基本语法
group by 后跟需要分组的字段进行分组查询。
select age from studentgroup by age;
分组也可以去除重复数据,使用分组:常用于在单个表中的查询结果。进行汇总数据。
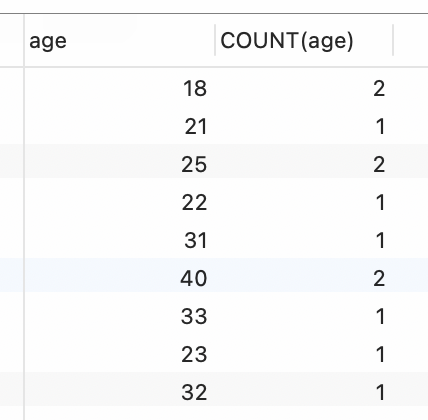
统计班级中学生的age,并统计出每个age的人数。
SELECT age, COUNT(age) from studentGROUP BY age;
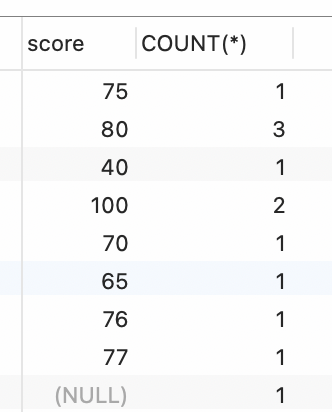
统计班级student表中学生的分数score,每个得分的人数统计出来。 ```sql — 统计 score SELECT score, COUNT(*) from student GROUP BY score;
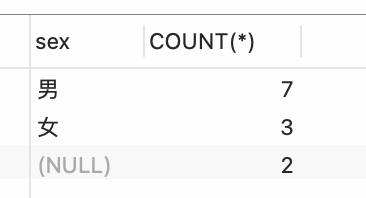
3. 统计班级student表中学生的性别,并统计出每个性别的人数。```sql-- 统计 sexSELECT sex, COUNT(*) from studentGROUP BY sex;
分组与排序
在进行分组的时候,主要使用语法 group by, 分完组的数据,也可以进行排序 order by。
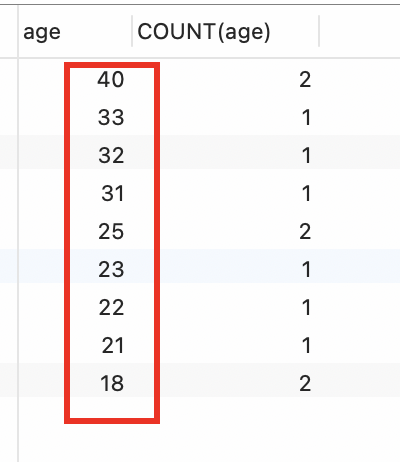
按照年龄age 进行分组,统计每个age对应的人数,并按age的大小进行降序排序。
SELECT age,COUNT(age) from studentGROUP BY ageORDER BY age DESC
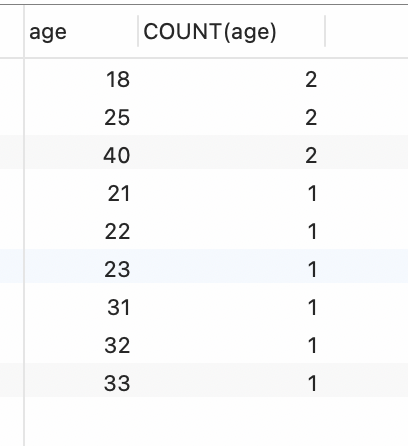
