国电电力数据同步传输管控平台
(HiveToHive流程部署)
目录
一、源端 2
1、结构展示 3
1.1 外层 3
1.2 内层 3
2、Processor 3
2.1 ExecuteGroovyScript(1) 3
2.2 SelectHiveQL(1) 5
2.3 ExecuteGroovyScript(2) 6
2.4 SelectHiveQL(2) 8
2.5 HiveConnectionPool、Hive_1_1ConnectionPool 9
二、目标端 10
1、结构展示 10
1.1 外层 10
1.2 内层 11
2、Processor 11
2.1 NiFi Flow 11
2.2 PutHiveStreaming 12
三、附页 14
附1: 14
附2: 15
附3: 17
一、源端
1、结构展示
1.1 外层

1.2 内层
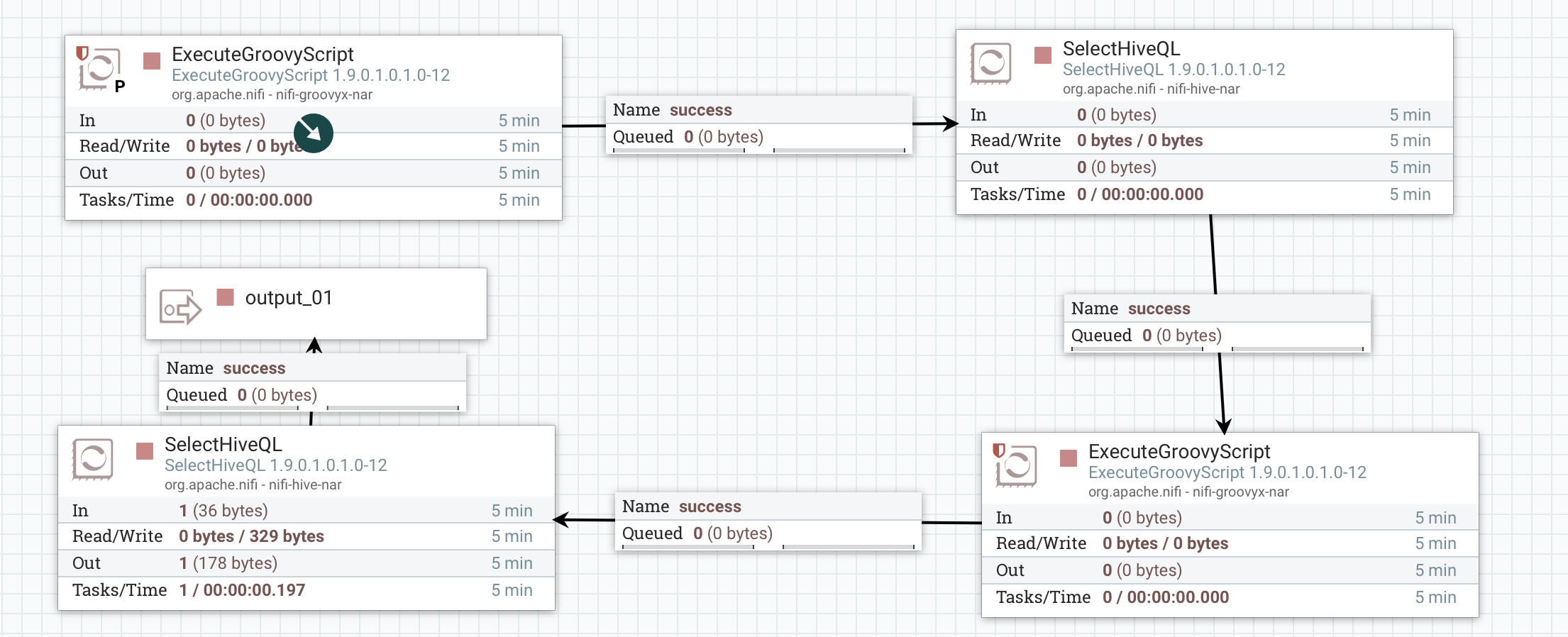
2、Processor
