- 32-1 从上到下打印二叉树
- 32-2 从上到下打印二叉树 2
- 32-3 从上到下打印二叉树
- 26. 树的子结构
- 27.二叉树的镜像(有东西)
- 28.对称的二叉树
- 剑指 Offer 12. 矩阵中的路径(可以当作回溯模板)">剑指 Offer 12. 矩阵中的路径(可以当作回溯模板)
- 剑指 Offer 13. 机器人的运动范围">剑指 Offer 13. 机器人的运动范围
- 剑指 Offer 34. 二叉树中和为某一值的路径">剑指 Offer 34. 二叉树中和为某一值的路径
- 剑指 Offer 36. 二叉搜索树与双向链表(重点)">剑指 Offer 36. 二叉搜索树与双向链表(重点)
- 剑指 Offer 54. 二叉搜索树的第k大节点">剑指 Offer 54. 二叉搜索树的第k大节点
- 剑指 Offer 55 - I. 二叉树的深度(平平无奇)">剑指 Offer 55 - I. 二叉树的深度(平平无奇)
- 剑指 Offer 55 - II. 平衡二叉树">剑指 Offer 55 - II. 平衡二叉树
- 剑指 Offer 07. 重建二叉树(重点)">剑指 Offer 07. 重建二叉树(重点)
- 剑指 Offer 68 - I. 二叉搜索树的最近公共祖先">剑指 Offer 68 - I. 二叉搜索树的最近公共祖先
- 剑指 Offer 68 - II. 二叉树的最近公共祖先(重点)">剑指 Offer 68 - II. 二叉树的最近公共祖先(重点)
- 剑指 Offer 38. 字符串的排列(记忆化+dfs)">剑指 Offer 38. 字符串的排列(记忆化+dfs)
- 这里可以分解一下(常规写法)
- 使用swap的写法(不用开辟空间来存储字符串)
- 297. 二叉树的序列化与反序列化(仔细研究)">297. 二叉树的序列化与反序列化(仔细研究)
- 剑指 Offer 49. 丑数(很妙)">剑指 Offer 49. 丑数(很妙)
- 剑指 Offer 19. 正则表达式匹配(每看,头痛)">剑指 Offer 19. 正则表达式匹配(每看,头痛)
- 回溯法
- 剑指 Offer II 079. 所有子集(集合)">剑指 Offer II 079. 所有子集(集合)
- 剑指 Offer II 080. 含有 k 个元素的组合(k集合)">剑指 Offer II 080. 含有 k 个元素的组合(k集合)
- 剑指 Offer II 081. 允许重复选择元素的组合(带重复的集合)">剑指 Offer II 081. 允许重复选择元素的组合(带重复的集合)
- 剑指 Offer II 082. 含有重复元素集合的组合(原数组重复的集合)">剑指 Offer II 082. 含有重复元素集合的组合(原数组重复的集合)
- 剑指 Offer II 083. 没有重复元素集合的全排列(全排列)">剑指 Offer II 083. 没有重复元素集合的全排列(全排列)
- 剑指 Offer II 084. 含有重复元素集合的全排列">剑指 Offer II 084. 含有重复元素集合的全排列
- 剑指 Offer II 085. 生成匹配的括号">剑指 Offer II 085. 生成匹配的括号
- 剑指 Offer II 086. 分割回文子字符串(可以看)">剑指 Offer II 086. 分割回文子字符串(可以看)
32-1 从上到下打印二叉树
值得说明的是,这里出现小错误,只有stack才有top操作。记得注意指针为空的情况,尽量一遍过。
class Solution {public:vector<int> levelOrder(TreeNode* root) {vector<int> ret;queue<TreeNode*> list;list.push(root);while(!list.empty()){TreeNode* node = list.front();//注意list没有top函数,只有stack才有top操作if(node){ret.push_back(node->val);list.push(node->left);list.push(node->right);}list.pop();}return ret;}};
32-2 从上到下打印二叉树 2
本题是上一题的扩展。
这一题的扩展要求就是将不同的层分开来。返回一个二维数组。我想的是笨蛋方法,加一个对于不同的层加一个标记。但是显然有更好的一种写法,int size = queue.size(),一次将队列里面的所有元素遍历完,显然这种写法更加高级。
本比写法
class Solution {public:vector<vector<int>> levelOrder(TreeNode* root) {vector<vector<int>> ret;vector<int> vec;int i = 0, pre = 0;queue<pair<TreeNode*, int>> list;list.push(pair(root, 0));while(!list.empty()){auto node = list.front();//注意list没有top函数,只有stack才有top操作if(node.first){vec.push_back(node.first->val);list.push(pair(node.first->left, node.second + 1));list.push(pair(node.first->right, node.second + 1));pre = node.second;list.pop();} else {list.pop();}node = list.front();if(node.second != pre&&vec.size()){ret.push_back(vec);vec.clear();}}return ret;}};
不考虑空指针的写法
class Solution {public:vector<vector<int>> levelOrder(TreeNode* root) {vector<vector<int>> ret;vector<int> vec;int i = 0, pre = 0;queue<pair<TreeNode*, int>> list;if(root) list.push(pair(root, 0));while(!list.empty()){auto node = list.front();//注意list没有top函数,只有stack才有top操作vec.push_back(node.first->val);if(node.first->left) list.push(pair(node.first->left, node.second + 1));if(node.first->right) list.push(pair(node.first->right, node.second + 1));pre = node.second;list.pop();node = list.front();if(node.second != pre){ret.push_back(vec);vec.clear();}}return ret;}};
