
介绍
网络爬虫是一种按照一定的规则自动地捕获万维网信息的程序或脚本。
爬虫程序通常从网站的某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,然后一直循环下去,直到把这个网站所有的网页都捕获完毕。
本质是模拟客户的请求,接收对方的网络响应,按照程序员的要求抓取对应的信息
(理论上浏览器能做的,爬虫都能做)
爬虫分类:
- 通用爬虫:搜索引擎的爬虫
- 聚焦爬虫:针对特定网站的爬虫
网络爬虫的步骤:
1.获取网页内容
2.对获取的网页内容进行分析处理
Python中实现网络爬虫的库有:urilib、urilib2、urilib3、requests等。
requests库主要用来获取网页内容
beautifulsoup4库用来分析网页数据
二、请求库的安装
2.1 requests库
requests库属于第三方库,需要手动安装
是一个阻塞式HTTP请求库,当我们发出一个请求后,程序会一直等待服务器响应,直到得到响应后,程序才会进行下一步处理,会耗费很多时间。pip install requests
2.2 Selenium
Selenium工具,是一个自动化测试工具,可以驱动浏览器执行特定的动作 pip install selenium
中文官方文档:https://selenium-python-zh.readthedocs.io/
2.3 ChromeDriver
查看安装的Chrome浏览器的版本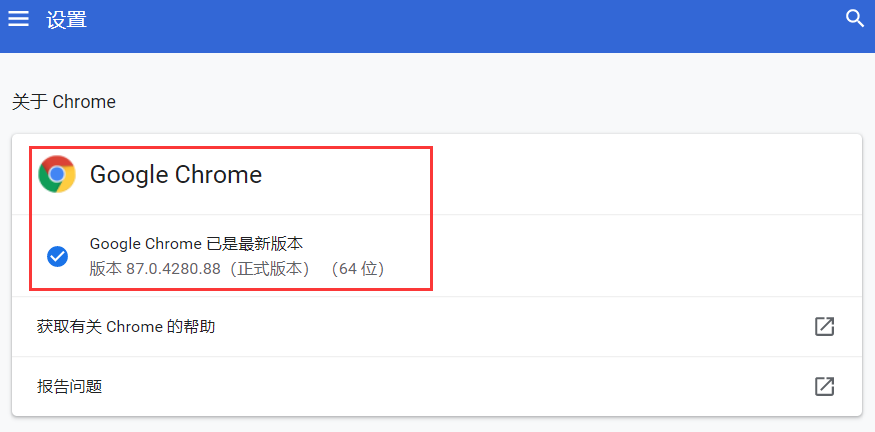
官网:https://chromedriver.chromium.org/
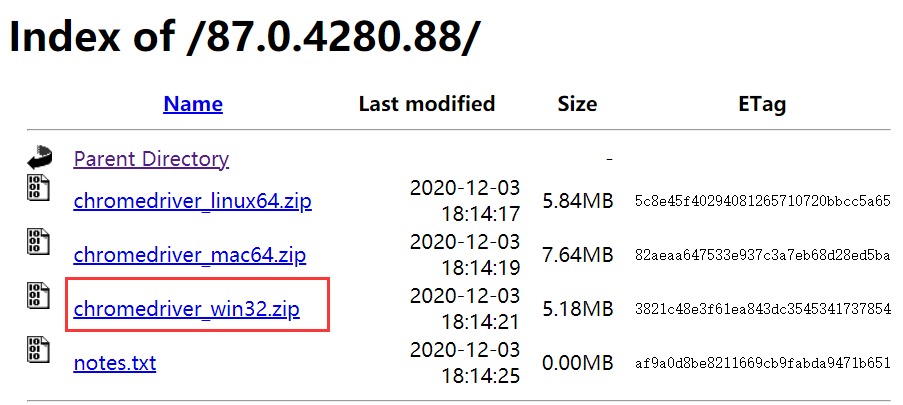
下载对应版本的安装包
下载完成后,将ChromeDriver的可执行文件配置到环境变量下,在windows下,将chromedriver.exe移动到C:\Users\lh\AppData\Local\Programs\Python\Python37\Scripts里面下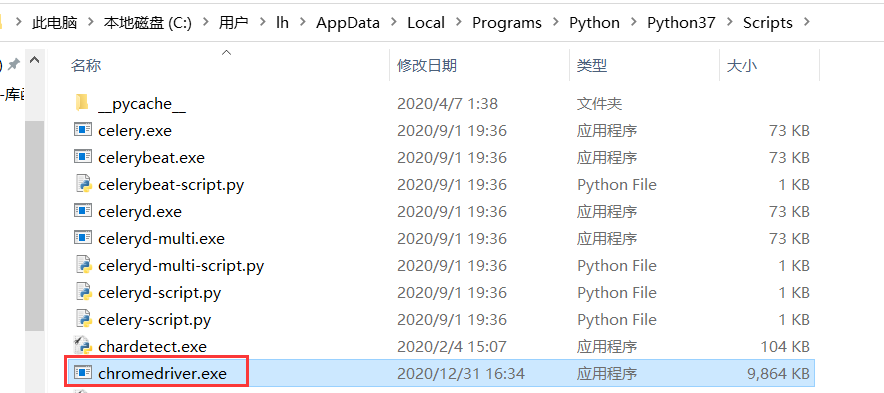
然后再命令行中输入chromedriver
然后运行下面的代码,会打开下面的空白的网页,说明安装成功
from selenium import webdriverbrowser = webdriver.Chrome()

如果是firefox浏览器,需要安装另一个驱动GeckoDriver驱动,方式与ChromeDriver类似
在cmd模式下输入命令的时候,输入geckodriver
from selenium import webdriverbrowseer = webdriver.Firefox()
2.4 PhantomJS
PhantomJS是一个无界面、可脚本编程的WebKit浏览器引擎,支持原生多种Web标准:DOM操作、CSS选择器、JSON、Canvas以及SVG。
Selenitm支持PhantomJS,在运行的时候就不会弹出一个浏览器,而且效率很高,还支持各种参数配置。
官网:https://phantomjs.org/download.html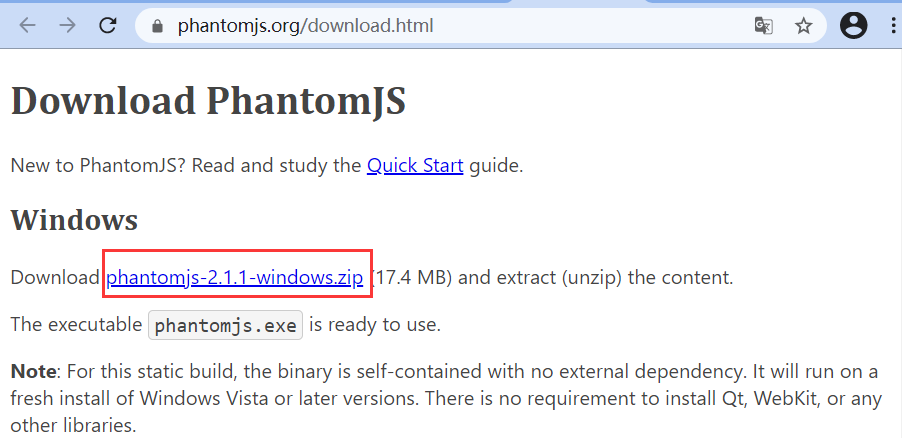
将压缩包解压之后,将可以将bin文件夹下的phantomjs.exe文件复制到Python的Scripts文件夹,或者将bin目录加入到环境变量中。
在cmd的命令行模式,phantomjs,显示如下图所示
验证安装
