
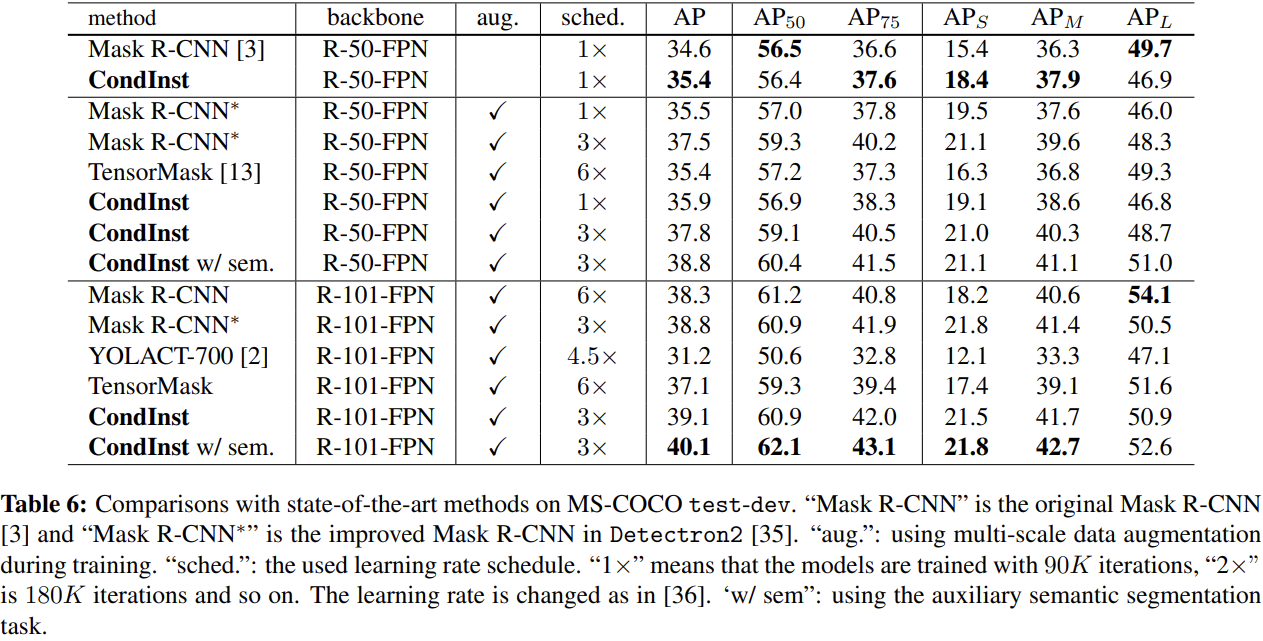
是一篇实例分割的论文,实在FCOS(一阶段的全卷积目标检测方法)的基础上改进的。看着对比实验,效果还不错。
前言
最近在关注VOS任务,对于如何处理不确定类别的多目标任务比较关心,所以翻了翻最近的论文,看到了这篇实例分割的任务。
在这篇文章中,不同于现有的mask-rcnn这一类依赖于ROI操作以及固定权重的网络来获得最终的instance mask,而是使用了特定的控制器controller来针对不同的实例生成特定的mask head的卷积核参数从而实现了instance-aware mask head。这将为各个instance分别进行mask的预测,该head的输出是单通道,经过sigmoid处理后,便可以获得针对该instance的的预测结果。
理解该文章,需要首先理解FCOS的设计:
- https://blog.csdn.net/WZZ18191171661/article/details/89258086
- FCOS官方代码详解(一):Architecture(backbone):https://blog.csdn.net/laizi_laizi/article/details/105479236
- FCOS官方代码详解(二):Architecture[head]:https://blog.csdn.net/laizi_laizi/article/details/105519290
- FCOS:一阶全卷积目标检测 - Jackpop的文章 - 知乎 https://zhuanlan.zhihu.com/p/63868458
第一次接触实例分割,有这几个问题有点疑惑: :::info
- 如何确定mask中实际应该有的instance的数量呢?
- 由proposal确定
- 如何将特定的参数与特定的instance对应起来?
- 参数是针对各个instance分别预测的,共同组合成一个
[num_instances, num_params]的数组
- 参数是针对各个instance分别预测的,共同组合成一个
- 由于与controller共同设置的还有一个分类器,这一个应该是用来确定实例类别的,但这又如何保证分类结果指定的类别与mask head分割的实例对应呢?
- 还是基于proposal?
如何应对多个实例相同类别的情况呢?
总结了基于ROI的设计思路的几个问题:
- Since ROIs are often axis-aligned bounding-boxes, for objects with irregular shapes, they may contain an excessive amount of irrelevant image content including background and other instances. This issue may be mitigated by using rotated ROIs, but with the price of a more complex pipeline.
- In order to distinguish between the foreground instance and the background stuff or instance(s), the mask head requires a relatively larger receptive field to encode sufficiently large context information. As a result, a stack of 3 × 3 convolutions is needed in the mask head (e.g., four 3 × 3 convolutions with 256 channels in Mask R-CNN). It considerably increases computational complexity of the mask head, resulting that the inference time significantly varies in the number of instances.
- ROIs are typically of different iszes. In order to use effective batched computation in modern deep learning frameworks, a resizing operation is often required to resize the cropped regions into pathces of the same size. For instance, Mask R-CNN resizes all the cropped regions to 14x14 (upsampled to 28x28 using a deconvolution), which restricts the output resolution of instance segmentation, as large instances would require higher resolutions to retain details at the boundary.
