
核心内容
对静态权重的深度分离卷积和MLP-Mixer,以及动态权重的Self-Attention操作进行了形式上的统一表示,并且提出了一种统一整合了这些方法思想的结构——Container。
首先定义了多头形式的上下文信息聚合框架: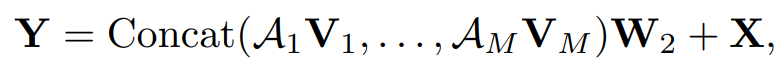 。这里的A表示不同头(独立的通道组)内部使用的仿射矩阵,用于上下文信息的聚合。而V=XW,是输入X线性变换后的结果。三种操作的不同主要在于仿射矩阵的定义方式有所不同。
。这里的A表示不同头(独立的通道组)内部使用的仿射矩阵,用于上下文信息的聚合。而V=XW,是输入X线性变换后的结果。三种操作的不同主要在于仿射矩阵的定义方式有所不同。
- Self-Attention:
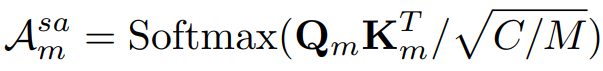
- 深度分离卷积:
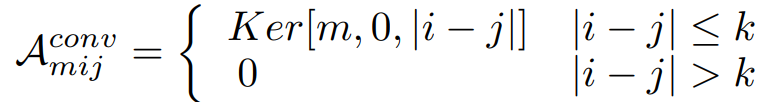
- MLP-Mixer:
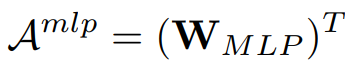
第一种形式是与输入相关的动态权重,后两种形式中的权重都是与输入无关的静态权重。
本文通过组合动态权重与静态权重,从而提出结构: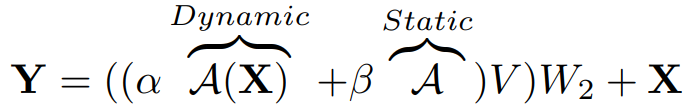 。动态权重的计算仍然遵循原始的注意力机制的形式,而后面静态权重的计算则可以按照标准的深度分离卷积(通道间权重独立,即头内部通道数为1)或者是标准的MLP-Mixer形式。除此之外,也可以使用通道间权重独立的MLP形式,这种形式可以称为多头的MLP。搭配不同的权重
。动态权重的计算仍然遵循原始的注意力机制的形式,而后面静态权重的计算则可以按照标准的深度分离卷积(通道间权重独立,即头内部通道数为1)或者是标准的MLP-Mixer形式。除此之外,也可以使用通道间权重独立的MLP形式,这种形式可以称为多头的MLP。搭配不同的权重 组合,可以实现不同形式的特化。由此实现了三种形式的统一。
组合,可以实现不同形式的特化。由此实现了三种形式的统一。
当组合深度分离卷积的时候,作者提供了如下一图来和传统的自注意力权重形式进行比较:
核心代码
class Attention_pure(nn.Module):# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.pydef __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):super().__init__()self.num_heads = num_headshead_dim = dim // num_heads# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weightsself.scale = qk_scale or head_dim ** -0.5self.attn_drop = nn.Dropout(attn_drop)self.proj_drop = nn.Dropout(proj_drop)def forward(self, x):B, N, C = x.shapeC = int(C // 3)qkv = x.reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)attn = (q @ k.transpose(-2, -1)) * self.scaleattn = attn.softmax(dim=-1)attn = self.attn_drop(attn)x = (attn @ v).transpose(1, 2).reshape(B, N, C)x = self.proj_drop(x)return xclass MixBlock(nn.Module):# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.pydef __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):super().__init__()self.dim = dimself.pos_embed = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)self.norm1 = nn.BatchNorm2d(dim)self.conv1 = nn.Conv2d(dim, 3 * dim, 1)self.conv2 = nn.Conv2d(dim, dim, 1)self.conv = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)self.attn = Attention_pure(dim,num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,attn_drop=attn_drop, proj_drop=drop)# NOTE: drop path for stochastic depth, we shall see if this is better than dropout hereself.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.norm2 = nn.BatchNorm2d(dim)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = CMlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)# 用于加权自注意力和静态聚合操作的权重self.sa_weight = nn.Parameter(torch.Tensor([0.0]))def forward(self, x):x = x + self.pos_embed(x)B, _, H, W = x.shaperesidual = xx = self.norm1(x)qkv = self.conv1(x)# 对V直接卷积conv = qkv[:, 2 * self.dim:, :, :]conv = self.conv(conv)sa = qkv.flatten(2).transpose(1, 2)sa = self.attn(sa)sa = sa.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()x = residual + self.drop_path(self.conv2(torch.sigmoid(self.sa_weight) * sa + (1 - torch.sigmoid(self.sa_weight)) * conv))x = x + self.drop_path(self.mlp(self.norm2(x)))return x
链接

若有收获,就点个赞吧
0 人点赞
