https://www.toutiao.com/i6818522613401256452/
非常优秀的文章> https://www.jianshu.com/p/2e2a18d02218
HashMap的特性
- HashMap默认初始化长度为16
- key和value允许为null。若key值重复则覆盖。
- 并且每次自动扩展或者是手动初始化容量时,必须是2的幂。
- 链表长度大于 8 并且整个数组长度大于64时, 转为红黑树,小于 6 变为链表
- 非同步,线程不安全。**不保证有序**
hashCode()方法
- 返回对象的哈希代码值(就是散列码),用来支持哈希表,例如:HashMap
- 可以提高哈希表的性能
- 哈希代码值可以提高性能
实现了hashCode一定要实现equals,因为底层HashMap就是通过这2个方法判断重复对象的
绕口令式hashCode与equals
- 如果两对象equals()是true,那么它们的hashCode()值一定相等
- 如果两对象的hashCode()值相等,它们的equals不一定相等(hash冲突啦)
重写对象的Equals方法时,要重写hashCode方法,为什么?
如果两个对象的hashCode相同,它们并不一定相同(即用equals比较返回false)
所以这里把 hashcode 的判断放在前面,只要 hashcode 不相等就玩儿完,不用再去调用复杂的 equals 了。很多程度地提升 HashMap 的使用效率。
HashMap
基于哈希表实现的Map接口,与Hashtable大致相同(Hashtable是把所有方法加锁),但是不是同步的并且允许空值
1. 数据结构
JDK 1.7
数组+链表
数组是HashMap的本体,而链表则是为了解决hash冲突而存在的
JDK8
数组: 连续的内存空间, 查找快
单链表 : 增删快, 查找慢
红黑树:
HashMap先得到key的散列值,在通过扰动函数(减少碰撞次数)得到Hash值,接着通过hash & (n -1 ),n位table的长度,运算后得到数组的索引值。如果当前节点存在元素,则通过比较hash值和key值是否相等,相等则替换,不相等则通过拉链法查找元素,直到找到相等或者下个节点为null时插入。
为什么变成树化, 为什么是8TREEIFY_THRESHOLD 用于判断是否需要将链表转换为红黑树的阈值,默认是8。
链表查询时线性的,会严重影响存取的性能。
当hashCode离散性很好的时候, 树型bin(容器)用到的概率非常小,因为数据均匀分布在每个bin中,几乎不会有bin中链表长度会达到阈值(树化门槛)。但是在随机hashCode下,离散性可能会变差,然而JDK又不能阻止用户实现这种不好的hash算法,因此就可能导致不均匀的数据分布。不过理想情况下随机hashCode算法下所有bin中节点的分布频率**会遵循泊松分布,我们可以看到,一个bin中链表长度**达到8个元素的概率为0.00000006,几乎是不可能事件。所以,之所以选择8,不是拍拍屁股决定的,而是根据概率统计决定的。由此可见,发展30年的Java每一项改动和优化都是非常严谨和科学的。
2. 成员变量解析(1.8)
1) 桶容量(capacity)
The default initial capacity
MUST be a power of two.(必须是2的幂)
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
2)The maximum capacity -
used if a higher value is implicitly specified(隐式的被指定) ,by either of(通过) the constructors with arguments
MUST be a power of two.(必须是2的幂)
static final int MAXIMUM_CAPACITY = 1 << 30; // 10'7374'1824
为什么必须是2的幂?
一方面取决于操作系统,申请内存一般是2的倍数,避免内存碎片 一方面是做移位操作,比进行加减乘除效率高 一方面
p = tab[i = (n - 1) & hash]计算数组下标时,做与运算时,n-1 因为(2的n次方-1)的二进制是n个1,一个key的hash值&1111……,就可以保证结果最大程度取决于key.hash。 如果是key.hash & 2n次方,就是 hash % 100……,与运算则后面的结果全都为0,增大了hash碰撞的概率。
3)The load factor(负载因子) used when none specified in constructor.
