
- 原始文档:https://www.yuque.com/lart/papers/gd07c1
- 论文:https://arxiv.org/abs/2205.13213
- 代码:https://github.com/zip-group/LITv2
核心动机
现有的ViT方法,模型有效性的设计基本上都是由一些间接反映计算复杂度的指标来引导的,例如FLOPs,然而这和直接的指标,例如模型的吞吐量等有着明显的差异。这篇文章则是尝试使用目标平台上更直接的速度评估作为模型有效性的设计原则。
这样的前提下,作者们提出了一个简单有效的架构,LITv2。其主要延续了图像分高低频处理局部细节和全局结构的传统图像处理的思想。具体来说,将注意力的多个头拆分成了两组,一组用于在局部窗口中关注于更加细节的高频信息,而另一组则基于query与平均池化下采样后得到的低频信息主导的k和v的交互,从而建模全局关系。基于双分支处理且并未引入复杂的变换操作而构建的HiLo操作展现出了良好的性能和效率。现有方法
深度学习的落地需要模型在算力有限的条件下,具有良好的速度和精度的权衡。然而现有的ViT架构大多在考虑模型的效率的时候,主要关注与一些间接地评价指标,例如FLOPs。然而这并不能直接反映出目标平台上的真实速度。作者对此总结道,之所以在ViT上这些间接的指标和直接的速度指标之间具有这么大的差异,主要是因为ViT所依赖的自注意力机制相较于以往的标准算子而言比较特殊:
- 由于密集的内存访问成本,内存和时间的平方级别的复杂度使得其在高分辨率图像上较慢,从芯片外的DRAM获取数据可能比较耗时。
- 虽然现在出现了不少的“有效”的注意力机制,但是其理论上较低的复杂度和实际上较慢的运行速度形成了对比。这主要是因为特定操作并非是硬件友好的,或者无法并行处理,从而拖慢了速度。例如多尺度窗口划分[Focal self-attention for local-global interactions in vision transformers]、递归结构[Quadtree attention for vision transformers]和扩张窗口[Visual attention network]。
