- 671二叉树中第二小的节点:
- 863二叉树中所有距离为k的节点:
- 802找到最终的安装状态:
- 385. 迷你语法分析器(特殊)">385. 迷你语法分析器(特殊)
- 427. 建立四叉树(粗心!!!!)">427. 建立四叉树(粗心!!!!)
- 记忆化
- 695. 岛屿的最大面积(标准dfs巧妙记忆化)">695. 岛屿的最大面积(标准dfs巧妙记忆化)
- 552学生出勤记录 Ⅱ
- 797所有可能的路径
- 79.单词搜索
- 638. 大礼包(反复研究)">638. 大礼包(反复研究)
- 1218. 最长定差子序列">1218. 最长定差子序列
- 547. 省份数量(记忆化,二维化一维)">547. 省份数量(记忆化,二维化一维)
- 417. 太平洋大西洋水流问题(非常重要)">417. 太平洋大西洋水流问题(非常重要)
- 312. 戳气球(很难/值得看)">312. 戳气球(很难/值得看)
- 回溯法
- 257. 二叉树的所有路径(字符串操作)">257. 二叉树的所有路径(字符串操作)
- 46. 全排列">46. 全排列
- 47. 全排列 II(不重复)">47. 全排列 II(不重复)
- 77. 组合(可以看看)">77. 组合(可以看看)
- 40. 组合总和 II(组合升级版)">40. 组合总和 II(组合升级版)
- 51. N 皇后(必看,经典题)">51. N 皇后(必看,经典题)
- 842. 将数组拆分成斐波那契序列(字节面试)">842. 将数组拆分成斐波那契序列(字节面试)
- 37. 解数独(hard)">37. 解数独(hard)
- 494. 目标和(实现方式值得一看)">494. 目标和(实现方式值得一看)
- 473. 火柴拼正方形(剪枝模板题)">473. 火柴拼正方形(剪枝模板题)
- 标记法
- 130. 被围绕的区域(深搜广搜,标记法)">130. 被围绕的区域(深搜广搜,标记法)
- 691. 贴纸拼词(这里的剪树枝是超级重点)">691. 贴纸拼词(这里的剪树枝是超级重点)
671二叉树中第二小的节点:
863二叉树中所有距离为k的节点:
使用dfs来将对应的父节点存进哈希表中,然后在三个方向进行搜索。要点在于使用哈希表来存储父节点。
802找到最终的安装状态:
385. 迷你语法分析器(特殊)
- 这一题主要是一个特殊的数据结构,有两种情况,单个整数,或者列表,列表里面也能包含列表。
分为两种情况,存在括号的话就代表是列表,可进行递归,如果是数字的话,就可以直接返回。
dfs
class Solution {public:int index = 0;NestedInteger deserialize(string s) {if (s[index] == '[') {//存在括号代表是一个listindex++;NestedInteger ni;while (s[index] != ']') {ni.add(deserialize(s));if (s[index] == ',') {index++;}}index++;return ni;} else {//如果只包含一个对象,就不用使用addbool negative = false;//负数标记位if (s[index] == '-') {//如果是负数negative = true;index++;}int num = 0;while (index < s.size() && isdigit(s[index])) {//解析出元素num = num * 10 + s[index] - '0';index++;}if (negative) {num *= -1;}return NestedInteger(num);//这里就是一个单个元素的构造函数}}};
栈
class Solution {public:NestedInteger deserialize(string s) {if (s[0] != '[') {return NestedInteger(stoi(s));}stack<NestedInteger> st;int num = 0;bool negative = false;for (int i = 0; i < s.size(); i++) {char c = s[i];if (c == '-') {negative = true;} else if (isdigit(c)) {num = num * 10 + c - '0';} else if (c == '[') {st.emplace(NestedInteger());} else if (c == ',' || c == ']') {if (isdigit(s[i - 1])) {//如果c是反括号,或者逗号,表示num数字找全了。添加到栈顶的数据结构if (negative) {num *= -1;}st.top().add(NestedInteger(num));}num = 0;negative = false;if (c == ']' && st.size() > 1) {//如果c是反括号,就代表当前的列表已经结束。并且栈里面的列表不止一个,则把后一个列表弹入前面的列表。NestedInteger ni = st.top();st.pop();st.top().add(ni);}}}return st.top();}};
427. 建立四叉树(粗心!!!!)