高级写法
每一次都把当前一层的全部遍历。
class Solution {public:vector<vector<int>> levelOrder(TreeNode* root) {vector<vector<int>> ans;if(root == nullptr) return ans;queue<TreeNode*> myQue;myQue.push(root);while(!myQue.empty()){vector<int> tmp;int size = myQue.size();for(;size--;myQue.pop()){auto node = myQue.front();if(node->left) myQue.push(node->left);if(node->right) myQue.push(node->right);tmp.push_back(node->val);}ans.push_back(tmp);//每一次都把当前一层的全部}return ans;}};
32-3 从上到下打印二叉树
本题又是上一题的扩展,要求是按照z自形状从上到下打印二叉树。
这里需要引入一个reverse函数来反转vector,可以向笨比写法一样维护一个pre来表示层数。也可以直接计算ret.size(),看里面有多少子数组来判奇偶性。
class Solution {public:vector<vector<int>> levelOrder(TreeNode* root) {vector<vector<int>> ret;vector<int> vec;int pre = 0;queue<pair<TreeNode*, int>> list;list.push(pair(root, 0));while(!list.empty()){auto node = list.front();//注意list没有top函数,只有stack才有top操作if(node.first){vec.push_back(node.first->val);list.push(pair(node.first->left, node.second + 1));list.push(pair(node.first->right, node.second + 1));list.pop();pre = node.second;} else {list.pop();}node = list.front();if(node.second != pre&&vec.size()){//if(ret.size()%2 == 1){//reverse(vec.begin(), vec.end());//} 另外一种写法if(pre%2 ==1){reverse(vec.begin(), vec.end());}ret.push_back(vec);vec.clear();}}return ret;}};
26. 树的子结构
看b树是不是a的子树,主要是看val以及结构是不是相等的。把问题分解,不要想着一个函数解决。专门写一个dfs来判断两个节点的树相同不。然后主要的函数用来一个一个的查找所有可能的节点。
主函数逻辑:如果A与B之间有一个为空指针,就直接返回false,然后判断dfs(A, B),然后递归主函数,再次输入左节点与右节点。
dfs函数逻辑:B为空时,代表已经匹配完成,A为空或者
class Solution {public:bool isSubStructure(TreeNode* A, TreeNode* B) {return (A != NULL&& B != NULL)&&(dfs(A, B)||isSubStructure(A->left, B)||isSubStructure(A->right, B));}bool dfs(TreeNode* A, TreeNode* B){if(B == NULL){return true;}if(A == NULL||A->val != B->val){return false;}return dfs(A->left, B->left)&&dfs(A->right, B->right);}};
27.二叉树的镜像(有东西)
复制一个链表,并且镜像处理。镜像的左右节点与实际上的左右节点是颠倒的。
class Solution {
public:
TreeNode* mirrorTree(TreeNode* root) {
if(root==NULL){
return NULL;
}
TreeNode* newnode = new TreeNode(root->val);
newnode->left = mirrorTree(root->right);
newnode->right = mirrorTree(root->left);
return newnode;
}
};
28.对称的二叉树
就是判断一个二叉树是不是对称的,我在上一题的基础上拓展,加一个判断是不是同一个二叉树的函数,消耗空间过大,是笨比写法。
判断是不是对称的,只需要在判断节点时,将左右节点调换就可以了
class Solution {
public:
bool isSymmetric(TreeNode* root) {
return root?isSymmetric(root->left,root->right) : true;
}
bool isSymmetric(TreeNode *left, TreeNode *right){
if(!left && !right)
return true;
if(!left||!right||left->val != right->val)
return false;
return isSymmetric(left->left, right->right)&&isSymmetric(left->right, right->left);//这里的特殊设计
}
};
剑指 Offer 12. 矩阵中的路径(可以当作回溯模板)
算是比较标准的回溯记忆剪枝算法。
有如下关键点:
- 记忆化,防止走回头路
- 先确定第一个格子
- 注意可以走的四个方向
- 注意越界
- 注意回溯的恢复操作。
第二次写