- 也总结了基于FCN处理实例分割任务主要问题:
- 基于FCN处理实例分割任务的主要难点在于,将FCNs应用于实例分割的主要困难在于相似的图像外观可能需要不同的预测,但FCNs难以实现这一点,例如,如果两个人外观相似,当预测A的mask的时候,FCN需要将B预测为相对于A的背景,这确实是困难的,因为他们外观上相似。
- 而基于ROI操作的方法,可以将关注的目标裁出来,例如如果预测A的时候,我们可以只扣出来A。
- 所以本文考虑使用instance-aware FCN来实现instance mask的预测。
实例分割需要两类信息:appearance information:分类目标;location information:区分属于相同类别的多个目标。当前几乎所有的方法都依赖于ROI剪裁的操作,这显示编码了实例的location information。而本文提出的CondInst方法则通过使用location/instance-sensitive convolution filters以及附加到原始特征上的相对坐标来利用location information。
提出的单阶段实例分割方法——CondInst
基于单阶段全卷积目标检测方法改进得到了单阶段实例分割方法,抛开了基于ROI(regions-of-interest)的模型设计策略,设计了instance-aware FCNs来实现instance mask的预测。从原来的通过ROI区分实例,改变到了现在的通过mask head的参数来区分实例。作者认为这份工作提供了一份Mask R-CNN之外的可以用来处理实例级检测任务的灵活的框架。
将现有的动态卷积的思路扩展到了更有挑战的实例分割任务上。
- 这样的设计的最终期望是网络的参数(滤波器)可以有效的编码特定实例的特性,并且仅仅关注于该目标的像素,这样就可以有效的应对前面FCN处理实例分割的问题。另外由于滤波器仅需要关注单个实例,这极大地减轻了学习需求和负担。
- 这些基于特定条件生成的conditional mask head可以被应用到整个特征图,这也避免了对于ROI操作和resize操作的需求,可以实现较灵活和准确的mask的预测。
- 通过有效而紧凑的设计,动态生成的FCN mask head可以实现超越之前的基于ROI的Mask RCNN方法,并且还相比于Mask R-CNN的mask head减少了很多的计算复杂度。As a result, the mask head can be extremely light-weight, significantly reducing the inference time per instance.
CondInst enjoys two advantages
- Instance segmentation is solved by a fully convolutional network, eliminating the need for ROI cropping and feature alignment.
Due to the much improved capacity of dynamically-generated conditional convolutions, the mask head can be very compact (e.g., 3 conv. layers, each having only 8 channels), leading to significantly faster inference.
相关工作
Mask R-CNN:该领域当之无愧的经典。首先应用目标检测器来检测实例的边界框,之后使用ROI操作来剪裁出特征图中的实例的特征。最终通过一个FCN结构获得想要的实例的mask。许多的方法都是基于这样的思路进一步改进和操作的。
- 也有尝试使用FCN来处理实例分割任务。InstanceFCN [17] 可能是第一个全卷积的实例分割方法。它通过普通的FCN预测一个位置敏感的得分图,之后将这些得分图被集成获得想要的instance mask。但是该方法对于重叠的实例会有问题。其他的方法试图通过首先进行分割任务,之后通过集成相同instance的像素来生成想要的instance mask。但是这些方法基本上没有能同时在精度和速度上超越mask r-cnn的方法。
- 最近的YOLACT和BlendMask可以看做是Mask R-CNN的变体,他们将ROI检测和用来预测mask的特征图进行解耦。SOLO设计了一个简单的基于FCN的实例分割方法,显示了具有竞争性的能力。PolarMask则是开发了一种新的mask的表示方法,来处理实例分割任务,它也是扩展了边界框检测器FCOS。最近的AdaptIS提出使用FiLM来解决全景分割任务,这个想法和CondInst共享了类似的想法,将实例信息编码到了FiLM生成的batch normalization的系数里,这也使得为了获得较好的预测,需要一个大的mask head来处理预测。相较而言,CondInst通过将信息编码到mask head卷积层的参数中,这将可以产生更加强大的能力和更加紧凑的结构。
网络结构
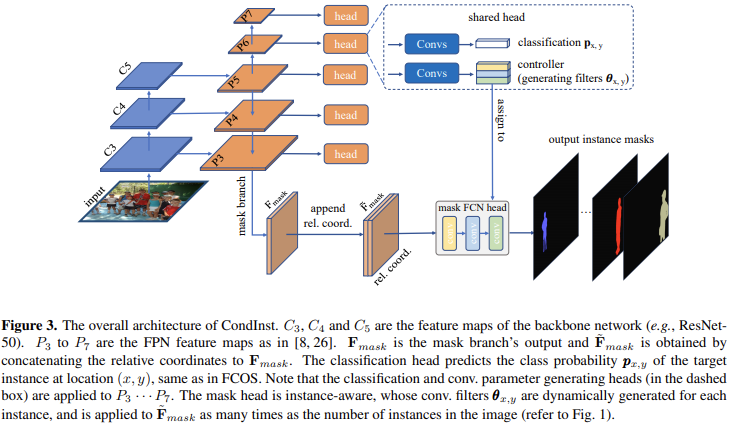
对于实例分割任务而言,用最常用的MS COCO举例。由于MS COCO的目标类别数量为80,所以这里最终的真值的mask可以定义为一个集合 ,这里的
,这里的 表示第i个实例的mask,并且
表示第i个实例的mask,并且 表示对应的类别(实例之间不会区分类别,只是给定的分割真值独立)。这也导致了实例分割不同于语义分割的一点,就是实际上最终预测的mask数量是不定的(因为这对应于图像中实例的数量)。
表示对应的类别(实例之间不会区分类别,只是给定的分割真值独立)。这也导致了实例分割不同于语义分割的一点,就是实际上最终预测的mask数量是不定的(因为这对应于图像中实例的数量)。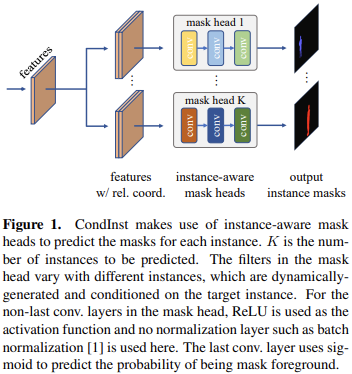
在这份工作中,对于包含K个实例的图像,将会生成K个不同的mask head,每个mask head将会把其对应的instance的特征包含到其滤波器参数中,从而更加关注于该instance的像素,生成对应的mask。这里也是该方法不同于mask rcnn的一点,后者将实例信息通过边界框来表示,而本文的CondInst则是显示编码其到mask head的参数中。这也可以更加灵活的处理不规则的形状,而这对于边界框来说稍显困难。
在网络处理的流程中,使用了FPN的结构来获取多尺度的特征,在FPN的每一层上,都使用了虚线框中的结构来实现实例相关的预测(例如目标实例的类别和动态生成的实例相关的滤波器参数),在这一点上,与Mask RCNN比较类似,都是先关注图像中的实例,然后预测实例的像素级掩码。Mask Branch的细节
与分割密切相关的mask分支(见图3,不是指那个mask head)被连接到FPN的P3上,因此它的输出分辨率是输入的1/8。mask分支在最后一层之前,包含四个3x3的有着128通道数的卷积层,最后一层卷积将特征的通道数从128降到了 ,这里的是一个超参数,最终选择使用8。这里处理后的特征表示为
,这里的是一个超参数,最终选择使用8。这里处理后的特征表示为 。
```python
。
```python为了关注核心内容,这里删掉了语义分割任务的代码
class MaskBranch(nn.Module): def init(self, cfg, inputshape: Dict[str, ShapeSpec]): super()._init() self.in_features = ( cfg.MODEL.CONDINST.MASK_BRANCH.IN_FEATURES ) # [“p3”, “p4”, “p5”] self.sem_loss_on = cfg.MODEL.CONDINST.MASK_BRANCH.SEMANTIC_LOSS_ON # False self.num_outputs = cfg.MODEL.CONDINST.MASK_BRANCH.OUT_CHANNELS # 8 norm = cfg.MODEL.CONDINST.MASK_BRANCH.NORM # “BN” num_convs = cfg.MODEL.CONDINST.MASK_BRANCH.NUM_CONVS # 4 channels = cfg.MODEL.CONDINST.MASK_BRANCH.CHANNELS # 128 self.out_stride = input_shape[self.in_features[0]].stride