from selenium import webdriverbrowser = webdriver.PhantomJS()browser.get('https://www.baidu.com/')print(browser.current_url)
运行下面的代码,防火墙如果有提示的话,要点击允许。我们可以看到没有浏览器 弹出,实际上PhantomJS已经运行起来了,访问https://www.baidu.com/,就会将当前的URL打印出来。
2.5 aiohttp
aiohttp是一个提供异步Web服务的库,从Python3.5版本开始,Python中加入了asyn/await关键字,使得回调的写法更加直观和人性,写法也更加简洁,架构也更加清晰,使用异步请求库进行数据抓取的时候,会大大提高效率。
在维护一个代理池的时候,以及利用异步方式检测大量代理的运行状况的时候,用到aiohttp会极大地提升效率。
官方文档:https://docs.aiohttp.org/en/stable/
PyPI:https://pypi.org/project/aiohttp/
安装: pip install aiohttp
还需要安装一个字符编码检测库cchardet,pip install cchardet
还需要安装一个加速DNS的解析库aiodns,pip install aiodns
执行 import aiohttp 没有报错的话,就说明安装好了。
三、解析库的安装
抓取网页代码之后,还需要从网页中提取信息,python有强大的解析库,lxml、Beautiful Soup、pyquery等,还提供了强大的解析方法,eg:XPath解析和CSS选择器解析等。
3.1 lxml
lxml是Python的一个解析库,支持HTML和XML解析,支持XPath解析方式,而且解析效率很高。
windows下的安装方式pip install lxml
官方网址:https://lxml.de/
github:https://github.com/lxml/lxml
PyPI:https://pypi.org/project/lxml/
运行import lxml不报错,就证明库已经安装好了
3.2 Beautiful Soup
Beautiful Soup 是一个Python的HTML或XML的解析库,可以从网页中提取数据,拥有强大的API和多种解析方式。
官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/
中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
PyPI: https://pypi.org/project/beautifulsoup4/
验证安装,运行下面的代码,出现happy New year!
from bs4 import BeautifulSoupsoup = BeautifulSoup('<p> Happy New year !</p>','lxml')print(soup.p.string)

安装的是beautifulsoup4这个包,引入的使用是bs4,是因为这个包源代码本身的库文件夹名称就是bs4,安装wan’c之后,库文件夹被移入到Python3的lib库中,被识别为bs4.
3.3 pyquery
pyquery是一个网页解析工具,提供了和jQuery类似的语法来解析HTML文档,支持CSS选择器。
github:https://github.com/gawel/pyquery
PyPI:https://pypi.org/project/pyquery/
官方文档:https://pyquery.readthedocs.io/