static final float DEFAULT_LOAD_FACTOR = 0.75f;
4) int threshold;阈值
阈值算法为capacity*loadfactory,大致当map中entry数量大于此阈值时进行扩容(1.8)
5) 数组
由 Node 内部类(实现 Map.Entry
transient Node<K,V>[] table;
6) 静态内部类
static class Node<K,V> implements Map.Entry<K,V> {
链表节点,key,value,next
hash()方法
如何减小冲突
异或后,提高散列度,避免冲突
通过移位和异或运算,可以让 hash 变得更复杂,进而影响 hash 的分布性。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
put 方法
存储对象,实现了懒加载,当存对象时才进行初始化
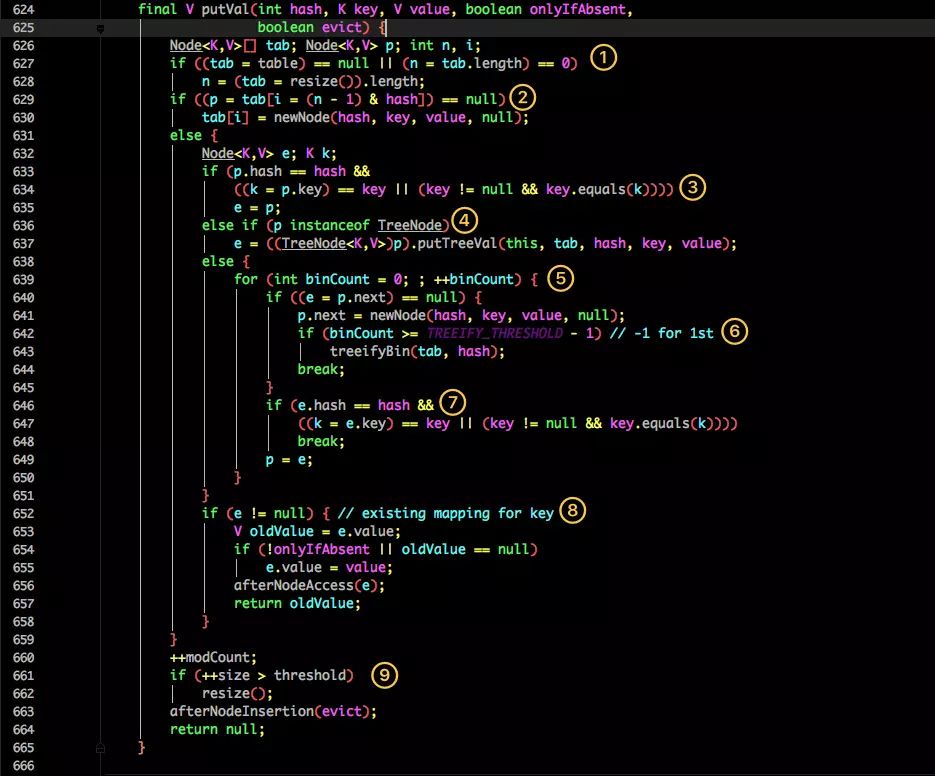
- 判断当前桶是否为空,空的就需要初始化(resize 中会判断是否进行初始化)。
- 根据当前 key 的 hashcode 定位到具体的桶中并判断是否为空,为空表明没有 Hash 冲突就直接在当前位置创建一个新桶即可。
- 如果当前桶有值( Hash 冲突),那么就要比较当前桶中的
key、key 的 hashcode与写入的 key 是否相等,相等就赋值给e,在第 8 步的时候会统一进行赋值及返回。 - 如果当前桶为红黑树,那就要按照红黑树的方式写入数据。
- 如果是个链表,就需要将当前的 key、value 封装成一个新节点写入到当前桶的后面(形成链表)。
- 接着判断当前链表的大小是否大于预设的阈值,大于时就要转换为红黑树。
- 如果在遍历过程中找到 key 相同时直接退出遍历。
- 如果
e != null就相当于存在相同的 key,那就需要将值覆盖。 - 最后判断是否需要进行扩容。
1.7和1.8区别
在java 1.8中,如果链表的长度超过了8,那么链表将转换为红黑树。(桶的数量必须大于64,小于64的时候只会扩容),小于6时, 会退化为链表
为什么引入红黑树?🍂
JDK 1.8 以前 HashMap 的实现是 数组+链表,即使哈希函数取得再好,也很难达到元素百分百均匀分布。
当 HashMap 中有大量的元素都存放到同一个桶中时,这个桶下有一条长长的链表,这个时候 HashMap 就相当于一个单链表,假如单链表有 n 个元素,遍历的时间复杂度就是 O(n),完全失去了它的优势。
针对这种情况,JDK 1.8 中引入了 红黑树(查找时间复杂度为 O(logn))来优化这个问题。
数组长度没有达到64不扩容? 因为没有达到64的时候扩容的效率比转红黑树的效率高
插入效率比平衡二叉树高,查询效率比普通二叉树高。所以选择性能相对折中的红黑树。
红黑树属于平衡二叉树
每个节点非红即黑 根节点总是黑色的 如果节点是红色的,则它的子节点必须是黑色的(反之不一定)
每个叶子节点都是黑色的空节点(NIL节点)
从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)
发生hash碰撞时,java 1.7 会在链表的头部插入,而java 1.8会在链表的尾部插入, 避免扩容后,链表产生相对位置倒叙,也可以避免并发产生循环链表死循环,
在java 1.8中,Entry被Node替代(换了一个马甲)。
get
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
