
主要工作
本文还是从多层级特征利用的角度入手,提出了一个Progressive Feature Polishing Network (PFPN),通过利用Feature Polishing Modules (FPMs)来“打磨”(polish)(细化)多层级特征。
这一点并没有太多让人感觉很有新意的地方。
倒是这篇文章反复提到了提出的结构可以avoid the long-term dependency problem。这一点主要引自Bengio et al. 1994年的一篇文章:Learning long-term dependencies with gradient descent is difficult。这里是一篇介绍文章和原文链接:
- https://www.jianshu.com/p/46367f985c64
- http://citeseer.ist.psu.edu/viewdoc/download;jsessionid=23894D6306F585CE5D8D7B028F821C40?doi=10.1.1.41.7128&rep=rep1&type=pdf
- [学习笔记] Long Short-Term Memory - 卓柳舟的文章 - 知乎 https://zhuanlan.zhihu.com/p/22670364
这是Bengio这篇文章摘要的翻译:
递归神经网络可用于将输入序列映射到输出序列,如用于识别、生产或预测问题。然而,在训练递归神经网络执行输入/输出序列中出现的时间偶发事件跨越很长时间间隔的任务时,已有工作报告了一些实际的困难。我们展示了为什么基于梯度的学习算法面临着一个越来越困难的问题,因为被捕获的依赖的持续时间增加了。这些结果揭示了通过梯度下降进行有效学习和网络长时间保持信息之间的权衡。基于对这一问题的理解,考虑了标准梯度下降的替代方法。
PFPN这篇文章提到“然而,这些(现有方法)在多级特征之间间接执行的集成可能由于引起的长期依赖问题而存在缺陷”,而这里指的便是Bengio这篇文章提到的梯度下降训练RNN模型存在一定的困难(“大概结论是back-propagation难以发现跨度太大的关联性”)。但是PFPN将十几年前在RNN上的结论直接用到了现在的CNN上,似乎有点牵强。
主要结构

整体结构还是比较直接和清晰的。各个结构都是不同的卷积块的组合。可以看出,这里有DSS的影子(递进式的跳层连接的集成)。
关于这里多部迭代计算的方式,文章有如下表述:
However, since the predicted results (一些现有的例如DSS、DHSNet等专注于显著性图细化的方法) have severe information loss than original representations, the refinement might be deficient. Different from these methods, our approach progressively improves the multi-level representations in a recurrent manner instead of attempting to rectify the predicted results. Besides, most previous refinements are performed in a deep-to-shallow manner, in which at each step only the features specific to that step are exploited. In contrast to that, our method polishes the representations at every level with multi-level context information at each step.
下面介绍下本文的关键结构,FPM。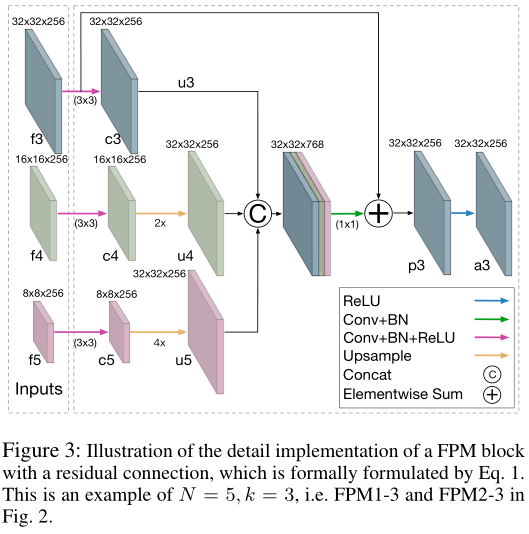
这里以FPM1-3或者FPM2-3为例进行展示,如上图所示。整体计算过程如下: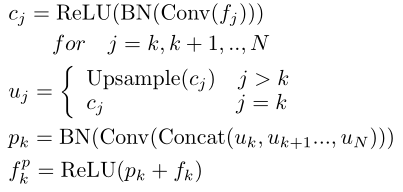
训练使用的损失函数如下: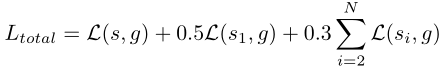
这篇文章使用了深监督技术。其中s表示最终的预测输出,si表示网络中间的预测输出:
In detail, 1x1 convolutional layers are performed on the multi-level feature maps before the Fusion Module to obtain a series of intermediate results.
实验细节
- Pytorch
- ResNet-101 and VGG-16. We initialize the layers of backbone with the weights pre-trained on ImageNet classification task and randomly initialize the rest layers.
- We follow source code of PiCA (Liu, Han, and Yang 2018) given by author and FQN (Li et al. 2019) and freeze the BatchNorm statistics of the backbone.
- Following the conventional practice (Liu, Han, and Yang 2018; Zhang et al. 2018a; 2018a), our proposed model is trained on the training set of DUTS dataset.
- We also perform a data augmentation similar to (Liu, Han, and Yang 2018) during training to mitigate the over-fitting problem.
- Specifically, the image is first resized to 300x300 and then a 256x256 image patch is randomly cropped from it.
- Random horizontal flipping is also applied.
- We use Adam optimizer to train our model without evaluation until the training loss convergences.
- The initial learning rate is set to 1e-4 and the overall training procedure takes about 16000 iterations.
- For testing, the images are scaled to 256x256 to feed into the network and then the predicted saliency maps are bilinearly interpolated to the size of the original image.
相关链接

若有收获,就点个赞吧
0 人点赞