安装:pip install pyquery
测试:运行import pyquery不报错,说明安装好了
3.4 tesserocr
在爬虫过程中,会遇到很多的验证码,而且多数为图像验证码,可以直接使用OCR来识别。
OCR,即Optical Character Recognition,光学字符识别,然后通过其形状将其翻译成电子文本。
tesserocr是Python的一个OCR识别库,是对tesseract做的一层Python API封装,核心是tesseract。
tesserocr的github:https://github.com/sirfz/tesserocr
tesserocr的PyPI:https://pypi.org/project/tesserocr/
tesseract的github:https://github.com/tesseract-ocr/tesseract
tesseract的下载地址:https://github.com/UB-Mannheim/tesseract/wiki
tesseract的语言包https://github.com/tesseract-ocr/tessdata
tesseract的文档:https://github.com/tesseract-ocr/tessdoc
首先需要下载tesseract,它为tesserocr提供支持。

双击运行下载的.exe文件,然后进行安装,出现下面的这个图的时候需要勾选一下,之后一路next进行安装。
之后需要安装 tesserocrpip install tesserocr pillow
报错
安装 ,但是依然没有解决问题所在。
,但是依然没有解决问题所在。
之后不采用pip instal 的方式去进行安装
https://github.com/simonflueckiger/tesserocr-windows_build/releases 上面下载.whl文件,然后以管理员的方式打开cmd命令行,进入这个.whl文件的目录下,然后 pip install ./tesserocr-2.4.0-cp37-cp37m-win_amd64.whl进行安装。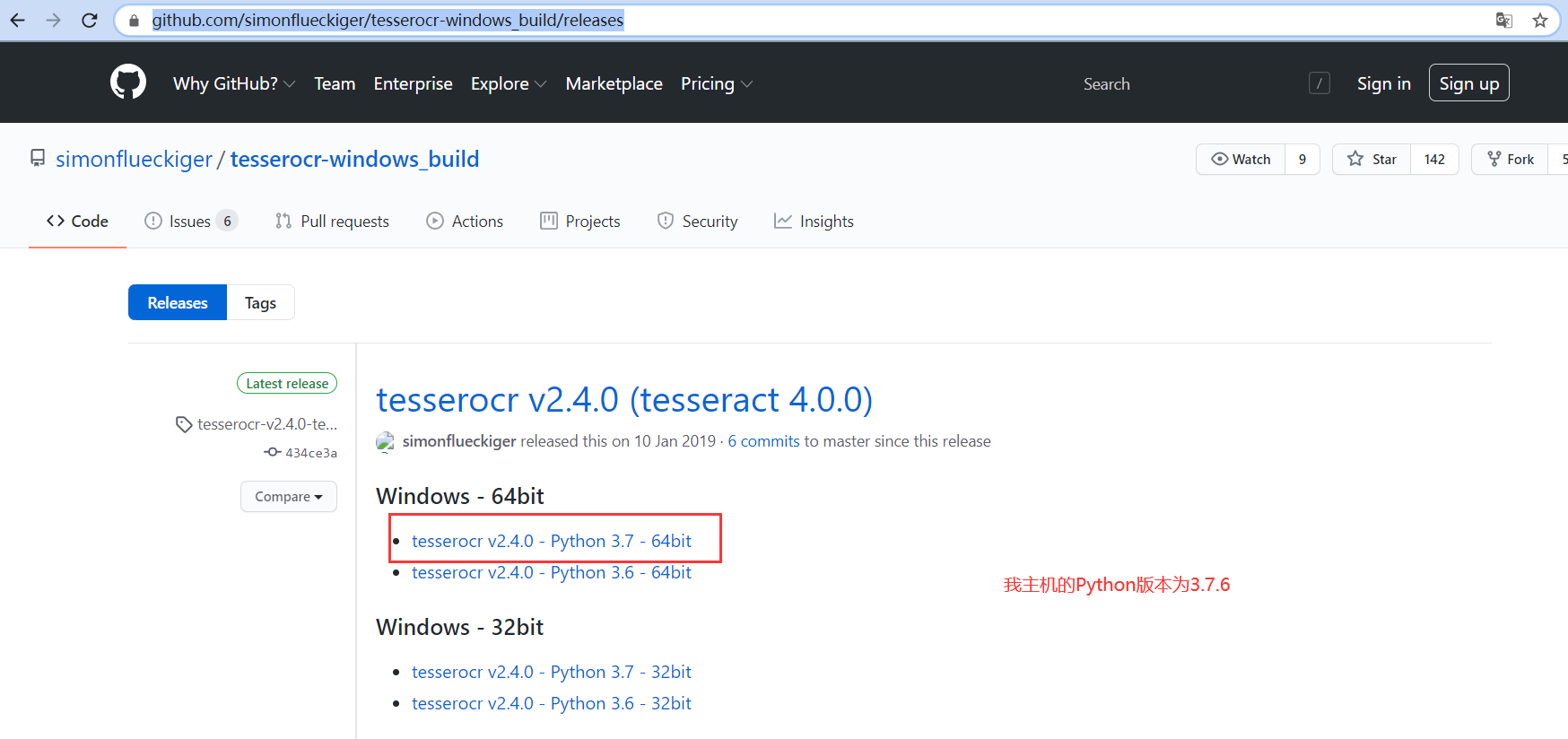

四、数据库的安装
进行数据存储,需要安装数据库,数据库分为关系型数据库和非关系型数据库
关系型数据库eg:SQLite、MySQL、Oracle、SQL Server、DB2等,数据库是以表的形式存储的
非关系型数据库:MongoDB、Redis,数据库的存储形式是键值对。
4.1 MySQL
MySQL是一个轻量级的关系型数据库
官方网址:https://www.mysql.com/cn/
下载地址:https://www.mysql.com/cn/downloads/
中文教程:https://www.runoob.com/mysql/mysql-tutorial.html
点击安装包安装就可以,在设置用户名和密码的位置设置密码
4.2 MongoDB
MongoDB是由C++语言编写的非关系型数据库,是一个基于分布式文件存储的开源数据库系统,其内容存储形式类似JSON对象,字段值可以包含其他文档、数组及文档数组等。
MongoDN支持多种平台,包括Windows、Linux、Mac OS ,Solaris等。
官方网站:https://www.mongodb.com/
官方文档:https://docs.mongodb.com/
GitHub: https://github.com/mongodb