class Solution {public:Node* construct(vector<vector<int>>& grid) {int n = grid.size();return dfs(grid, 0, n, 0, n);}Node* dfs(vector<vector<int>>& grid, int l, int r, int t, int b) {Node* root = new Node;if(helper(grid, l, r, t, b)) {root->isLeaf = true;root->val = grid[l][t];} else {root->topLeft = dfs(grid, l, l + (r-l)/2, t, t + (b-t)/2);root->topRight = dfs(grid, l, l + (r-l)/2, t + (b-t)/2, b);root->bottomLeft = dfs(grid, l + (r-l)/2, r, t, t + (b-t)/2);root->bottomRight = dfs(grid, l + (r-l)/2, r, t + (b-t)/2, b);}return root;}bool helper(vector<vector<int>>& grid, int l, int r, int t, int b) {int tmp = grid[l][t];for(int i = l; i < r; i++) {for(int j = t; j < b; j++) {if(grid[i][j] != tmp) {return false;}}}return true;}};
记忆化
695. 岛屿的最大面积(标准dfs巧妙记忆化)
这道题并不是路径问题,所以不使用回溯。这道题是求面积类问题,将多条路径相加即可。
class Solution {public:vector<int> der = {-1, 0, 1, 0, -1};int maxAreaOfIsland(vector<vector<int>>& grid) {int n = grid.size(), m = grid[0].size(), ret = 0;for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){if(grid[i][j] == 1){ret = max(dfs(grid, i, j, n, m), ret);}}}return ret;}int dfs(vector<vector<int>>& grid, int r, int l, int n, int m){if(grid[r][l] == 0) return 0;grid[r][l] = 0;int area = 1;for(int i = 0; i < 4; i++){int x = r + der[i], y = l + der[i+1];if(x>=0&&x<n&&y>=0&&y<m){area += dfs(grid, x, y, n, m);}}return area;}};
552学生出勤记录 Ⅱ
使用dfs来遍历所有的情况,要点在于在每一天都有三种选择,而ans代表着当前天数下的选择,换一句话来说,一个节点有三个树枝,ans代表这个节点之下所有树枝数量。这里有几个关键点
本来absent 以及 late应该放在出口初判断,在这段代码中,直接剪枝了,不让走这条路。
- 运用记忆化的方法,使用一个三维数组来标记走过的路径,下次再走这条路时直接返回值。
- 注意这种写题模式。这里其实可以用更加高效的方法动态规划,但是有利于dfs的练习因此写到这里。
这种带返回值的写法很关键,非常适合带记忆化的写法,如果我常用的无返回值的话,很难确定标记节点后续有多少种可能。这种是可以得出每一个节点后续满足条件的树枝数目的,而无返回值的只能一次一次累计。
class Solution { private: static constexpr int MOD = 1000000007; public: int checkRecord(int n) { vector<vector<vector<int>>> mem(n , vector<vector<int>> (2 , vector<int>(3))); return dfs(0, n, 0 , 0, mem); } int dfs(int day, int n , int absent , int late , vector<vector<vector<int>>> &mem){ if(day >= n){ return 1; } if(mem[day][absent][late] != 0){ return mem[day][absent][late]; } int ans = 0; ans = (ans + dfs(day+1, n, absent, 0, mem))%MOD; if(absent < 1){ ans = (ans + dfs(day + 1, n , 1, 0, mem))%MOD; } if(late < 2) { ans = (ans + dfs(day + 1, n, absent, late + 1, mem))%MOD; } mem[day][absent][late] = ans; return ans; } };797所有可能的路径
千万注意,深搜和广搜侧重点不一样。深搜是可以找到所有的路径,用递归的方式可以方便存储每一条路径。而广搜是可以找到最短的路径,用队列的方式。这里用到了回溯法,回来的时候弹出
class Solution { public: vector<vector<int>> ans; vector<int> stk; void dfs(vector<vector<int>>& graph, int x, int n) { if (x == n) { ans.push_back(stk); return; } for (auto& y : graph[x]) { stk.push_back(y); dfs(graph, y, n); stk.pop_back(); } } vector<vector<int>> allPathsSourceTarget(vector<vector<int>>& graph) { stk.push_back(0); dfs(graph, 0, graph.size() - 1); return ans; } };79.单词搜索
标准的操作