feature_channels = {k: v.channels for k, v in input_shape.items()}conv_block = conv_with_kaiming_uniform(norm, activation=True)self.refine = nn.ModuleList() # 用来对self.in_features指定的特征进行融合前的卷积处理for in_feature in self.in_features:self.refine.append(conv_block(feature_channels[in_feature], channels, 3, 1))tower = []for i in range(num_convs):tower.append(conv_block(channels, channels, 3, 1))tower.append(nn.Conv2d(channels, max(self.num_outputs, 1), 1))self.add_module("tower", nn.Sequential(*tower)) # 对整合了P5、P4的P3特征进行处理def forward(self, features, gt_instances=None):for i, f in enumerate(self.in_features): # self.in_features=["p3", "p4", "p5"]if i == 0:x = self.refine[i](features[f])else:x_p = self.refine[i](features[f])target_h, target_w = x.size()[2:]h, w = x_p.size()[2:]assert target_h % h == 0assert target_w % w == 0factor_h, factor_w = target_h // h, target_w // wassert factor_h == factor_wx_p = aligned_bilinear(x_p, factor_h) # 上采样到P3的尺寸x = x + x_pmask_feats = self.tower(x)if self.num_outputs == 0: # 实际中不会进入,因为self.num_outputs=8mask_feats = mask_feats[:, : self.num_outputs]return mask_feats, losses
之后**将上的所有位置相对于_mask head的参数所对应的位置_的相对位置信息(坐标偏移数据)添加(拼接)到原始特征图上**,这样的操作为最终推理mask提供了a strong cue。最终得到包含了位置和外观信息的特征图。```pythondef compute_locations(h, w, stride, device):"""计算对于下采样stride倍后,特征分辨率为(h,w)的特征上的各点在原图上的映射坐标实际上就是论文中提到的坐标映射公式:$(\lfloor \frac{s}{2} \rfloor + x \times s, \lfloor \frac{s}{2} \rfloor + y \times s)$输出的形状为 [hxw, 2]"""# x \times sshifts_x = torch.arange(0, w * stride, step=stride,dtype=torch.float32, device=device)# y \times sshifts_y = torch.arange(0, h * stride, step=stride,dtype=torch.float32, device=device)shift_y, shift_x = torch.meshgrid(shifts_y, shifts_x)shift_x = shift_x.reshape(-1)shift_y = shift_y.reshape(-1)# stride // 2: \lfloor \frac{s}{2} \rfloorlocations = torch.stack((shift_x, shift_y), dim=1) + stride // 2return locationsclass DynamicMaskHead(nn.Module):......def mask_heads_forward_with_coords(self, mask_feats, mask_feat_stride, instances):"""考虑相对坐标关系的前提下,计算 maskmask_feats: 对应于所有图像的 mask 特征mask_feat_stride: 对应当前 mask feat 对应的 strideinstances: 包含着当前 batch 中所有实例的信息"""# 计算当前尺度的特征图映射到原图上的坐标# 输出形状为[mask_feats.size(2) * mask_feats.size(3), 2]locations = compute_locations(mask_feats.size(2), mask_feats.size(3),stride=mask_feat_stride, device=mask_feats.device)# 实例的数量n_inst = len(instances)# 获取实例所属的图像的索引和实例对应的 mask head 的参数im_inds = instances.im_indsmask_head_params = instances.mask_head_paramsN, _, H, W = mask_feats.size()if not self.disable_rel_coords: # 这个在测试的时候还使用么???# 所有实例对应的位置instance_locations = instances.locations# 使用各个实例的位置 减去 当前特征图上其他所有位置对应于原图的坐标([HW, 2] -> [1, HW, 2])# 从而获得HW个像素位置相对特定实例的相对坐标 [n_inst, HW, 2]relative_coords = \instance_locations.reshape(-1, 1, 2) - locations.reshape(1, -1, 2)# [n_inst, HW, 2] -> [n_inst, 2, HW]relative_coords = relative_coords.permute(0, 2, 1).float()# 这个的用处暂不清楚???soi = self.sizes_of_interest.float()[instances.fpn_levels]relative_coords = relative_coords / soi.reshape(-1, 1, 1)relative_coords = relative_coords.to(dtype=mask_feats.dtype)# 通过拼接相对坐标和对应图像的mask特征([n_inst, self.in_channels, H * W])# 得到包含位置信息的特征mask_head_inputs = torch.cat([relative_coords, mask_feats[im_inds].reshape(n_inst, self.in_channels, H * W)], dim=1)else:mask_head_inputs = mask_feats[im_inds].reshape(n_inst, self.in_channels, H * W)
将得到的特征图送到mask head中,最终使用一个单一的sigmoid函数来生成最终的mask head的预测。
:::info
如何二值化呢?