忘记了flag可以在进行一次剪枝,如果已经得出结果了就可以直接返回,而不用继续递归下去,判断中加一项,!flag。class Solution { public: bool flag=false; vector<int> map={-1,0,1,0,-1};//走格子必须要的操作。就代表着四个操作,分别是上下左右。 bool exist(vector<vector<char>>& board, string word) { vector<vector<bool>> flags(board.size(),vector<bool>(board[0].size(),false));//记忆化剪枝。 for(int i=0;i<board.size();i++){ for(int j=0;j<board[0].size();j++){ if(board[i][j]==word[0]) dfs(board,word,i,j,1,flags); } } return flag; } void dfs(vector<vector<char>> & board,string &word,int r,int c,int k,vector<vector<bool>> &flags){ if(flag) return; if(k==word.size()){ flag=true; return; } flags[r][c]=true; int x,y; for(int i=0;i<4;i++){ x=r+map[i],y=c+map[i+1]; if(x>=0&&y>=0&&x<board.size()&&y<board[0].size()&&board[x][y]==word[k]&&!flags[x][y]){//这里是防止走回头路 dfs(board,word,x,y,k+1,flags); } } flags[r][c]=false;//这里的剪枝是精髓。 } };剑指 Offer 13. 机器人的运动范围
这里的重点在于每个格子只走一遍。不是路径问题,因此不需要回溯状态。class Solution { public: vector<int> map{-1, 0, 1, 0, -1}; int res = 0; int movingCount(int m, int n, int k) { vector<vector<bool>> flags(m, vector<bool>(n, false)); dfs(0, 0, k, m, n, flags); return res; } void dfs(int r , int c , int k, int m, int n, vector<vector<bool>> &flags){ if(r<0||c<0||r>=m||c>=n||flags[r][c]){ return; } if((r%10+r/10+c%10+c/10) > k){ return; } res++; flags[r][c] = true; for(int i = 0; i < 4; i++){ dfs(r + map[i], c + map[i+1], k , m, n, flags); } //正常的回溯,这里应该有一个将标记恢复的操作,因为别的路径可以走这个格子,但是再这一题中是不能这样的。 return; } };剑指 Offer 34. 二叉树中和为某一值的路径
值得注意的是出口的问题。深度优先搜索:
```cpp class Solution { public: vector
} void dfs(TreeNode* root, int target, int sum, vectorvector<int> vec; vector<vector<int>> ret; dfs(root, target, 0, vec, ret); return ret;& vec,vector
}if(root==nullptr){ return; } if(root->left==nullptr&&root->right==nullptr&&sum + root->val == target){ vec.push_back(root->val); ret.push_back(vec); vec.pop_back(); return; } vec.push_back(root->val); dfs(root->left, target, sum + root->val, vec, ret); dfs(root->right, target, sum + root->val, vec, ret); vec.pop_back();
};
<a name="uqkxe"></a>
#### 广度优先搜索:
```cpp
class Solution {
public:
vector<vector<int>> ret;
unordered_map<TreeNode*, TreeNode*> parent;
void getPath(TreeNode* node) {
vector<int> tmp;
while (node != nullptr) {
tmp.emplace_back(node->val);
node = parent[node];
}
reverse(tmp.begin(), tmp.end());
ret.emplace_back(tmp);
}
vector<vector<int>> pathSum(TreeNode* root, int target) {
if (root == nullptr) {
return ret;
}
queue<TreeNode*> que_node;
queue<int> que_sum;
que_node.emplace(root);
que_sum.emplace(0);
while (!que_node.empty()) {
TreeNode* node = que_node.front();
que_node.pop();
int rec = que_sum.front() + node->val;
que_sum.pop();
if (node->left == nullptr && node->right == nullptr) {
if (rec == target) {
getPath(node);
}
} else {
if (node->left != nullptr) {
parent[node->left] = node;
que_node.emplace(node->left);
que_sum.emplace(rec);
}
if (node->right != nullptr) {
parent[node->right] = node;
que_node.emplace(node->right);
que_sum.emplace(rec);
}
}
}
return ret;
}
};
剑指 Offer 36. 二叉搜索树与双向链表(重点)
这题的想法实在是太重要了。涉及到中序遍历。主要是再中序遍历可以取到的地方进行链表操作。这一种想法很重要
注意特殊情况
class Solution { public: Node* treeToDoublyList(Node* root) { if(root == nullptr) return nullptr; dfs(root); head->left = pre; pre->right = head; return head; } private: Node *pre, *head; void dfs(Node* cur) { if(cur == nullptr) return; dfs(cur->left); //在这中间进行操作,就和普通的链表操作一样。 if(pre != nullptr) { pre->right = cur; } else { head = cur; } cur->left = pre; pre = cur; //中序遍历 dfs(cur->right); } };剑指 Offer 54. 二叉搜索树的第k大节点
