- 大数据是海量数据或大量数据,规模大到无法通过目前主流的计算机系统在合理时间内获取、存储、管理、处理并提炼以帮助使用者决策
- 海量数据从原始数据源到产生价值,期间会经过存储、清洗、挖掘、分析等多个环节
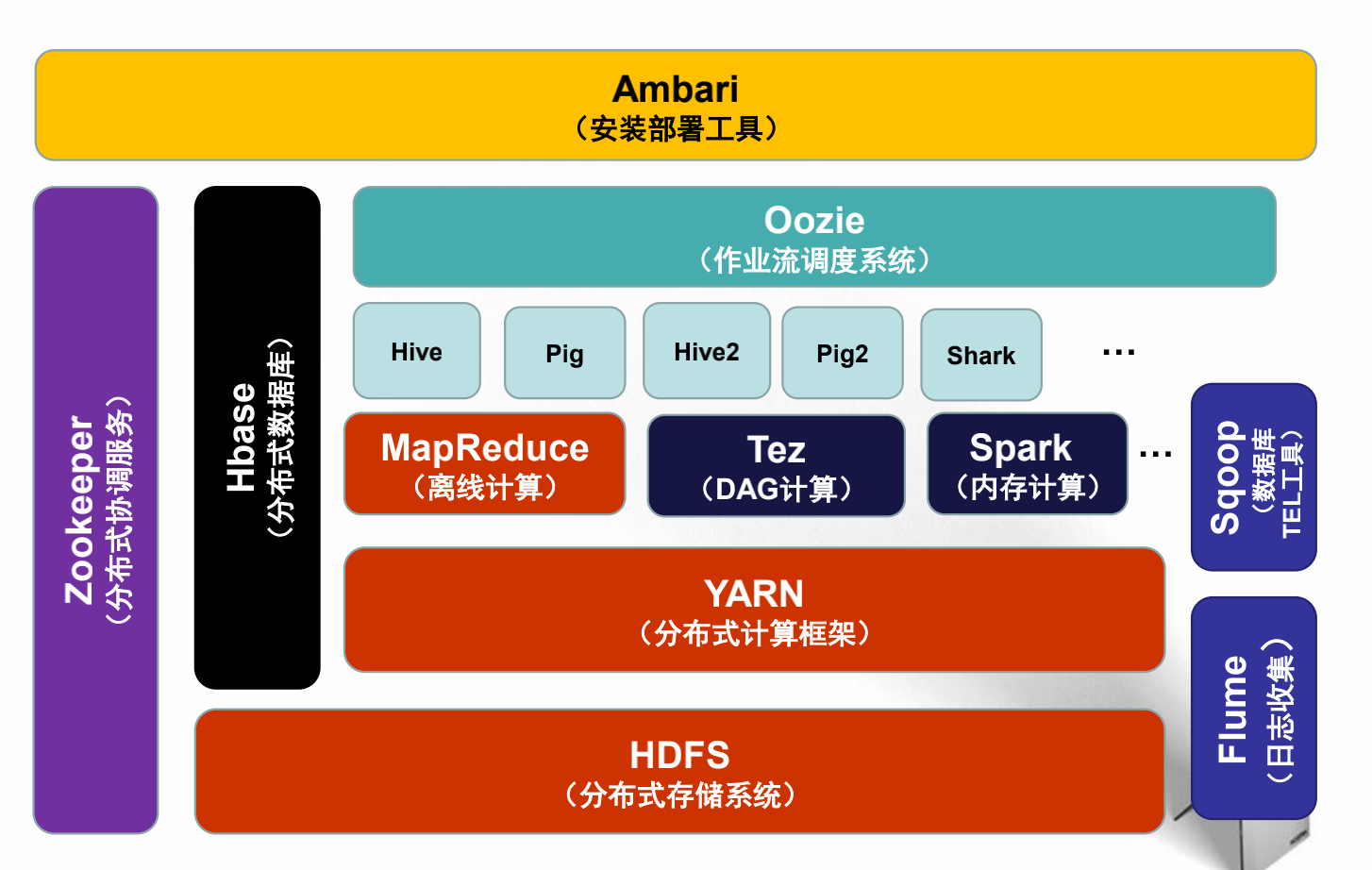
- 分布式系统基础架构Hadoop;HDFS为海量的数据提供了存储;MapReduce则为海量的数据提供了并行计算,从而大大提高了计算效率
- Hadoop在企业中的应用架构