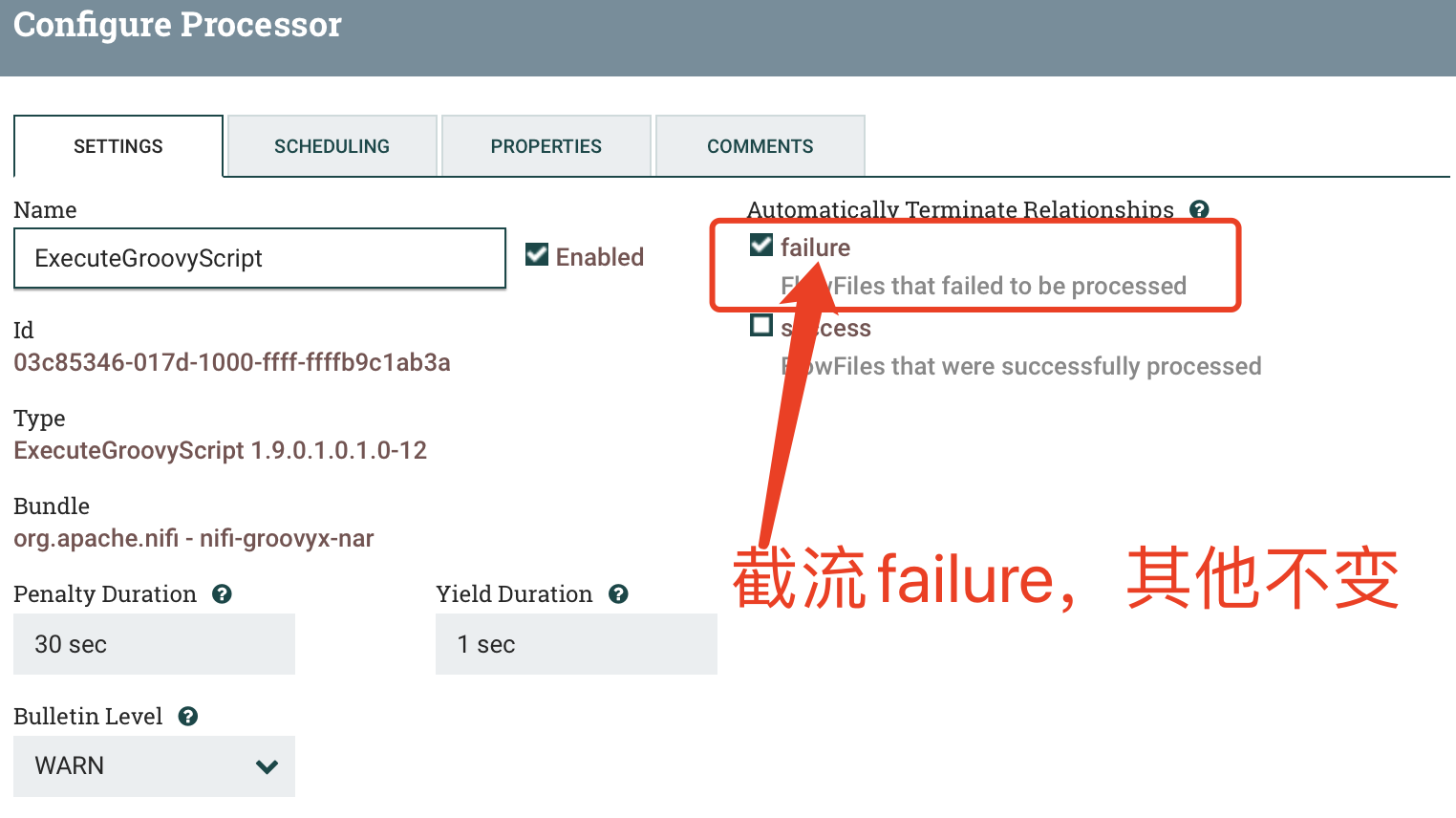
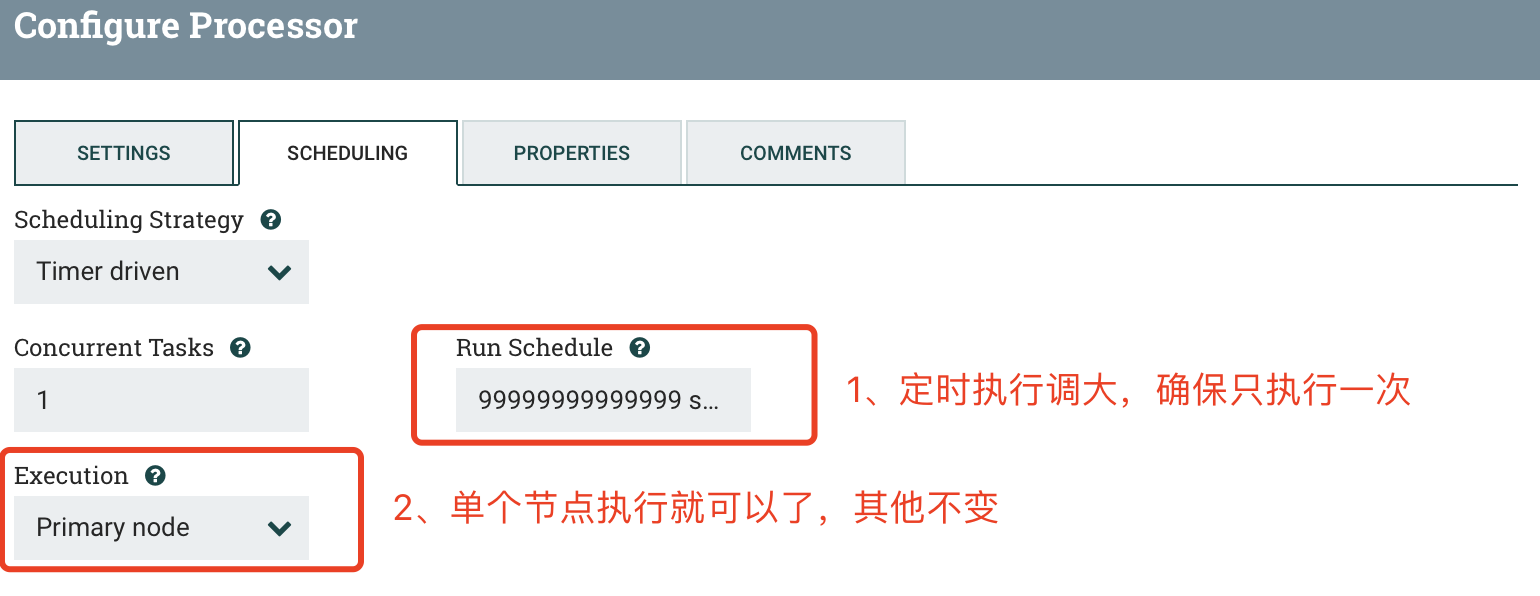
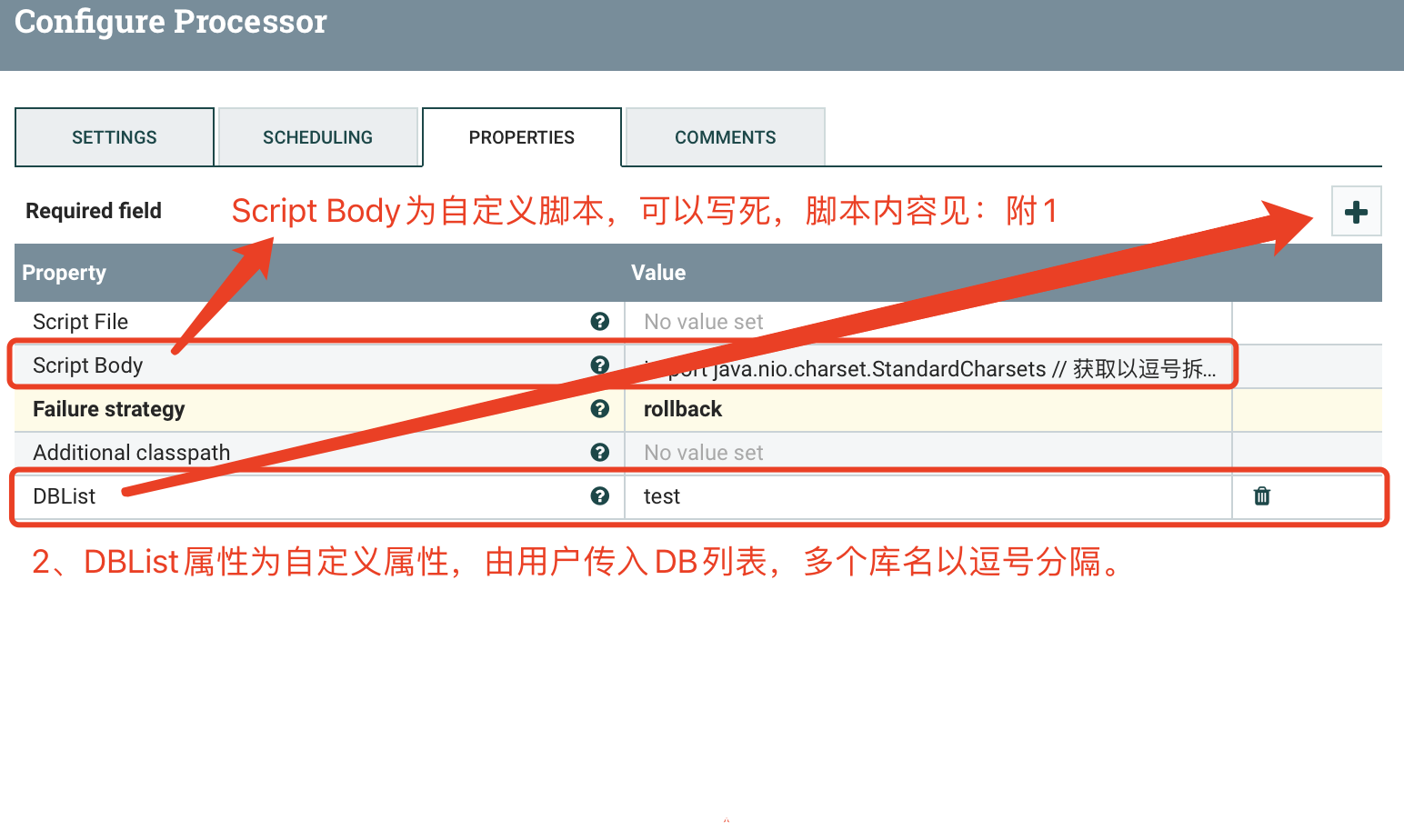
2.1 ExecuteGroovyScript(1)
a) SETTINGS
b) SCHEDULING
c) PROPERTIES
2.2 SelectHiveQL(1)
a) SETTINGS
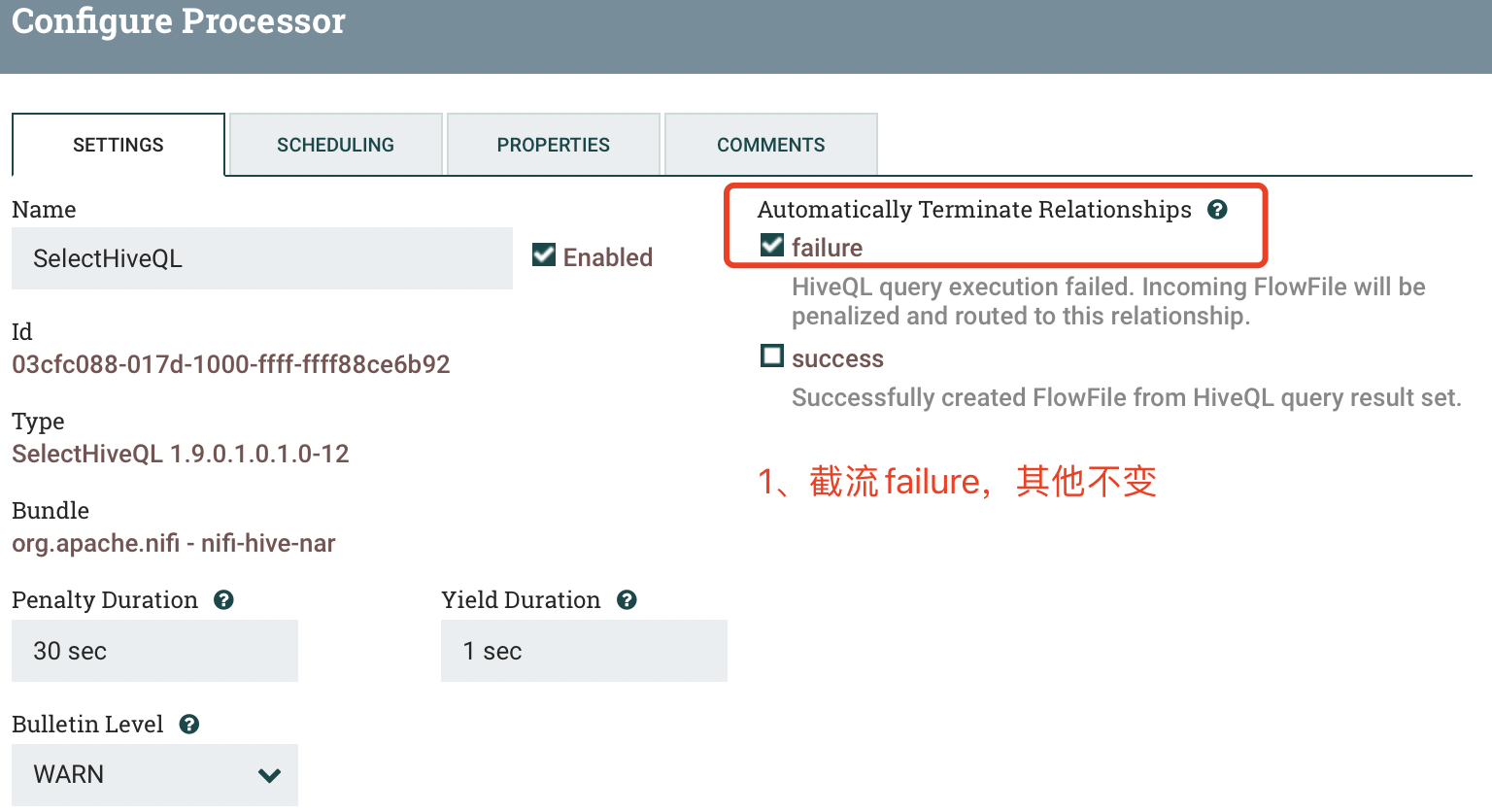
b) SCHEDULING
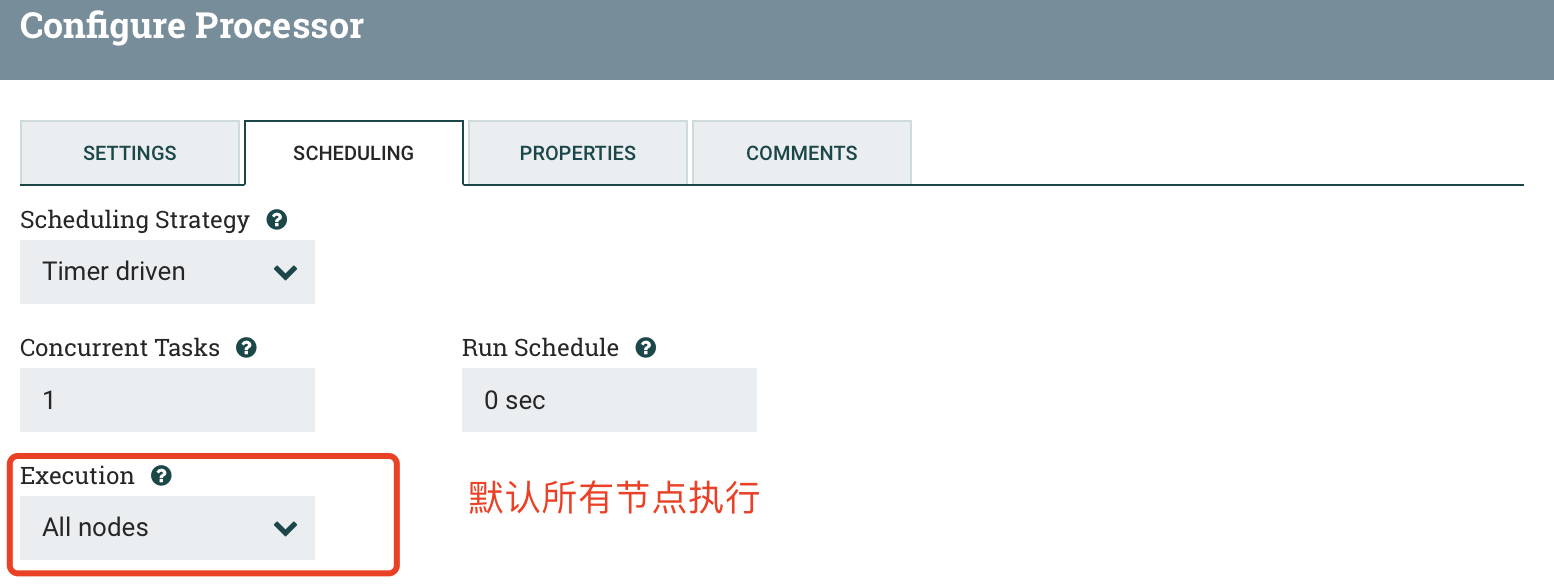
c) PROPERTIES
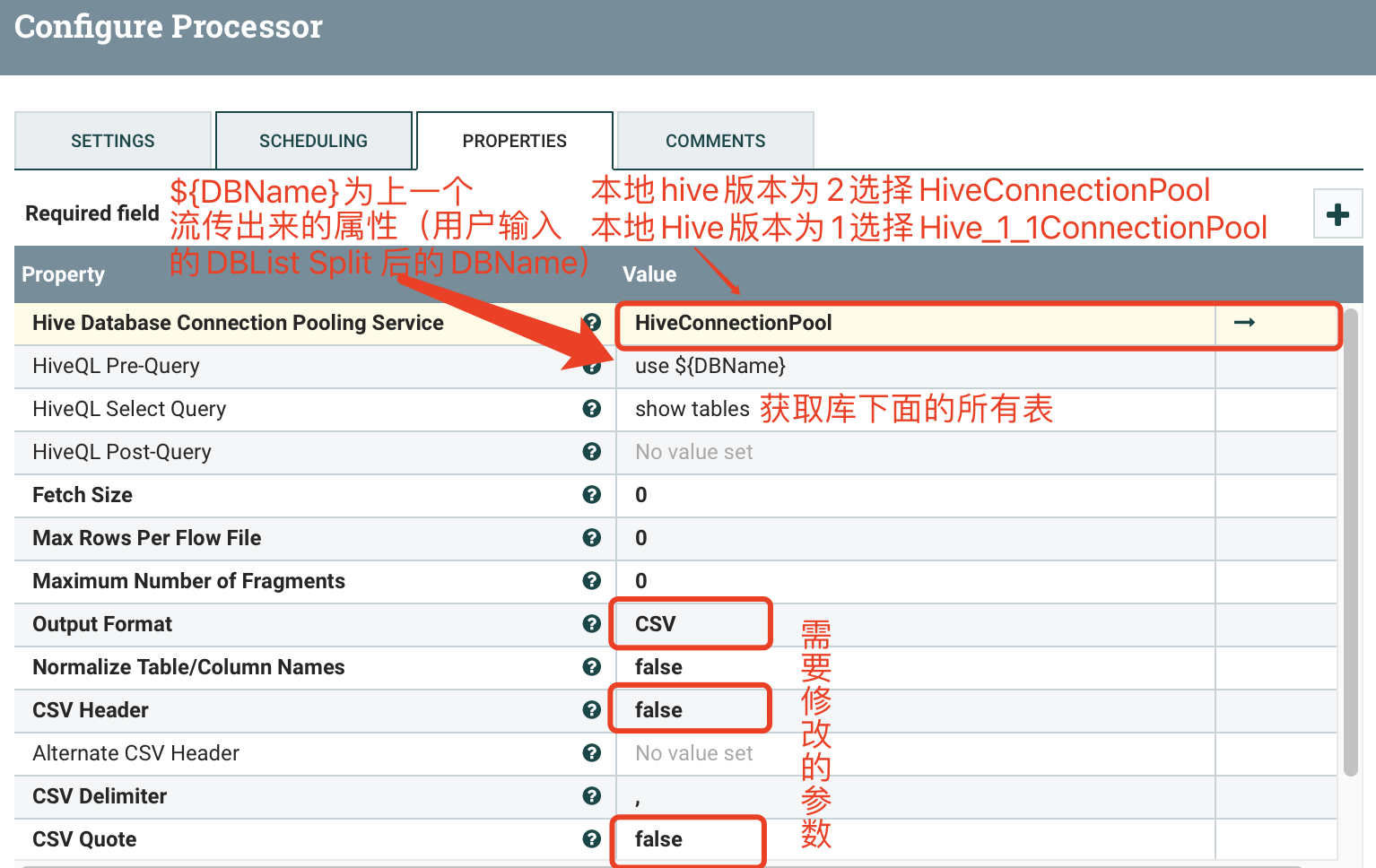
2.3 ExecuteGroovyScript(2)
a) SETTINGS
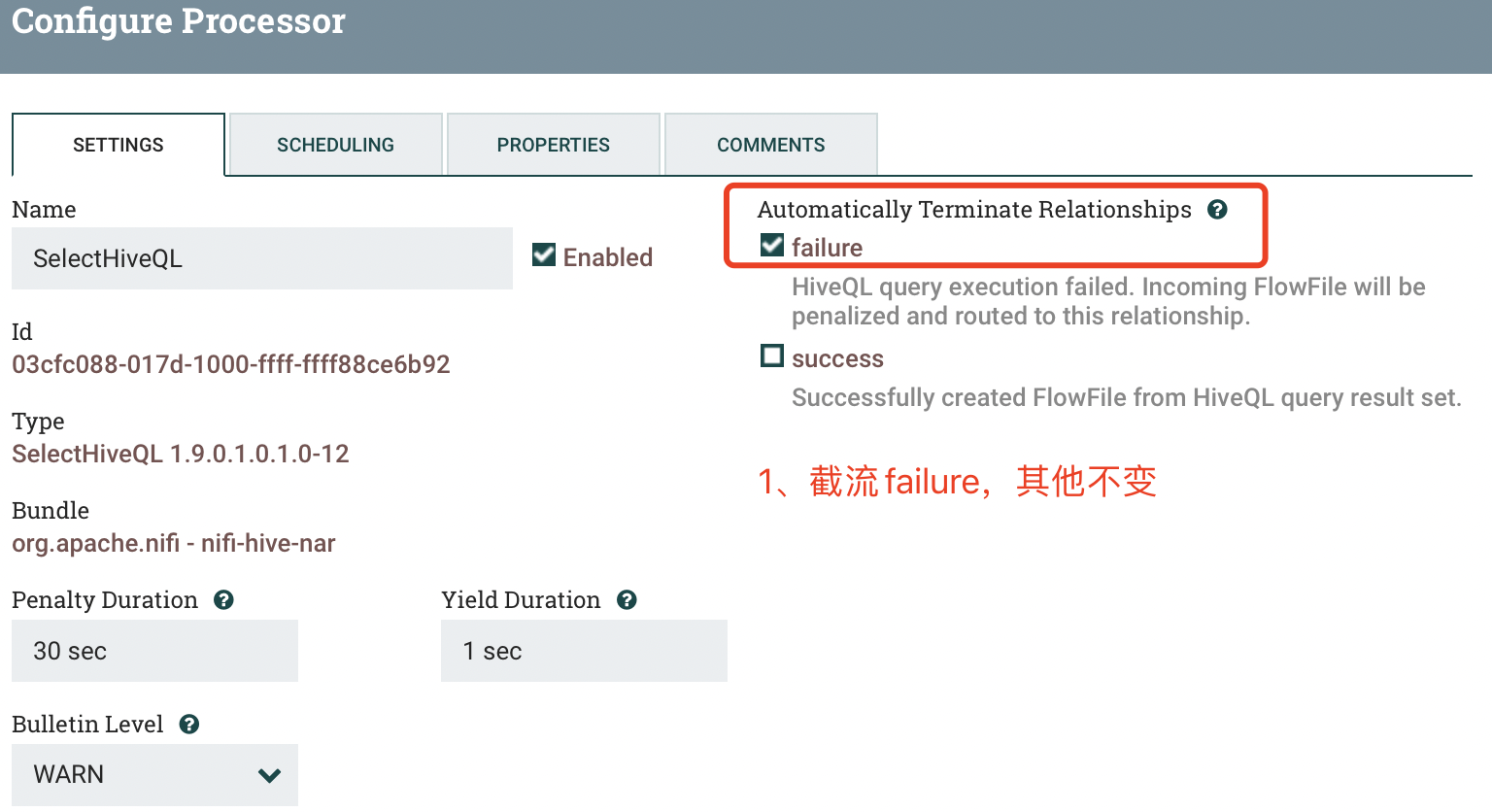