所以本文尝试在间接指标FLOPs之外,引入了更直接的指标,即吞吐量(throughput)。
主要改进
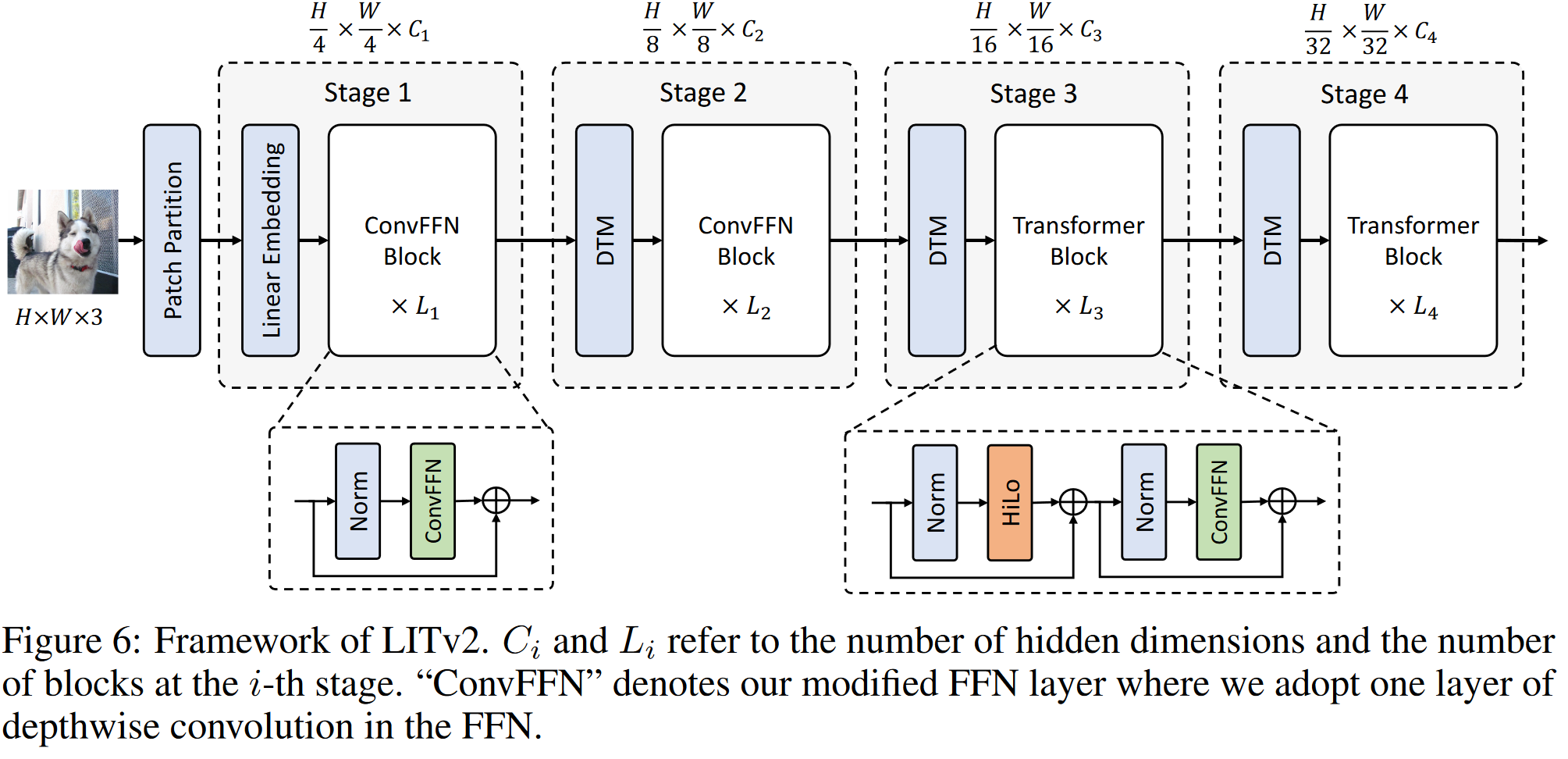
简单概括就是,在LITv1的基础上:
- 移除相对位置编码,并在FFN中引入0补齐的3x3深度分离卷积;
-
基于LITv1
本工作基于作者先前的工作LITv1。
LITv1的简要总结可见我的另一篇文章:https://blog.csdn.net/P_LarT/article/details/124998694。 其主要基于这样的观察:早起的MSA层仍然专注于局部模式。所以其移除了浅层中的MSA,仅使用FFN,深层使用标准MSA。这一范式和最近字节关于面向TensorRT的视觉Transformer的设计的工作(https://www.yuque.com/lart/papers/pghqxg)也算是殊途同归了。