中文教程:https://www.runoob.com/mongodb/mongodb-tutorial.html
4.3 Redis
Redis是基于内存的高效的非关系型数据库
官方网站:https://redis.io
官方文档:https://redis.io/documentation
中文官网:http://www.redis.cn
GitHub: https://github.com/antirez/redis
中文教程:http://www.runoob.com/redis/redis-tutorial.html
Redis Desktop Manager::https://redisdesktop.com
Redis Desktop Manager GitHub:https://github.com/uglide/RedisDesktopManager
redis 发行版本地址:https://github.com/microsoftarchive/redis/releases
下载之后,之间点击 .msi文件就可以完成安装

Redis的可视化管理工具,下载地址https://github.com/uglide/RedisDesktopManager/releases
https://docs.rdm.dev/en/latest/install/
五、存储库的安装
数据库要和Python交互的话,还需要安装一些Python存储库,eg:MySQL需要安装PyMySQL、MongoDB需要安装PyMongo等。
5.1 PyMySQL
把数据存储到MySQL中的时候,需要借助PyMySQL来进行操作
官网:https://pypi.org/project/PyMySQL/
官方文档:https://pymysql.readthedocs.io/en/latest/
PyPI:https://pypi.org/project/PyMySQL/
下载:
##查看安装版本import pymysqlprint(pymysql.VERSION)##结果(0, 10, 1, None)
5.2 PyMongo
把数据存储到Mondogo中的时候,需要借助PyMongo来进行操作。
GitHub:https://github.com/mongodb/mongo-python-driver
官方文档:https://api.mongodb.com/python/current/
PyPI:https://pypi.org/project/pymongo/
下载:
#查看安装版本import pymongoprint(pymongo.version)##结果3.11.2
5.3 Redis-py
把数据存储到Redis中的时候,需要借助Redis-py来进行操作。
GitHub:https://github.com/andymccurdy/redis-py
官方文档:https://redis-py.readthedocs.io/en/stable/
下载:
##查看安装版本import redisprint('redis数据库的版本:',redis.VERSION)##结果redis数据库的版本: (3, 5, 3)
5.5 Redisdump工具
RedisDump工具时一个用于Redis数据导入/导出的工具,是基于Ruby实现的,所以,要安装RedisDump,需要先安装Ruby。
GitHub:https://github.com/delano/redis-dump
官方文档:http://delanotes.com/redis-dump/
