线程安全用红色标出
Conllection存放单值的最大接口
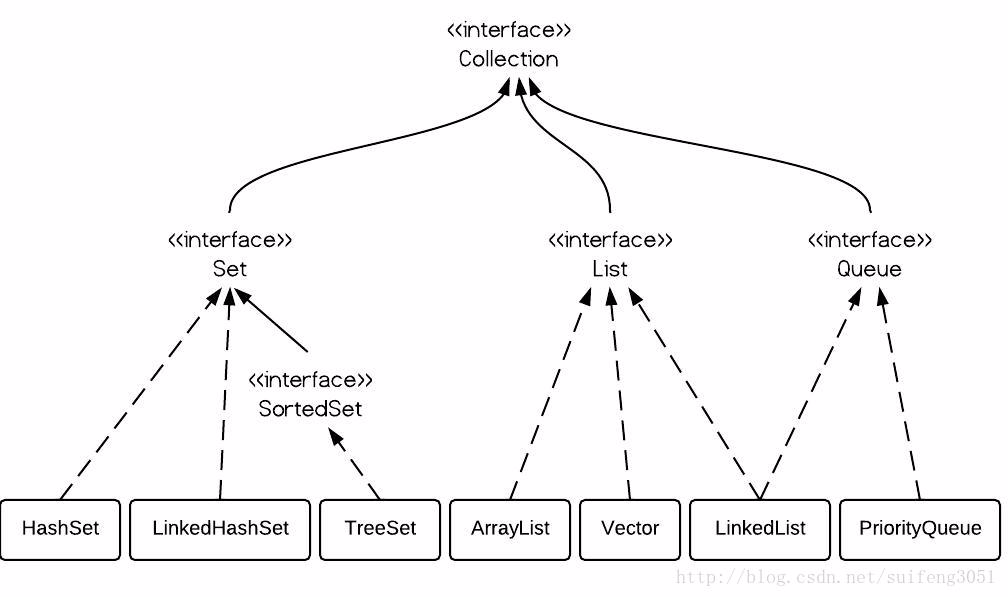
1.<< interface>> Set
无序集合,可以去重(去除重复通过hashCode()和equals()判断,所以必须重写这两个方法)
HashSet 首先判断两个元素的哈希值,如果哈希值一样,接着会比较equals 方法
2.1 HashSet 不需要指定顺序
存取快,内部是hashMap
当往集合在添加元素时add(Object),HashMap.put(Object, new Object())
首先会调用 Object 的 hashCode()方法判断hashCode 是否已经存在,如不存在则直接插入元素;
如果已存在则调用 Object 对象的 equals()方法判断如果为 true 则说明元素已经存在,如为 false 则插入元素。
2.1.1 LinkedHashSet
LinkedHashSet 与存储顺序一致
它继承与 HashSet、又基于 LinkedHashMap 来实现的。
LinkedHashSet 底层使用 LinkedHashMap 来保存所有元素
2.2.1 TreeSet 需要指定顺序
数据结构就是treeMap的数据结构:红黑树,
需要实现 Comparable 接口,并且覆写相应的 compareTo()函数 实现排序
2.<< interface>> List
2.1 ArrayList
[数组实现]
头部插入慢,尾部插入快,随机访问快
删除复杂度O(n),效率不高
无参构造后容量是0 , 默认容量为10
ArrayList每次扩容的容量是当前的1.5倍+1
内存是连续的
顺序表:需要申请连续的内存空间保存元素,可以通过内存中的物理位置直接找到元素的逻辑位置。在顺序表中间插入or删除元素需要把该元素之后的所有元素向前or向后移动。
2.2 LinkedList
[双向链表实现]
头部和尾部操作快(有专门的指针),中间操作慢
随机访问慢,顺序访问快,
- 链表大小:
transient int size = 0; - (指向)第一个结点/头结点:
transient Node<E> first; - (指向)最后一个结点/尾结点:
transient Node<E> last;
遍历LinkedList时应用iterator方式,不要用get(int)方式,否则效率会很低
内存不连续
双向链表:不需要申请连续的内存空间保存元素,需要通过元素的头尾指针找到前继与后继元素(查找元素的时候需要从头or尾开始遍历整个链表,直到找到目标元素)。在双向链表中插入or删除元素不需要移动元素,只需要改变相关元素的头尾指针即可。
2.3~~ Vector~~[过时]
线程安全 -> 性能低
由于Vector中的方法基本都是synchronized的,其性能低于ArrayList
Vector可以定义数组长度扩容的因子,ArrayList不能
丨———Stack[栈,先进后出]
3.<< interface>> Queue
先进先出
阐述ArrayList、Vector、LinkedList的存储性能和特性?