按照年龄age 进行分组,统计每个age对应的人数,并按人数的大小进行降序排序。
SELECT age,COUNT(age) from studentGROUP BY ageORDER BY COUNT(age) DESC, age
having 分组的条件
使用group by 进行分组,分组完成之后可以对返回的结果进行条件过滤。
having 放在group by 之后, 跟 group by 一起使用,不能单独使用。
以age字段进行分组,统计每个age的人数,查询人数为2的信息;
select age, count(*) from studentgroup by agehaving count(*) = 2;

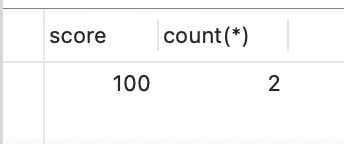
以score字段进行分组,统计每个分数的人数,查询人数为2的相关信息;
select score,count(*) from studentgroup by scorehaving count(*) = 2;
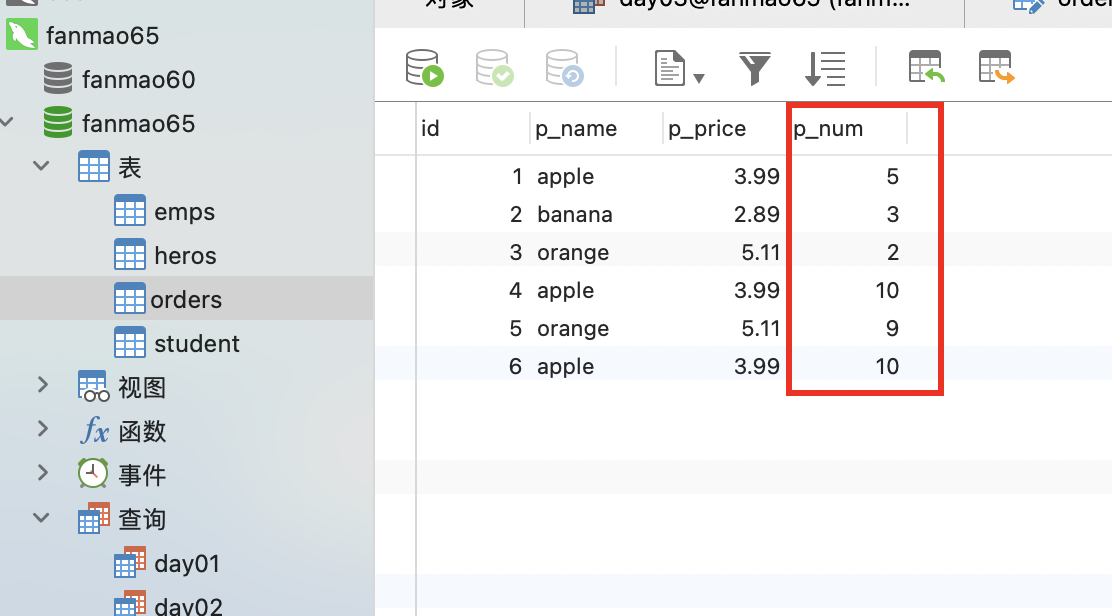
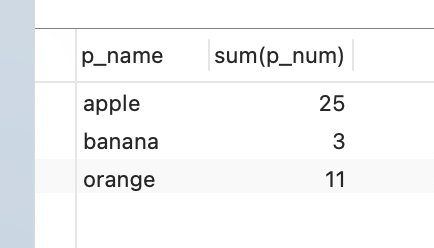
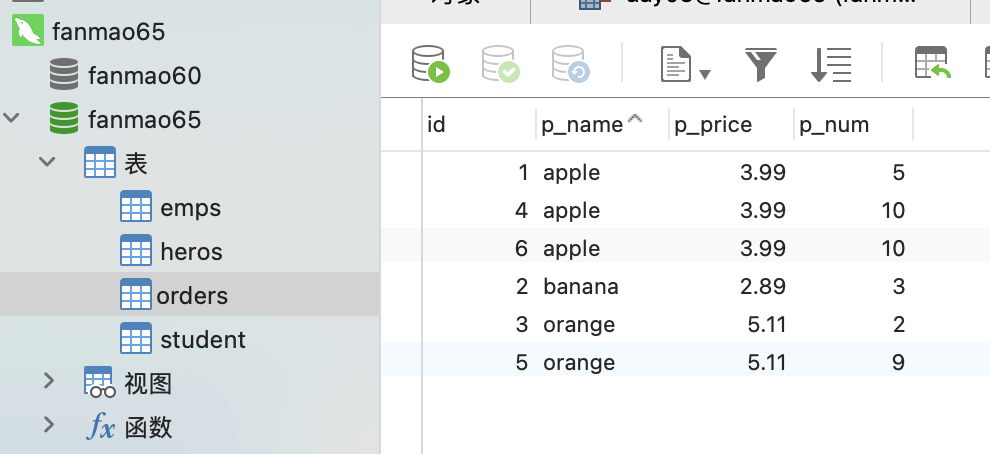
统计order 表中 每种水果p_name,销售总数量 p_num;
-- 使用 sum 函数进行数据统计select p_name, sum(p_num) from ordersGROUP BY p_name;
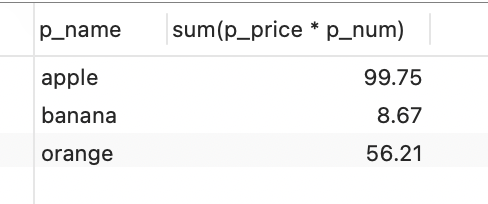