b) SCHEDULING
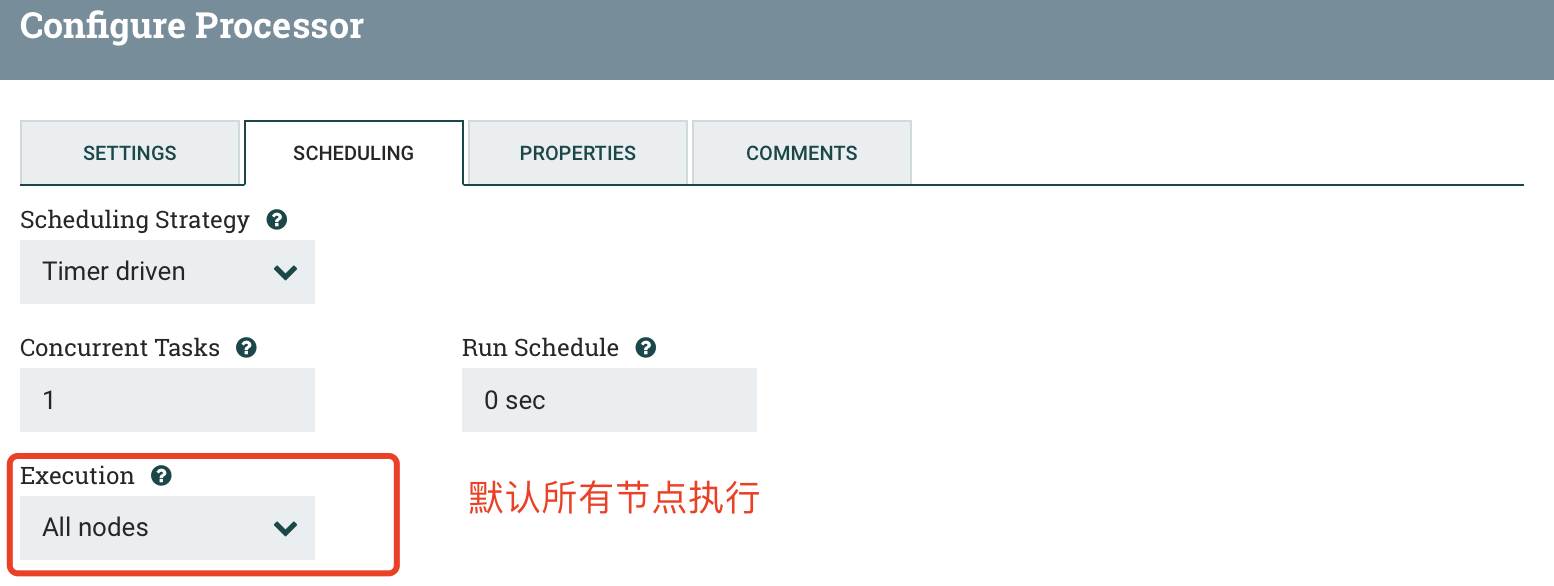
c) PROPERTIES
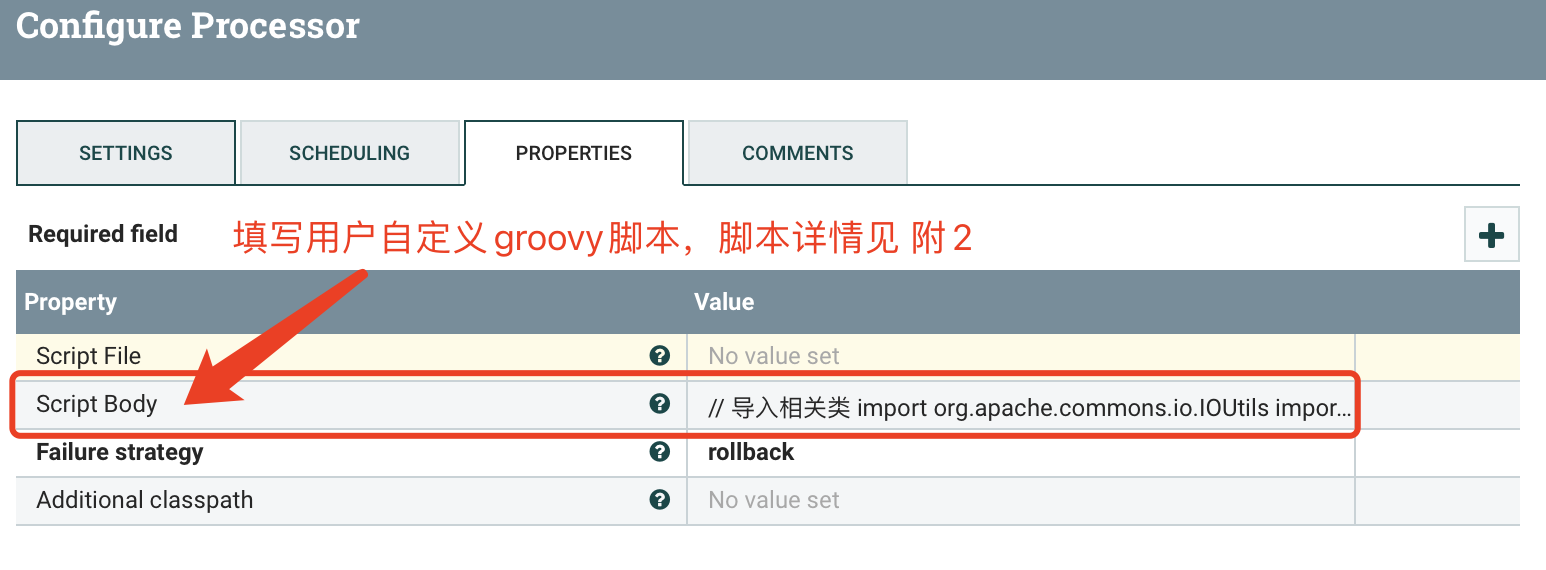
2.4 SelectHiveQL(2)
a) SETTINGS
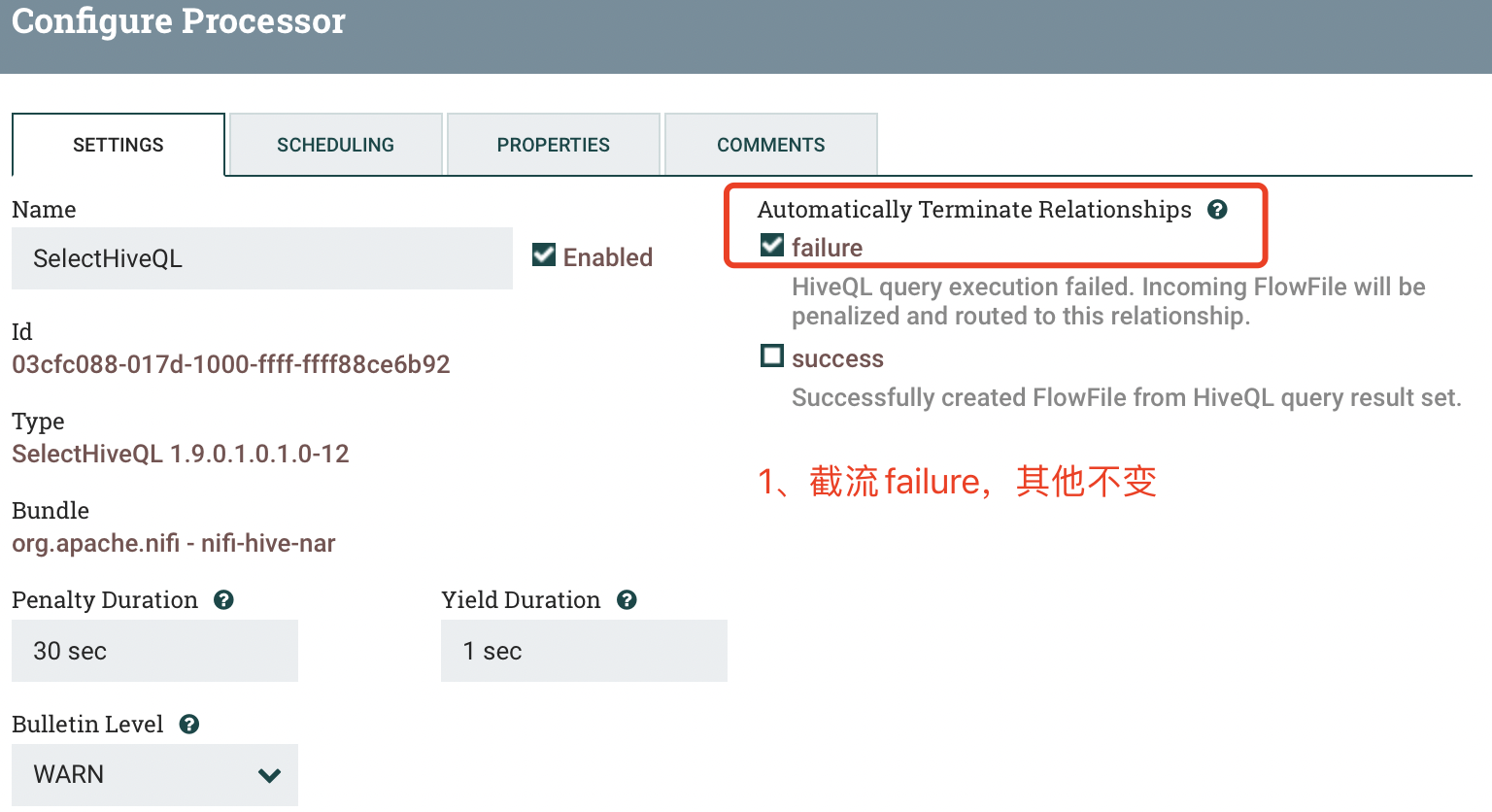
b) SCHEDULING
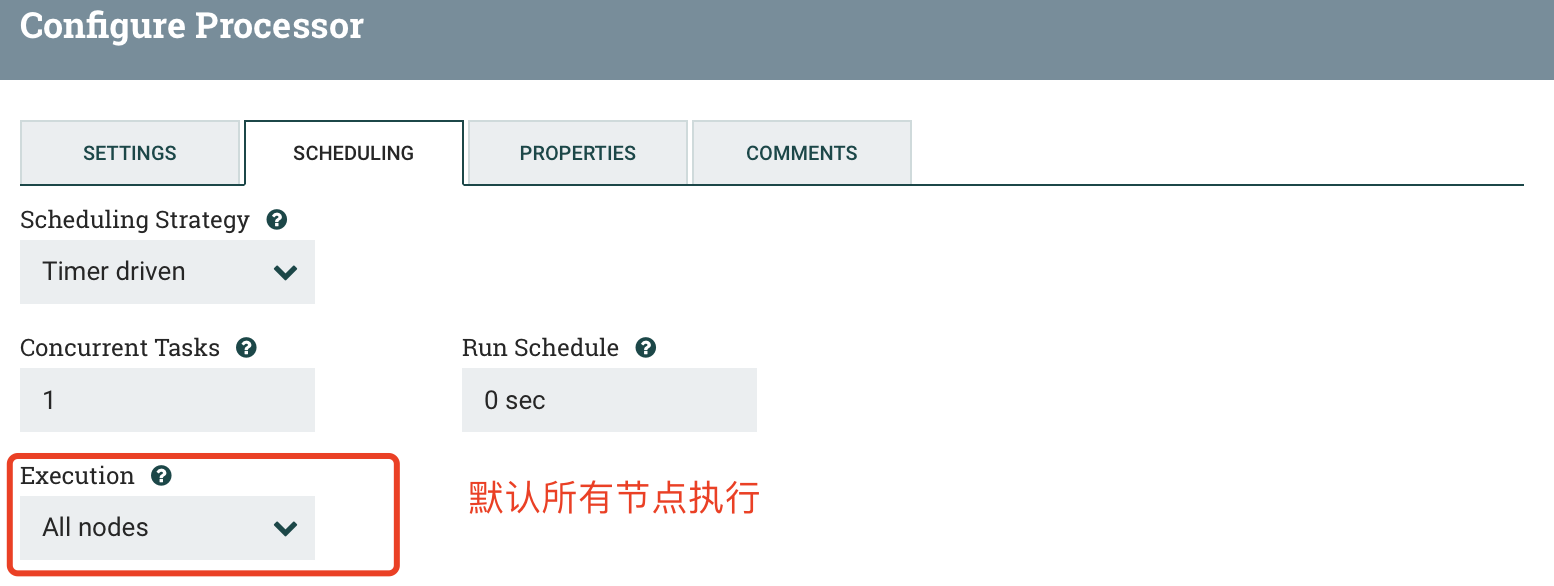
c) PROPERTIES
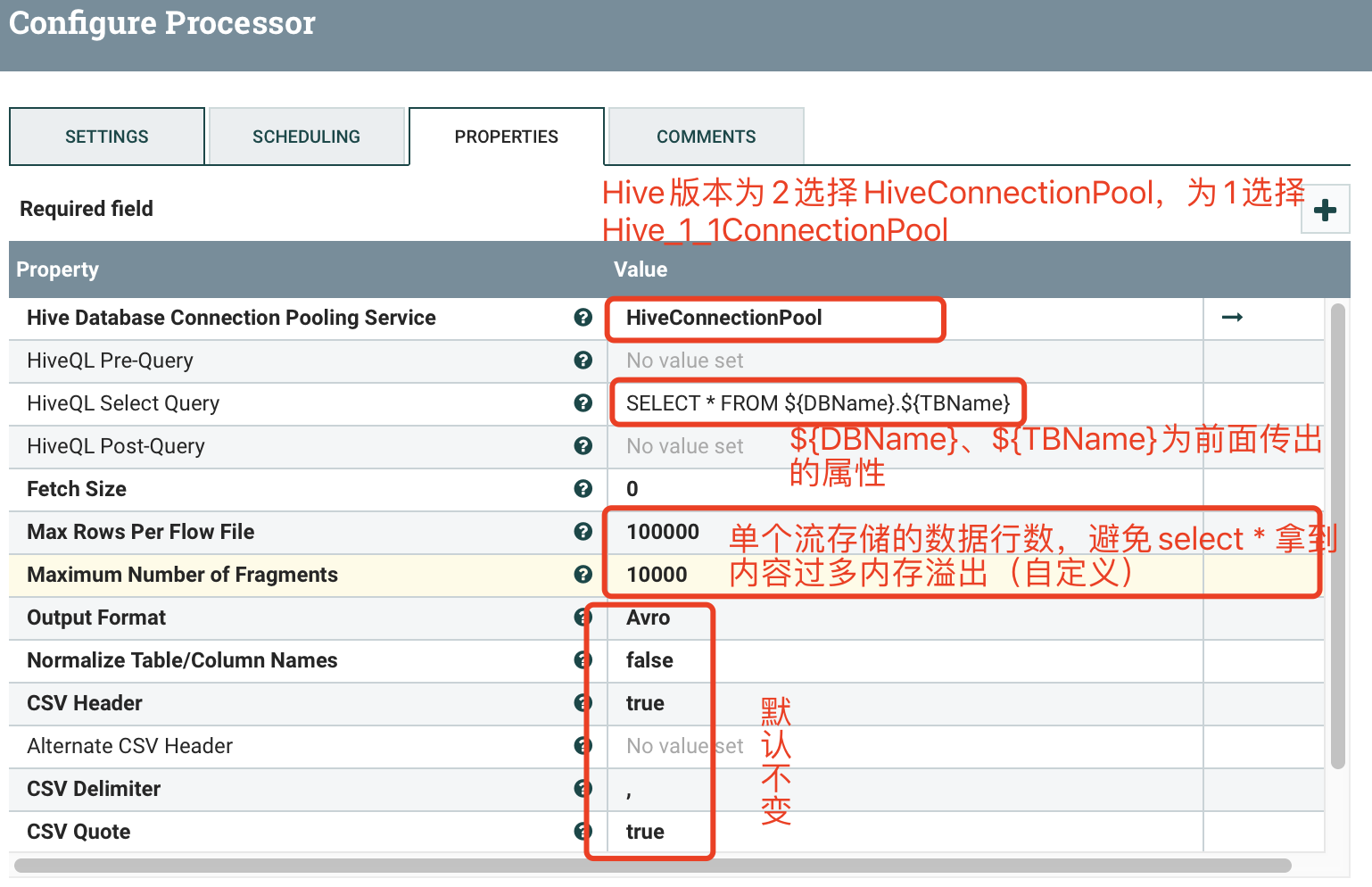
2.5 HiveConnectionPool、Hive_1_1ConnectionPool

a) PROPERTIES
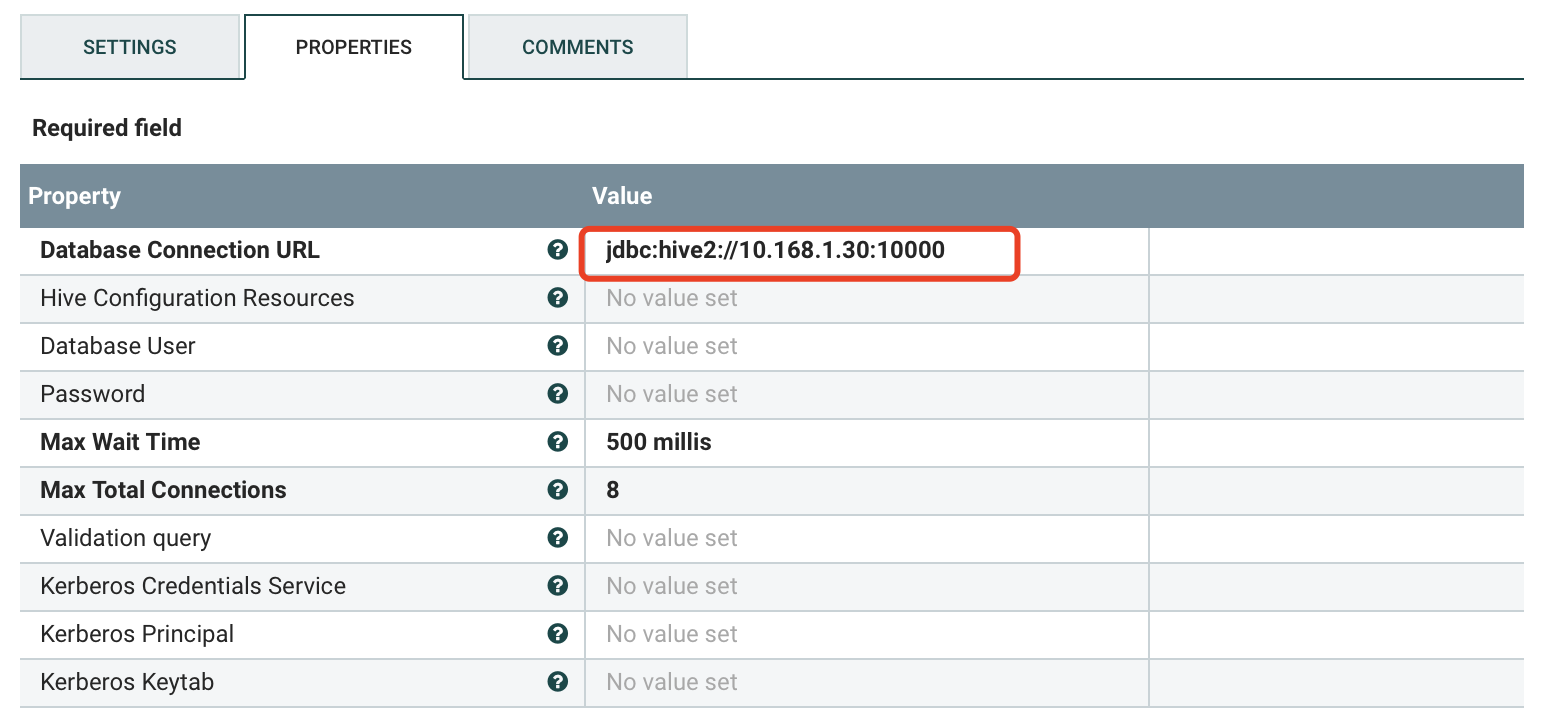
注:HiveConnectionPool和Hive_1_1ConnectionPool配置参数一样