- 另外,它也使用可变形卷积改进的patch merging layer,从而自适应的融合不同的patch。
LITv1速度较快且性能良好,但是其仍然在速度上存在两点主要的瓶颈:
- 深层结构中仍然使用标准的MSA,对于高分辨率输入仍然力不从心。
- 所使用的固定相对位置编码对于不同分辨率的图像输入,会使用插值,这会动态降低速度。
所以本文尝试进一步改进LITv1中使用的标准MSA和位置编码方式,以使其可以更好的用于高分辨率图像中。
改进MSA
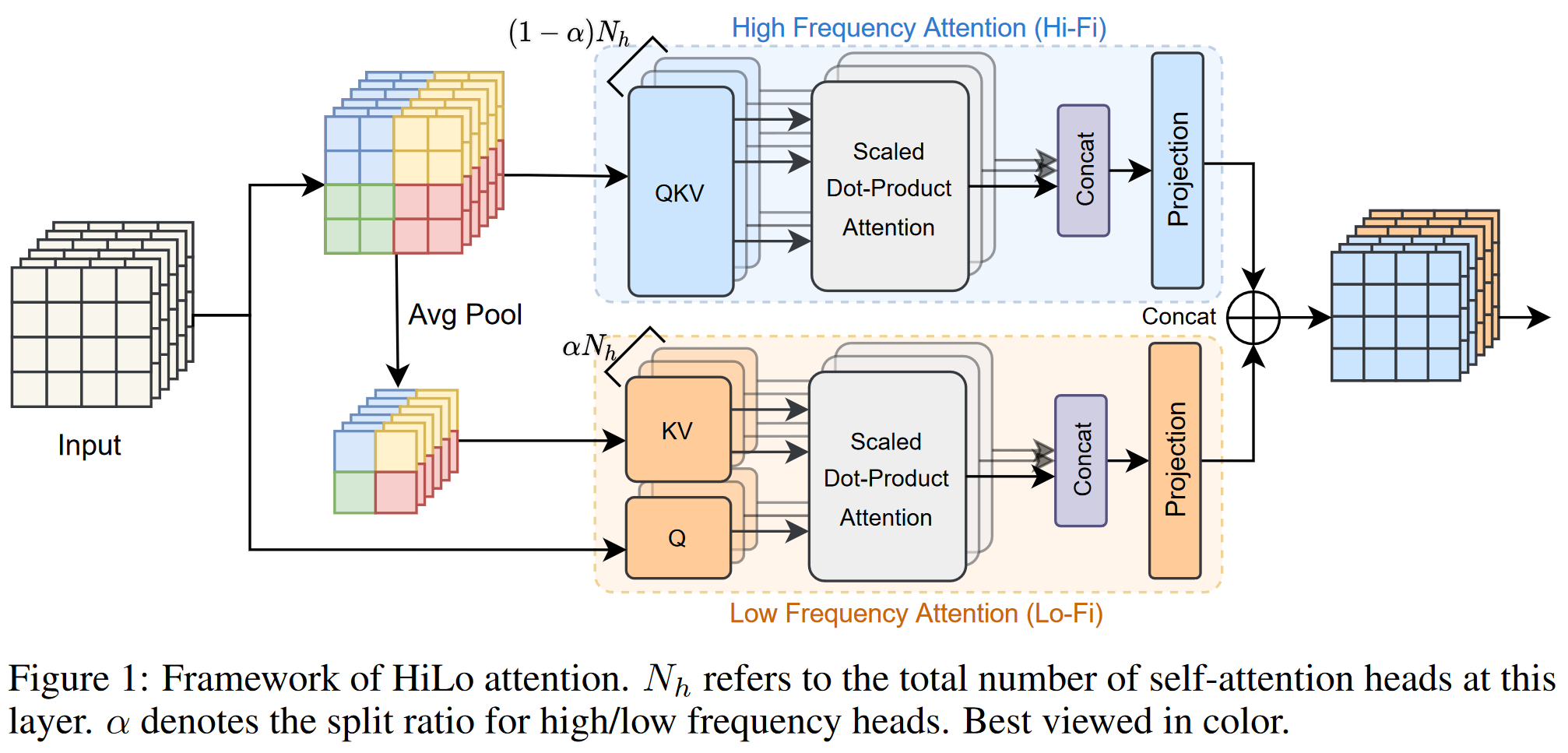
自然图像包含丰富的频率,高频捕获对象的局部细节(例如线条和形状),而低频编码全局结构(例如纹理和颜色)。所以很多计算机视觉领域中的工作采用了高低频信息分解处理的策略。
作者基于这种频域分解的思路,设计了一种双路MSA结构,即HiLo(High frequency attention + Low frequency attention),从而用于替换标准的基于全局信息建模的MSA。在这两个分支中,针对性的设计可以降低复杂度,同时其中并不涉及到耗时的操作。所以整体在GPU上的速度也是很快的。