- 统计每种水果的销售总额(p_price*p_num)。
SELECT p_name, sum(p_price * p_num) from ordersGROUP BY p_name;
总结
使用分组的场景主要是做一些数据汇总的操作,比如统计销售每种商品销售的数量,销售的总额。
使用方式:
- 先确定分组的字段。
- 使用 sum,count等聚合函数对相关字段进行对应的运算。
统计orders 表中,每种水果的 订单数(count()),销售总额(sum(pricenum)),销售数量,销售最大单价,销售最小单价,销售平均单价。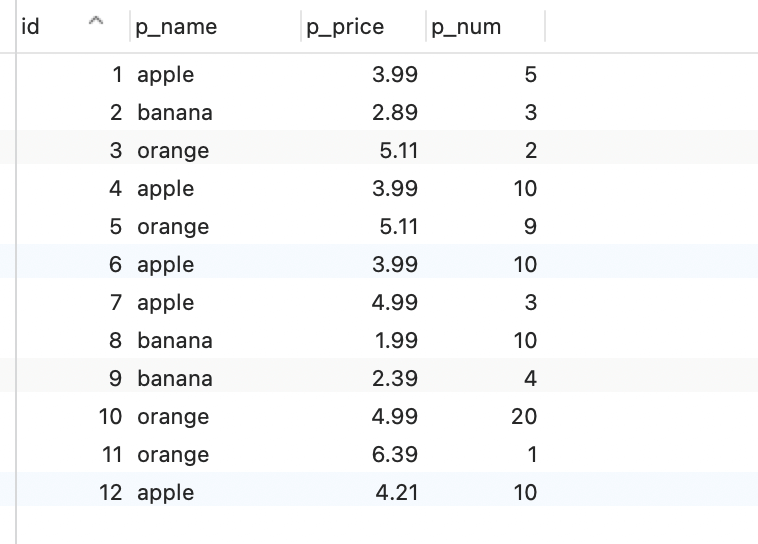
select p_name, count(*) 订单数,sum(p_price*p_num) 销售总额,sum(p_num) 销售数量,max(p_price) 最大价格,min(p_price) 最小价格,avg(p_price) 平均价格 from ordersgroup by p_name;

查询订单数量大于3的商品名称,订单数量,销售数量。
SELECT p_name,SUM(p_num)销售数量,COUNT(*)订单数 FROM `orders`GROUP BY p_nameHAVING 订单数>3; -- 过滤
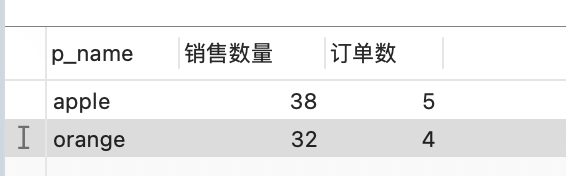
查询订单数量大于3并且销售数量不低于20的商品名称,订单数量,销售数量。
select p_name, count(*)订单数量, sum(p_num) 销售数量 from ordersgroup by p_namehaving 订单数量>3 and 销售数量>=20;