安装Ruby,http://www.ruby-lang.org/zh_cn/downloads/
安装之后,可以执行gem命令,利用gem命令,进行安装RedisDump,gem install redis-dump
安装完成之后,执行redis-dump和redis-reload命令,调用成功,就证明安装成功。
六、Web库的安装
现在访问的很多网站都是Web服务程序搭建的,Python也有web服务程序,Flask、Django等,可以用于开发网站和接口等。
6.1 Flask
Flask是一个轻量级的Web服务程序,主要用来做一些API服务。
GitHub:https://github.com/pallets/flask
官方文档:http://flask.pocoo.org
中文文档:http://docs.jinkan.org/docs/flask/
PyPI:https://pypi.org/project/Flask/
安装 pip install flask
from flask import Flaskapp = Flask(__name__)@app.route('/')def hello():return "Hello Flask !"if __name__ == '__main__':app.run()##结果Use a production WSGI server instead.* Debug mode: off* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)127.0.0.1 - - [03/Jan/2021 23:30:44] "GET / HTTP/1.1" 200 -
访问http://127.0.0.1:5000/,显示如下所示的图像,说明Flask程序运行成功。 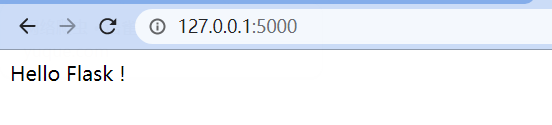
6.2 Tornado
Tornado是一个支持异步的Web框架,通过使用非阻塞I/O六,可以支撑成千上万的开放连接,效率非常高。
GitHub: https://github.com/tornadoweb/tornado
PyPI: https://pypi.org/project/tornado/
官方文档:http://www.tornadoweb.org
下载 pip install tornado
##测试 tornado是否安装成功import tornado.ioloopimport tornado.webclass MainHandler(tornado.web.RequestHandler):def get(self):self.write("Hello tornado!")def make_app():return tornado.web.Application([(r"/",MainHandler)])if __name__ == "__main__":app = make_app()app.listen(8888)tornado.ioloop.IOLoop.current().start()##结果WARNING:tornado.access:404 GET /favicon.ico (127.0.0.1) 1.00ms
运行程序,访问http://127.0.0.1:8888/,可以看出如下所示的图,说明Tornado成功安装。
七、App爬取相关库的安装
APP中的页面要加载出来,首先需要获取数据,这些数据一般都是通过请求服务器的接口来获取的,需要通过一些抓包技术来抓取数据。
7.1 Charles