- 高频分支(Hi-Fi):直观上,直接使用全局注意力在特征上捕获高频信息,可能是冗余且计算复杂的。所以在高频分支中使用非重叠窗口注意力捕获细粒度高频信息(例如2x2大小的窗口)。
- 低频分支(Lo-Fi):[How do vision transformers work?]显示出了MSA中的全局注意力可以帮助捕获低频信息。然而直接应用到高分辨率特征需要较高的计算成本。由于平均操作是一种低通滤波器,所以低频分支在无重叠窗口上执行平均池化。之后用降采样后的信号来生成K和V。和原始心信号生成的Q计算全局注意力。
具体构建过程中,为了控制计算成本,这里直接对MSA中的头使用一个划分比例α进行分组,其中(1-α)的头用于高频分支,其他的用于低频分支。整体操作的计算复杂度显然小于标准的MSA,同时也保证了较高的吞吐量。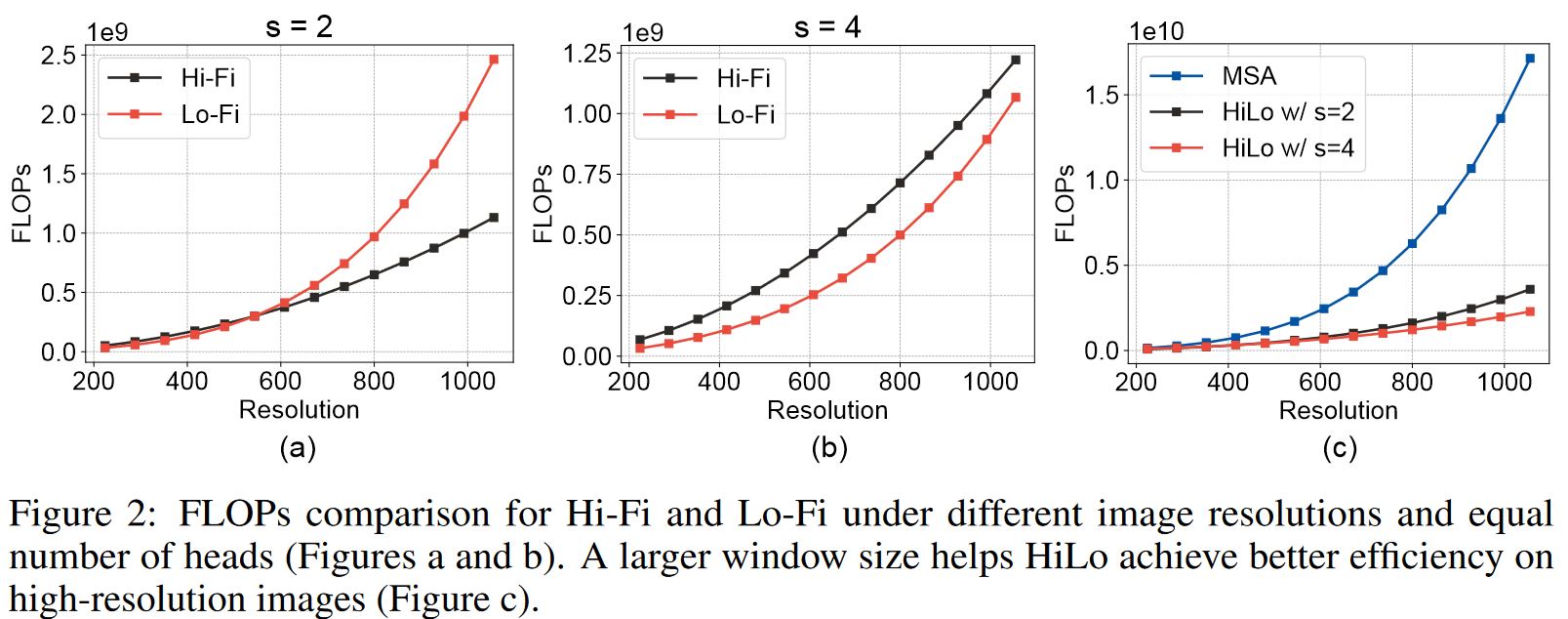