class Solution { public: bool flag=false; vector<int> map={-1,0,1,0,-1}; bool exist(vector<vector<char>>& board, string word) { vector<vector<bool>> flags(board.size(),vector<bool>(board[0].size(),false)); for(int i=0;i<board.size();i++){ for(int j=0;j<board[0].size();j++){ if(board[i][j]==word[0]) dfs(board,word,i,j,1,flags); } } return flag; } void dfs(vector<vector<char>> & board,string &word,int r,int c,int k,vector<vector<bool>> &flags){ if(flag) return; if(k==word.size()){ flag=true; return; } flags[r][c]=true; int x,y; for(int i=0;i<4;i++){ x=r+map[i],y=c+map[i+1]; if(x>=0&&y>=0&&x<board.size()&&y<board[0].size()&&board[x][y]==word[k]&&!flags[x][y]){ dfs(board,word,x,y,k+1,flags); } } flags[r][c]=false; } };638. 大礼包(反复研究)
dfs(无记忆化)
这一题先计算直接买商品的价格,然后使用递归来计算购买大礼包之后的价格。
在递归中先计算当前大礼包是否满足需求,然后再假设购买了大礼包一次来更新val值,贼出口出进行对最小价格的比较。最终回溯法回复状态。class Solution { public: int ret = 0, n, flag; int shoppingOffers(vector<int>& price, vector<vector<int>>& special, vector<int>& needs) { n = price.size(); for(int i = 0; i < n; i++){ ret += needs[i] * price[i]; } dfs(price, special, needs, ret); return ret; } void dfs(vector<int> & price, vector<vector<int>>& special, vector<int>& needs, int val){ if(ret > val){ ret = val; } for(int i = 0; i < special.size(); i++){//遍历礼包的数量来方便dfs遍历所有情况。 flag = 0; for(int j = 0; j < n; j++){//如果超出所需要的need量则不会买这个礼包 if(needs[j] < special[i][j]){ flag = 1; break; } } if(flag == 1) continue; for(int j = 0; j < n; j++){ needs[j] -= special[i][j];//注意更新剩下的容量 val -= price[j] * special[i][j]; } val += special[i][n];//更新价格 dfs(price, special, needs, val); val -= special[i][n];//回溯法回溯回来,不影响下一次循环 for(int j = 0; j < n; j++){ needs[j] += special[i][j]; val += price[j] * special[i][j]; } } } };记忆化+dfs+提前过滤
要点
提前排除掉没有优惠的大礼包
- 使用map来维护一个记忆化的表来保存路径,防止dfs进入重复的路程
- 每一次dfs,都把优惠过的大礼包进行一次遍历,如果超出需求就否定当前的路
- 每一层都更新新的需求值,并把当前路径的最小价格存储在hash表里面(这里使用回溯法感觉简便一点)
每一层dfs进行一次判断,这条路径是否已经走过,如果走过则直接返回hash表里面的值就行。
class Solution { public: map<vector<int>, int> memo;//存储记忆化 int shoppingOffers(vector<int>& price, vector<vector<int>>& special, vector<int>& needs) { int n = price.size(); // 过滤不需要计算的大礼包,只保留需要计算的大礼包 vector<vector<int>> filterSpecial; for (auto & sp : special) {//遍历大礼包的数量 int totalCount = 0, totalPrice = 0; for (int i = 0; i < n; ++i) { totalCount += sp[i]; totalPrice += sp[i] * price[i]; } if (totalCount > 0 && totalPrice > sp[n]) {//只计算有优惠的大礼包 filterSpecial.emplace_back(sp); } } return dfs(price, special, needs, filterSpecial, n); } // 记忆化搜索计算满足购物清单所需花费的最低价格 int dfs(vector<int> price,const vector<vector<int>> & special, vector<int> curNeeds, vector<vector<int>> & filterSpecial, int n) { if (!memo.count(curNeeds)) {//如果需求一样,就没有必要继续往下走了,因为之前已经走过了。 int minPrice = 0; for (int i = 0; i < n; ++i) { minPrice += curNeeds[i] * price[i]; // 不购买任何大礼包,原价购买购物清单中的所有物品 } for (auto & curSpecial : filterSpecial) { int specialPrice = curSpecial[n];//当前大礼包的价格 vector<int> nxtNeeds;//更新之后的需求 for (int i = 0; i < n; ++i) { if (curSpecial[i] > curNeeds[i]) { // 不能购买超出购物清单指定数量的物品 break; } nxtNeeds.emplace_back(curNeeds[i] - curSpecial[i]);//更新需求 } if (nxtNeeds.size() == n) { // 大礼包可以购买 minPrice = min(minPrice, dfs(price, special, nxtNeeds, filterSpecial, n) + specialPrice); } } memo[curNeeds] = minPrice;//memo存储的就是当前需求的最低价格 } return memo[curNeeds]; } };1218. 最长定差子序列
使用dfs时间不复杂度不符合要求。
