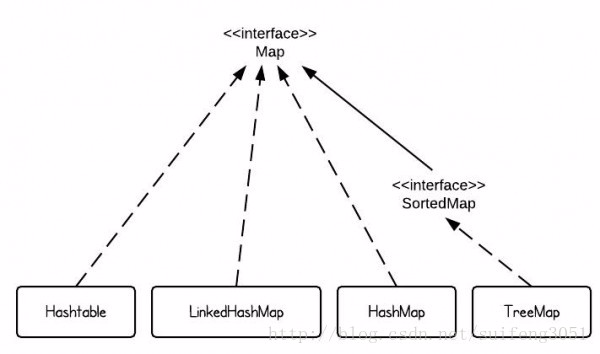
Map接口
Map:存储键值对 Hash表解释:其中有0~15共16个位置,hashCode的值就是代表哈希表16个位置中的其中一个,具体的值是通过hash函数计算出来的,hashCode的存在就是为了能在散列存储结构中快速查找对象。
1.Hashtable注意table,[数组+链表]
线程安全,性能低
Hashtable 初始容量为:11
HashTable 使用一把锁(锁住整个链表结构)处理并发问题,多个线程竞争一把锁,容易阻塞;
2.HashMap[数组 + 链表/红黑树]
异步处理,非线程安全,性能高
默认null,懒加载后容量为16(数组),扩容因子为0.75
HashMap有快速寻址的特点
HashMap不能保证元素的顺序
使用场景:在 Map 中插入、删除和定位元素时;
key重复值将被覆盖
- jdk1.8 当每个链表长度 >8 ,并且数组元素个数 ≥64时,会调整成红黑树,目的是提高效率
- jdk1.8 当链表长度 <6 时 调整成链表
- jdk1.8 以前,链表时头插入,之后为尾插入
2.1 ConcurrentHashMap 多线程中使用
对桶数组进行分段加锁,不允许空值.
是HashMap的线程安全版(自JDK1.5引入),提供比Hashtable更高效的并发性能。
原理:
ConcurrentHashMap使用分离锁的思路解决并发性能,其将 Entry数组拆
分至16个Segment中,以哈希算法决定Entry应该存储在哪个Segment。
这样就可以实现在写操作时只对一个Segment 加锁,大幅提升了并发写的性能。
在进行读操作时,ConcurrentHashMap在绝大部分情况下都不需要加锁,其Entry
中的value是volatile的,这保证了value被修改时的线程可见性,无需加锁便能实现
线程安全的读操作。
它不能保证读操作的绝对一致性。
2.2 WeakHashMap
2.3 LinkedHashMap
- 优于HashMap
- 和HashMap相比存慢取快
- 遍历比 HashMap 慢;
- LinkedHashMap 保存了记录的插入顺序;
LinkedHashMap与HashMap非常类似,唯一的不同在于前者
的Entry在HashMap.Entry的基础上增加了到前一个插入和后一个插入的Entry的引用,以实现能够按Entry的插入顺序进行遍历。
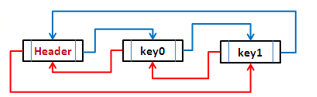
LinkedHashMap中也实现了Lru算法
使用场景: 在需要输出的顺序和输入的顺序相同的情况下。
3. SortedMap
3.1 TreeMap
TreeMap是基于红黑树实现的Map结构,其Entry类拥有到左/右叶子节点和父节点的引用,同时还记录了自己的颜色
能够把它保存的记录根据键排序(默认按键值升序排序,也可以指定排序的比较器)
关于map的空值问题
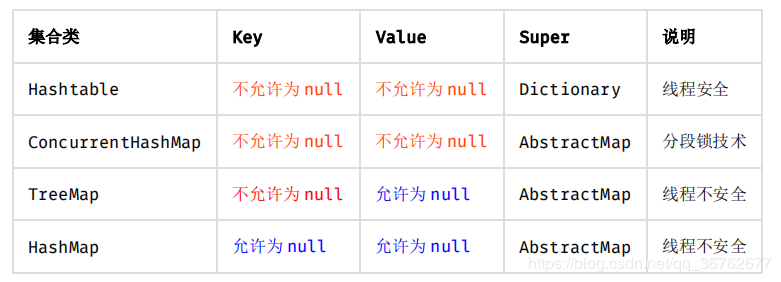
且两者的的key值均不能重复,若添加key相同的键值对,后面的value会自动覆盖前面的value,但不会报错。
- ConcurrentHashMap放入null值报错
//ConcurrentHashMap源码:/** Implementation for put and putIfAbsent */final V putVal(K key, V value, boolean onlyIfAbsent) {if (key == null || value == null) throw new NullPointerException();//......
Map常用方法
isEmpty, clear, remove, containsKey/Value
replace(1.8). putIfAbsent(存在则不更新)
getIfDefault(没获取到取默认值)

若有收获,就点个赞吧
0 人点赞