:::
最终该实例的类别通过使用图三中虚线框中与mask head对应的controller并行的classification head获取。所以这里的mask的预测也是class-agnostic。
这里得到的预测的mask,实际上分辨率是输入的1/8,所以为了获得更高分辨率的mask,会使用一个双线性插值来将mask上采样4倍,最终是对应于输入的1/2。
与FCOS相似,对于FPN的特征图 上的每个位置都关联着一个实例,要么是正样本,要么是负样本。
上的每个位置都关联着一个实例,要么是正样本,要么是负样本。
实例与位置关联
每个位置关联的实例会以如下方式判断:
- 对于特征图
 ,假定其对应的下采样率为
,假定其对应的下采样率为 。对于该特征图上的位置
。对于该特征图上的位置 ,可以映射到原图的
,可以映射到原图的 位置。
位置。 - 如果映射的位置落到了一个实例(由真值判定:https://blog.csdn.net/WZZ18191171661/article/details/89258086#t5)的中心区域,这个位置便被认为对该实例负责。任何在实例中心区域之外的位置被标记为负样本,
中心区域被定义为一个方形区域:
 ,即一个以
,即一个以 为中心(实际表示实例的mass center,质心)的边长为
为中心(实际表示实例的mass center,质心)的边长为 的方形区域。这里的
的方形区域。这里的 表示一个常量,按照FCOS的设定,使用1.5。而表示对应于当前层级
表示一个常量,按照FCOS的设定,使用1.5。而表示对应于当前层级 的下采样率。
的下采样率。
不同的head结构
从图3中可以看到,主要包含三个head结构,classification head、controller head、mask head。
classification head
- 针对每个位置预测与之关联的实例的类别,仍以所以这里输出的logits尺寸应该为HxWxC,这里会使用C(这里的C是实际的类别数量)个二元分类来对C维矢量进行分类。而对应的真值是实例的类别
 或者是0(即背景类)。
或者是0(即背景类)。
- 针对每个位置预测与之关联的实例的类别,仍以所以这里输出的logits尺寸应该为HxWxC,这里会使用C(这里的C是实际的类别数量)个二元分类来对C维矢量进行分类。而对应的真值是实例的类别
- controller head
- 这个head的架构和classification head是相同的,用来生成mask head针对特定位置上实例的卷积层的参数。
- 为了预测滤波器,这里会将所有的滤波器的参数(权重和偏置参数)拼接成一个单独的N维矢量
 ,而这里的N表示参数的总数。所以这里的controller head会有N个输出通道,正如之前提到的,这里的mask head的参数量很少,实际也就是169个参数。
,而这里的N表示参数的总数。所以这里的controller head会有N个输出通道,正如之前提到的,这里的mask head的参数量很少,实际也就是169个参数。- 1个(8+2)x1x1x8的卷积层,该卷积层的输入会拼接8通道的mask branch提取的特征和单独计算获得的2通道相对坐标信息,总共10通道
- 1个8x1x1x8的卷积层
- 1个8x1x1x1的卷积层
- 总共参数量:1(1011+1)8+1(811+1)8+1(811+1)1) = 169
- 这种形式的结构,使得mask head充分降低了参数,减少了计算复杂度。
- mask head
- 仅仅使用卷积和relu操作,不使用batch normalizatoin。
- 最终使用sigmoid生成属于特定前景目标的概率。
- 这些生成的滤波器中包含了特定位置上的实例的信息,这样的mask head也将会更加关注于该实例的像素区域,甚至是输入完整的特征图。
- center-ness head
- 该结构通过预测一个标量数据来表示目标实例的位置到中心的偏差成程度,这个结果被用来乘到分类得分上,并且也被用在NMS上来移除重复的检测。
- 这里的设定和FCOS是一致的。
边界框的使用
 表示位置
表示位置 的分类标签,大于0表示该像素是与某个实例相关联的,而等于0表示不属于任何实例,即背景。
的分类标签,大于0表示该像素是与某个实例相关联的,而等于0表示不属于任何实例,即背景。 表示
表示 的位置数量。
的位置数量。 表示一个指示函数,满足条件时结果为1,否则为0。
表示一个指示函数,满足条件时结果为1,否则为0。- 表示对于该位置的生成的滤波器参数。
 表示拼接了两通道的相对坐标(特征图上其他位置在原图的映射坐标相对于当前关注的位置在原图坐标的差值)数据的特征图,会被送入mask head中。
表示拼接了两通道的相对坐标(特征图上其他位置在原图的映射坐标相对于当前关注的位置在原图坐标的差值)数据的特征图,会被送入mask head中。 表示关联于位置的实例的mask真值。这里的最终会被下采样1/2来保证和预测的mask尺寸相同。
表示关联于位置的实例的mask真值。这里的最终会被下采样1/2来保证和预测的mask尺寸相同。这里最后使用了dice loss来计算实例预测和真值mask之间的差异。
推理细节
输入图片,通过网络获得分类的置信度
 ,center-ness scores,检测框的预测
,center-ness scores,检测框的预测 ,和生成的滤波器参数。
,和生成的滤波器参数。- 首先遵循FCOS的流程获得预测的边界框。
- box-based NMS使用阈值0.6来移除重复的检测,然后选择最优的100个边界框(即,实例。这些都对应着一个个的实例),这些会被用来计算mask。
- 假设处理后还有K个边界框,所以需要生成K组滤波器。
这K组滤波器会被用到实例特定的mask head处理特征,生成预测。由于该结构本身就很紧凑,所以即使有100个检测(这是MS-COCO每张图片的最大检测数量),也非常的快速。
实验细节
Following FCOS [8], ResNet-50 [33] is used as our backbone network and the weights pre-trained on ImageNet [34] are used to initialize it. For the newly added layers, we initialize them as in [8].