- 按照年龄age 进行分组,统计年龄人数最多的 年龄 age。
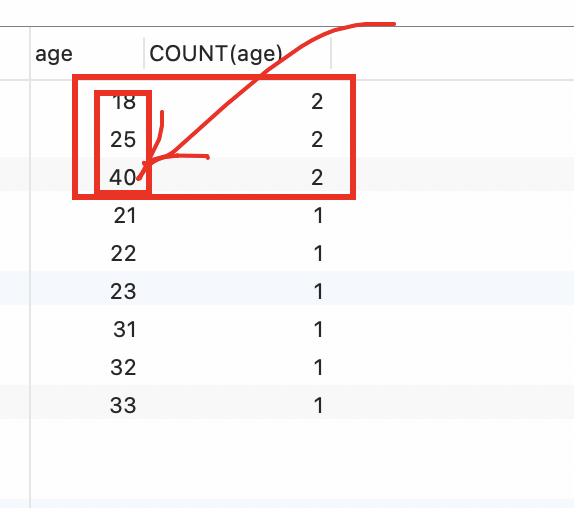
分析:
- 先找到 人数最多。
b. 根据人数找对应的年龄select count(age) from studentgroup by age -- 分组。ageorder by count(age) desc -- 按照 人数 排序limit 1 -- 最大人数
c. 两个查询使用子查询的方式合并到一句SELECT age ,count(*) from studentGROUP BY ageHAVING COUNT(*) = 2
SELECT age ,count(*) from studentGROUP BY ageHAVING COUNT(*) = (select count(age) from studentgroup by age -- 分组。ageorder by count(age) desc -- 按照 人数 排序limit 1 -- 最大人数);

练习
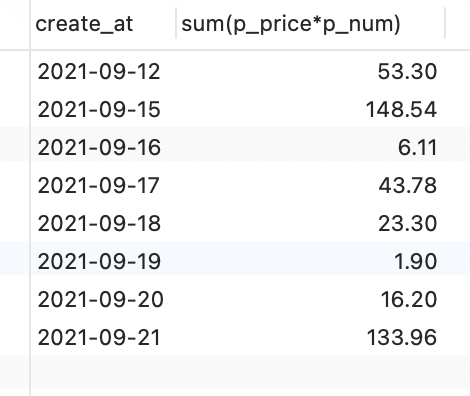
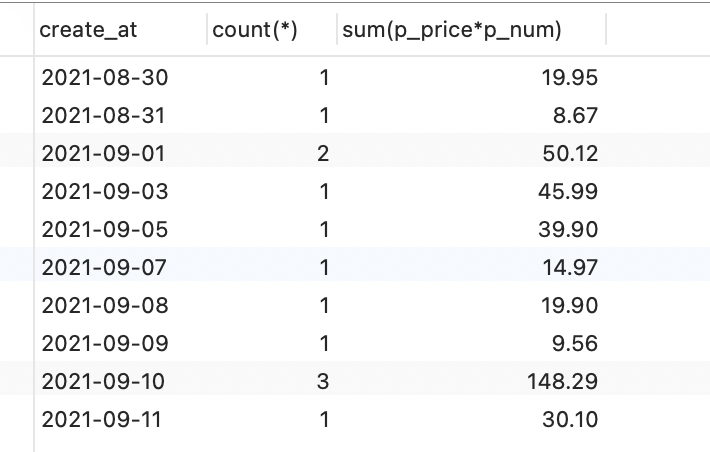
统计每天的订单数量,订单总额
SELECT create_at,count(*), sum(p_price*p_num) from ordersGROUP BY create_at;
统计2021年每个月的订单数量,订单总额
- 分析,先把 日期
2021-08-30格式化2021-08select date_format(create_at,"%Y-%m") from orders;
