- 小技巧
- 链表的基本操作
- 206. 反转链表">206. 反转链表
- 237. 删除链表中的节点(神思维)">237. 删除链表中的节点(神思维)
- 83. 删除排序链表中的重复元素">83. 删除排序链表中的重复元素
- 21. 合并两个有序链表(使用dummy)">21. 合并两个有序链表(使用dummy)
- 24. 两两交换链表中的节点(记得画图,常看)">24. 两两交换链表中的节点(记得画图,常看)
- 其他链表操作
- 160. 相交链表(两个指针)">160. 相交链表(两个指针)
- 234. 回文链表(链表中点+反转链表)">234. 回文链表(链表中点+反转链表)
- 328. 奇偶链表">328. 奇偶链表
- 19. 删除链表的倒数第 N 个结点(快慢指针)">19. 删除链表的倒数第 N 个结点(快慢指针)
- 148. 排序链表(归并排序)">148. 排序链表(归并排序)
- 147. 对链表进行插入排序">147. 对链表进行插入排序
小技巧
由于在进行链表操作时,尤其是删除节点时,经常会因为对当前节点进行操作而导致内存或指针出现问题。有两个小技巧可以解决这个问题:
- 一是尽量处理当前节点的下一个节点而非当前节点本身
- 二是建立一个虚拟节点,使其指向当前链表的头节点,这样即使原链表所有的节点全部删除,也会有一个虚拟节点存在,返回 dummy->next即可。
-
链表的基本操作
206. 反转链表
迭代
关键在于一个pre指针,以及一个next指针
class Solution {public:ListNode* reverseList(ListNode* head) {ListNode* prev = nullptr,*next;while(head != nullptr){next = head -> next;head -> next = prev;prev = head;//prev表示前一个节点head = next;//将头节点进行更新}return prev;}};
递归(从后往前)
在递归中,当前节点是操作不了前面的节点的,所以cur->next = pre是不可能的,
- 只能使用cur->next->next= cur,让后面的节点指向当前的节点。
这里从后往前,先进入后面,然后再回归的时候进行操作。
class Solution {public:ListNode* reverseList(ListNode* head) {if (!head || !head->next) {//如果head为空或者,head->next为空返回。return head;}ListNode* newHead = reverseList(head->next);head->next->next = head;head->next = nullptr;return newHead;}};
递归(从前往后)
和迭代一样,从前往后操作,先操作然后进入。需要一个dummy节点。来实现先存储cur->next,然后cur->next = pre,
//只要找到最后一个节点全部都返回。把最后一个节点返回。
class Solution {public:ListNode* reverseList(ListNode* head, ListNode* dummy = nullptr) {if(!head) {return dummy;}ListNode* node = head->next;head->next = dummy;return reverseList(node, head);//只要找到最后一个节点全部都返回。把最后一个节点返回。}};
237. 删除链表中的节点(神思维)
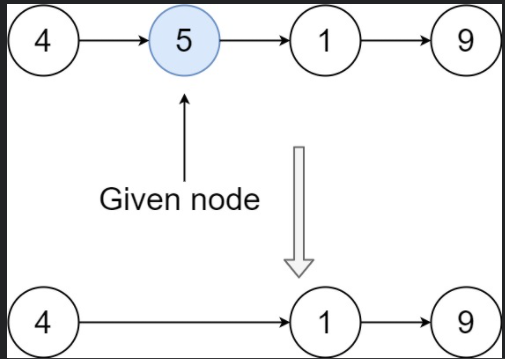
因为链表不知道前面的一个节点是无法完成中间节点的删除的。这里有一个神思维,直接把要删除的节点变成下一个节点,然后把原本不需要删除的下一个节点删除掉。
class Solution {public:void deleteNode(ListNode* node) {node->val=node->next->val;node->next=node->next->next;return ;}};
引发思考
这里为什么不用下面的代码来删除节点呢?