- Our models are trained with stochastic gradient descent (SGD) over 8 V100 GPUs for 90K iterations with the initial learning rate being 0.01 and a mini-batch of 16 images.
- The learning rate is reduced by a factor of 10 at iteration 60K and 80K, respectively.
- Weight decay and momentum are set as 0.0001 and 0.9, respectively.
- Following Detectron2 [35], the input images are resized to have their shorter sides in [640, 800] and their longer sides less or equal to 1333 during training. Left-right flipping data augmentation is also used during training.
- When testing, we do not use any data augmentation and only the scale of the shorter side being 800 is used.
- The inference time in this work is measured on a single V100 GPU with 1 image per batch.
 用来表示当前位置到实例边界框的四条边的距离。
用来表示当前位置到实例边界框的四条边的距离。 得到。所以不需要额外的标注。
得到。所以不需要额外的标注。
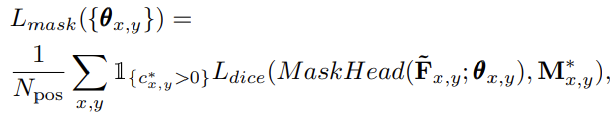
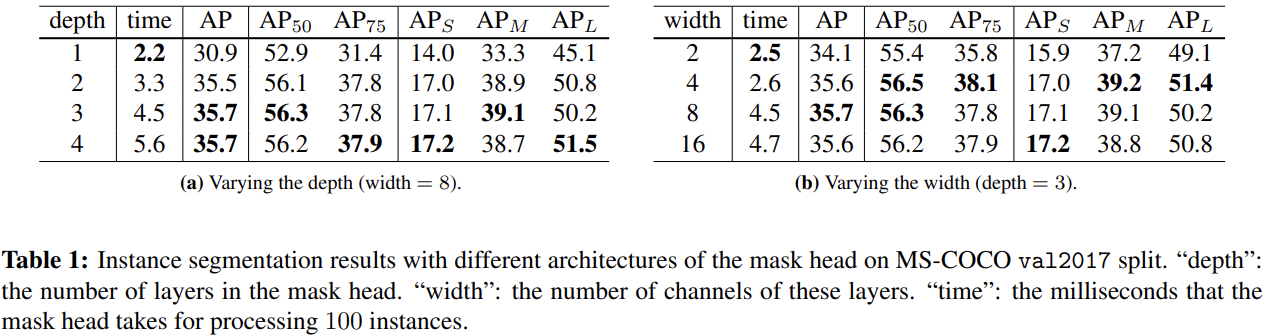
关于不同mask head配置的一些比较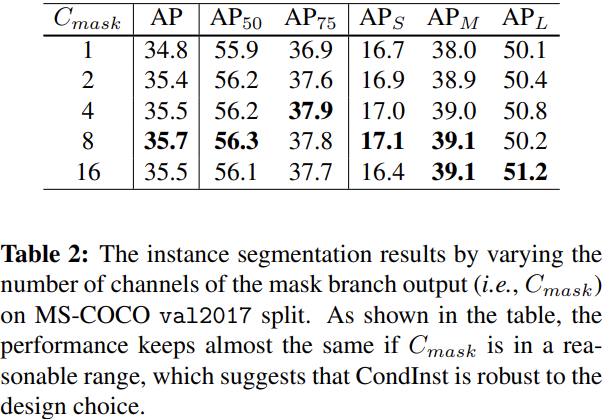
关于mask branch输出通道数的不同设置的比较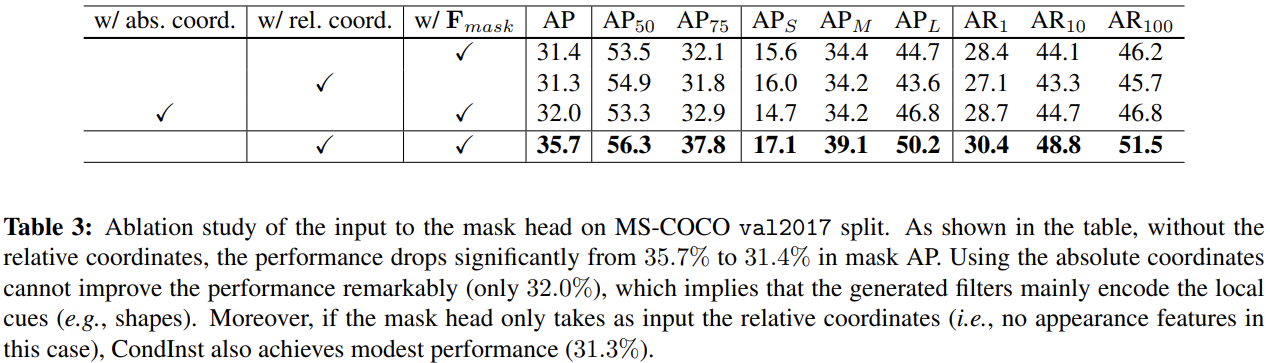
使用相对坐标信息的有效性,这里有意思的一点是仅适用相对坐标效果也是可以的
The significant performance drop implies that the generated filters not only encode the appearance cues but also encode the shape of the target instance. It can also be evidenced by the experiment only using the relative coordinates. We would like to highlight that unlike Mask R-CNN, which encodes the shape of the target instance by a bounding-box, CondInst implicitly encodes the shape into the generated filters, which can easily represent any shapes including irregular ones and thus is much more flexible.