二、目标端
1、结构展示
1.1 外层
1.2 内层

2、Processor
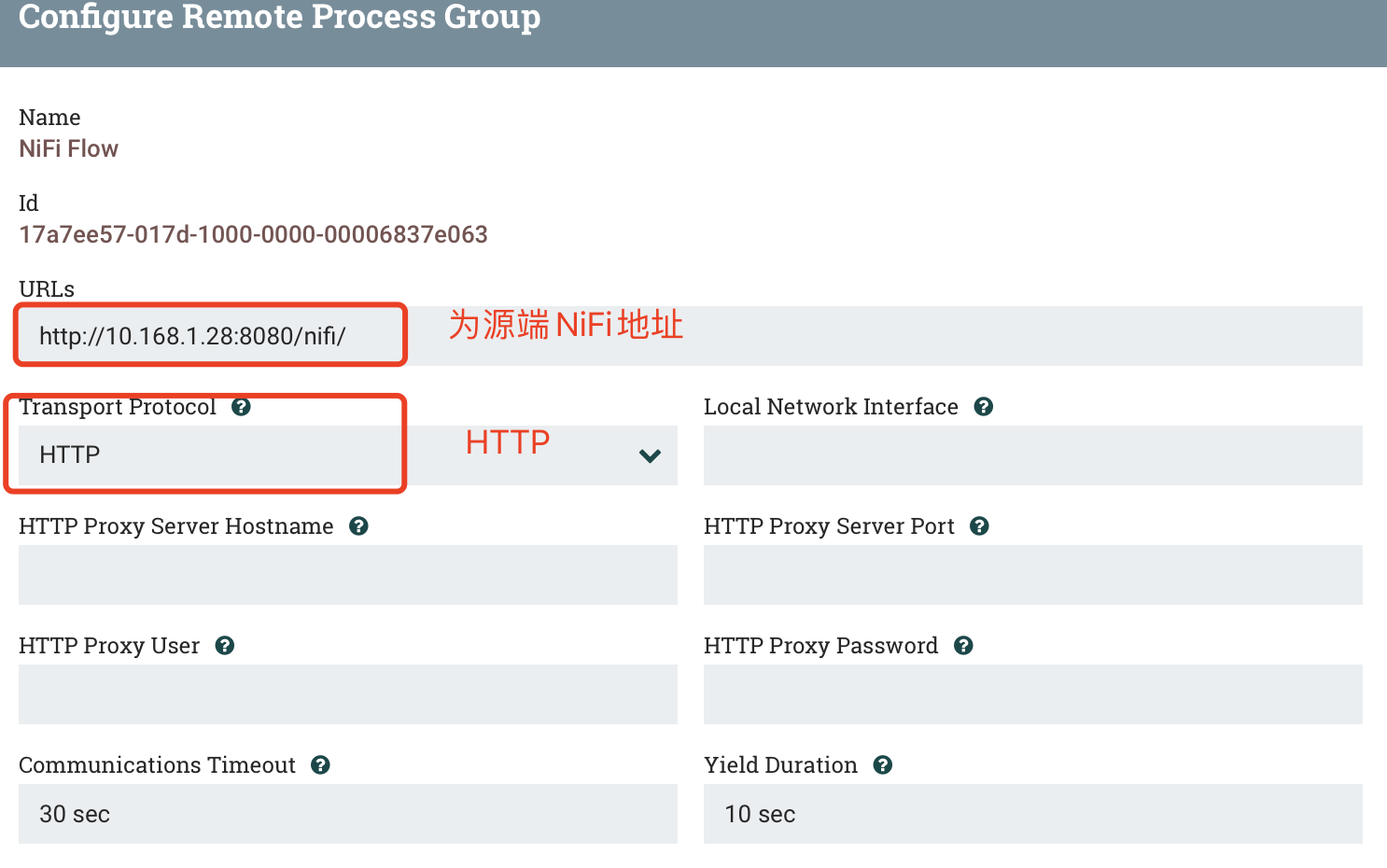
2.1 NiFi Flow
a) SETTINGS
b) SCHEDULING
c) PROPERTIES
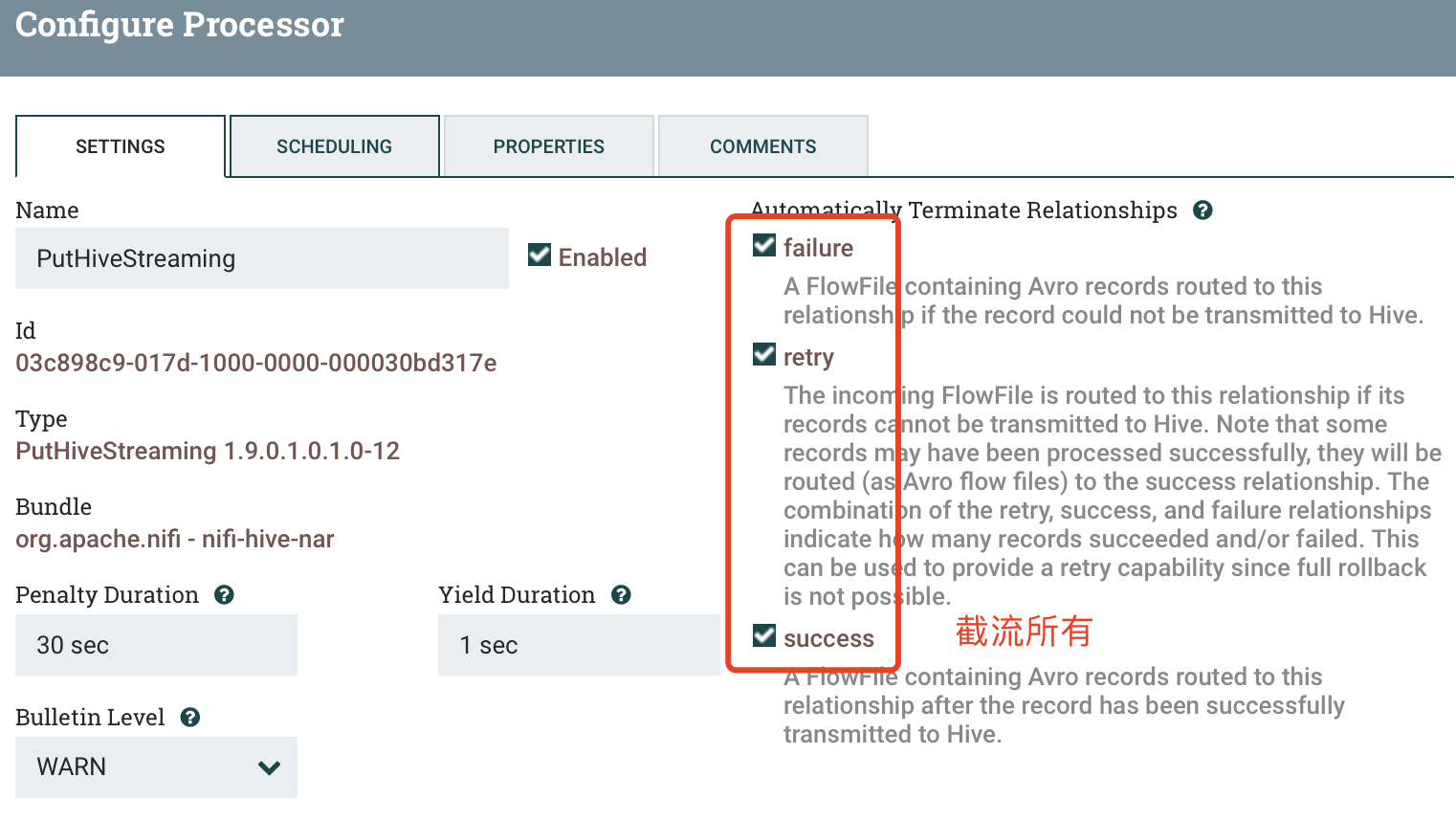
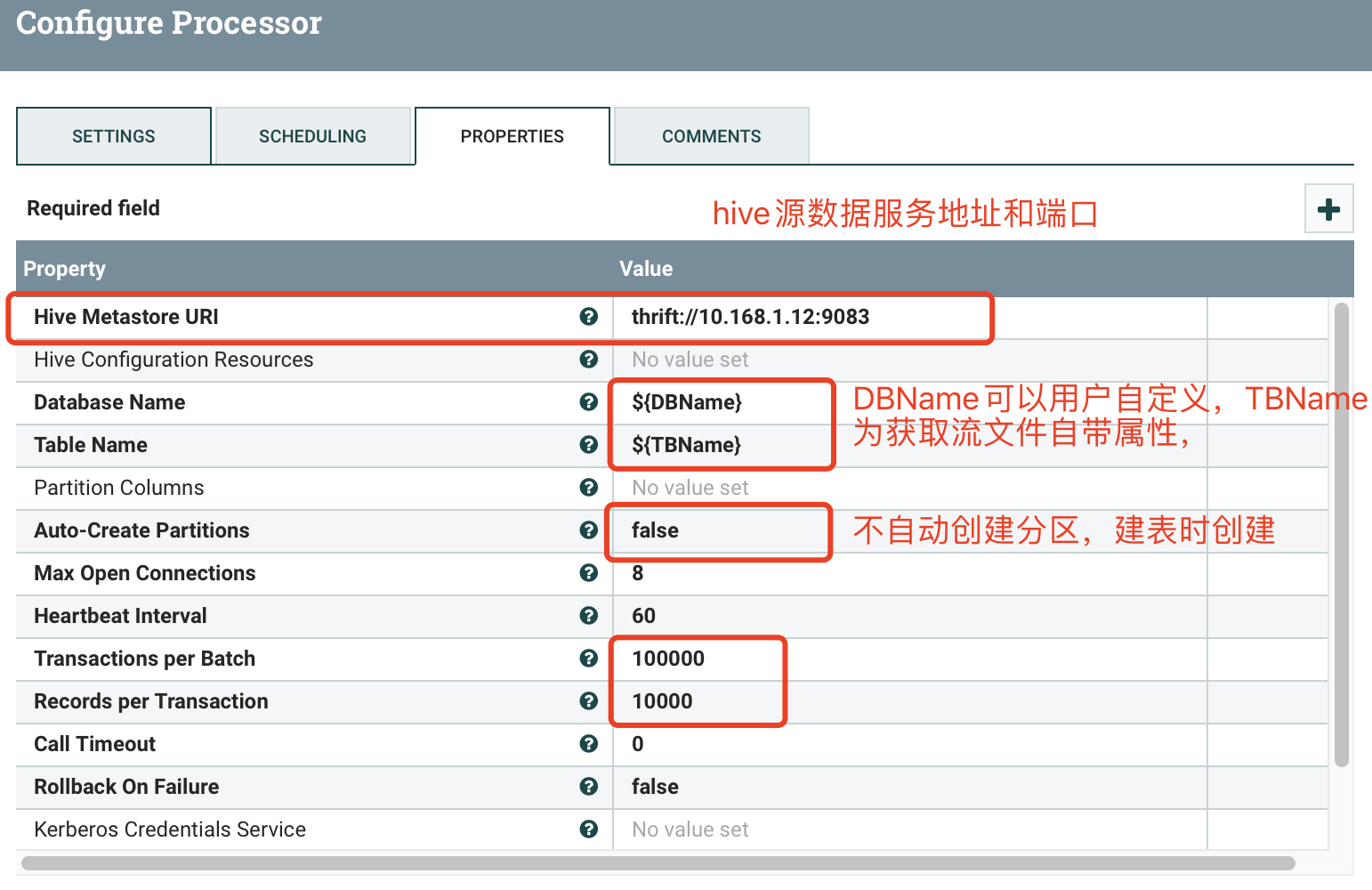
2.2 PutHiveStreaming
a) SETTINGS
b) SCHEDULING
c) PROPERTIES
三、附页
附1:
import java.nio.charset.StandardCharsets
// 获取以逗号拆分的库名字符串
String DBList = DBList
// 拆分库名
String[] data = DBList.split(“,”)
// 获取数据长度