class Solution { public: int ret = 0; int longestSubsequence(vector<int>& arr, int difference) { int n = arr.size(); vector<bool> flags(n); for(int i = 0; i < n; i++){ if(!flags[i]) dfs(arr, flags, difference, i, 1); } return ret; } void dfs(vector<int> &arr,vector<bool> &flags, int difference, int idx, int val){ ret = max(ret, val); flags[idx] = true; for(int i = idx+1; i < arr.size(); i++){ if((arr[i] - arr[idx]) == difference){ dfs(arr, flags, difference, i, val+1); } } } };547. 省份数量(记忆化,二维化一维)
这一题与最大岛屿问题不一样,计算的逻辑不同。一定需要记忆化。
class Solution { public: vector<int> dir = {-1, 0, 1, 0, -1}; int findCircleNum(vector<vector<int>>& isConnected) { int n = isConnected.size(), ret = 0; vector<bool> flags(n); for(int i = 0; i < n; i++){ if(!flags[i]){ ret++; dfs(isConnected, flags, i); } } return ret; } void dfs(vector<vector<int>>& isConnected,vector<bool>&flags, int c){ if(flags[c] == true) return; flags[c] = true; for(int i = 0; i < isConnected.size(); i++){ if(!flags[i]&&isConnected[c][i]==1){ dfs(isConnected, flags, i); } } return; } };417. 太平洋大西洋水流问题(非常重要)
这一题的意思就是左上为太平洋,右下为大西洋,找出能能够同时到达这两个地方的位置。只能往低于等于自己的地方走
换个角度来想问题,切分为两个问题,一个从太平洋触发,一个从大西洋触发。两个数组,一个代表那些位置能到太平洋,一个位置代表哪些位置能够到大西洋。这两个数组的并集就是即能到太平洋又能到大西洋的地方。
class Solution { public: vector<vector<int>> pacificAtlantic(vector<vector<int>>& matrix) { vector<vector<int>> res; if(matrix.empty()) return res; m = matrix.size(); n = matrix[0].size(); vector<vector<bool>> Pacificmark(m,vector<bool>(n,false)); vector<vector<bool>> Atlanticmark(m,vector<bool>(n,false)); for(int i=0;i<m;i++){ dfs(matrix,Pacificmark,i,0); dfs(matrix,Atlanticmark,i,n-1); } for(int i=0;i<n;i++){ dfs(matrix,Pacificmark,0,i); dfs(matrix,Atlanticmark,m-1,i); } for(int i=0;i<m;i++){ for(int j=0;j<n;j++){ if(Atlanticmark[i][j] && Pacificmark[i][j]){ res.push_back({i,j}); } } } return res; } private: int m,n; int d[4][2] = {{1,0},{-1,0},{0,1},{0,-1}}; void dfs(vector<vector<int>>& matrix,vector<vector<bool>>& marked,int startx,int starty){ marked[startx][starty] = true; for(int i=0;i<4;i++){ int nextx = startx + d[i][0]; int nexty = starty + d[i][1]; if(inArea(nextx,nexty) && !marked[nextx][nexty]){ if(matrix[nextx][nexty] >= matrix[startx][starty]){ dfs(matrix,marked,nextx,nexty); } } } } bool inArea(const int& x,const int& y){ return x>=0 && x<m && y>=0 && y<n; } };312. 戳气球(很难/值得看)
自顶向下的记忆化方法
意思就是任何子问题的求解都只依赖于更小的子问题的求解。因为我们可以将子问题按规模排序,按从小到大排序。当求解每个子问题时,它所依赖的那些更小的子问题都已经求解完毕,结果已经保存每个子问题只需要求解一次,当我们求解它时,它的所有前提子问题已经求解完成。
就比如下面的转移方程,因为rec[i][j]依赖于rec[i][k]以及rec[j][k],而k在i和j之间,这就代表当前的子集依赖于更小的j以及更大的i。所以循环遍历的方向应该是i从大到小,而j从小到大。 ```cpp class Solution { public: vectorval;
public: int solve(int left, int right) { if (left >= right - 1) { return 0; } if (rec[left][right] != -1) { return rec[left][right]; } for (int i = left + 1; i < right; i++) { int sum = val[left] val[i] val[right]; sum += solve(left, i) + solve(i, right); rec[left][right] = max(rec[left][right], sum);//记忆化 } return rec[left][right]; }
int maxCoins(vector<int>& nums) {
int n = nums.size();
val.resize(n + 2);
for (int i = 1; i <= n; i++) {
val[i] = nums[i - 1];
}
val[0] = val[n + 1] = 1;
rec.resize(n + 2, vector<int>(n + 2, -1));//初始化为-1,-1就代表尚未遍历到。一种剪枝的方法。
return solve(0, n + 1);
}
};
<a name="jjNMP"></a>