由于高分辨分支和token数量成线性关系,而低分辨率分支仍然成平方关系,所以在高分辨率图像上,为了获得更好的效率,作者建议增加窗口大小。
在假设双分支有着相同数量的头: Hi-Fi计算成本:
; Lo-Fi计算成本:

双分支独立处理,也使得输出投影矩阵Wo被拆成了两个更小的矩阵,从而也降低了模型参数。最终输出是双分支输出的拼接。
向FFN中引入深度分离卷积
作者们在每个FFN中引入了3x3的深度分离卷积层:
- 隐式学习位置信息:位置编码对于MSA至关重要,因为其具有置换不变性。LITv1中使用Swin中采用的固定的相对位置编码。对于密集预测任务而言,由于不同分辨率下需要进行插值操作,会拖慢速度。所以作者们(延续了[How much position information do convolutional neural networks encode?]中指出的0补齐的卷积可以隐式学习位置信息的思想,在FFN中引入了3x3的0补齐的深度分离卷积。
引入更大的感受野。LITv1浅层结构中仅使用了MLP结构,这有助于强化其感受野。
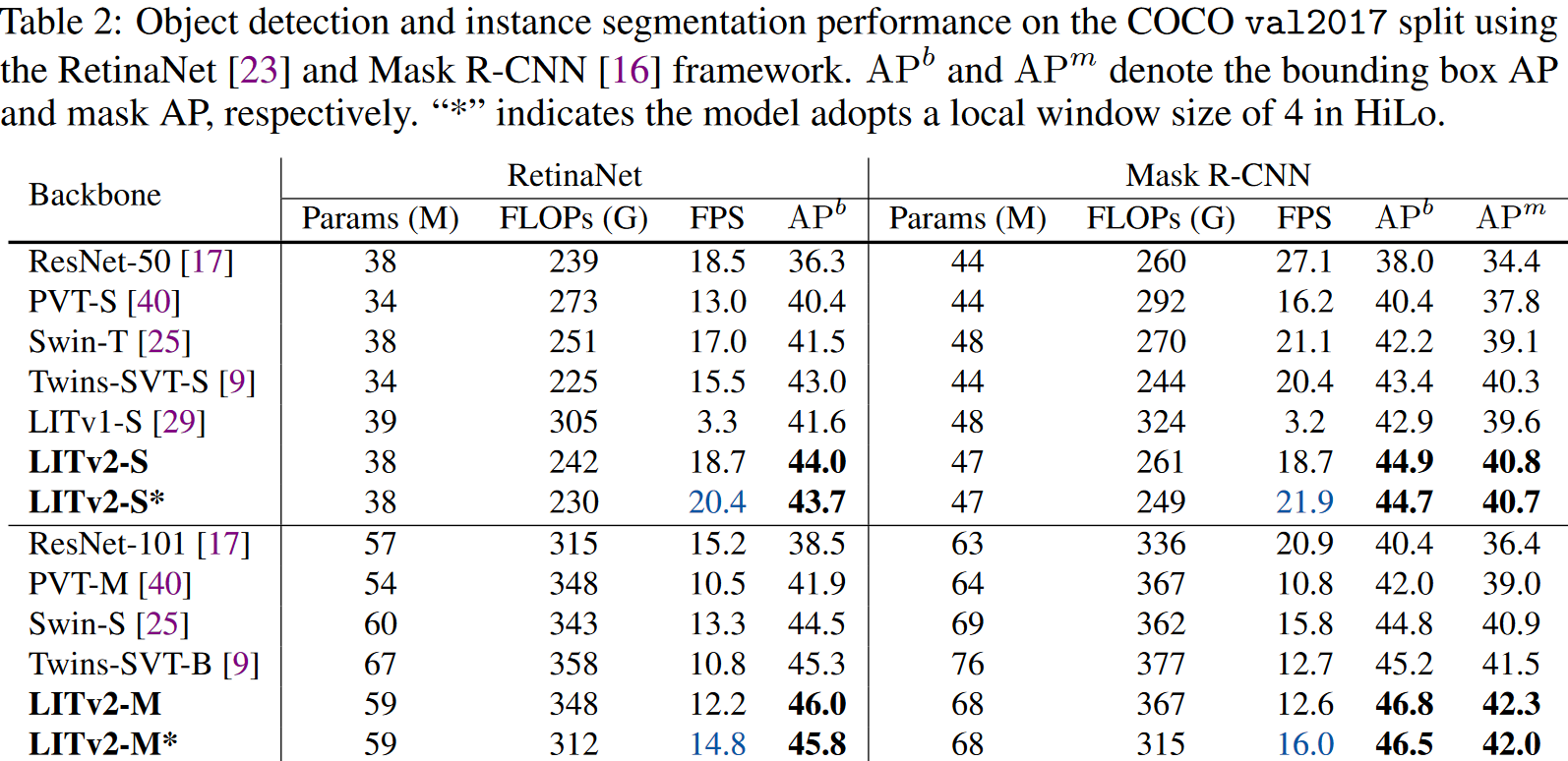
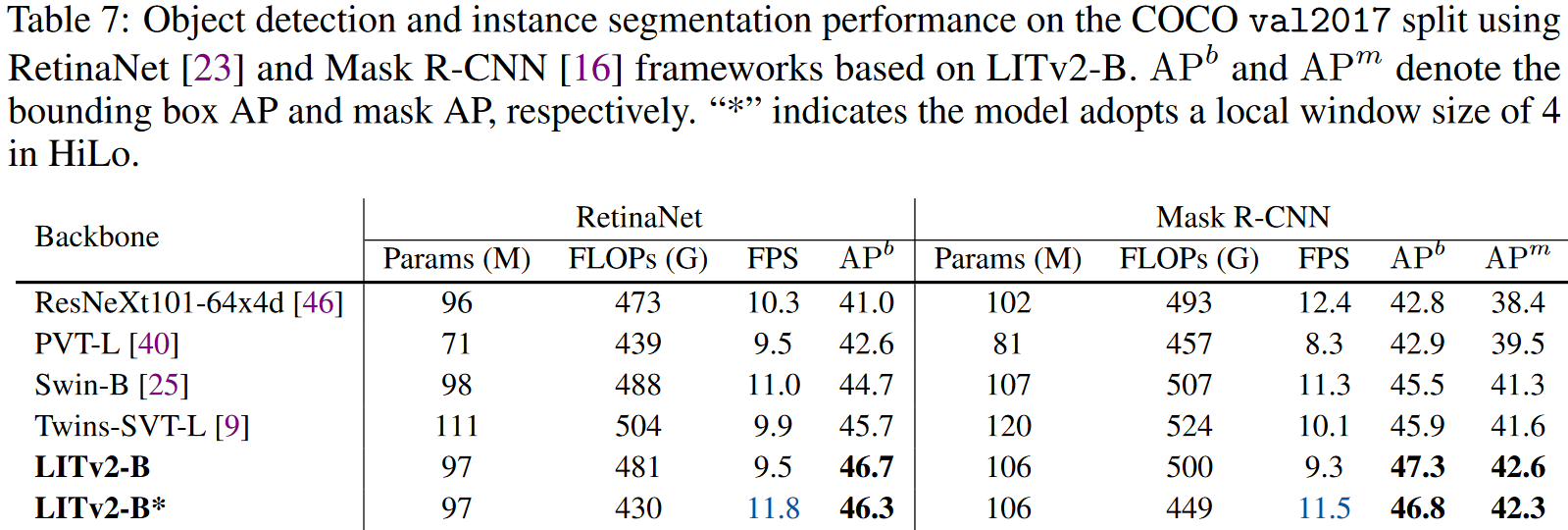
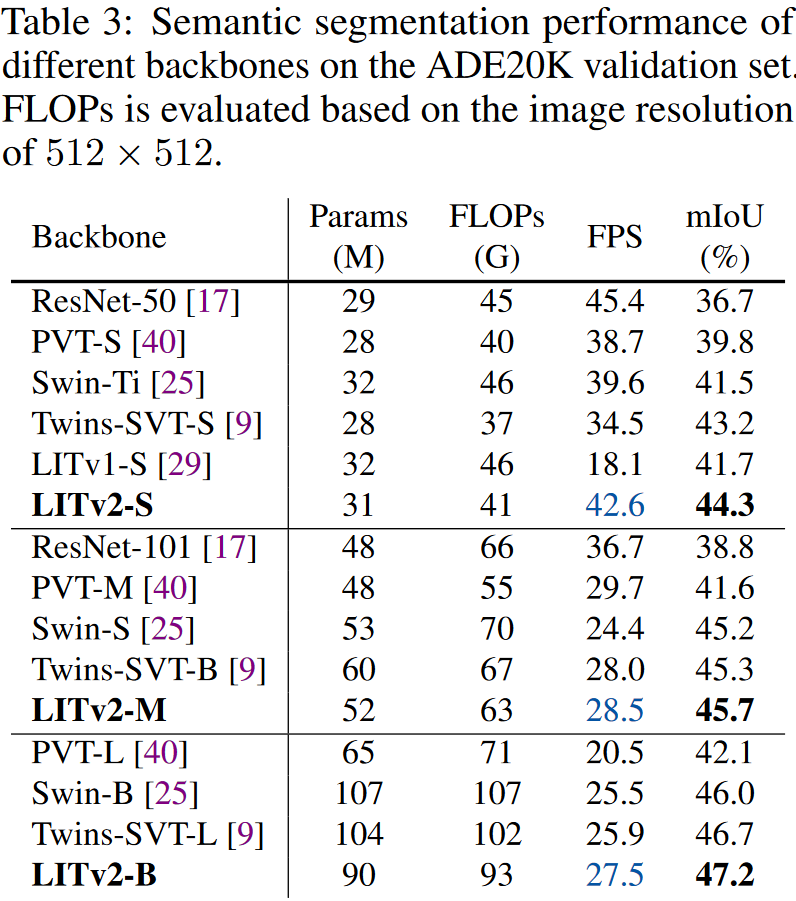
实验效果
模型参数设置
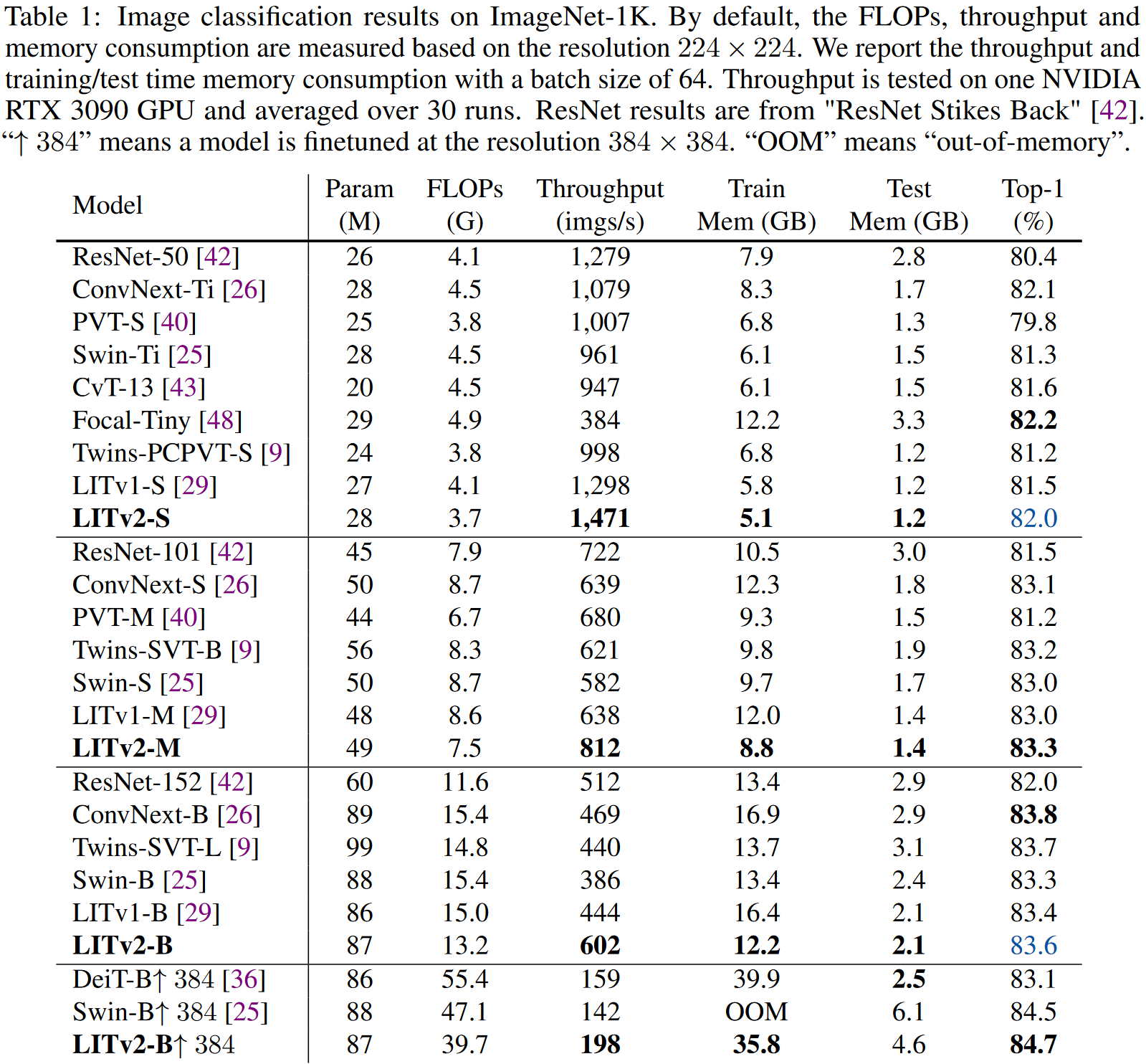
对比实验
作者们在ImageNet-1K、COCO和ADE20K上做了对比实验。
消融实验
和其他注意力机制简化策略的对比
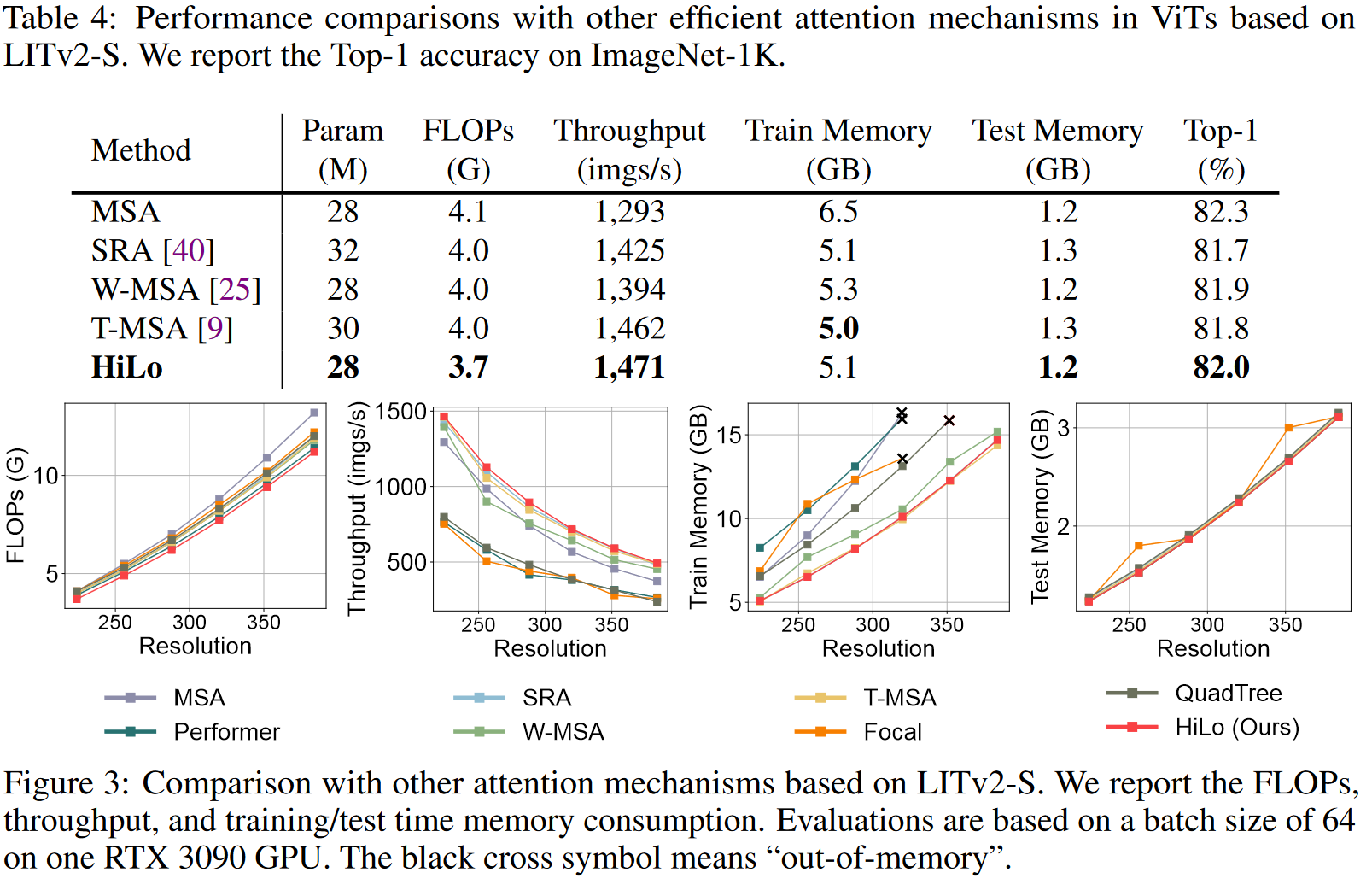
表4中的实验都是直接使用对应的策略替换LITv2-S中的HiLo来获得的。spatial reduction attention (SRA) in PVT
- shifted-window based attention (W-MSA) in Swin
