一、前置准备
1. 创建MySQL的学生信息表并导入数据
create database test character set utf8;use test;create table student (id int(6),name varchar(30),sex char(3),age Int(3));insert into student values(000001,'张三','男',18);insert into student values(000002,'李四','男',20);insert into student values(000003,'王五','女',20);select * from student;
2. 数据表赋权限
GRANT ALL on maxwell.* to 'maxwell'@'%' identified by '123456';GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE on *.* to 'maxwell'@'%';FLUSH PRIVILEGES;
3. 通过impala创建kudu表
CREATE TABLE student (id BIGINT,age INT,name STRING,sex STRING,PRIMARY KEY (id, age))PARTITION BY HASH (id) PARTITIONS 4,RANGE (age)(PARTITION VALUES < 20,PARTITION 20 <= VALUES < 30,PARTITION 30 <= VALUES < 50,PARTITION 50 <= VALUES) STORED AS KUDUTBLPROPERTIES("kudu.master_addresses" = "cdh1.macro.com:7051");
二、构建管道
1. 创建JDBC Query Consumer
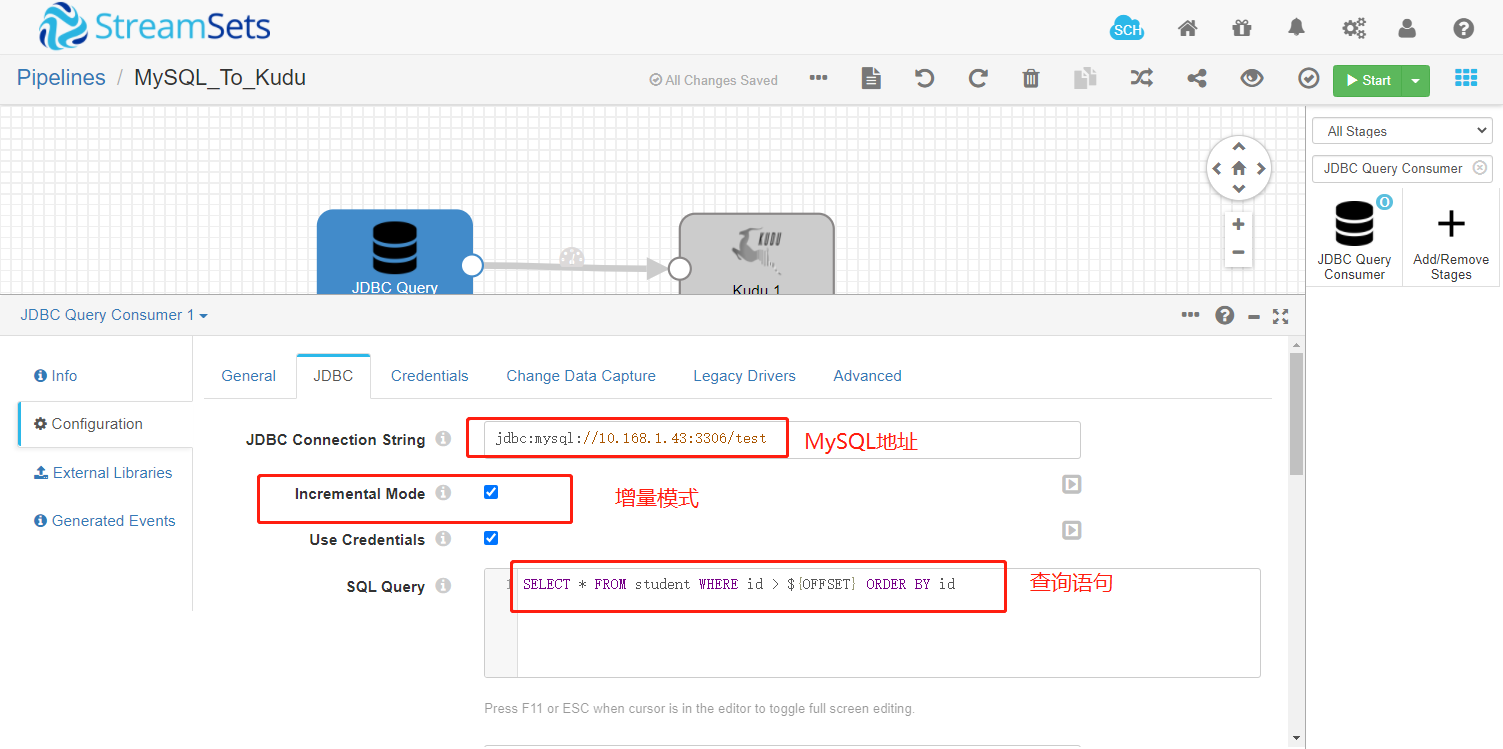
1.1 修改配置


2. 创建Kudu输出端
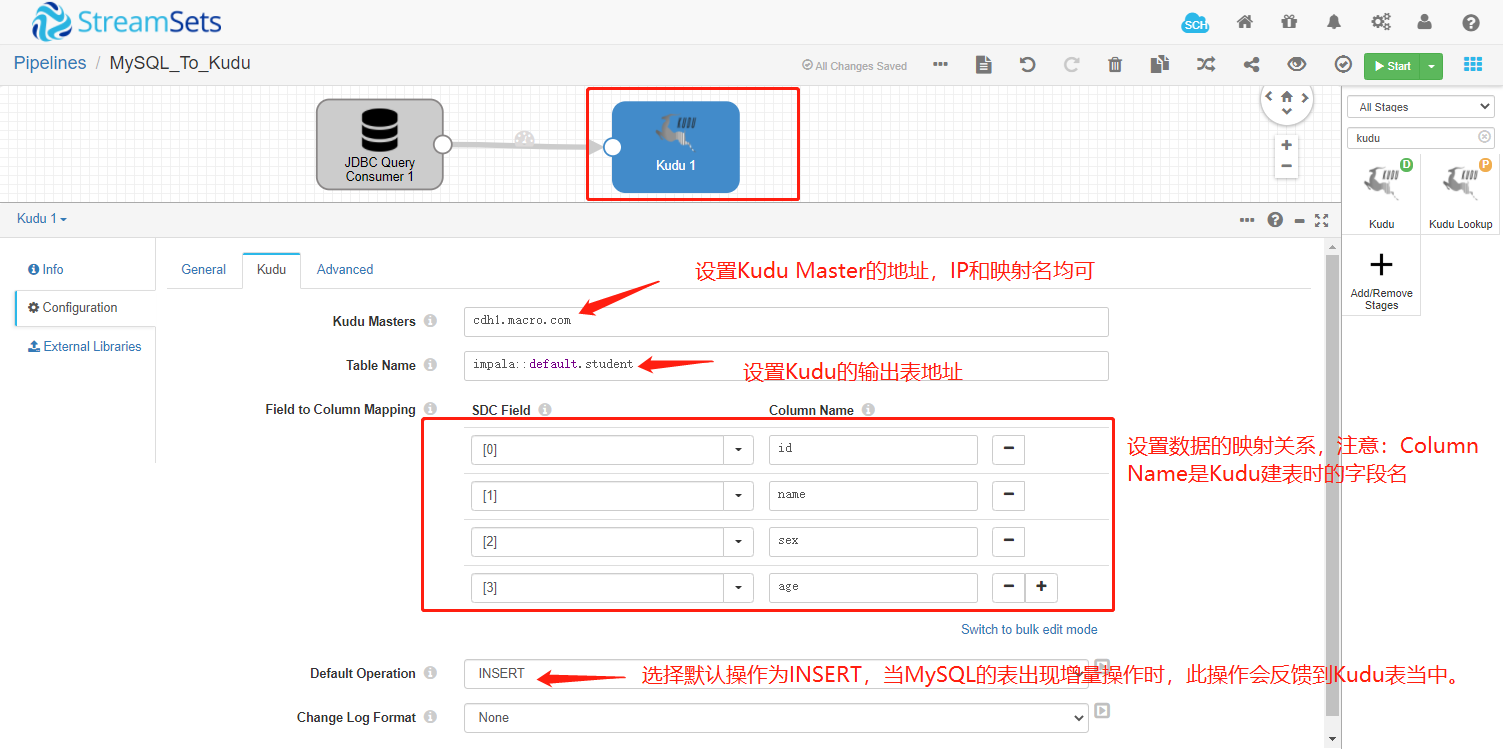
2.1 修改配置
3. 成功连接到数据源后运行程序
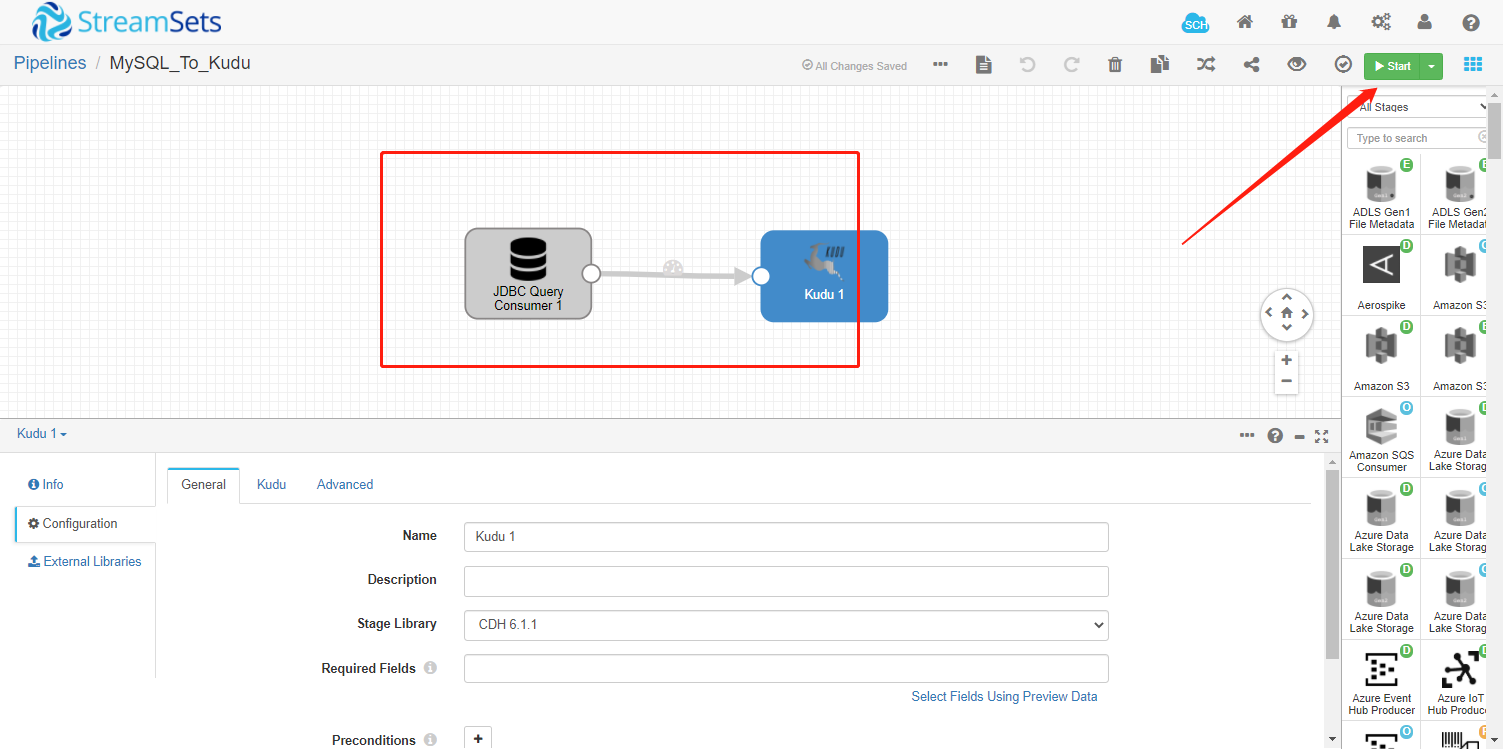
