问题
- 延迟(Latency):也可以理解为最大停顿时间,即垃圾收集过程中一次 STW 的最长时间,越短越好,一定程度上可以接受频次的增大,GC 技术的主要发展方向。
吞吐量(Throughput):应用系统的生命周期内,由于 GC 线程会占用 Mutator 当前可用的 CPU 时钟周期,吞吐量即为 Mutator 有效花费的时间占系统总运行时间的百分比,例如系统运行了 100 min,GC 耗时 1 min,则系统吞吐量为 99%,吞吐量优先的收集器可以接受较长的停顿。
排查总体思路
工具
公司的监控系统:大部分公司都会有,可全方位监控JVM的各项指标。
- JDK的自带工具,包括jmap、jstat等常用命令:# 查看堆内存各区域的使用率以及GC情况jstat -gcutil -h20 pid 1000# 查看堆内存中的存活对象,并按空间排序jmap -histo pid | head -n20# dump堆内存文件jmap -dump:format=b,file=heap pid
- 可视化的堆内存分析工具:JVisualVM、MAT等
- 排查指南
- 查看监控,以了解出现问题的时间点以及当前FGC的频率(可对比正常情况看频率是否正常)
- 了解该时间点之前有没有程序上线、基础组件升级等情况。
- 了解JVM的参数设置,包括:堆空间各个区域的大小设置,新生代和老年代分别采用了哪些垃圾收集器,然后分析JVM参数设置是否合理。
- 再对步骤1中列出的可能原因做排除法,其中元空间被打满、内存泄漏、代码显式调用gc方法比较容易排查。
- 针对大对象或者长生命周期对象导致的FGC,可通过 jmap -histo 命令并结合dump堆内存文件作进一步分析,需要先定位到可疑对象。
- 通过可疑对象定位到具体代码再次分析,这时候要结合GC原理和JVM参数设置,弄清楚可疑对象是否满足了进入到老年代的条件才能下结论。
排查实战
01 从一次FGC频繁的线上案例说起
去年10月份,我们的广告召回系统在程序上线后收到了FGC频繁的系统告警,通过下面的监控图可以看到:平均每35分钟就进行了一次FGC。而程序上线前,我们的FGC频次大概是2天一次。下面,详细介绍下该问题的排查过程。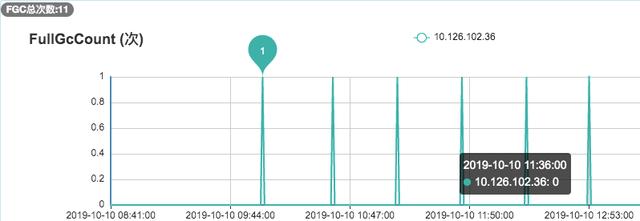
1. 检查JVM配置
通过以下命令查看JVM的启动参数:
ps aux | grep “applicationName=adsearch”
-Xms4g -Xmx4g -Xmn2g -Xss1024K -XX:ParallelGCThreads=5 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+UseCMSCompactAtFullCollection -XX:CMSInitiatingOccupancyFraction=80
可以看到堆内存为4G,新生代为2G,老年代也为2G,新生代采用ParNew收集器,老年代采用并发标记清除的CMS收集器,当老年代的内存占用率达到80%时会进行FGC。
进一步通过 jmap -heap 7276 | head -n20 可以得知新生代的Eden区为1.6G,S0和S1区均为0.2G。
2. 观察老年代的内存变化
通过观察老年代的使用情况,可以看到:每次FGC后,内存都能回到500M左右,因此我们排除了内存泄漏的情况。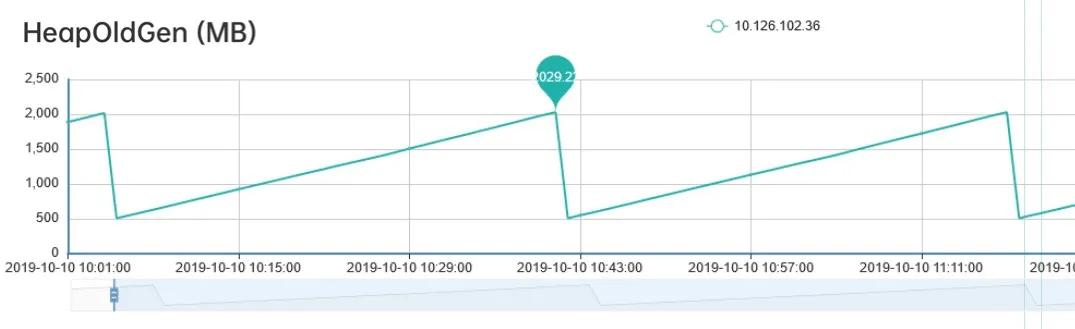
3. 通过jmap命令查看堆内存中的对象
通过命令 jmap -histo 7276 | head -n20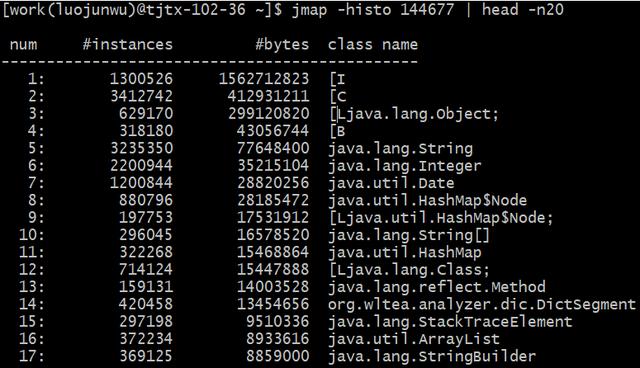
上图中,按照对象所占内存大小排序,显示了存活对象的实例数、所占内存、类名。可以看到排名第一的是:int[],而且所占内存大小远远超过其他存活对象。至此,我们将怀疑目标锁定在了 int[] .