ArrayList 和Vector他们底层都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢。<br /> <br /> LinkedList使用双向链表实现存储(将内存中零散的内存单元通过附加的引用关联起来,形成一个可以按序号索引的线性结构,这种链式存储方式与数组的连续存储方式相比,内存的利用率更高),按序号索引数据需要进行前向或后向遍历,但是插入数据时只需要记录本项的前后项即可,所以插入速度较快。
由于ArrayList和LinkedListed都是非线程安全的,如果遇到多个线程操作同一个容器的场景,则可以通过工具类Collections中的synchronizedList方法将其转换成线程安全的容器后再使用(这是对装饰者模式的应用,将已有对象传入另一个类的构造器中创建新的对象来增强实现)。
一、ArrayList分析
1.Arraylist中add() 扩容
(oldCapacity + (oldCapacity >> 1)) 约是oldCapacity 的1.5倍
- 初始化扩容
size=0 数组={} 扩容为 容量为10
- 大于当前容量时扩容
当数组的大小大于初始容量的时候(比如初始为10,当添加第11个元素的时候),就会进行扩容
旧的数组就会使用Arrays.copyOf方法被复制到新的数组中去,现有的数组引用指向了新的数组。
remove() 缩容
遍历查找 复杂度O(N)
找到index, 并计算后面还剩多少个元素 ,fastRemove调用System.copy方法复制
modCount
只有add和remove操作时modCount时才会增加,
多线程情况下, 如果遍历时modCount数量改变会抛出异常
2. 为什么说ArrayList是线程不安全的?
add 方法不是原子操作,也没有加锁
多线程并发的时候,假如A、B两个线程,A挂起的时候,B线程拿到的size值和A是一样的,就会覆盖线程A的值,导致A的值为空。再者,因为size不能保证原子性,ArrayList 有默认数组大小,就会抛出数组下标越界的异常
二、如何线程安全
使⽤ReentrantLock加锁
- CopyOnWriteArrayList/Set
执⾏修改操作时,会拷⻉⼀份新的数组进⾏操作(add、set、remove等),代价⼗分昂贵,在执⾏完修改后将原来集合指向新的集合来完成修改操作,源码⾥⾯⽤ReentrantLock可重⼊锁来保证不会有多个线程同时拷⻉⼀份数组
设计思想:读写分离+最终⼀致
缺点:内存占⽤问题,写时复制机制,内存⾥会同时驻扎两个对象的内存,旧的对象和新写⼊的对象,
如果对象⼤则容易发⽣Yong GC和Full GC
使用场景:读⾼性能,适⽤读操作远远⼤于写操作的场景中使⽤(读的时候是不需要加锁的,直接获取,删除和增加是需要加锁的, 读多写少)
- Collections.synchronizedList
线程安全的原因是因为它⼏乎在每个⽅法中都使⽤了synchronized同步锁
使用场景: 写操作性能⽐CopyOnWriteArrayList好,读操作性能并不如
线程安全的LinkedList
- Collections.synchronizedList(new LinkedList
());
- 将LinkedList全部换成ConcurrentLinkedQueue
ConcurrentLinkedQueue是一个基于链接节点的无界线程安全队列,它采用先进先出的规则对节点进行排序,当我们添加一个元素的时候,它会添加到队列的尾部,当我们获取一个元素时,它会返回队列头部的元素。它采用了“wait-free”算法来实现,
- 使用 CAS 原子指令来处理对数据的并发访问,这是非阻塞算法得以实现的基础。

若有收获,就点个赞吧
0 人点赞