#### 自底向上的动态规划方法
```cpp
class Solution {
public:
int maxCoins(vector<int>& nums) {
int n = nums.size();
vector<vector<int>> rec(n + 2, vector<int>(n + 2));
vector<int> val(n + 2);
val[0] = val[n + 1] = 1;
for (int i = 1; i <= n; i++) {
val[i] = nums[i - 1];
}
for (int i = n - 1; i >= 0; i--) {
for (int j = i + 2; j <= n + 1; j++) {
for (int k = i + 1; k < j; k++) {
int sum = val[i] * val[k] * val[j];
sum += rec[i][k] + rec[k][j];
rec[i][j] = max(rec[i][j], sum);
}
}
}
return rec[0][n + 1];
}
};
回溯法
257. 二叉树的所有路径(字符串操作)
没什么好说的
- 字符串无法相减,只能使用pop_back()与erase;
-
回溯
class Solution { public: vector<string> binaryTreePaths(TreeNode* root) { vector<string> ret; string str; dfs(root, ret, str); return ret; } void dfs(TreeNode* root, vector<string>& ret, string &str){ if(!root->left&&!root->right){ string fstr=to_string(root->val); str += fstr; ret.emplace_back(str); str.erase(str.size()-fstr.size(),fstr.size()); return; } string str2 = to_string(root->val); str += str2; str += "->"; if(root->left) dfs(root->left, ret, str); if(root->right) dfs(root->right, ret, str); str.erase(str.size()-str2.size()-2, str2.size()+2); } };不回溯
class Solution { public: void construct_paths(TreeNode* root, string path, vector<string>& paths) { if (root != nullptr) { path += to_string(root->val); if (root->left == nullptr && root->right == nullptr) { // 当前节点是叶子节点 paths.push_back(path); // 把路径加入到答案中 } else { path += "->"; // 当前节点不是叶子节点,继续递归遍历 construct_paths(root->left, path, paths); construct_paths(root->right, path, paths); } } } vector<string> binaryTreePaths(TreeNode* root) { vector<string> paths; construct_paths(root, "", paths); return paths; } };46. 全排列
笨比写法
class Solution { public: vector<vector<int>> permute(vector<int>& nums) { vector<vector<int>> ret; vector<int> vec; vector<bool> flags(nums.size()); dfs(nums, ret, vec, flags); return ret; } void dfs(vector<int>& nums, vector<vector<int>> &ret, vector<int>& vec, vector<bool>& flags){ if(vec.size() == nums.size()){ ret.push_back(vec); return; } for(int i = 0; i < nums.size(); i++){ if(!flags[i]){ flags[i] = true; vec.push_back(nums[i]); dfs(nums, ret, vec, flags); flags[i] = false; vec.pop_back(); } } } };高级写法(swap)
对于每一个当前位置i,我们可以将其于之后的任意位置交换,然后继续处理位置i+1,直到处理到最后一位。为了防止我们每次遍历时都要新建一个子数组存储位置i之前已经交换好的数字利用回溯法,只对原数组进行修改,递归完之后在修改回来。
基本也是先确定第一层,然后后面的进行调换。换过之后就不能动前面的数了,防止重复情况。
class Solution { public: vector<vector<int>> permute(vector<int>& nums) { vector<vector<int>> ans; dfs(nums, 0, ans); return ans; } void dfs(vector<int>& nums, int level, vector<vector<int>> &ans){ if(level == nums.size()){ ans.push_back(nums); return; } for(int i = level; i < nums.size(); i++){ swap(nums[i], nums[level]); dfs(nums, level + 1, ans); swap(nums[level], nums[i]); } } };47. 全排列 II(不重复)
全排列1的升级版,顺序不同,结果相同也不行。
- 剪枝掉所有的重复的情况
- 只要前面有元素和当前的元素就相等,就一定是重复了的。
- 因为都是前面的与后面的发生交换
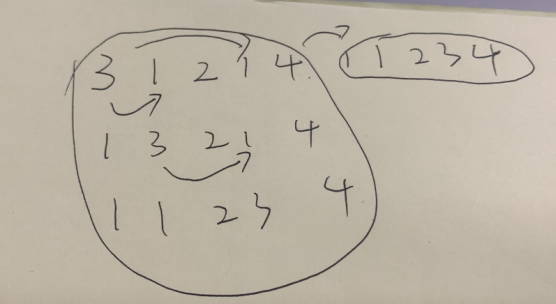
class Solution {
private:
vector<vector<int>> ans;
public:
vector<vector<int>> permuteUnique(vector<int>& nums) {
dfs(nums, 0);
return ans;
}
void dfs(vector<int>&nums, int count){
if(count == nums.size()){
ans.push_back(nums);
}
for(int i = count; i < nums.size(); i++){
