视图
什么是视图?
有一张表,表里面存放的是所有的 公司员工的工资信息。这个信息是比较敏感,不同职位权限不一样,比如老板可以看到员工的工资,但是员工不能看老板的。
创建视图等于 在一张表上 创建一些虚拟表,专门针对不同的用户设置不同的查看权限。
老板可以查看所有信息
select * from emps
经理可以查看 经理,员工
select * from emps where job_title in ("经理","员工");
员工可以看员工
select * from emps where job_title = "员工";
基本语法
create view 视图名字asselect 语句;
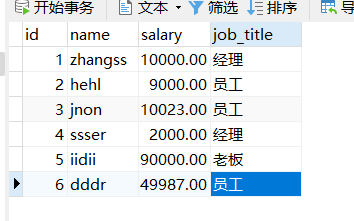
为老板创建专门视图
CREATE VIEW bossasselect * FROM emps;
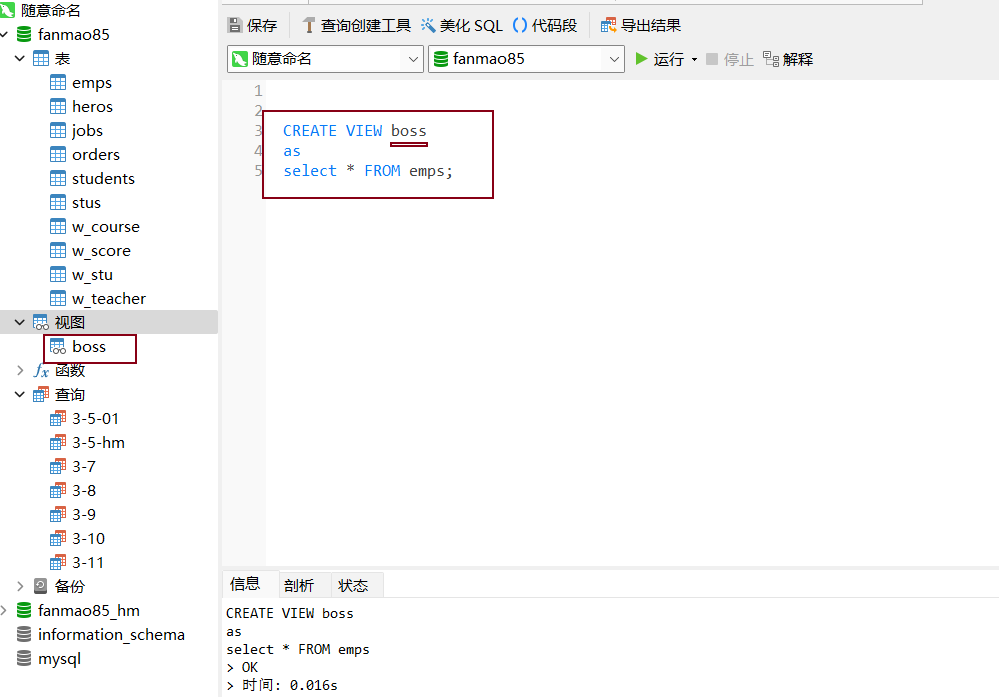
查看视图
select * from 视图名字
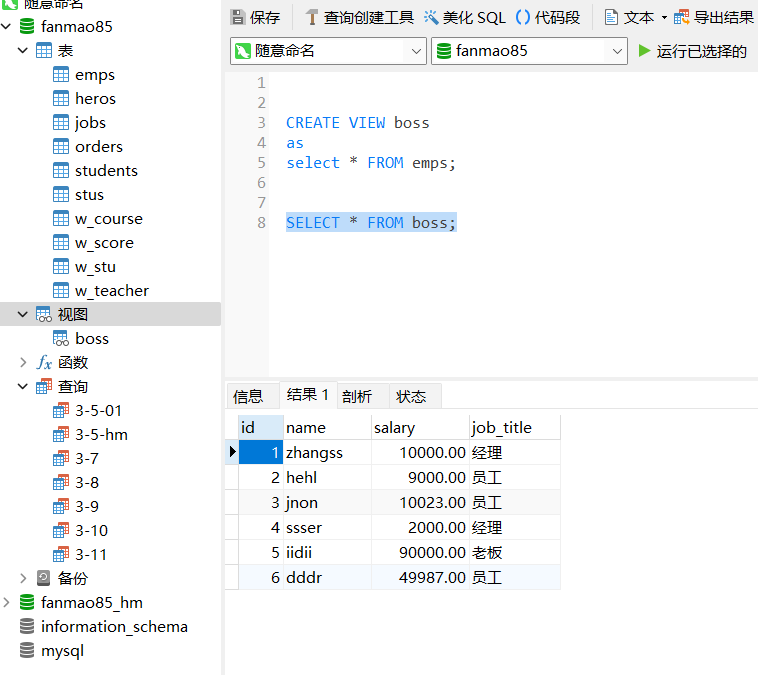
创建经理 视图 manager
create view managerasselect * from empswhere job_title in("经理","员工");
创建员工 视图 employee
create view employeeasselect * from empswhere job_title in("员工");
删除视图
DROP VIEW boss;
事务
在企业应用中,举个例子,电商系统中, 手机app 上下了一个订单,购买一件商品。
商品表,
库存表,
订单表,
当你下单成功的时候,库存表中数量会减少1个,同时订单表中会增加1条新记录。
这两个相关联的表要同时发生这些操作, 这个就叫事务。
事务具有一致性。
如果两个表中 订单表改变,库存表没变,这就是一个bug。
存储过程
可以将一些比较长的查询语句放在存储过程中,使用的时候只需要调用存储过程即可。
定义存储过程
基本语法
delimiter $$ -- 声明临时的结束符号为 $$ 创建存储过程之前的固定用法。CREATE PROCEDURE boss() -- 创建存储过程BEGIN -- begin end 固定SELECT * from emps; -- 语句END$$ -- 使用$$ 作为结束符delimiter ; -- 改回原来 ; 作为结束符。-- 调用存储过程CALL boss();
存储过程的参数
在调用存储过程的时候,比如要查看经理对应的数据,平时写sql语句
select * from emps where power <=8;
查看老板
select * from emps where power <=9;
查看员工
select * from emps where power<=0;
上面的语句,除了后面的 值不一样,其他操作都一样,可以将这个值设置为变量。 等call调用的时候 你想看哪个权限,只需要输入对应的权限值就可以了。
delimiter $$ -- 声明临时的结束符号为 $$ 创建存储过程之前的固定用法。