- 首先将 key hash 之后取得所定位的桶。
- 如果桶为空则直接返回 null 。
- 否则判断桶的第一个位置(有可能是链表、红黑树)的 key 是否为查询的 key,是就直接返回 value。
- 如果第一个不匹配,则判断它的下一个是红黑树还是链表。
- 红黑树就按照树的查找方式返回值。
- 不然就按照链表的方式遍历匹配返回值。
获取对象,将 K 传给:
①、调用 hash(K) 方法(计算 K 的 hash 值)从而获取该键值所在链表的数组下标;
②、顺序遍历链表,equals()方法查找相同 Node 链表中 K 值对应的 V 值。
hashCode 是定位的,存储位置;equals是定性的,比较两者是否相等。
resize()
rehash
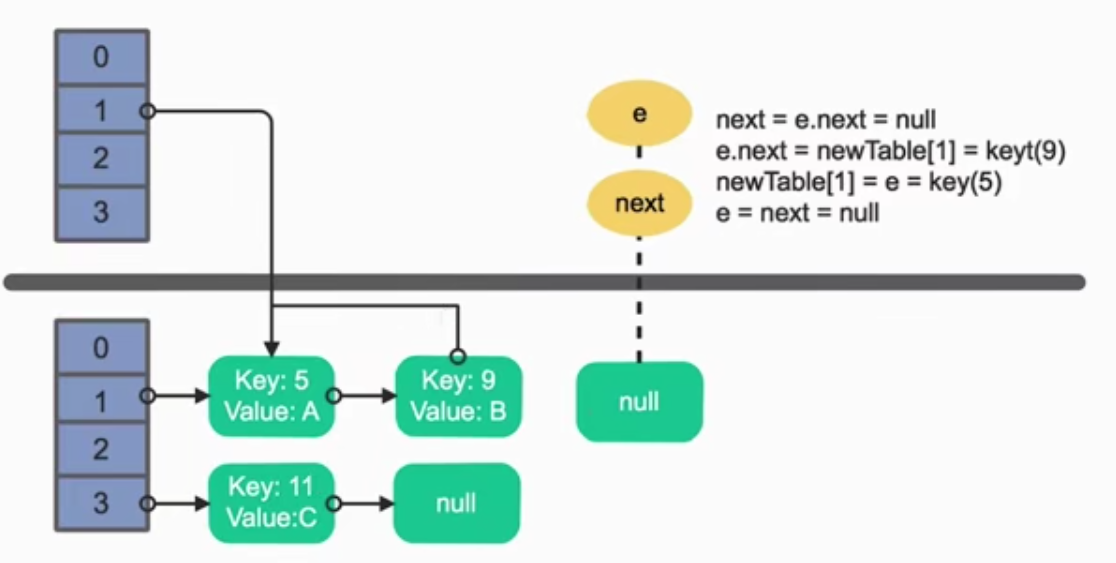
线程安全问题
首先HashMap是线程不安全的,其主要体现:
#1.在jdk1.7中,在多线程环境下,扩容时会造成环形链或数据丢失。
#2.在jdk1.8中,在多线程环境下,会发生数据覆盖的情况。
JDK1.7
初始化方法inflateTable()
如果构造方法中传入size,找到大于size的最近的2的幂的数,作为size
创建entry数组[size]
put()方法
①、初始化table,调用 hash(K) 方法计算 K 的 hash 值,然后结合数组长度,计算得数组下标i;
②、遍历链表,判断key是否相等,如果找到,则覆盖,如果没找到下一步
③、addEntry() 是否需要扩容(size是否大于阈值[CAPACITY0.75f] && 当前table[i]位置不为空)
如果需要扩容:new 新数组[length 2],迁移数据transfer(),遍历旧table和他的链表,(一般不会rehash)放进新table
④、createEntry() modCount++,头插法,将原来的table[i]作为成员变量,放入新Entry的next,设置table[下标i]为新的Entry,size++
为什么扩容? 链表会非常长,影响get的效率,为了减小链表长度,进行使用新数组进行扩容 1.7的扩容问题? 会产生循环链表,导致cpu耗尽
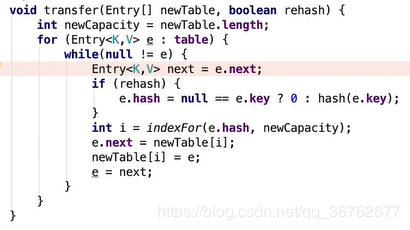
JDK1.8
put()方法
①、调用 hash(K) 方法计算 K 的 hash 值,然后结合数组长度,计算得数组下标;
②、调整数组大小(当容器中的元素个数大于 capacity * loadfactor 时,容器会进行扩容resize 为 2n);
③、i.如果 K 的 hash 值在 HashMap 中不存在,则执行插入,若存在,则发生碰撞;
ii.如果 K 的 hash 值在 HashMap 中存在,且它们两者 equals 返回 true,则更新键值对;
iii. 如果 K 的 hash 值在 HashMap 中存在,且它们两者 equals 返回 false,则插入链表的尾部(尾插法)或者红黑树中(树的添加方式)。
(JDK 1.7 之前使用头插法、JDK 1.8 使用尾插法)
(注意:当碰撞导致链表大于 TREEIFY_THRESHOLD= 8 时,就把链表转换成红黑树)
如何扩容?目的? 链表过长会将链表转成红黑树,以实现在O(logn)时间复杂度内查找 扩容后旧值位置? 这个值只可能在两个地方:一种是在原下标位置,另一种是在下标为<原下标+原容量>的位置
参考链接

若有收获,就点个赞吧
0 人点赞