bool flag = true;
for(int j = count; j < i; j++){
if(nums[j]==nums[i]){
flag = false;
}
}
if(flag){
swap(nums[i], nums[count]);
dfs(nums, count+1);
swap(nums[i], nums[count]);
}
}
}
};
77. 组合(可以看看)
这题与上一题不同的是,这一题顺序不同元素相同,不能算是同一种情况。因此可以只从大到小来考虑。
- 对每一层都是对元素选择要或者不要。数组永远是增序的。
- 为了避免出现 1,2与2,1这种重复的情况,后面可选用的数字永远在比当前数字大。
如果不管顺序只管元素组合的话,可以这样写,因为没有漏掉的情况,比如说第一个选3的话第二个就不用选1,2因为前面的1和2的情况都已经组合过1,3和1,2了,会产生重复的。
class Solution { public: vector<vector<int>> combine(int n, int k) { vector<vector<int>> ans; vector<int> comb; dfs(ans, comb, 1, n, k); return ans; } void dfs(vector<vector<int>>& ans, vector<int>& comb, int pos, int n, int k){ if(comb.size() == k){ ans.push_back(comb); return; } for(int i = pos; i <= n; i++){ comb.push_back(i); dfs(ans, comb, i+1, n, k); comb.pop_back(); } } };40. 组合总和 II(组合升级版)
相比组合,需要剪枝,因为这个 给的数组可能出现重复
- 相比组合,跳出递归的条件为和为target
- 因为candidates[i]与candidates[i-1]一样时,选i和i-1完全是一样的结果
- 对于组合问题,只有选与不选,因此直接push_back()和pop_back()即可,不需要swap
- 剪枝的条件只有candidates[i] == candidates[i-1],这是因为一开始就进行了排序操作,因此相等的元素都放在一起了。
而且只需要出现剩余的target比candidates[i]小就可以直接跳出循环,这也是因为排序的功劳。
class Solution { public: vector<vector<int>> res; vector<int> temp; void backtrack(vector<int>& candidates, int target, int index) { if(target == 0) { res.push_back(temp); return; } for(int i = index; i < candidates.size() && target-candidates[i] >= 0; i++) { if(i > index && candidates[i] == candidates[i-1])//剪枝,避免完全一样的情况!!! //因为candidates[i]与candidates[i-1]一样时,选i和i-1完全是一样的结果!!! //对于组合问题,只有选与不选,因此与排列问题不同,至于要满足与前面一位不相同即可。 continue; temp.push_back(candidates[i]); backtrack(candidates, target-candidates[i], i+1); temp.pop_back(); } } vector<vector<int>> combinationSum2(vector<int>& candidates, int target) { sort(candidates.begin(), candidates.end());//将相等的元素放在一起 backtrack(candidates, target, 0); return res; } };51. N 皇后(必看,经典题)
要点在以下
有一个隐藏的条件,必须在n*n的棋盘上放n个皇后,因此每行或者每列必有一个皇后。也就是说如果在i行没找到可以放Q的位置,从i+1到第N行都不用查看了。结合递归的思路之后再第i行找到了Q的位置,才会继续在i+1行寻找。挡在第N行找到时,就符合题意了。
- 注意左斜边和右斜边的情况,最好的办法是维护三个vector
,分别是n,左斜,右斜。 - 通过修改状态矩阵来进行回溯。
- 注意公式,当皇后位于x,y位置时,左斜边位

class Solution { public: vector<vector<string>> solveNQueens(int n) { vector<vector<string>> ans; if (n == 0) { return ans; } vector<string> board(n, string(n, '.')); vector<bool> column(n, false), ldiag(2*n-1, false), rdiag(2*n-1, false);//分别是左斜和右斜! backtracking(ans, board, column, ldiag, rdiag, 0, n); return ans; } // 辅函数 void backtracking(vector<vector<string>> &ans, vector<string> &board, vector<bool> &column, vector<bool> &ldiag, vector<bool> &rdiag, int row, int n) { if (row == n) { ans.push_back(board); return; } for (int i = 0; i < n; ++i) { if (column[i] || ldiag[n-row+i-1] || rdiag[row+i]) { continue; } // 修改当前节点状态 board[row][i] = 'Q'; column[i] = ldiag[n-row+i-1] = rdiag[row+i] = true; // 递归子节点 backtracking(ans, board, column, ldiag, rdiag, row+1, n); // 回改当前节点状态 board[row][i] = '.'; column[i] = ldiag[n-row+i-1] = rdiag[row+i] = false; } } };842. 将数组拆分成斐波那契序列(字节面试)
剪枝情况
首数字为0的情况 break
- 超范围的情况 break
- 当前数大于前面两数之和 break
- 当前数小于前面两数之和 continue
- 等于的话进入下一层backtrack
注意剪枝的位置可以放到循环里面更有效率
