ConcurrentHashMap1.7和1.8的不同实现
https://blog.csdn.net/shadow_zed/article/details/82079579
1.7 分段锁(ReentrantLock + Segment + HashEntry)
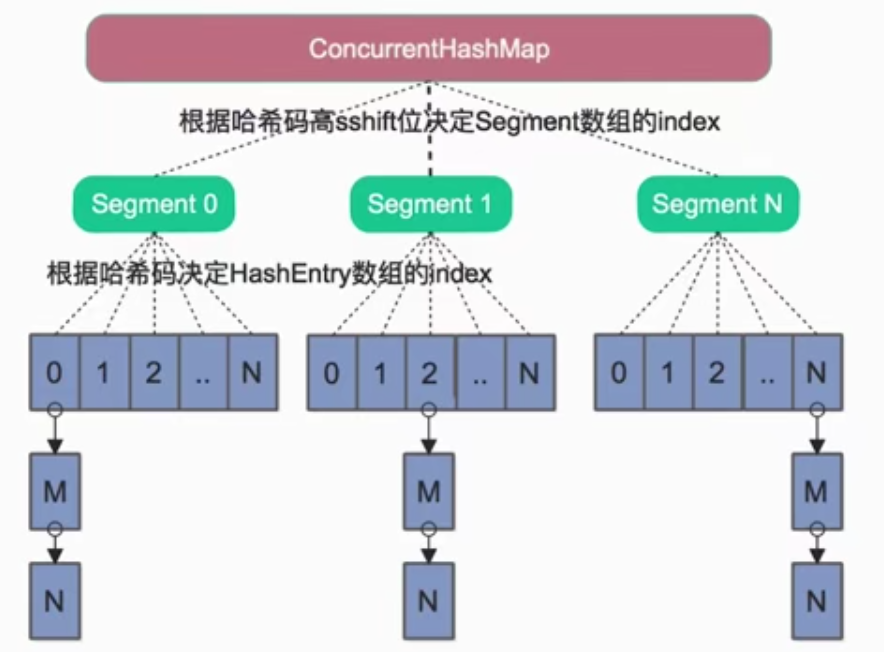
相当于把一个 HashMap 分成多个段,每段分配一把锁,这样支持多线程访问。锁粒度:基于 Segment,包含多个 HashEntry。
①、Segment 继承 ReentrantLock(重入锁) 用来充当锁的角色,每个 Segment 对象守护每个散列映射表的若干个桶;
②、HashEntry 用来封装映射表的键-值对;
③、每个桶是由若干个 HashEntry 对象链接起来的链表
进行put操作会先获取锁,finally解锁
不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发。每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。
1.8 CAS + synchronized + Node + 红黑树。
JDK 1.8 中使用 锁粒度:Node(首结点)(实现 Map.Entry)。锁粒度降低了。
其中抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性。
1.8 在 1.7 的数据结构上做了大的改动,采用红黑树之后可以保证查询效率(
O(logn)),甚至取消了 ReentrantLock 改为了 synchronized,这样可以看出在新版的 JDK 中对 synchronized 优化是很到位的。
- 在1.8中ConcurrentHashMap的get操作全程不需要加锁,这也是它比其他并发集合比如hashtable、用Collections.synchronizedMap()包装的hashmap;安全效率高的原因之一。
- get操作全程不需要加锁是因为Node的成员val是用volatile修饰的和数组用volatile修饰没有关系。
- 数组用volatile修饰主要是保证在数组扩容的时候保证可见性。
get操作可以无锁是由于Node的元素val和指针next是用volatile修饰的,在多线程环境下线程A修改结点的val或者新增节点的时候是对线程B可见的。
transient volatile Node<K,V>[] table;
使得Node数组在扩容的时候对其他线程具有可见性而加的volatile
为什么要用synchronized
- JVM 开发团队没有放弃 synchronized,而且基于 JVM 的 synchronized 优化空间更大,更加自然。
- 在大量的数据操作下,对于 JVM 的内存压力,基于 API 的 ReentrantLock 会开销更多的内存。
ConcurrentHashMap源码分析
对数组分段加锁
JDK1.7
ConcurrentHashMap里面有一个Segment数组
Segment是一个简单的HashMap,有自己的Entry数组,
JDK1.8
static class Segment<K,V> extends ReentrantLock implements Serializable {private static final long serialVersionUID = 2249069246763182397L;final float loadFactor;Segment(float lf) { this.loadFactor = lf; }}

若有收获,就点个赞吧
0 人点赞