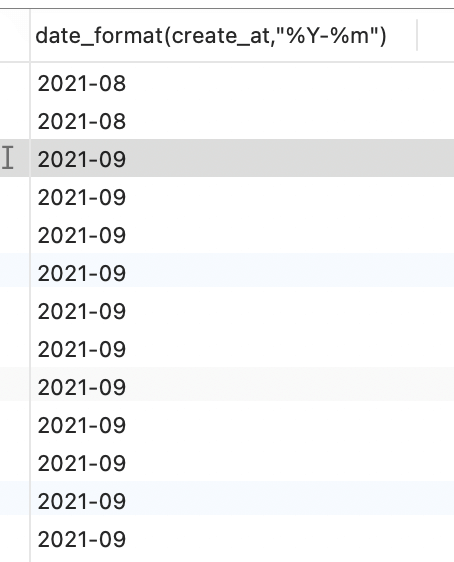
b. 按照格式化之后的数据进行分组;select date_format(create_at,'%Y-%m'),count(*),sum(p_price*p_num) from ordersgroup by date_format(create_at,'%Y-%m');

- 分析,先把 日期
统计2021年9月份每天的订单数量,订单总额
- 分析:因为要查询9月份的数据,可以先使用 where 条件过滤 create_at 字段
select * from orderswhere create_at like "2021-09%";
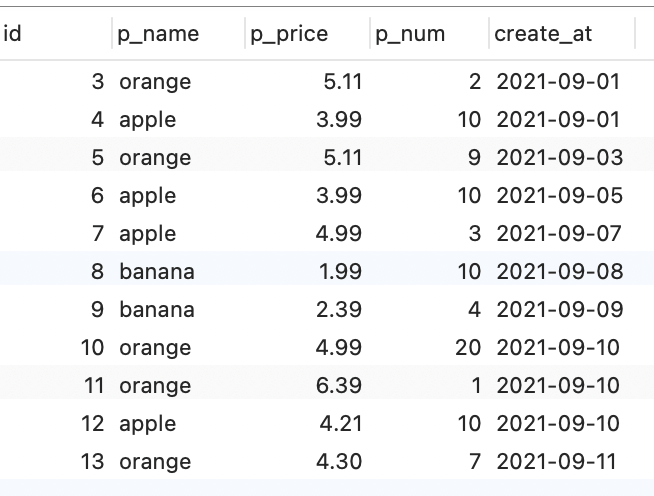
- 分析:因为要查询9月份的数据,可以先使用 where 条件过滤 create_at 字段
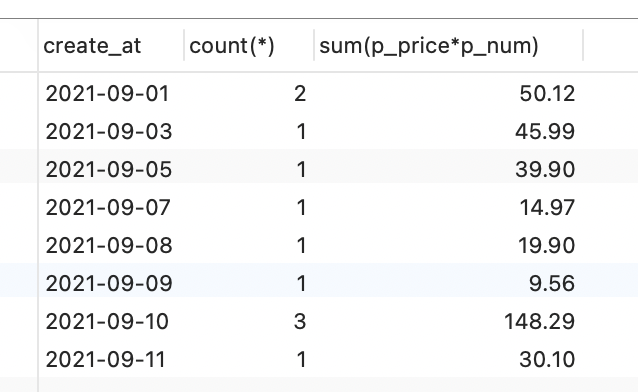
b. 9月份的数据查询出来之后,再进行分组;
select create_at,count(*),sum(p_price*p_num) from orderswhere create_at like "2021-09%" -- 先过滤出来9月份的数据group by create_at; -- 按照每天进行分组;
应用场景
统计最近10天的订单数; — 使用 datediff() 计算
- 分析:先过滤出来最近10 使用
datediff(now(),create_at) <= 10-- 最近10天之内的数据SELECT * from ordersWHERE DATEDIFF(NOW(),create_at) <= 10 ;