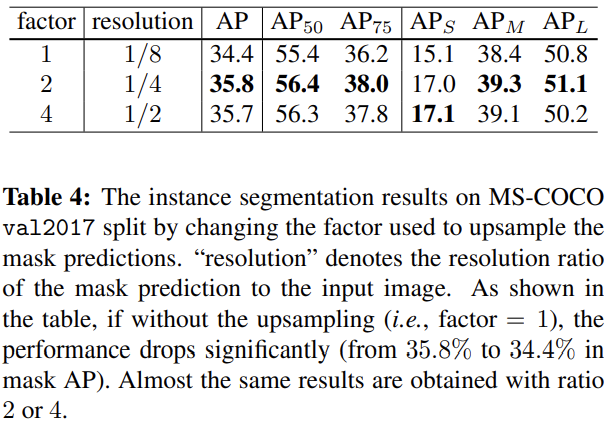
比较了网络输出分辨率的影响,可见必要的上采样是合理的,但是网络中使用的factor是4,但是没有使用这里看起来性能更好的2。
We use factor = 4 in all other models as it has the potential to produce highresolution instance masks.
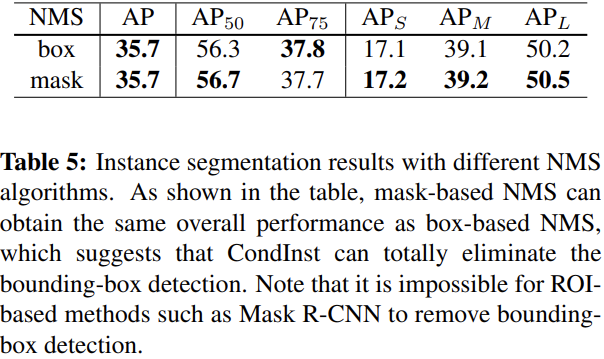
代码分析
classification/controller/center-ness/reg_bbox head
一些常量的实际设定值我用注释的形式标了出来。
class FCOSHead(nn.Module):def __init__(self, cfg, input_shape: List[ShapeSpec]):"""Arguments:in_channels (int): number of channels of the input feature"""super().__init__()# TODO: Implement the sigmoid version first.self.num_classes = cfg.MODEL.FCOS.NUM_CLASSESself.fpn_strides = cfg.MODEL.FCOS.FPN_STRIDEShead_configs = {"cls": (cfg.MODEL.FCOS.NUM_CLS_CONVS,cfg.MODEL.FCOS.USE_DEFORMABLE,), # 4, False"bbox": (cfg.MODEL.FCOS.NUM_BOX_CONVS,cfg.MODEL.FCOS.USE_DEFORMABLE,), # 4, False"share": (cfg.MODEL.FCOS.NUM_SHARE_CONVS, False), # 0, False}norm = None if cfg.MODEL.FCOS.NORM == "none" else cfg.MODEL.FCOS.NORMself.num_levels = len(input_shape)in_channels = [s.channels for s in input_shape]assert len(set(in_channels)) == 1, "Each level must have the same channel!"in_channels = in_channels[0]self.in_channels_to_top_module = in_channelsfor head in head_configs:tower = []num_convs, use_deformable = head_configs[head]for i in range(num_convs):if use_deformable and i == num_convs - 1:conv_func = DFConv2delse:conv_func = nn.Conv2dtower.append(conv_func(in_channels,in_channels,kernel_size=3,stride=1,padding=1,bias=True,))if norm == "GN":tower.append(nn.GroupNorm(32, in_channels))elif norm == "NaiveGN":tower.append(NaiveGroupNorm(32, in_channels))elif norm == "BN":tower.append(ModuleListDial([nn.BatchNorm2d(in_channels)for _ in range(self.num_levels)]))elif norm == "SyncBN":tower.append(ModuleListDial([NaiveSyncBatchNorm(in_channels)for _ in range(self.num_levels)]))tower.append(nn.ReLU())self.add_module("{}_tower".format(head), nn.Sequential(*tower))# classification/bbox_pred/centerness head的预测层self.cls_logits = nn.Conv2d(in_channels, self.num_classes, kernel_size=3, stride=1, padding=1)self.bbox_pred = nn.Conv2d(in_channels, 4, kernel_size=3, stride=1, padding=1)self.ctrness = nn.Conv2d(in_channels, 1, kernel_size=3, stride=1, padding=1)if cfg.MODEL.FCOS.USE_SCALE:# 否对各层的bbox_pred使用可学习的放缩因子(初始值设置为1)self.scales = nn.ModuleList([Scale(init_value=1.0) for _ in range(self.num_levels)])else:self.scales = Nonefor modules in [self.cls_tower,self.bbox_tower,self.share_tower,self.cls_logits,self.bbox_pred,self.ctrness,]:for l in modules.modules():if isinstance(l, nn.Conv2d):torch.nn.init.normal_(l.weight, std=0.01)torch.nn.init.constant_(l.bias, 0)# initialize the bias for focal lossprior_prob = cfg.MODEL.FCOS.PRIOR_PROBbias_value = -math.log((1 - prior_prob) / prior_prob)torch.nn.init.constant_(self.cls_logits.bias, bias_value)def forward(self, x, top_module=None, yield_bbox_towers=False):"""根据输入的FPN的多层级的特征,使用共享的多头结构进行相关的预测,包括1. 分类logits、list([N, C, H, W])2. bbox回归参数、list([N, 4, H, W])3. centerness得分、list([N, 1, H, W])4. controller得到的特征、list([N, num_gen_params, H, W])5. 共享的bbox特征提取结构生成的特征 list([N, in_channels, H, W])"""logits = []bbox_reg = []ctrness = []top_feats = []bbox_towers = []for l, feature in enumerate(x):# 使用共享的head来处理FPN不同层级的featurefeature = self.share_tower(feature) # 这个是多个分支共享的结构,CondInst实际上没用到cls_tower = self.cls_tower(feature) # 这个是分类分支单独的特征处理结构bbox_tower = self.bbox_tower(feature) # 这个是bbox回归分支单独的特征处理结构if yield_bbox_towers: # 是否要收集各层级共享的bbox特征提取结构生成的特征bbox_towers.append(bbox_tower)logits.append(self.cls_logits(cls_tower)) # 收集各层级预测得到的logitsctrness.append(self.ctrness(bbox_tower)) # 收集各层级预测得到的centerness得分reg = self.bbox_pred(bbox_tower) # 获得当前层级的bbox预测if self.scales is not None:reg = self.scales[l](reg) # 对预测的bbox进行可学习的放缩# Note that we use relu, as in the improved FCOS, instead of exp.bbox_reg.append(F.relu(reg)) # 收集各层级预测得到bbox预测if top_module is not None:top_feats.append(top_module(bbox_tower)) # 这里可以添加额外的top_module来借助bbox_tower特征生成与实例相关的特征# 对于CondInst,这里的top_module就是controllerreturn logits, bbox_reg, ctrness, top_feats, bbox_towers