class Solution { public: vector<int> splitIntoFibonacci(string num) { vector<int> list; backtrack(list, num, num.length(), 0, 0, 0); return list; } bool backtrack(vector<int>& list, string num, int length, int index, long long sum, int prev) { if (index == length) { return list.size() >= 3; } long long curr = 0; for (int i = index; i < length; i++) { if (i > index && num[index] == '0') { break; }//这就代表 curr = curr * 10 + num[i] - '0'; //curr = stoll(num.substr(index, i+1-index)); if (curr > INT_MAX) { break; } if (list.size() >= 2) { if (curr < sum) { continue; } else if (curr > sum) { break; } } list.push_back(curr); if (backtrack(list, num, length, i + 1, prev + curr, curr)) { return true; } list.pop_back(); } return false; } };37. 解数独(hard)
使用line,column,block分别代表指定数字在行、列、九宫格中是否存在
- 最后一维代表指定数字,因为范围是0-8,因此后面计算digit需要-1;
使用回溯法来进行暴力搜索
class Solution { private: bool line[9][9];//行,第二维代表具体数字1-9 bool column[9][9];//列,~ bool block[3][3][9];//9宫格,~ bool valid = false; vector<pair<int,int>> spaces;//存储空白格下标 public: void dfs(vector<vector<char>>& board, int idx) { if(idx == spaces.size()) {//出口,当idx为空白位置的数量代表数独已经解开,即为每个空白位置都已经分配的数字且不冲突 valid = true;//这里是为了防止多余的计算 return; } auto [i, j] = spaces[idx];//取出空白位置下标 for(int k = 0; k < 9&&!valid; k++) {//每个空白位置都可能选择从1-9,因此i范围从0-8,后面需要+1与1-9想匹配。 if(!line[i][k]&&!column[j][k]&&!block[i/3][j/3][k]) {//满足条件行列格都不存在相同元素 line[i][k] = column[j][k] = block[i/3][j/3][k] = true; board[i][j] = k + '0' + 1;//赋值 dfs(board, idx+1);//进入下一次递归 line[i][k] = column[j][k] = block[i/3][j/3][k] = false;//上一次的选择存在问题,因此回溯,为了避免影响到别的情况恢复为原样。进入for的下一层 } } } void solveSudoku(vector<vector<char>>& board) { memset(line, false, sizeof(line));//初始化上述数组为false memset(column, false, sizeof(column)); memset(block, false, sizeof(block)); for(int i = 0; i < 9; i++) { for(int j = 0; j < 9; j++) { if(board[i][j] == '.') { spaces.emplace_back(i, j);//记载下来空白位置 } else { int digit = board[i][j] - '0' - 1;//这里是为了配合初始数组的范围 line[i][digit] = column[j][digit] = block[i/3][j/3][digit] = true;//这里是将行列格对应的数字标记为已存在 } } } dfs(board, 0); return ; } };494. 目标和(实现方式值得一看)
题目可以转换为每个位置可以选择0或1,看有多少种情况满足条件的所有可能问题。但是复杂度太高,为指数级。
class Solution { public: int res = 0; int findTargetSumWays(vector<int>& nums, int target) { dfs(nums, target, 0); return res; } void dfs(vector<int>& nums, int target, int a){ if(a == nums.size()){ if(target == 0){ res++; } return; } dfs(nums, target-nums[a], a+1); dfs(nums, target+nums[a], a+1); } };473. 火柴拼正方形(剪枝模板题)
class Solution { public: bool dfs(int index, vector<int> &matchsticks, vector<int> &edges, int len) { if (index == matchsticks.size()) { return true; } for (int i = 0; i < edges.size(); i++) {//看看当前的火柴能不能占一条边。 edges[i] += matchsticks[index]; if (edges[i] <= len && dfs(index + 1, matchsticks, edges, len)) { return true; } edges[i] -= matchsticks[index]; } return false; } bool makesquare(vector<int> &matchsticks) { int totalLen = accumulate(matchsticks.begin(), matchsticks.end(), 0); if (totalLen % 4 != 0) { return false; } sort(matchsticks.begin(), matchsticks.end(), greater<int>()); // 减少搜索量 vector<int> edges(4); return dfs(0, matchsticks, edges, totalLen / 4); } };标记法
130. 被围绕的区域(深搜广搜,标记法)
这题的一个关键点就是从四周先扩散,这个想法非常重要!!!!
