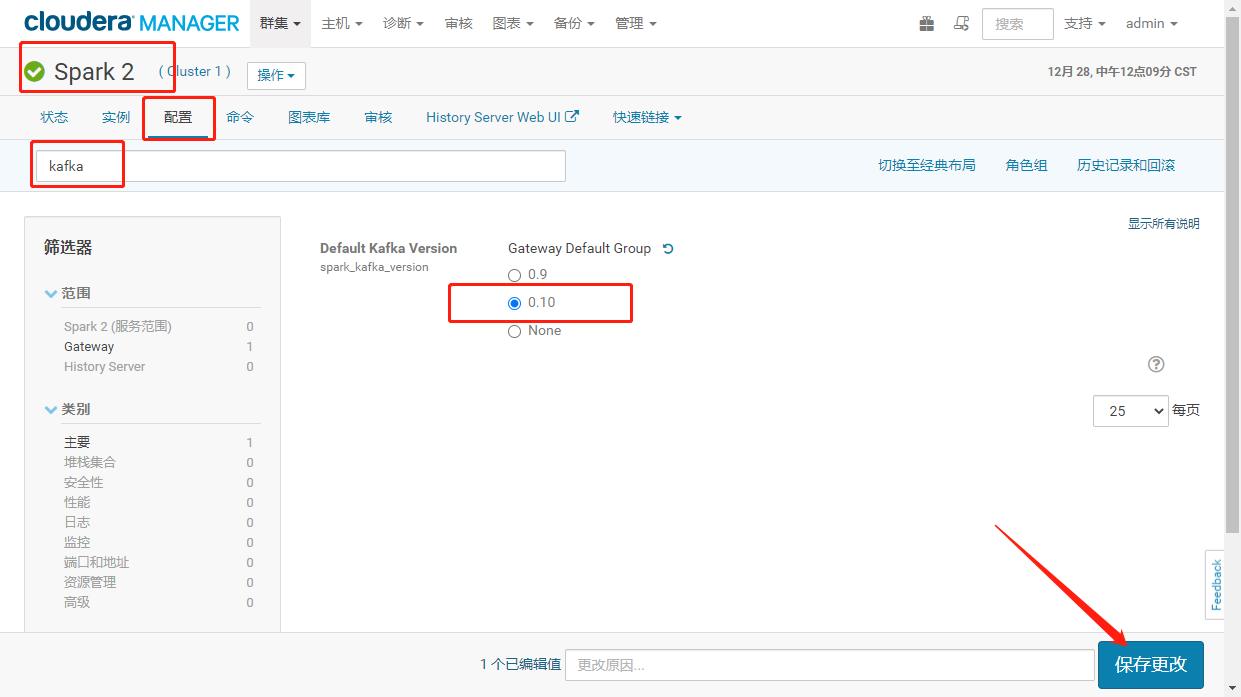
- 提示NoClassDefFoundError: org/apache/htrace/Trace
- 对于用maven构建hadoop开发项目的时候,在加入了hadoop的依赖项之后,会出现无法更新htrace-core的现象,所以要自己单独拷贝htrace-core的jar包到/opt/cloudera/parcels/SPARK2/lib/spark2/jars目录下

解决方案:拷贝如下htrace-core的jar包到每一个节点。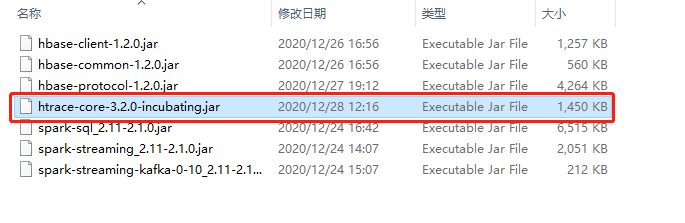
- 开发工程中在DIEA运行时,提示找不到视图或表
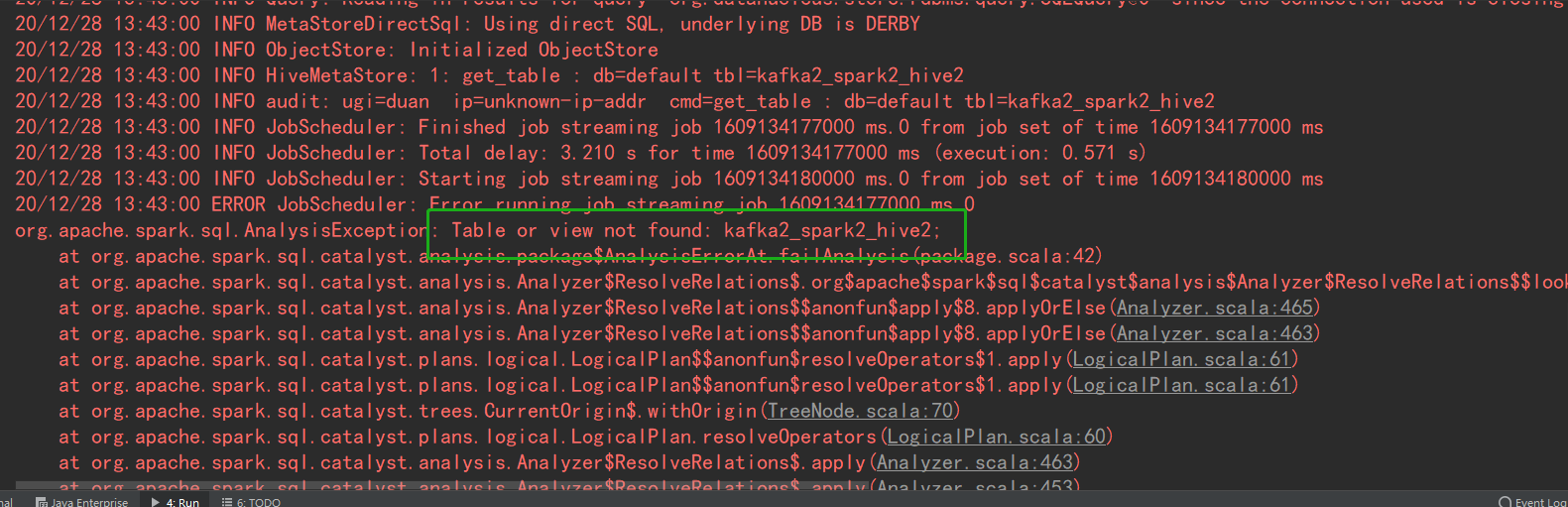
解决方案:
在hadoop环境中拷贝hive-site.xml文件到项目中的resource文件夹下(find / -name hive-site.xml 搜索)