Chaeles是一个网络抓包工具,与Fidder相比,功能更加强大,而且跨平台支持更好。
官方网站: https://www.charlesproxy.com
下载链接:https://www.charlesproxy.com/download
7.2 mitmproxy
mitmproxy是一个支持HTTP和HTTPS的抓包工具,是通过控制台的形式进行操作的。
mitmproxy还有两个关联组件
一个是mitmdump,是mitmproxy的命令行接口,利用它可以对接Python脚本,实现监听后的处理
一个是mitmweb,是一个web程序,通过它可以清除地观察到mitmproxy捕获的请求。
GitHub: https://github.com/mitmproxy/mitmproxy
官方网站:https://mitmproxy.org/
PyPI:https://pypi.org/project/mitmproxy/
官方文档:https://docs.mitmproxy.org/stable/
下载地址:https://github.com/mitmproxy/mitmproxy/releases
DockerHub: https://hub.docker.com/r/mitmproxy/mitmproxy
7.3 Appium
APPium是移动端的自动化测试工具,利用它可以驱动Android、IOS等设备完成自动化测试,eg:模拟点击、滑动、输入等操作。
GitHub: https://github.com/appium/appium
官方网站: http://appium.io/
官方文档:http://appium.io/introduction.html
下载链接:https://github.com/appium/appium-desktop/releases
Python Client: https://github.com/appium/python-client
八、爬虫框架的安装
爬虫框架就是将直接用库进行爬虫中可以复用的代码和组件抽离处理,将各个功能模块化形成的一个框架。
8.1 pyspider
pyspider是国人binux编写的强大的网络爬虫框架,具有强大的WebUI、脚本编辑器、人物控制器、项目管理器以及结果处理器,同时支持多个数据库后端、多种消息队列,另外还支持JavaScript渲染页面的爬取。
官方文档:http://docs.pyspider.org/en/latest/
PyPI: https://pypi.python.org/pypi/pyspider
GitHub: https://github.com/binux/pyspider
官方教程:http://docs.pyspider.org/en/latest/tutorial/
在线实例:http://demo.pyspider.org/
8.2 Scrapy
Scrapy是一个十分强大的爬虫框架,依赖的库比较多,至少需要依赖的库有Twisted 14.0、 Ixml 3.4和pyOpenSSL 0.14。在不同的平台环境下,它所依赖的库也各不相同,所以在安装之前,最好确保把一些基本库安装好。
官方网站:https://scrapy.org
官方文档:https://docs.scrapy.org
PyPI: https://pypi.python.org/pypi/Scrapy
GitHub: https://github.com/scrapy/scrapy
中文文档:http://scrapy-chs.readthedocs.io

若有收获,就点个赞吧
0 人点赞