int length = data.length;
if (length==0){
return
}
// 循环所有库
for (Integer i = 0; i < length; i++) {
if (data[i]==””){
session.transfer(flowFile,REL_FAILURE)
continue
}
flowFile = session.create()
// 添加属性
flowFile = session.putAttribute(flowFile, ‘DBName’, data[i])
// 写入flowFile中
session.write(flowFile, {outputStream ->
outputStream.write(data[i].toString().getBytes(StandardCharsets.UTF_8))
} as OutputStreamCallback)
// flowFile —> success
session.transfer(flowFile, REL_SUCCESS)
}
附2:
// 导入相关类
import org.apache.commons.io.IOUtils
import java.nio.charset.StandardCharsets
// 获取流文件
flowFile = session.get()
// 读取文件内容
def text = ‘’
session.read(flowFile, {
inputStream ->
text = IOUtils.toString(inputStream, StandardCharsets.UTF_8)
} as InputStreamCallback
)
// 获取DBName
def DBName = flowFile.getAttribute(‘DBName’)
if (text == ‘’) {
session.transfer(flowFile, REL_FAILURE)
return
}
// 拆分表名
String[] data = text.split(“\n”)
// 获取数据长度
int length = data.length;
// 循环所有库
for (Integer i = 0; i < length; i++) {
newFlowFile = session.create()
// 添加属性
newFlowFile = session.putAttribute(newFlowFile, ‘DBName’, DBName)
// 添加属性
newFlowFile = session.putAttribute(newFlowFile, ‘TBName’, data[i])
// 声明容器存储结果
StringBuffer stringBuffer = new StringBuffer()
stringBuffer.append(“{\”DBName\”:\””+ DBName + “\”,\”TBNaem\”:\”” + data[i] + “\”}”)
// 写入flowFile中
session.write(newFlowFile, {outputStream ->
outputStream.write(stringBuffer.toString().getBytes(StandardCharsets.UTF_8))
} as OutputStreamCallback)
// flowFile —> success
session.transfer(newFlowFile, REL_SUCCESS)
}
// flowFile —> success
session.transfer(flowFile, REL_FAILURE)
附3:
整个流程为通过用户传入库名来获取整个库数据,如果需要拉单个表,源端只需要SelectHiveQL一个Processor就行,用户自定义SQL,目标端PutHiveStraming也是用户自定义入库库名和表名。

若有收获,就点个赞吧
0 人点赞
