前言
准备回顾三篇RGBD的分割的文章,这三篇内容有些关联,所以一起介绍似乎更合适一些。
- (ECCV 2018)Depth-aware cnn for rgb-d segmentation
- (CVPR 2018)Surfconv: Bridging 3d and 2d convolution for rgbd images)
- (3DV 2019)3D Neighborhood Convolution: Learning Depth-Aware Features for RGB-D and RGB Semantic Segmentation
对于RGBD任务的思考
这实际上是一个跨模态的任务,大量的实验证明了,对于RGB图像分割任务附加Depth信息,可以为目标引入几何信息,使用得当,是可以实现性能的一致提升。
但是如何利用Depth信息这是很多研究在尝试探索的地方。现有的方式按照Depth-aware cnn for rgb-d segmentation和我个人的了解,主要有如下几种:
- 将Depth当做与RGB同等地位的输入
- Depth与RGB图像直接构成RGBD四通道数据送入网络
- 一些工作将Depth编码为三通道HHA(horizontal disparity, height above ground, and norm angle)图像,并且二者分别送入各自的独立的网络中进行处理,之后会进行特征或者预测的交互融合
- 弊端:这样的设定,相较于传统的2D卷积,会导致网络参数成倍增长,前向传播时间也会增长
- 补充:似乎没有提到单独使用Depth通道作为另一个独立网路的输入?
- 使用3D卷积网络来充分利用像素之间的几何关系,主要方法有volumetric CNN和3D点云图网络
- 将Depth当做RGB信息流的补充与约束
- 使用优化过的Depth来增强RGB的特征:CPFP: Contrast Prior and Fluid Pyramid Integration for RGBD Salient Object Detection
但是,当我们对网络输入了需要的数据,我们又该如何更好的操作和利用这些数据呢?有人就开始在CNN上“动手脚”了。
这里考虑到了卷积的运算过程,可以表示为如下加权求和形式:
对于平均池化操作,也是可以表示为如下操作:
对于2D平面,感受野可以表示为:(这里展示了以(pi,pj)为中心的一个区间)
而对于3D卷积而言,感受野进一步变成了:(这里展示了以(pi,pj)为中心的一个区间)
三篇文章的改造策略略有不同(一样还怎么发论文:))
- Depth-aware cnn for rgb-d segmentation:对运算利用深度信息上的距离关系进行重加权,池化亦是如此
- 3D Neighborhood Convolution: Learning Depth-Aware Features for RGB-D and RGB Semantic Segmentation使用了类似的构造,但是略有修改,对采样区域进行了调整:
-




- 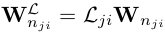- 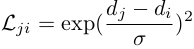- 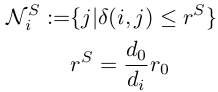

- Surfconv: Bridging 3d and 2d convolution for rgbd images)主要是针对卷积运算的采样区域(感受野)进行了调整
- 对于感受野R,这里提出了一个Local Planarity Assumption,相当于将该区域特征对应的深度坐标统一表示为中心元素的深度坐标,即认为同一采样区域的特征有着相同的深度



若有收获,就点个赞吧
0 人点赞