class Solution {public:void deleteNode(ListNode* node) {node = node->next;}};
因为这里的node本质上你可以看作是一个装地址的容器,你改变它的值本质上只是改变了这个容器的值,并没有改变原本链表的结构,只能通过node->next来进入到一个节点里面来改变结构。
83. 删除排序链表中的重复元素
- 需要一个dummy来记住头节点
注意delete养成好习惯,回收堆空间,防止内存泄漏。
class Solution {public:ListNode* deleteDuplicates(ListNode* head) {ListNode *dummy = head;while(dummy&&dummy->next){if(dummy->val==dummy->next->val) {ListNode *next = dummy->next;dummy->next = next->next;delete(next);} else {dummy = dummy->next;}}return head;}};
21. 合并两个有序链表(使用dummy)
迭代
朴实无华的思路,和归并排序里面的排序有点像
class Solution {public:ListNode* l3;ListNode* mergeTwoLists(ListNode *l1, ListNode *l2) {ListNode *dummy = new ListNode(0), *node = dummy;//这里就用到了那个思想,需要一个前置节点dummywhile (l1 && l2) {if (l1->val <= l2->val) {node->next = l1;l1 = l1->next;} else {node->next = l2;l2 = l2->next;}node = node->next;}node->next = l1? l1: l2;return dummy->next;}};
递归
思路想岔了,不应该新建一个节点
- 因为新建的节点很难传递到递归的下一层。
ListNode* head1 = new ListNode();//如果没有后面的就是申请了一个空指针
class Solution {public:ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {if (l1 == nullptr) {return l2;} else if (l2 == nullptr) {return l1;} else if (l1->val < l2->val) {l1->next = mergeTwoLists(l1->next, l2);return l1;} else {l2->next = mergeTwoLists(l1, l2->next);return l2;}}};
class Solution {public:ListNode* head1();ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {dfs(list1, list2, head1);return head1->next;}void dfs(ListNode* list1, ListNode* list2, ListNode* head){if(!list1){head->next = list2;return ;}if(!list2){head->next = list1;return ;}if(list1->val<list2->val){head->next = list1;dfs(list1->next, list2, head->next);} else {head->next = list2;dfs(list1, list2->next, head->next);}}};
24. 两两交换链表中的节点(记得画图,常看)
迭代写法
- 需要一个dummy
画图就会清晰很多
class Solution {public:ListNode* swapPairs(ListNode* head) {ListNode* dummyHead = new ListNode(0);dummyHead->next = head;ListNode* temp = dummyHead;while (temp->next != nullptr && temp->next->next != nullptr) {ListNode* node1 = temp->next;ListNode* node2 = temp->next->next;temp->next = node2;node1->next = node2->next;node2->next = node1;temp = node1;}return dummyHead->next;}};
递归
class Solution {public:ListNode* swapPairs(ListNode* head) {if (head == nullptr || head->next == nullptr) {return head;}ListNode* newHead = head->next;head->next = swapPairs(newHead->next);newHead->next = head;return newHead;}};
其他链表操作
160. 相交链表(两个指针)
从自己的头开始效率会低,从对方的头开始效率会高
class Solution {public:ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {ListNode *l1 = headA,*l2 = headB;while(l1!=l2){l1 = l1?l1->next:headB;l2 = l2?l2->next:headA;}return l1;}};
234. 回文链表(链表中点+反转链表)
先得到链表的中点,然后将后半部分反转
同时遍历,看是否一样
class Solution {public:bool isPalindrome(ListNode* head) {int num = 0;ListNode *mid = head;while(mid){mid = mid->next;num++;}//得到最大长度num = num%2==0? num/2:num/2+1;//取中位数mid = head;for(int i = 0; i < num; i++){mid = mid->next;}mid = reverse(mid);//在中间反转链表while(head&&mid){if(head->val!=mid->val)//从中间开始遍历,不同则为falsereturn false;head = head->next;mid = mid->next;}return true;}ListNode* reverse(ListNode * head){//反转链表ListNode* pre = nullptr;ListNode* next;while(head){next = head->next;head->next = pre;pre = head;head = next;}return pre;}};
328. 奇偶链表
对于原始链表,每个节点都是奇数节点或偶数节点。头节点是奇数节点,头节点的后一个节点是偶数节点,相邻节点的奇偶性不同。因此可以将奇数节点和偶数节点分离成奇数链表和偶数链表,然后将偶数链表连接在奇数链表之后,合并后的链表即为结果链表。
even1指的是偶链表的尾节点,odd指的是奇数链表的偶节点。
class Solution {public:ListNode* oddEvenList(ListNode* head) {if(!head) return head;ListNode* odd = head, * even = head->next;ListNode* even1 = even;while(even1&&even1->next){odd->next = even1->next;odd = odd->next;even1->next = odd->next;even1 = even1->next;}odd->next = even;return head;}};
19. 删除链表的倒数第 N 个结点(快慢指针)
使用一个快指针先走到n的地方
- 然后使用一个慢指针从头开始,这样的话,当快指针到达链表尾部的时候,慢指针就到了倒数第n个地方,因为快指针和慢指针之间差n个。
注意删除的是头节点的情况
class Solution { public: ListNode* removeNthFromEnd(ListNode* head, int n) { ListNode* dummy = new ListNode(0), *pre;//使用一个dummy来判断链表是头节点的情况。 ListNode* fast = dummy, *low = dummy; dummy->next = head; int num = 0; while(num<n){ num++; fast = fast->next; } while(fast){ fast=fast->next; pre = low; low = low->next; } pre->next = low->next; pre = dummy->next; delete(dummy);//注意防止内存泄漏的情况 return pre; } };148. 排序链表(归并排序)