**
三、测试
1. insert
1.1 登录MySQL,插入数据,观察StreamSets实时情况

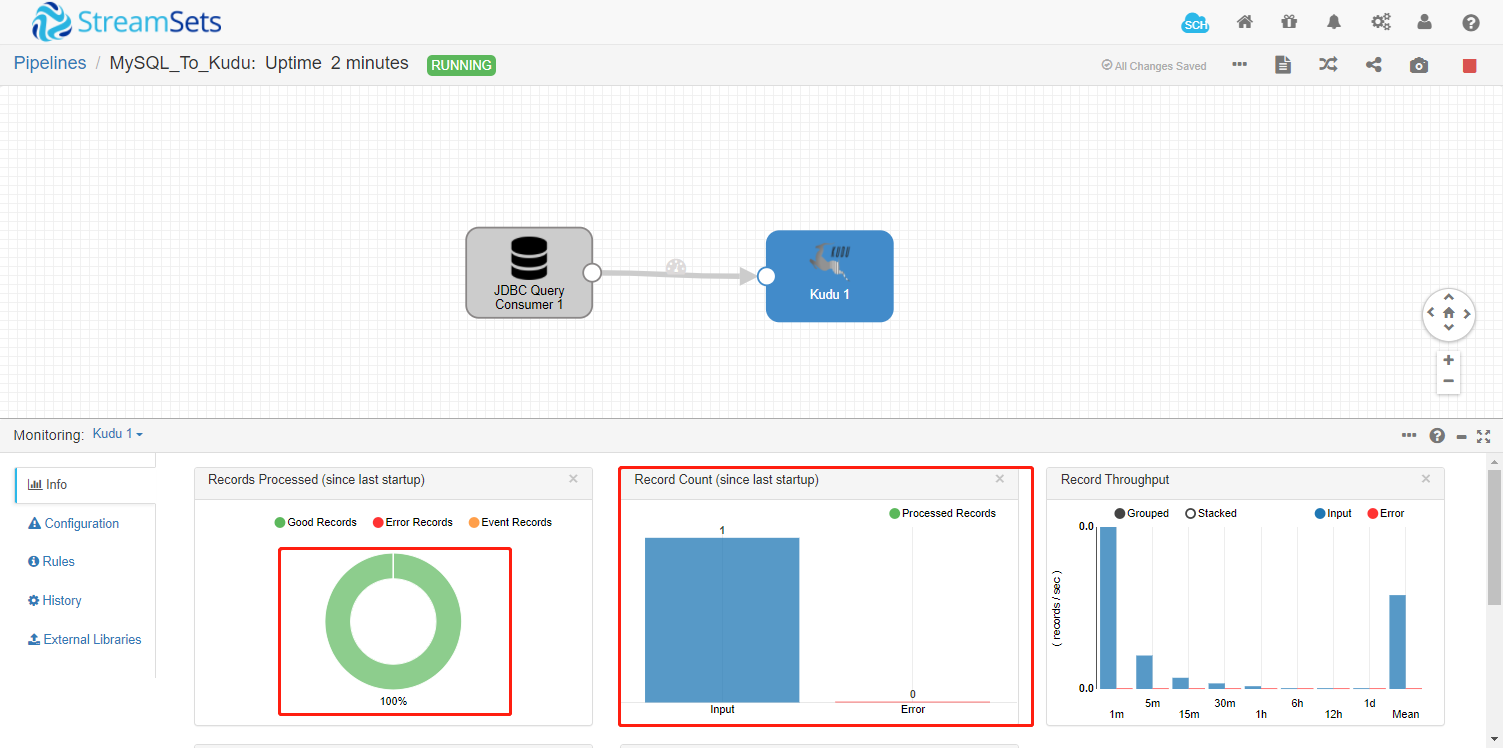
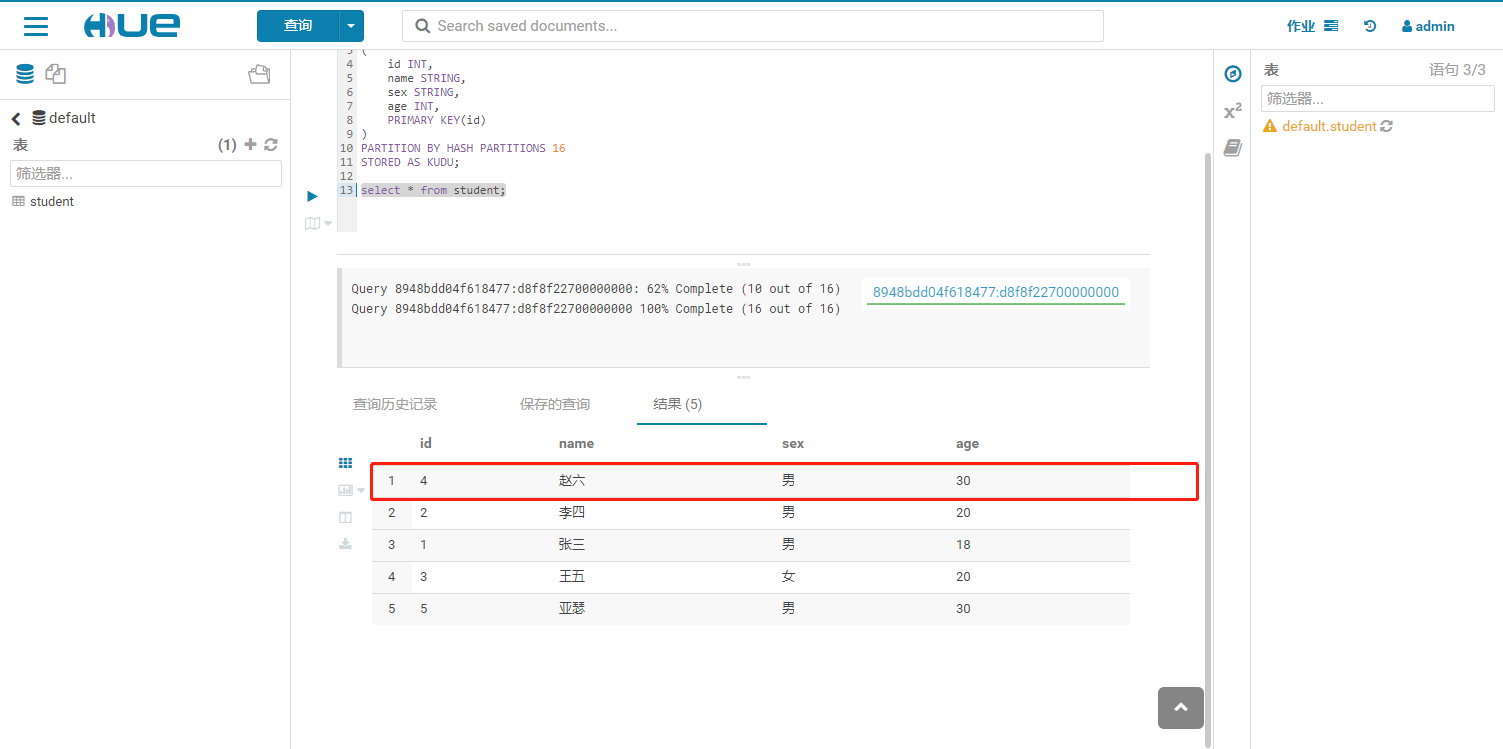
1.2 查询kudu表是否成功写入
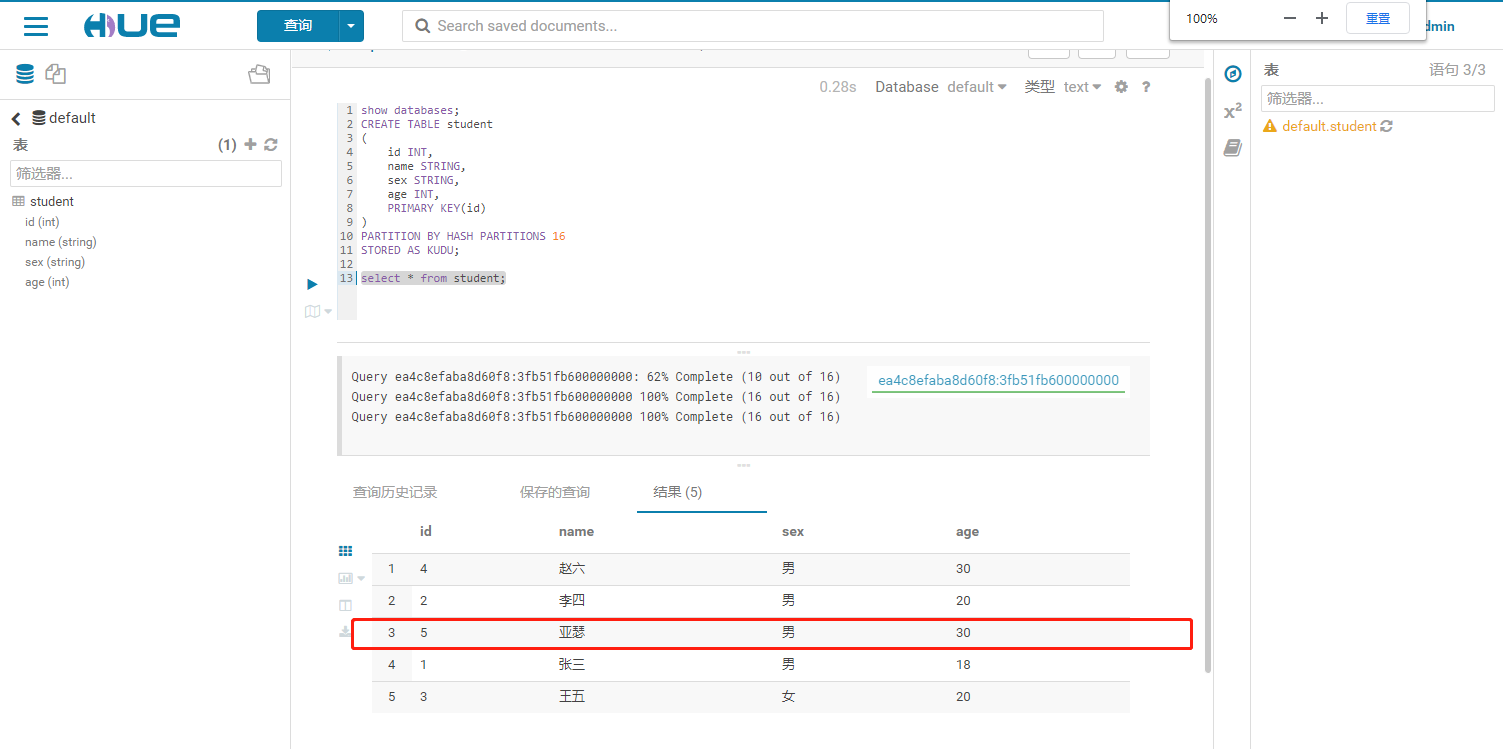
2. delete
2.1 删除一条MySQL数据