Mask Head
def dice_coefficient(x, target):"""x: [n_inst, 1, H * int(mask_feat_stride / self.mask_out_stride),W * int(mask_feat_stride / self.mask_out_stride)]"""eps = 1e-5n_inst = x.size(0)x = x.reshape(n_inst, -1)target = target.reshape(n_inst, -1)intersection = (x * target).sum(dim=1)union = (x ** 2.0).sum(dim=1) + (target ** 2.0).sum(dim=1) + epsloss = 1. - (2 * intersection / union)return lossdef parse_dynamic_params(params, channels, weight_nums, bias_nums):"""解析 mask head 的参数获得 weight 和 biasparams: [num_insts, num_params]channels: 卷积核个数weight_nums: mask head 各个卷积层对应的权重参数数量列表 (self.num_layers*[1*1*in_channels*out_channels])bias_nums: mask head 各个卷积层对应的bias参数数量列表 (self.num_layers*[out_channels])"""assert params.dim() == 2assert len(weight_nums) == len(bias_nums)assert params.size(1) == sum(weight_nums) + sum(bias_nums)num_insts = params.size(0)num_layers = len(weight_nums)# 按照列表中的各个值划分params为新的参数列表params_splits = list(torch.split_with_sizes(params, weight_nums + bias_nums, dim=1))# 获取各层的权重分组和bias分组weight_splits = params_splits[:num_layers]bias_splits = params_splits[num_layers:]for l in range(num_layers): # 将参数变形为各层实际需要的形状if l < num_layers - 1:# out_channels x in_channels x 1 x 1weight_splits[l] = weight_splits[l].reshape(num_insts * channels, -1, 1, 1)bias_splits[l] = bias_splits[l].reshape(num_insts * channels)else:# out_channels x in_channels x 1 x 1weight_splits[l] = weight_splits[l].reshape(num_insts * 1, -1, 1, 1)bias_splits[l] = bias_splits[l].reshape(num_insts)# weight_splits: length=num_layers, item=[num_insts * channels, in_channels, 1, 1]# bias_splits: length=num_layers, item=[num_insts * channels]return weight_splits, bias_splitsdef build_dynamic_mask_head(cfg):return DynamicMaskHead(cfg)class DynamicMaskHead(nn.Module):"""这实际上实在针对多个实例进行计算,这里的4D的tensor的第一个维度是表示不同的实例"""def __init__(self, cfg):super(DynamicMaskHead, self).__init__()self.num_layers = cfg.MODEL.CONDINST.MASK_HEAD.NUM_LAYERS # 3self.channels = cfg.MODEL.CONDINST.MASK_HEAD.CHANNELS # 8self.in_channels = cfg.MODEL.CONDINST.MASK_BRANCH.OUT_CHANNELS # 8self.mask_out_stride = cfg.MODEL.CONDINST.MASK_OUT_STRIDE # 4self.disable_rel_coords = cfg.MODEL.CONDINST.MASK_HEAD.DISABLE_REL_COORDS # Falsesoi = cfg.MODEL.FCOS.SIZES_OF_INTEREST # [64, 128, 256, 512]self.register_buffer("sizes_of_interest", torch.tensor(soi + [soi[-1] * 2]))weight_nums, bias_nums = [], []for l in range(self.num_layers):if l == 0: # 是否对 mask head 的初始输入特征附加相对坐标信息if not self.disable_rel_coords:weight_nums.append((self.in_channels + 2) * self.channels)else:weight_nums.append(self.in_channels * self.channels)bias_nums.append(self.channels)elif l == self.num_layers - 1: # mask head 的最后一层卷积,这里输出是单通道的weight_nums.append(self.channels * 1)bias_nums.append(1)else: # mask head 的其他的卷积层weight_nums.append(self.channels * self.channels)bias_nums.append(self.channels)self.weight_nums = weight_numsself.bias_nums = bias_numsself.num_gen_params = sum(weight_nums) + sum(bias_nums)def mask_heads_forward(self, features, weights, biases, num_insts):'''使用指定的 weight 和 bias 来卷积处理特征features: [n_inst, C'mask, H, W]weights: length=num_layers, item=[num_insts * channels, in_channels, 1, 1]bias: length=num_layers, item=[num_insts * channels]因为这里使用的是分组卷积,会对输入通道按照实例数进行分组,所以输入的时候,直接所有实例都叠加到一起了return [1, num_insts, H, W]'''assert features.dim() == 4n_layers = len(weights)x = featuresfor i, (w, b) in enumerate(zip(weights, biases)):x = F.conv2d(x,w,bias=b,stride=1,padding=0,groups=num_insts # 根据实例数量进行分组卷积,不同的参数只应用于特定的实例组# 按照这一点,表示不同实例的维度应该是通道维度)if i < n_layers - 1: # 只有最后一层不使用relux = F.relu(x)return xdef mask_heads_forward_with_coords(self, mask_feats, mask_feat_stride, instances):"""考虑相对坐标关系的前提下,计算 maskmask_feats: 对应于所有图像的 mask 特征mask_feat_stride: 对应当前 mask feat 对应的 strideinstances: 包含着当前 batch 中所有实例的信息"""# 计算当前尺度的特征图映射到原图上的坐标# 输出形状为[mask_feats.size(2) * mask_feats.size(3), 2]locations = compute_locations(mask_feats.size(2), mask_feats.size(3),stride=mask_feat_stride, device=mask_feats.device)# 实例的数量n_inst = len(instances)# 获取实例所属的图像的索引和实例对应的 mask head 的参数im_inds = instances.im_indsmask_head_params = instances.mask_head_paramsN, _, H, W = mask_feats.size()if not self.disable_rel_coords: # 这个在测试的时候还使用么???