-
自己的笨比写法
class Solution { private: vector<int> dir = {-1, 0, 1, 0, -1}; public: void solve(vector<vector<char>>& board) { int n = board.size(), m = board[0].size(); vector<vector<bool>> flags(n, vector<bool>(m)); for(int i = 0; i < n; i++){ for(int j = 0; j < m; j++){ vector<pair<int, int>> vec; bool flag = false; if(board[i][j]=='O'&&!flags[i][j]){ dfs(board, i, j, vec, flags, flag, n, m); if(!flag) { for(auto it : vec){ board[it.first][it.second] = 'X'; } } } } } } void dfs(vector<vector<char>>& board, int r, int c, vector<pair<int, int>>& vec, vector<vector<bool>>& flags, bool & flag, int n, int m){ if(r==n-1||c==m-1||r==0||c==0){ flag = true; } vec.emplace_back(r, c); flags[r][c] = true; int x, y; for(int i = 0; i < 4; i++){ x = r + dir[i], y = c + dir[i+1]; if(x>=0&&x<n&&y>=0&&y<m&&!flags[x][y]&&board[x][y]=='O'){ dfs(board, x, y, vec, flags, flag, n, m); } } return ; } };深搜
class Solution { public: int n, m; void dfs(vector<vector<char>>& board, int x, int y) { if (x < 0 || x >= n || y < 0 || y >= m || board[x][y] != 'O') { return; } board[x][y] = 'A'; dfs(board, x + 1, y); dfs(board, x - 1, y); dfs(board, x, y + 1); dfs(board, x, y - 1); } void solve(vector<vector<char>>& board) { n = board.size(); if (n == 0) { return; } m = board[0].size(); for (int i = 0; i < n; i++) { dfs(board, i, 0); dfs(board, i, m - 1); } for (int i = 1; i < m - 1; i++) { dfs(board, 0, i); dfs(board, n - 1, i); } for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { if (board[i][j] == 'A') { board[i][j] = 'O'; } else if (board[i][j] == 'O') { board[i][j] = 'X'; } } } } };广搜
class Solution { public: const int dx[4] = {1, -1, 0, 0}; const int dy[4] = {0, 0, 1, -1}; void solve(vector<vector<char>>& board) { int n = board.size(); if (n == 0) { return; } int m = board[0].size(); queue<pair<int, int>> que; for (int i = 0; i < n; i++) { if (board[i][0] == 'O') { que.emplace(i, 0); board[i][0] = 'A'; } if (board[i][m - 1] == 'O') { que.emplace(i, m - 1); board[i][m - 1] = 'A'; } } for (int i = 1; i < m - 1; i++) { if (board[0][i] == 'O') { que.emplace(0, i); board[0][i] = 'A'; } if (board[n - 1][i] == 'O') { que.emplace(n - 1, i); board[n - 1][i] = 'A'; } } while (!que.empty()) { int x = que.front().first, y = que.front().second; que.pop(); for (int i = 0; i < 4; i++) { int mx = x + dx[i], my = y + dy[i]; if (mx < 0 || my < 0 || mx >= n || my >= m || board[mx][my] != 'O') { continue; } que.emplace(mx, my); board[mx][my] = 'A'; } } for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { if (board[i][j] == 'A') { board[i][j] = 'O'; } else if (board[i][j] == 'O') { board[i][j] = 'X'; } } } } };691. 贴纸拼词(这里的剪树枝是超级重点)
参考链接
https://leetcode.cn/problems/stickers-to-spell-word/class Solution { public: int answer=16;//存放答案,因为target.size()小于等于15,所以初始设置为16 int num=0;//记录已经使用的贴纸数 vector<pair<string,int>> havetried;//记忆化数组,记录字符串状态和贴纸次数,避免重复。 void solve(vector<string> &stickers,string &left) { if(left=="")//成功贴出,且num<answer(在上一层控制) answer=num; if(num>=answer-1)//如果num>=answer-1,最终答案不会比answer小,终止搜索 return ; for(int i=0;i<stickers.size();++i) { if(stickers[i].find(left[0])!=stickers[i].npos)//注意这个表达,使用stl的find函数对效率也会有提升。注意这个表达,npos表示不存在这个位置。 {//因为left中的0一定会选择,先后顺序而已,因此直接规定先选,避免重复情况,对效率提升非常大。 string temp=stickers[i],copy=left;//拷贝stickers[i]和left int pos=0; for(int j=0;j<left.size();++j)//删除left中能用temp贴的所有字母 if((pos=temp.find(left[j]))!=temp.npos) { temp.erase(pos,1); left.erase(j,1); --j; } ++num;//贴纸数+1 if(find(havetried.begin(),havetried.end(),(pair<string,int>){left,num})==havetried.end())//如果没有查找过这个状态,记录并查找,对效率提升巨大。 { havetried.push_back({left,num}); solve(stickers,left); } left=copy;//回溯至原状态 --num; } } } int minStickers(vector<string>& stickers, string target) { solve(stickers,target); return answer==16?-1:answer;//answer==16说明没找到 } };

若有收获,就点个赞吧
0 人点赞
