
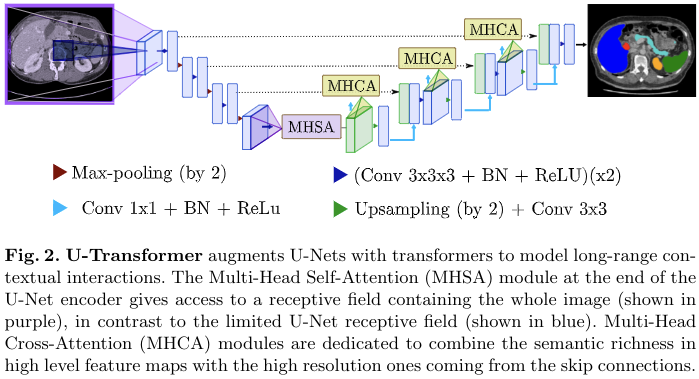
模型整体结构图
是一篇基于Transformer的医学分割任务的方法,所以这里主要关注于以下几个问题:
- 文章为什么要用Transformer(这里实际上反映的是Transformer可以起到的作用)
- 文章使用Transformer有什么特殊之处(实际上体现结构上的创意)
- 文章如何的训练策略如何(实际上对应着凸显Transformer有效性的策略)
- 文章的实验如何体现Transformer的有效性(同上)
为什么要用Transformer
FCNs suffer from conceptual limitations in complex segmentation tasks, e.g. when dealing with local visual ambiguities and low contrast between organs.
(U-Net) the limited receptive field framed in red does not capture sufficient contextual information, making the segmentation fail.实际上就是想办法围绕Transformer本身的优势,即利用全局上下文的能力,来组织文章的motivation,所以调U-Net的毛病的时候也是提到了说起CNN必会提到的一点,即有限的感受野。 另外,这里关于FCN类编码器解码器的结构的描述很不错,摘抄下来: the encoder extracts high-level semantic representations by using a cascade of convolutional layers, while the decoder leverages skip connections to re-use high-resolution feature maps from the encoder in order to recover lost spatial information from high-level representations.
U-Transformer overcomes the inability of U-Nets to model long-range contextual interactions and spatial dependencies, which are arguably crucial for accurate segmentation in challenging contexts.
Transformer结构、应用上的创新
:::info
本文没有直接使用完整的Transformer,仅仅是将Transformer中的Self-Attention和Cross-Attention拆了出来,保留了位置编码、两类Attention结构。
比较有意思的是使用Cross-Attention来生成门控值,这一点倒是可以看做是Attention U-Net (https://zhuanlan.zhihu.com/p/114471013) 的一种改进,即将计算自**由卷积获得的对应于局部信息的特征的门控改进为基于全局信息**构建的门控。
:::
U-Transformer keeps the inductive bias of convolution by using a U-shaped architecture, but introduces attention mechanisms at two main levels, which help to interpret the model decision.(写的挺好)
另外本文将这里的Cross-Attention看作是了一种自己和过往工作的不同,即之前的工作将注意力机制的使用限制在了Self-Attention上,而本文则使用Cross-Attention用在了改善空间和语义细节上。
Self-Attention
Firstly, a self-attention module leverages global interactions between semantic features at the end of the encoder to explicitly model full contextual information.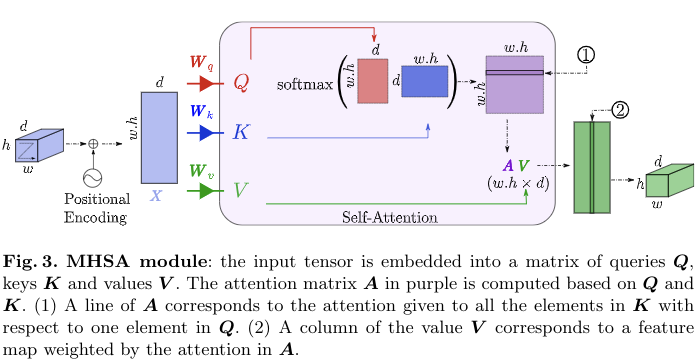
To account for absolute contextual information, a positional encoding is added to the input features.
It is especially relevant for medical image segmentation, where the different anatomical structures follow a fixed spatial position.
The positional encoding can thus be leveraged to capture absolute and relative position between organs in MHSA.
Cross-Attention (Global Attention Based Gating Operation)
Secondly, we introduce cross-attention in the skip connections to filter out non-semantic features, allowing a fine spatial recovery in the U-Net decoder.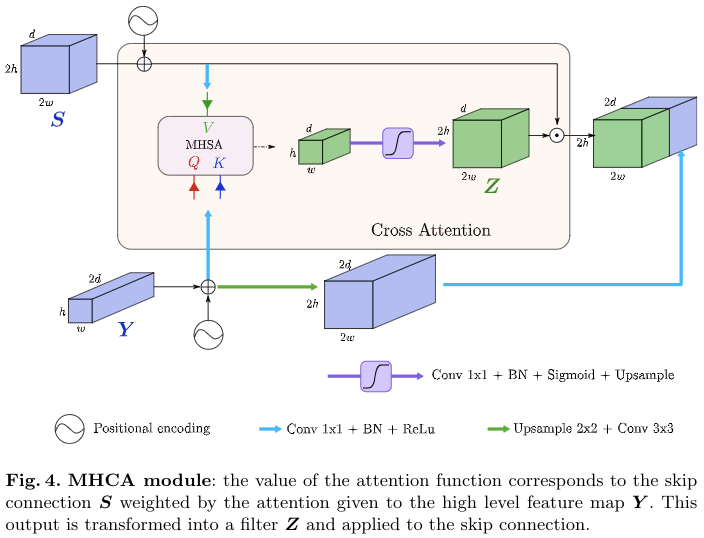
Attention may also be used to increase the U-Net decoder efficiency and in particular enhance the lower level feature maps that are passed through the skip connections.
Indeed, if these skip connections insure to keep a high resolution information, they lack the semantic richness that can be found deeper in the network.(用来说明不同层次特征的特性)
The idea behind the MHCA module is to turn off irrelevant or noisy areas from the skip connection features and highlight regions that present a signifcant interest for the application. 从跳层连接特征中排除无关或嘈杂的区域,并突出显示对应用具有重大意义的区域。
这里的MHCA模块被设计为一个类似与门控操作的结构,来对来自编码器的浅层特征进行a gating operation。这里得到的特征Z被视作一个过滤器,较低幅值的位置被视作噪声和不相关区域。
具体的训练策略

若有收获,就点个赞吧
0 人点赞