# 所有实例对应的位置instance_locations = instances.locations# 使用各个实例的位置 减去 当前特征图上其他所有位置对应于原图的坐标([HW, 2] -> [1, HW, 2])# 从而获得HW个像素位置相对特定实例的相对坐标 [n_inst, HW, 2]relative_coords = \instance_locations.reshape(-1, 1, 2) - locations.reshape(1, -1, 2)# [n_inst, HW, 2] -> [n_inst, 2, HW]relative_coords = relative_coords.permute(0, 2, 1).float()# 这个的用处暂不清楚???soi = self.sizes_of_interest.float()[instances.fpn_levels]relative_coords = relative_coords / soi.reshape(-1, 1, 1)relative_coords = relative_coords.to(dtype=mask_feats.dtype)# 通过拼接相对坐标和对应图像的mask特征([n_inst, self.in_channels, H * W])# 得到包含位置信息的特征mask_head_inputs = torch.cat([relative_coords, mask_feats[im_inds].reshape(n_inst, self.in_channels, H * W)], dim=1)else:mask_head_inputs = mask_feats[im_inds].reshape(n_inst, self.in_channels, H * W)# [n_inst, self.in_channels, H * W] -> [1, n_inst * C'mask, H, W]mask_head_inputs = mask_head_inputs.reshape(1, -1, H, W)# [num_insts, num_params] -># weights: length=num_layers, item=[num_insts * channels, in_channels, 1, 1]# biases: length=num_layers, item=[num_insts * channels]weights, biases = parse_dynamic_params(mask_head_params, self.channels,self.weight_nums, self.bias_nums)# 使用实例级别的参数来计算得到实例级别的mask# [1, n_inst * C'mask, H, W] -> [1, n_inst, H, W]mask_logits = self.mask_heads_forward(mask_head_inputs, weights, biases, n_inst)# [1, n_inst, H, W] -> [n_inst, 1, H, W]mask_logits = mask_logits.reshape(-1, 1, H, W)assert mask_feat_stride >= self.mask_out_strideassert mask_feat_stride % self.mask_out_stride == 0# [n_inst, 1, H, W] -># [n_inst, 1, H * int(mask_feat_stride / self.mask_out_stride),# W * int(mask_feat_stride / self.mask_out_stride)]mask_logits = aligned_bilinear(mask_logits, \int(mask_feat_stride / self.mask_out_stride))return mask_logits.sigmoid()def __call__(self, mask_feats, mask_feat_stride, pred_instances, gt_instances=None):if self.training:gt_inds = pred_instances.gt_inds# [len(gt_instances), n_inst,# H * int(mask_feat_stride / self.mask_out_stride),# W * int(mask_feat_stride / self.mask_out_stride)]gt_bitmasks = torch.cat([per_im.gt_bitmasks for per_im in gt_instances])# [n_inst, H * int(mask_feat_stride / self.mask_out_stride),# W * int(mask_feat_stride / self.mask_out_stride)] -># [n_inst, 1, H * int(mask_feat_stride / self.mask_out_stride),# W * int(mask_feat_stride / self.mask_out_stride)]gt_bitmasks = gt_bitmasks[gt_inds].unsqueeze(dim=1).to(dtype=mask_feats.dtype)# 从上面的三行代码中我大致推测:# gt_instances包含了整个batch图片对应的信息,其中每一项表示单个图片的信息,该信息中包含着真值的二值mask(gt_bitmasks)# gt_bitmasks中包含着不同实例对应的完整的mask信息# pred_instances包含了从proposal中得到的实例信息,这部分信息应该主要来自于proposal与真值的对应关系# pred_instances.gt_inds 表示当前预测的实例对应的真值mask的编号if len(pred_instances) == 0:loss_mask = mask_feats.sum() * 0 + pred_instances.mask_head_params.sum() * 0else:mask_scores = self.mask_heads_forward_with_coords(mask_feats, mask_feat_stride, pred_instances)# 计算针对各个实例的dice loss(各个实例的mask的预测都是整图大小的)mask_losses = dice_coefficient(mask_scores, gt_bitmasks)# 对所有实例进行平均loss_mask = mask_losses.mean()return loss_mask.float()else:if len(pred_instances) > 0:mask_scores = self.mask_heads_forward_with_coords(mask_feats, mask_feat_stride, pred_instances)pred_instances.pred_global_masks = mask_scores.float()# 这边出去之后,必然需要考虑如何整合所有实例的mask到一张图上return pred_instances
相关链接

若有收获,就点个赞吧
0 人点赞
