Hadoop
适合海量数据存储和计算的平台
版本:1.0
-> 2.0 新增Yarn
-> 3.0
- 本地模式(Local)无需运行任何的守护进程,所有程序都在同一个JVM上执行。HDFS在这种模式下,用的就是本地的文件系统
- 伪分布模式 Hadoop守护进程运行在本地机器上,模拟一个小规模的集群
-
Hadoop的特点
扩容能力(Scalable):能可靠地(reliably)存储和处理千兆字节(PB)数据。
- 成本低(Economical):可以通过普通机器组成的服务器群来分发以及处理数据。这些服务器群总计可达数千个节点。
- 高效率(Efficient):通过分发数据,hadoop可以在数据所在的节点上并行地(parallel)处理它们,这使得处理非常的快速。
- 可靠性(Reliable):hadoop能自动地维护数据的多份副本,并且在任务失败后能自动地重新部署(redeploy)计算任务。
Hadoop的朋友圈
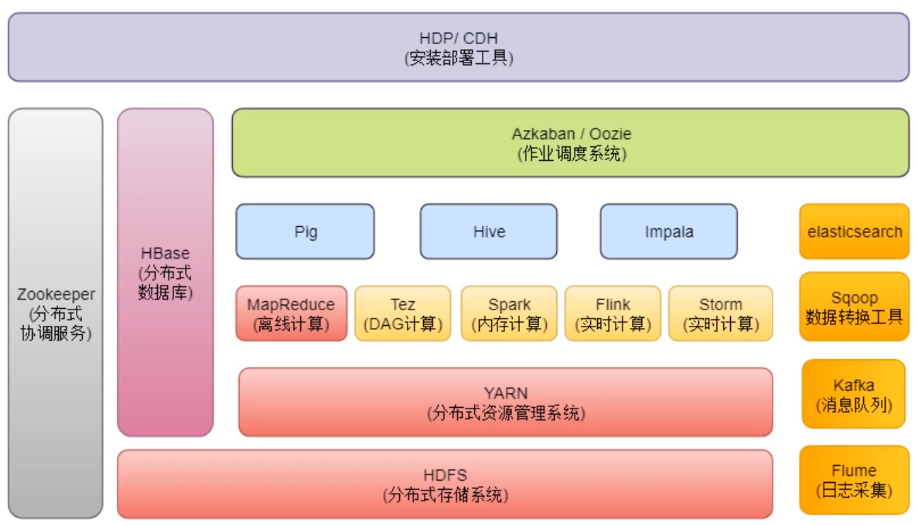
hadoop的三个核心
http://localhost:8088/
- HDFS: Hadoop Distributed File System 分布式文件系统
- YARN: Yet Another Resource Negotiator 资源管理调度系统
支持主从架构,主节点最多两个
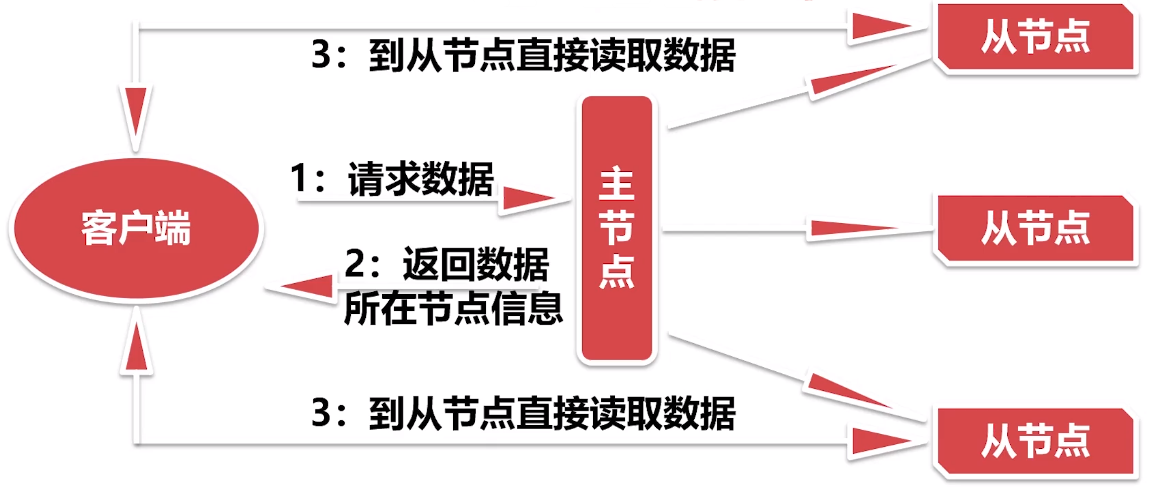
1. NameNode
http://localhost:9870/
接收用户请求,维护文件系统目录结构,最多两个
2. DataNode
命令
hadoop fs -mkdir /input
hadoop fs -ls /input
hadoop fs -put LICENSE.txt /input
Map和Reduce
Map是一个独立的程序,会在很多节点上同时执行,每个节点处理一部分数据
Reduce是聚合程序
全文参考链接:
- https://blog.csdn.net/gwd1154978352/article/details/81095592
- 安装: https://blog.csdn.net/liaoningxinmin/article/details/85992752
mac 下 native 资源:https://download.csdn.net/download/qq_14811559/10413344

若有收获,就点个赞吧
0 人点赞