4. 进一步dump堆内存文件进行分析
锁定 int[] 后,我们打算dump堆内存文件,通过可视化工具进一步跟踪对象的来源。考虑堆转储过程中会暂停程序,因此我们先从服务管理平台摘掉了此节点,然后通过以下命令dump堆内存:
jmap -dump:format=b,file=heap 7276
通过JVisualVM工具导入dump出来的堆内存文件,同样可以看到各个对象所占空间,其中int[]占到了50%以上的内存,进一步往下便可以找到 int[] 所属的业务对象,发现它来自于架构团队提供的codis基础组件。
5. 通过代码分析可疑对象
通过代码分析,codis基础组件每分钟会生成约40M大小的int数组,用于统计TP99 和 TP90,数组的生命周期是一分钟。而根据第2步观察老年代的内存变化时,发现老年代的内存基本上也是每分钟增加40多M,因此推断:这40M的int数组应该是从新生代晋升到老年代。
我们进一步查看了YGC的频次监控,通过下图可以看到大概1分钟有8次左右的YGC,这样基本验证了我们的推断:因为CMS收集器默认的分代年龄是6次,即YGC 6次后还存活的对象就会晋升到老年代,而codis组件中的大数组生命周期是1分钟,刚好满足这个要求。
至此,整个排查过程基本结束了,那为什么程序上线前没出现此问题呢?通过上图可以看到:程序上线前YGC的频次在5次左右,此次上线后YGC频次变成了8次左右,从而引发了此问题。
6. 解决方案
为了快速解决问题,我们将CMS收集器的分代年龄改成了15次,改完后FGC频次恢复到了2天一次,后续如果YGC的频次超过每分钟15次还会再次触发此问题。当然,我们最根本的解决方案是:优化程序以降低YGC的频率,同时缩短codis组件中int数组的生命周期,这里就不做展开了。
- 在什么情况下,GC会对程序产生影响?
不管YGC还是FGC,都会造成一定程度的程序卡顿(即Stop The World问题:GC线程开始工作,其他工作线程被挂起),即使采用ParNew、CMS或者G1这些更先进的垃圾回收算法,也只是在减少卡顿时间,而并不能完全消除卡顿。
那到底什么情况下,GC会对程序产生影响呢?根据严重程度从高到底,我认为包括以下4种情况:
- FGC过于频繁:FGC通常是比较慢的,少则几百毫秒,多则几秒,正常情况FGC每隔几个小时甚至几天才执行一次,对系统的影响还能接受。但是,一旦出现FGC频繁(比如几十分钟就会执行一次),这种肯定是存在问题的,它会导致工作线程频繁被停止,让系统看起来一直有卡顿现象,也会使得程序的整体性能变差。
- YGC耗时过长:一般来说,YGC的总耗时在几十或者上百毫秒是比较正常的,虽然会引起系统卡顿几毫秒或者几十毫秒,这种情况几乎对用户无感知,对程序的影响可以忽略不计。但是如果YGC耗时达到了1秒甚至几秒(都快赶上FGC的耗时了),那卡顿时间就会增大,加上YGC本身比较频繁,就会导致比较多的服务超时问题。
- FGC耗时过长:FGC耗时增加,卡顿时间也会随之增加,尤其对于高并发服务,可能导致FGC期间比较多的超时问题,可用性降低,这种也需要关注。
- YGC过于频繁:即使YGC不会引起服务超时,但是YGC过于频繁也会降低服务的整体性能,对于高并发服务也是需要关注的。
其中,「FGC过于频繁」和「YGC耗时过长」,这两种情况属于比较典型的GC问题,大概率会对程序的服务质量产生影响。剩余两种情况的严重程度低一些,但是对于高并发或者高可用的程序也需要关注。

若有收获,就点个赞吧
0 人点赞