- WinDow下IDEA环境运行提示实例化错误,截图如下:
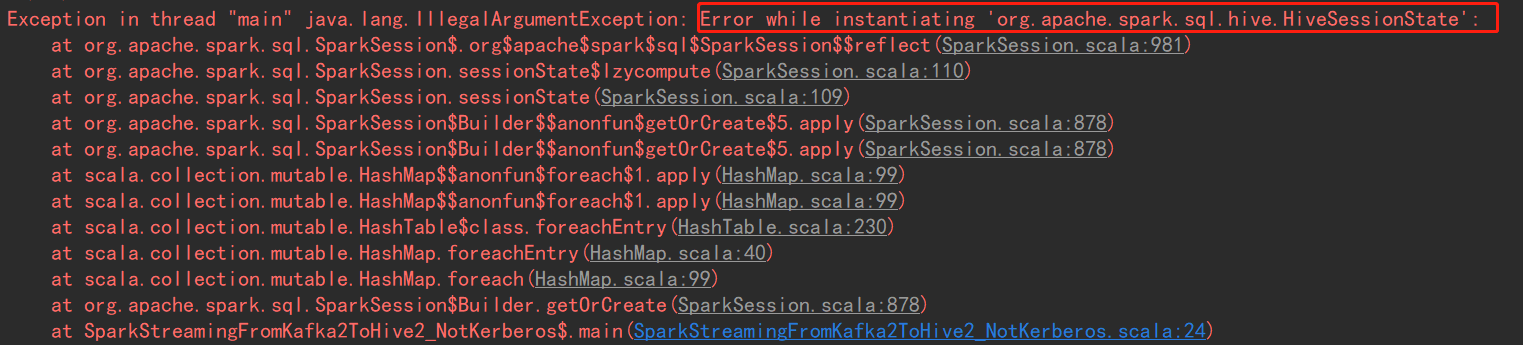
原因:window下需要安装hadoop环境
解决:
1、下载集群对应linux的hadoop版本 <—超链接
2、下载对应的window下的hadoop需要的bin目录 <—超链接
3、解压Linux,把bin目录替换为winutils的bin目录
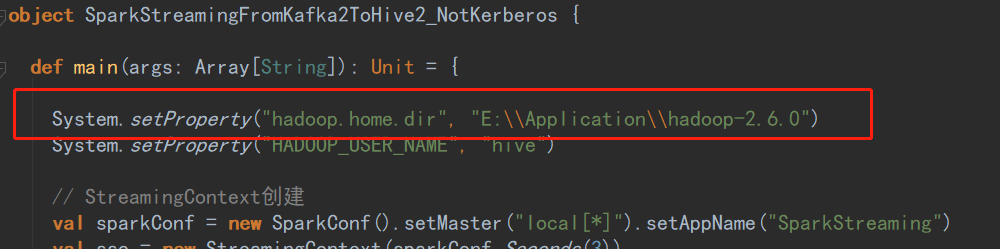
4、在代码中引用这个地址
System.setProperty("hadoop.home.dir", "E:\\Application\\hadoop-2.6.0")
- java.lang.IllegalArgumentException: Missing application resource 找不到资源

原因:如果jar没有设置CLASSPATH环境变量是可以直接指定文件路径的,如果设置了,需要加—jars指定路径

若有收获,就点个赞吧
0 人点赞