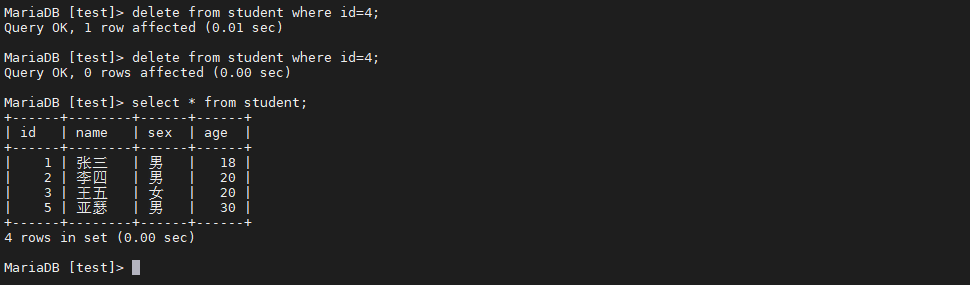
2.2 StreamSets实时状态信息并未改变
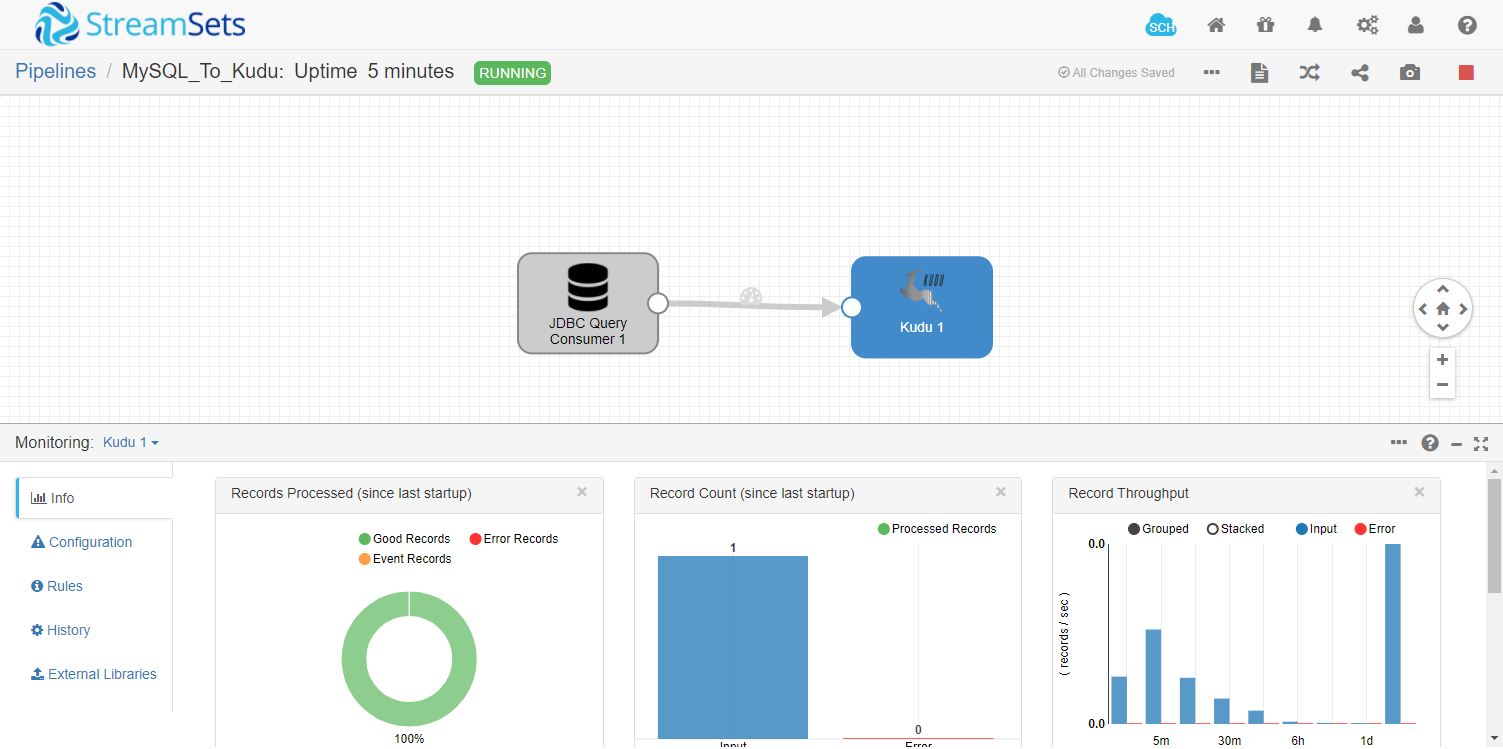 2.3 查看kudu表发现数据还在,增量操作完成
2.3 查看kudu表发现数据还在,增量操作完成
四、总结:
1. 问题1:找不到JDBC
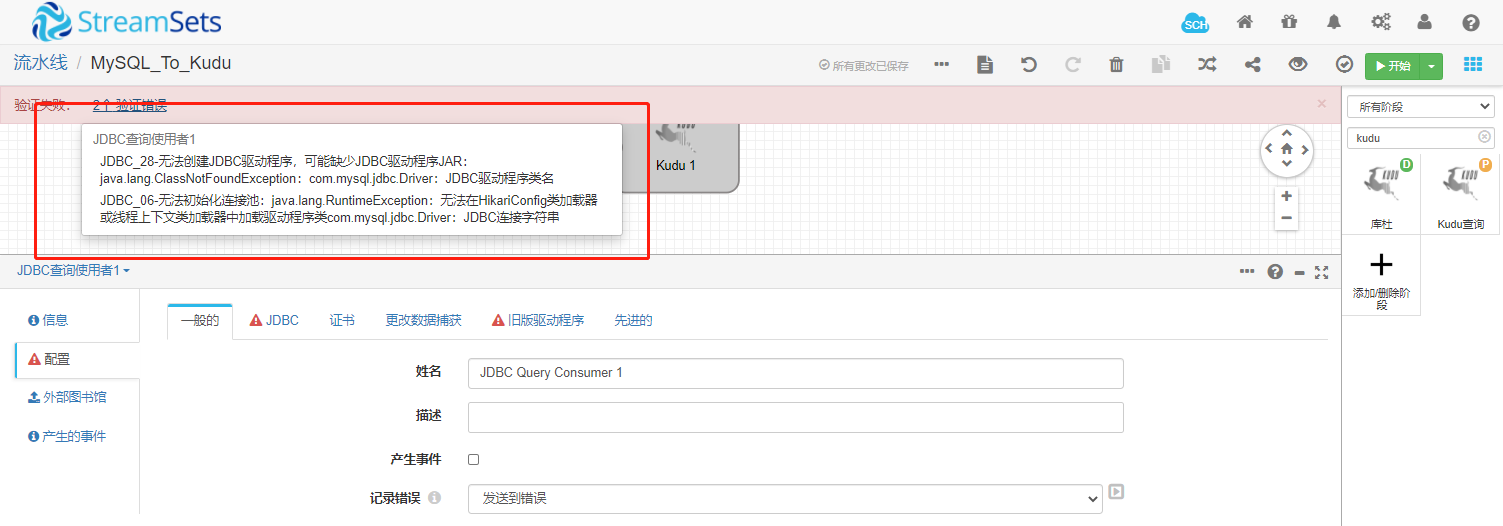
1.1 解决步骤:
新建文件夹/opt/cloudera/parcels/STREAMSETS_DATACOLLECTOR-3.14.0/sdc-extras,并赋予给用户sdc。
mkdir /opt/cloudera/parcels/STREAMSETS_DATACOLLECTOR-3.14.0/sdc-extraschown sdc:sdc /opt/cloudera/parcels/STREAMSETS_DATACOLLECTOR-3.14.0/sdc-extras
在CM中配置StreamSets包的路径
export STREAMSETS_LIBRARIES_EXTRA_DIR="/opt/cloudera/parcels/STREAMSETS_DATACOLLECTOR/sdc-extras/"
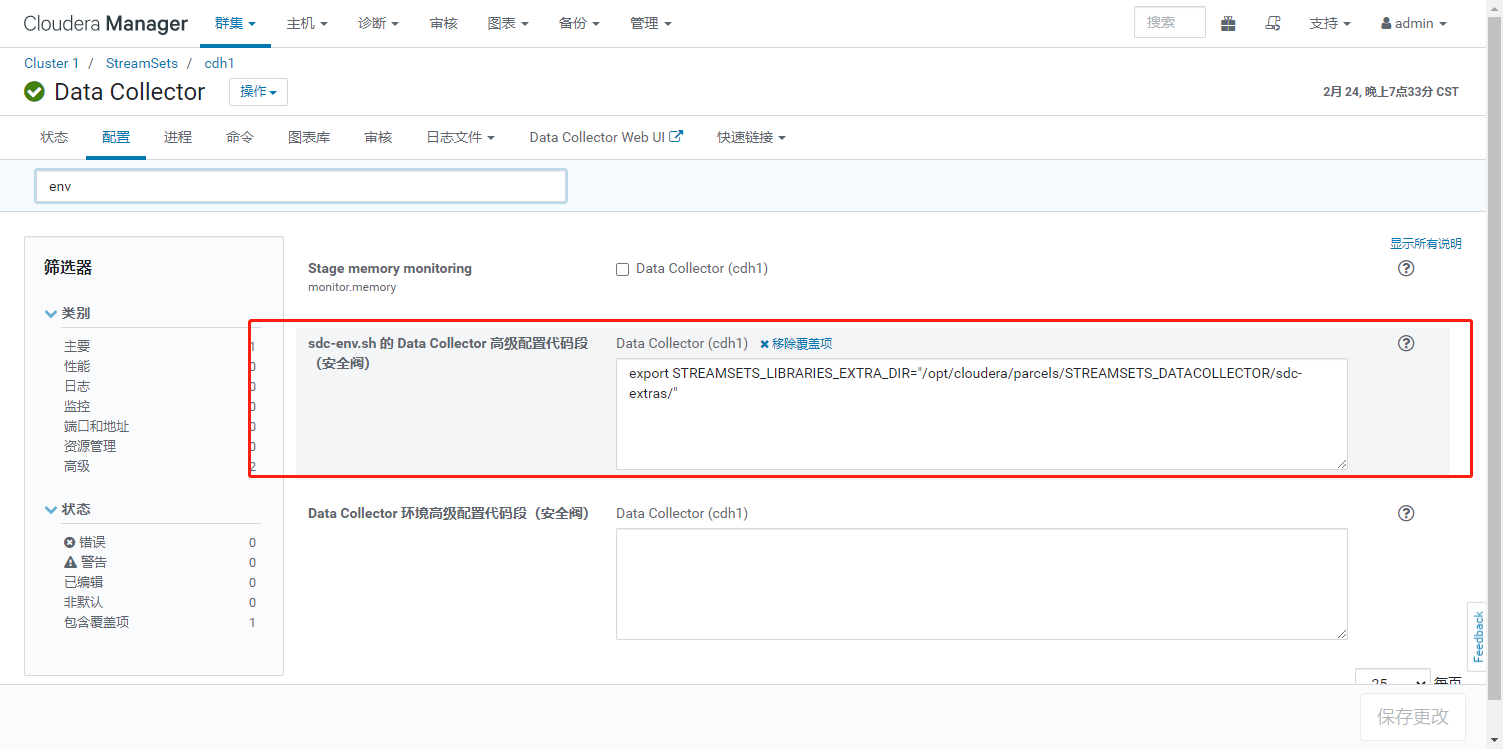
重启集群后在web界面添加jdbc
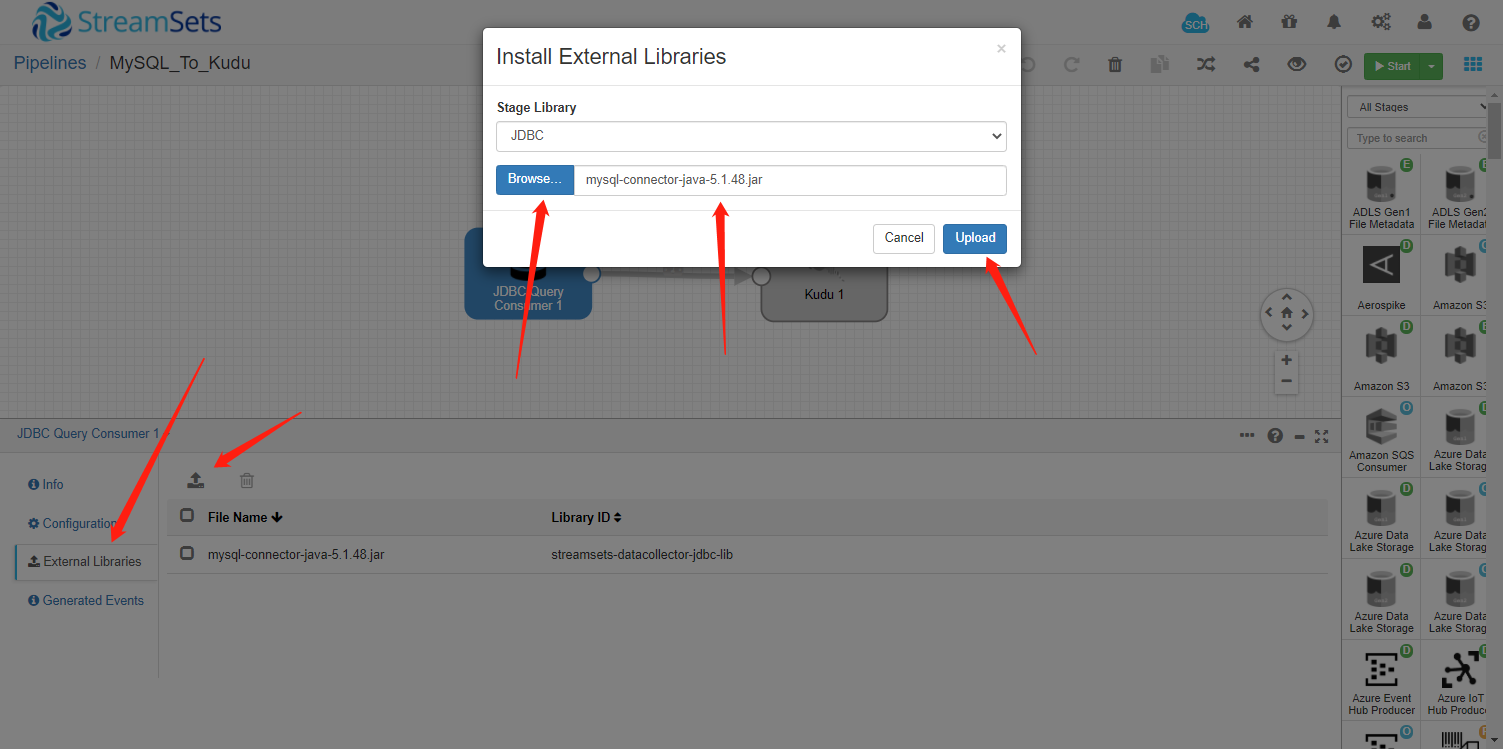
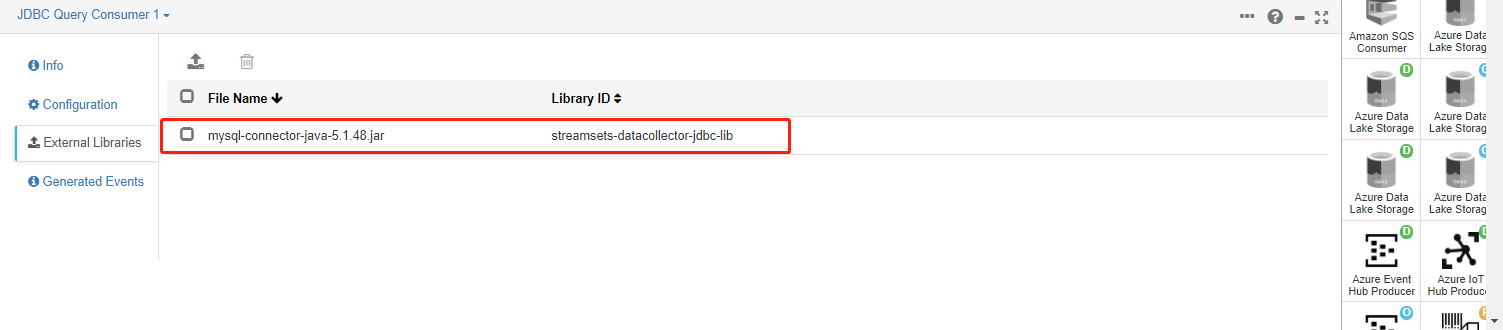
- 添加jdbc后可能集群进程会意外退出,需要再次重启集群。

若有收获,就点个赞吧
0 人点赞