归并排序基于分治算法。最容易想到的实现方式是自顶向下的递归实现,考虑到递归调用的栈空间,自顶向下归并排序的空间复杂度是 )O(logn)。如果要达到 O(1) 的空间复杂度,则需要使用自底向上的实现方式。
自顶向下
对链表自顶向下归并排序的过程如下。
找到链表的中点,以中点为分界,将链 表拆分成两个子链表。寻找链表的中点可以使用快慢指针的做法,快指针每次移动 2 步,慢指针每次移动 11步,当快指针到达链表末尾时,慢指针指向的链表节点即为链表的中点。
- 对两个子链表分别排序。
将两个排序后的子链表合并,得到完整的排序后的链表。可以使用「21. 合并两个有序链表」的做法,将两个有序的子链表进行合并。
class Solution { public: ListNode* sortList(ListNode* head) { return sortList(head, nullptr); } ListNode* sortList(ListNode* head, ListNode* tail) { if (head == nullptr) { return head; } if (head->next == tail) { head->next = nullptr;//为每个小子集加上nullptr结尾 return head; } ListNode* slow = head, *fast = head; while (fast != tail) { slow = slow->next; fast = fast->next; if (fast != tail) { fast = fast->next; } } ListNode* mid = slow; return merge(sortList(head, mid), sortList(mid, tail)); } ListNode* merge(ListNode* head1, ListNode* head2) { ListNode* dummyHead = new ListNode(0); ListNode* temp = dummyHead, *temp1 = head1, *temp2 = head2; while (temp1 != nullptr && temp2 != nullptr) { if (temp1->val <= temp2->val) { temp->next = temp1; temp1 = temp1->next; } else { temp->next = temp2; temp2 = temp2->next; } temp = temp->next; } if (temp1 != nullptr) { temp->next = temp1; } else if (temp2 != nullptr) { temp->next = temp2; } return dummyHead->next; } };自底向上
用 subLength 表示每次需要排序的子链表的长度,初始subLength=1。
- 每次将链表拆分成若干个长度为 subLength 的子链表(最后一个子链表的长度可以小于 subLength),按照每两个子链表一组进行合并,合并后即可得到若干个长度为 subLength×2 的有序子链表(最后一个子链表的长度可以小于 subLength×2)。合并两个子链表仍然使用「21. 合并两个有序链表」的做法。
将subLength 的值加倍,重复第 2 步,对更长的有序子链表进行合并操作,直到有序子链表的长度大于或等于 length,整个链表排序完毕。
class Solution { public: ListNode* sortList(ListNode* head) { if (head == nullptr) { return head; } int length = 0; ListNode* node = head; while (node != nullptr) { length++; node = node->next; } ListNode* dummyHead = new ListNode(0, head); for (int subLength = 1; subLength < length; subLength <<= 1) { ListNode* prev = dummyHead, *curr = dummyHead->next; while (curr != nullptr) { ListNode* head1 = curr; for (int i = 1; i < subLength && curr->next != nullptr; i++) { curr = curr->next; } ListNode* head2 = curr->next; curr->next = nullptr; curr = head2; for (int i = 1; i < subLength && curr != nullptr && curr->next != nullptr; i++) { curr = curr->next; } ListNode* next = nullptr; if (curr != nullptr) { next = curr->next; curr->next = nullptr; } ListNode* merged = merge(head1, head2); prev->next = merged; while (prev->next != nullptr) { prev = prev->next; } curr = next; } } return dummyHead->next; } ListNode* merge(ListNode* head1, ListNode* head2) { ListNode* dummyHead = new ListNode(0); ListNode* temp = dummyHead, *temp1 = head1, *temp2 = head2; while (temp1 != nullptr && temp2 != nullptr) { if (temp1->val <= temp2->val) { temp->next = temp1; temp1 = temp1->next; } else { temp->next = temp2; temp2 = temp2->next; } temp = temp->next; } if (temp1 != nullptr) { temp->next = temp1; } else if (temp2 != nullptr) { temp->next = temp2; } return dummyHead->next; } };147. 对链表进行插入排序
首先判断给定的链表是不是只有一个
- 创建哑节点dummy,为了方便在头部插入,令dummy->next=head。
- 维护last代表链表已经完成排序的最后一个节点,初始时last=head;
- 维护cur代表last节点的后一个节点,就是即将判断的节点,cur=head->next;
- 比较last节点与cur节点的值
- 如果last节点的值小于cur节点的值,就代表不需要进行别的操作。
- 如果last节点的值大于cur节点的的值,就需要从链表头部dummy开始比较下一个节点的值和cur节点的值的大戏小。prev的下一个节点是第一个比cur大的节点,prev初始为dummy,为什么这里是prev的下一个节点呢,是为了方便后续的cur节点的插入。因为链表难以知道前一个节点的指针。
class Solution { public: ListNode* insertionSortList(ListNode* head) { if(!head->next) return head; ListNode* last = head, *dummy = new ListNode(0); dummy->next = head; ListNode* cur = head->next; while(cur) { if(last->val <= cur->val) { last = last->next; } else { ListNode* first = dummy; while(first->next->val <= cur->val) { first = first->next; } last->next = cur->next; cur->next = first->next; first->next = cur; } cur = last->next; } last = dummy->next; delete(dummy); return last; } };

若有收获,就点个赞吧
0 人点赞