- alternated local and global attention (T-MSA) in Twins
α的影响以及架构修改的影响

这里α表示低频分组比例。图4中展现出了低频分组的重要性。这里最终选择使用0.9。不过从架构细节中可以看到,这里调整的是stage3的HiLo。
表5中,直接引入ConvFFN获得了最好的效果,而通过移除RPE和引入HiLO则获得了更好的性能与速度的权衡。HiLo频域分析
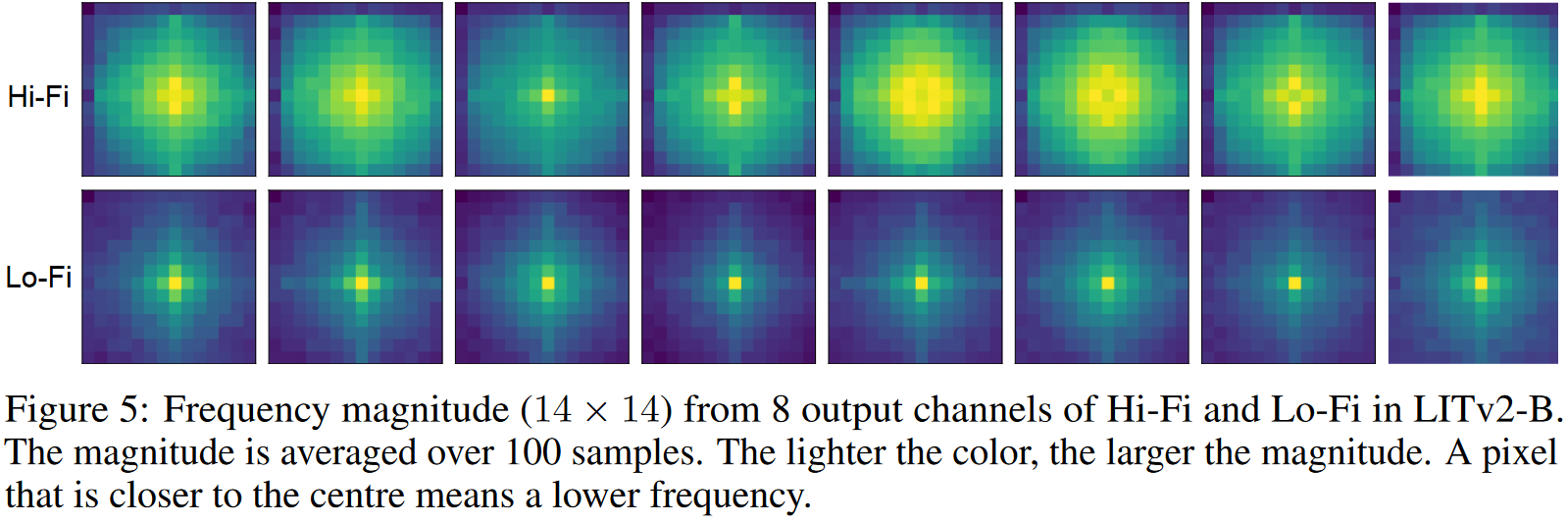
展示了高低频分支设计的合理性,二者展现出了明显的差异。窗口大小的影响
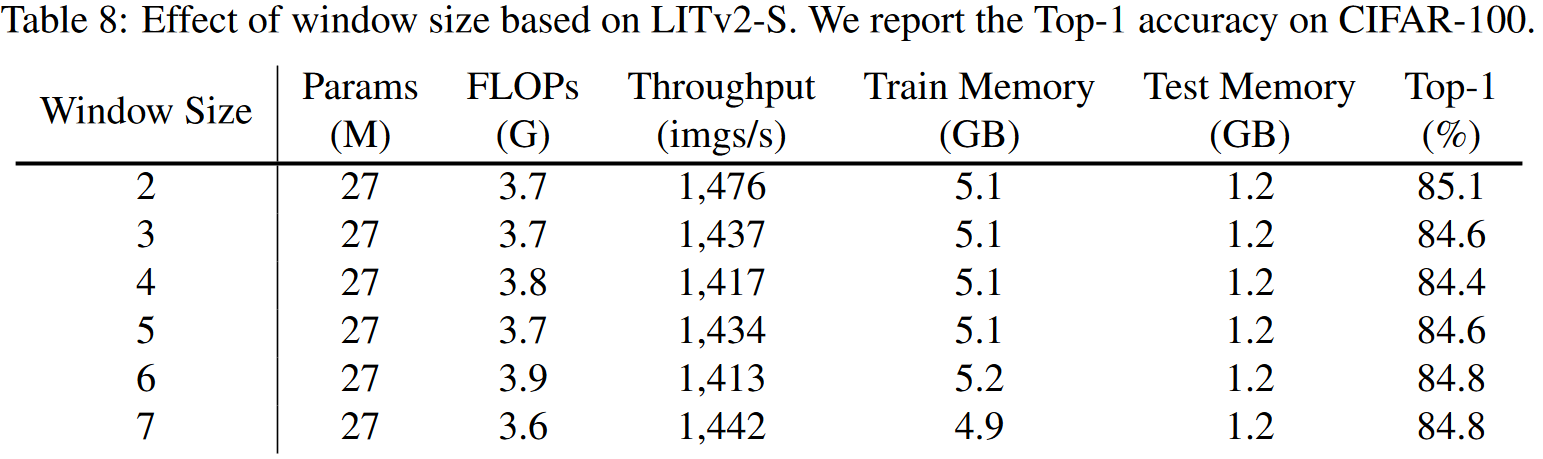
作者在CIFAR100上进行了消融实验,最终选定2作为默认值。这里的表中奇怪的一点是更大的窗口实际上并没有带来太明显的速度提升,反而是s=2获得了最好的速度。
或许是因为由于使用窗口均匀划分,其中padding的操作会额外造成影响。


若有收获,就点个赞吧
0 人点赞