b. 再进行分组select create_at, count(*) from orderswhere datediff(now(),create_at) <= 10 -- 过滤日期group by create_at; -- 进行分组
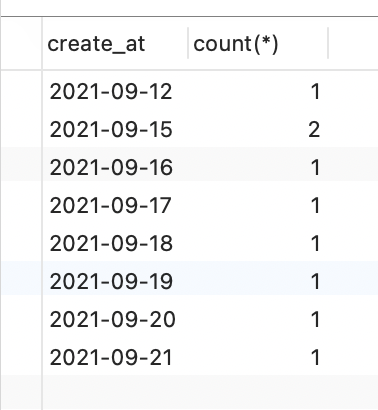
- 分析:先过滤出来最近10 使用
统计最近10天的销售额;
原理与上面原理一样。先过滤出 最近10天的所有数据,再进行分组查询;
select create_at, sum(p_price*p_num) from orderswhere datediff(now(),create_at) <= 10 -- 过滤日期group by create_at; -- 进行分组
查询顺序
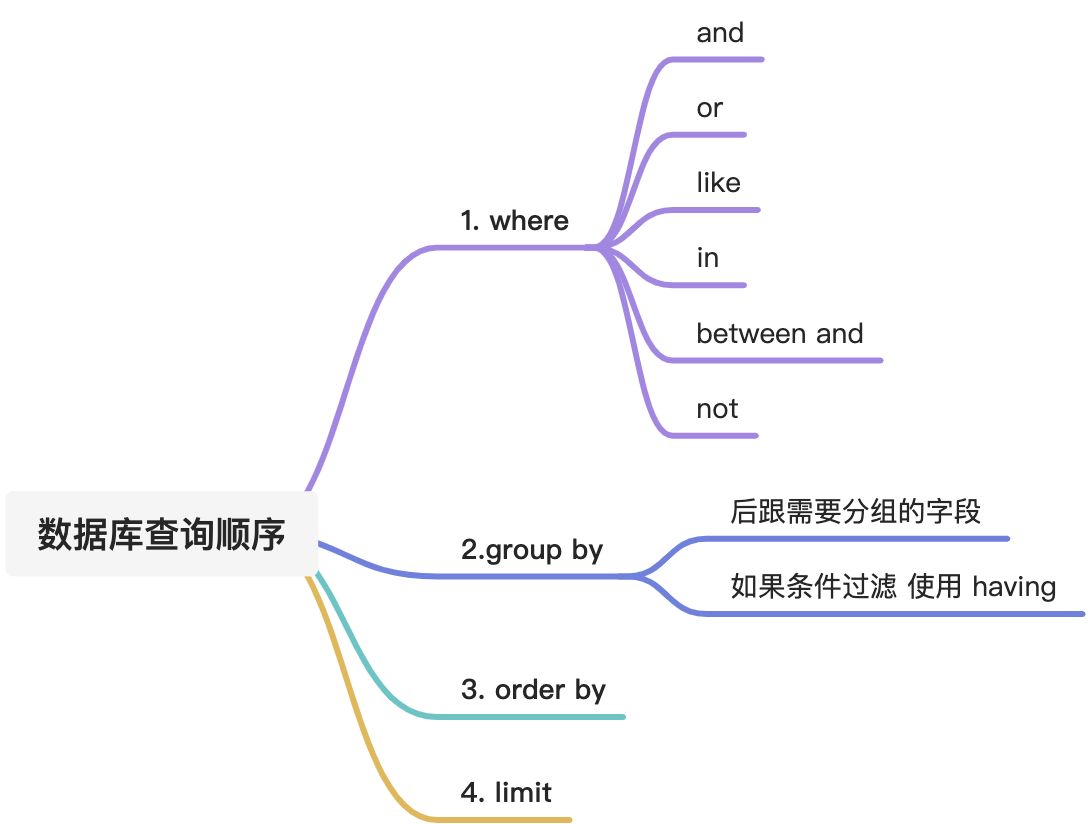
使用这些查询语句的时候,语法顺序
| where |
|---|
| group by … having |
| order by |
| limit |
面试题
- count(*), count(name), count(1) 之间的区别;
统计结果上对比
SELECT count(*), count(score), count(1) from student;
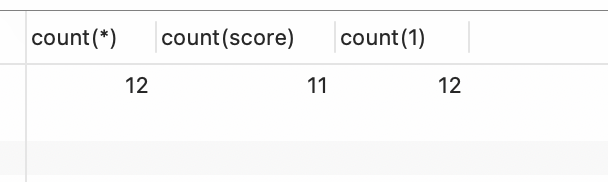
count(name) 如果为空,不统计。
count(*), count(1) 都会统计。
执行效率
count(1) 比count(*) 速度快。
- 查询的时候,去重有哪些方法?