CREATE PROCEDURE boss(in x integer) -- 创建存储过程
BEGIN -- begin end 固定
SELECT * from emps where power <= x; -- 语句 x为变量, 传入的时候可以是任意值
END$$ -- 使用$$ 作为结束符
delimiter ; -- 改回原来 ; 作为结束符。
-- 调用存储过程
-- 添加对应的值
CALL boss(9); -- 老板的权限值为9
call boss(8); -- 经理的权限值为8
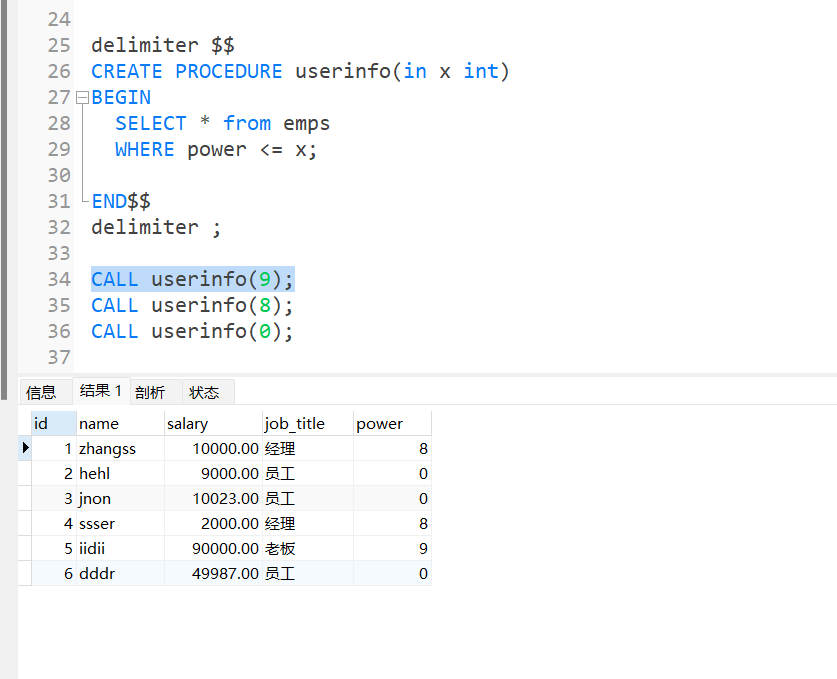
通过传入不同的值 可以方便的进行操作。
存储过程批量添加数据
插入一条数据使用 insert into 的方式。
往emps 表中添加一条数据
insert into emps
(name,salary,job_title,power)
values
('zhangsan',10000+floor(rand()*90000),"经理",8);
使用存储过程中
delimiter $$
CREATE PROCEDURE add_data()
BEGIN
DECLARE i INT DEFAULT 1; -- 声明变量i的值默认为1
REPEAT -- 开始循环
insert into emps
(name,salary,job_title,power)
values
('zhangsan',10000+floor(rand()*90000),"经理",8);
set i=i+1; -- 每次添加一条数据之后 将i的值递增1
UNTIL i=10000 END REPEAT; -- 当i的值为10000的时候 停止循环
END $$
delimiter ;
CALL add_data();
删除存储过程
DROP PROCEDURE add_data;
索引
添加索引可以提高sql查询的效率。
语法
create index nameindex on emps (name);
在emps 表中的name 字段添加索引。
删除索引
使用 drop index 删除索引。
DROP INDEX nameindex on emps;
面试问题
- 什么视图?
视图是在原有的表上创建一个虚拟的表,根据条件将原表中的数据通过过滤之后放在视图,使用方式与表的使用方式原理是类似的。一般公司中也是开发创建的,最多做下查询操作,使用不多。
- 什么是事务? 如何测试?
MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你既需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务!
测试的时候主要查看数据库,比如删除一个用户账号信息,那么要查看对应的其他的信息(相关的表)做一次查询操作,查看数据是否更新。
- 如何往表中批量加入1万条数据?
- 使用navicat 的导入功能。 将数据在Excel文件做好,做好之后,使用navicat的导入功能进行导入。
- 使用存储过程的方式。

若有收获,就点个赞吧
0 人点赞