- HDFS(分布式文件系统)
将文件切分成等大的数据块,存储到多台机器上
将数据切分、容错、负载均衡等功能透明化
可将HDFS看成一个容量巨大、具有高容错性的磁盘
- YARN(资源管理系统)
负责集群的资源管理和调度
使得多种计算框架可以运行在一个集群中
良好的扩展性、高可用性
对多种类型的应用程序进行统一管理和调度
自带了多种多用户调度器,适合共享集群环境
- MapReduce(分布式计算框架)
适合PB级以上海量数据的离线处理
- Hive(基于MR的数据仓库)
使用HQL(类SQL)进行离线数据处理
- Pig
适合于使用 Hadoop 和 MapReduce 平台来查询大型半结构化数据集,Pig能够让你专心于数据及业务本身,而不是纠结于数据的格式转换以及MapReduce程序的编写。本质是上来说,当你使用Pig进行处理时,Pig本身会在后台生成一系列的MapReduce操作来执行任务,Pig是一种数据流语言和运行环境,用于检索非常大的数据集。
- Spark内存计算:
基于内存计算的大数据并行计算框架,基于DAG的任务调度执行机制
- Shark开源的分布式和容错内存分析系统:
实时的查询分析数据
- Sqoop数据库ELT工具:
用于在Hadoop(Hive)和关系型数据库之间传输数据的工具
- Flume日志收集:
分布式的海量日志采集、聚合和传输的系统,支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力
- Hadoop生态系统
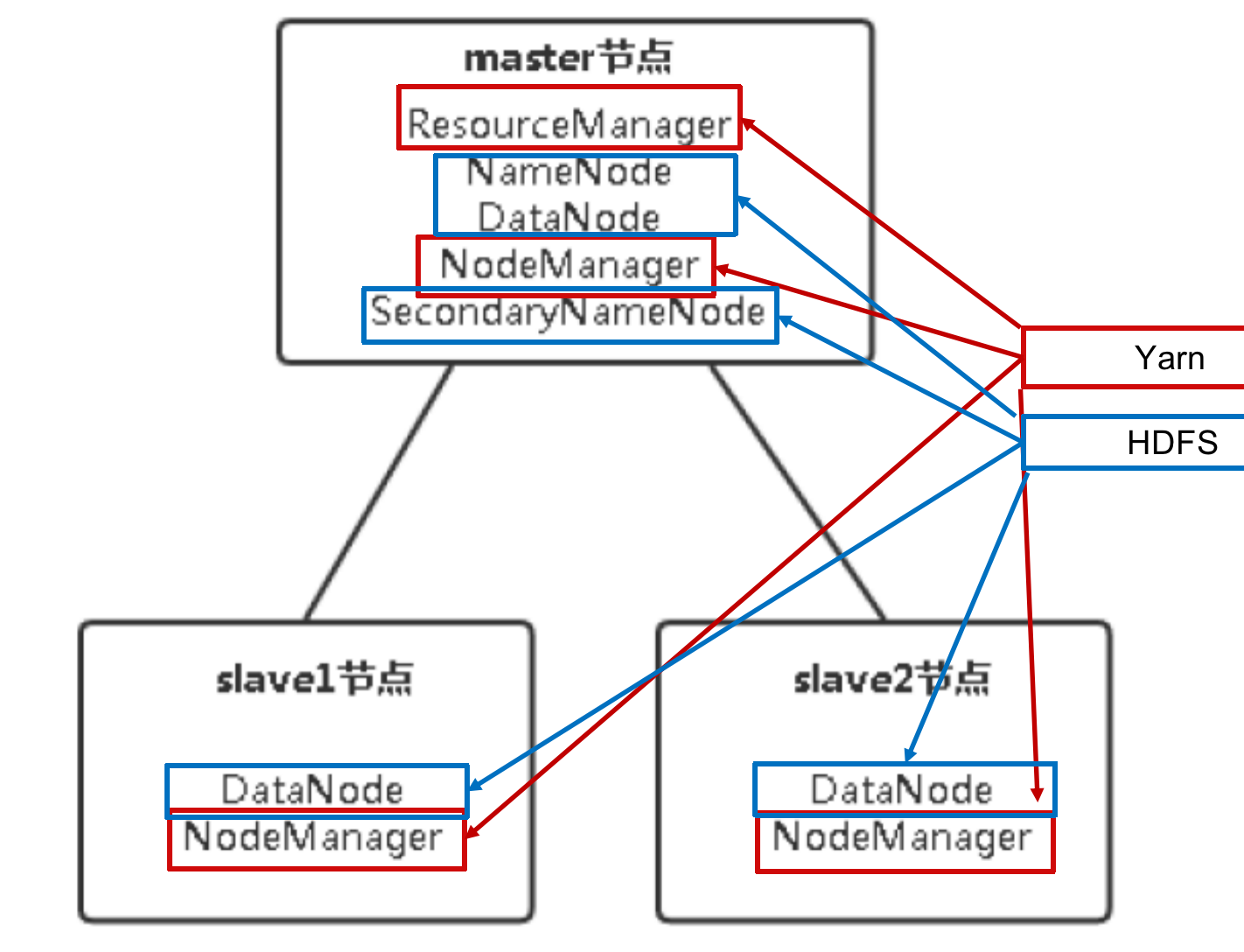
- 各个节点的作用


海量其规模巨大到无法通过目前主
流的计算机系统在合理时间内获取、存储、管理、处

若有收获,就点个赞吧
0 人点赞