distinct
group by 去重。
- 分组查询你使用过吗? 举一个场景;
使用过,统计相关数据的时候,比如:电商里面统计最近10天的订单数的数。 https://www.yuque.com/imhelloworld/bypiud/ltnb1h#CUj24
银行中 最近10天的 每天刷卡次数。
作业
根据订单表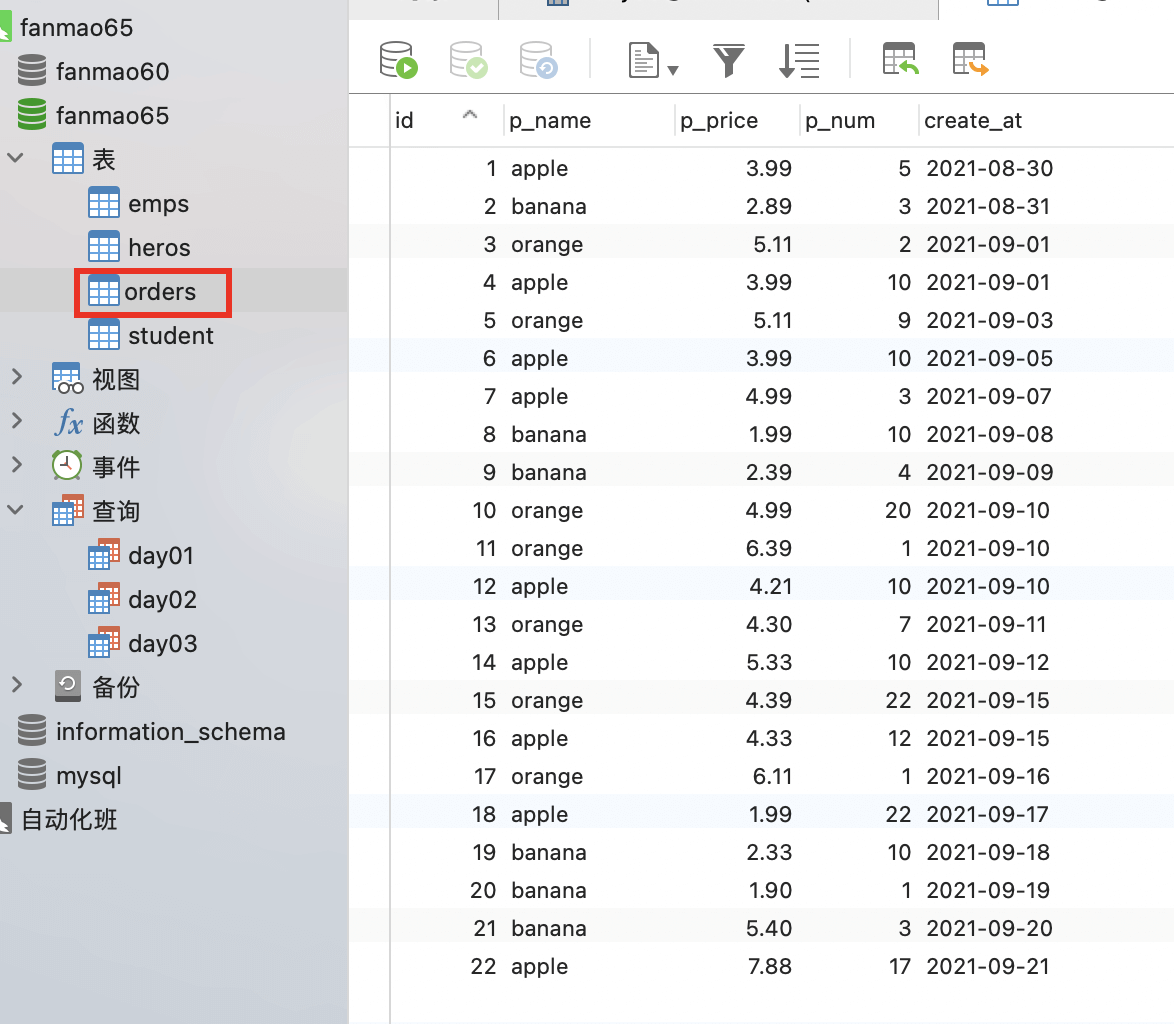
- 查询 单价 (p_price) 大于5 的所有订单;
查询 销售数量(p_num) 在10-20 之间的订单;
-- 查询 单价 (p_price) 大于5 的所有订单;SELECT * FROM ordersWHERE p_price > 5;-- 查询 销售数量(p_num) 在10-20 之间的订单;SELECT *FROM ordersWHERE p_num BETWEEN 10 AND 20 ;
查看 商品名称(p_name)为
apple,orange的订单信息;- 查询 每个订单的 商品名称(p_name) , 商品单价(p_price), 商品数量(p_num), 订单价格,并按订单价格降序; ```python SELECT *FROM orders WHERE p_name in(“apple”,”orange”)
SELECT id,p_name,p_price,p_num,p_nump_price FROM orders ORDER BY p_nump_price desc;
5. 查询 最近1周的订单信息;5. 针对每个订单中商品的单价大于5元的订单进行降序排序;```python-- 查询 最近1周的订单信息;select * from orderswhere datediff(now(),create_at) <=7;-- 针对每个订单中商品的单价大于5元的订单进行降序排序;select * from orderswhere p_price >5order by p_price desc;
- 统计每个商品(p_name)的订单数量,订单总额; ```python 统计每个商品(p_name)的订单数量,订单总额;
SELECT p_name 商品名称,count()订单数量,sum(p_pricep_num)订单总额 FROM orders GROUP BY p_name;
8. 查询商品名称(p_name)以`e` 结尾,每天的订单总额,订单销售总量;```pythonselect create_at,sum(p_num*p_price),count(*) from orderswhere p_name like "%e"group by create_at;
- 统计单个订单中销售数量(p_num)最高的 商品名称(p_name),销售数量,销售单价,订单日期(create_at); ```python — 1. 先找到最大的销售数量 select max(p_num) from orders;
select p_num from orders order by p_num desc limit 1;
— 2 根据数量找订单 select * from orders WHERE p_num = ( select max(p_num) from orders )
10. 统计 销售总量最多的商品的名字,商品销售总量;```python-- 1. 找到每个商品的销售总量select p_name, sum(p_num) from ordersgroup by p_name;-- 2. 最大select sum(p_num) from ordersgroup by p_nameORDER BY SUM(p_num) DESCLIMIT 1;-- 根据最大值找到对应的商品SELECT p_name, sum(p_num) FROM ordersGROUP BY p_nameHAVING SUM(p_num) = (select sum(p_num) from ordersgroup by p_nameORDER BY SUM(p_num) DESCLIMIT 1);
- 统计 销售总量第二多的商品的名字,商品销售总量; ```python — 1. 第二高的销售数量 select distinct(sum(p_num)) from orders group by p_name ORDER BY SUM(p_num) DESC LIMIT 1,1
— SELECT p_name, sum(p_num) FROM orders GROUP BY p_name HAVING SUM(p_num) = ( — 子查询 select distinct(sum(p_num)) from orders group by p_name ORDER BY SUM(p_num) DESC LIMIT 1,1 )
12. 统计 销售总额sum(p_price*p_num)最多的商品名字,销售总额;```python-- 1. 销售总额最大select p_name,sum(p_price*p_num) from ordersgroup by p_nameorder by sum(p_price*p_num) desclimit 1--select p_name,sum(p_price*p_num) from ordersgroup by p_name having sum(p_price*p_num) = (select sum(p_price*p_num) from ordersgroup by p_nameorder by sum(p_price*p_num) desclimit 1);

若有收获,就点个赞吧
0 人点赞