简单操作,进行反中序操作就行了。注意递归的头部操作是出口,中序遍历操作在中间。有本质区别。
class Solution { public: int ret; int i; int kthLargest(TreeNode* root, int k) { dfs(root, k); return ret; } void dfs(TreeNode* root, int k){ if(root==NULL){ return; } dfs(root->right, k); i++; if(i == k){ ret = root->val; return; } dfs(root->left, k); } };剑指 Offer 55 - I. 二叉树的深度(平平无奇)
class Solution { private: int ret = 0; public: int maxDepth(TreeNode* root) { dfs(root, 0); return ret; } void dfs(TreeNode* root, int d){ if(root == NULL){ ret = max(d, ret); return; } dfs(root->left, d+1); dfs(root->right, d+1); } };简便写法
class Solution { public: int i=0; int maxDepth(TreeNode* root) { if(root==nullptr) return 0; return max(maxDepth(root->left),maxDepth(root->right))+1; } };剑指 Offer 55 - II. 平衡二叉树
上一题的扩展,自顶向下,分别比较左节点和右节点的深度即可。
先写一个函数来确定深度,然后来进行比较class Solution { public: int height(TreeNode* root) { if (root == NULL) { return 0; } else { return max(height(root->left), height(root->right)) + 1; } } bool isBalanced(TreeNode* root) { if (root == NULL) { return true; } else { return abs(height(root->left) - height(root->right)) <= 1 && isBalanced(root->left) && isBalanced(root->right); } } };剑指 Offer 07. 重建二叉树(重点)
有一个重要的条件就是需要没有重复节点,不然的话就难以构造
根据前序遍历和中序遍历的结果来反推完整的二叉树。要点是通过前序遍历的第一个节点就是根节点,然后再中序遍历里面通过哈希表来查找所在的地方,中序遍历的特点可以帮助获得左右子树的数量。然后进行递归来构建新的子树。 ```cpp class Solution { private: unordered_map
public:
TreeNode* myBuildTree(const vector
// 前序遍历中的第一个节点就是根节点
int preorder_root = preorder_left;
// 在中序遍历中定位根节点
int inorder_root = index[preorder[preorder_root]];
// 先把根节点建立出来
TreeNode* root = new TreeNode(preorder[preorder_root]);
// 得到左子树中的节点数目
int size_left_subtree = inorder_root - inorder_left;
// 递归地构造左子树,并连接到根节点
// 先序遍历中「从 左边界+1 开始的 size_left_subtree」个元素就对应了中序遍历中「从 左边界 开始到 根节点定位-1」的元素
root->left = myBuildTree(preorder, inorder, preorder_left + 1, preorder_left + size_left_subtree, inorder_left, inorder_root - 1);//此处都减去了根节点
// 递归地构造右子树,并连接到根节点
// 先序遍历中「从 左边界+1+左子树节点数目 开始到 右边界」的元素就对应了中序遍历中「从 根节点定位+1 到 右边界」的元素
root->right = myBuildTree(preorder, inorder, preorder_left + size_left_subtree + 1, preorder_right, inorder_root + 1, inorder_right);//这里代表的意思是区间。
return root;
}
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
int n = preorder.size();
// 构造哈希映射,帮助我们快速定位根节点
for (int i = 0; i < n; ++i) {
index[inorder[i]] = i;
}
return myBuildTree(preorder, inorder, 0, n - 1, 0, n - 1);k//这里的是子树的左右边界
}
};
<a name="bzYNa"></a>
### [剑指 Offer 64. 求1+2+…+n](https://leetcode-cn.com/problems/qiu-12n-lcof/)(位运算符,重点)
这题的要求是不使用条件判断符号。
<a name="izykx"></a>
#### 使用if
```cpp
class Solution {
public:
int sumNums(int n) {
return n == 0? 0 : n + sumNums(n-1);
}
};
使用逻辑运算符&&的短路性质
因为&&的特性如果前面已经判断不成立的话,后面就直接不会进去。
class Solution {
public:
int sumNums(int n) {
n && (n += sumNums(n-1));
return n;
}
};
剑指 Offer 68 - I. 二叉搜索树的最近公共祖先
二次解读:千万注意题目给的条件。
这里的二叉树是二叉搜索树,注意这个条件。利用二叉搜索树,左子树一定小于根节点,右子树一定大于根节点。一定要注意利用这个条件。这里最笨的方法,将到节点的路径记载到vector里面,选择两个节点路径的分叉处就是最近公共祖先。
两次遍历方法(笨比)
class Solution {
public:
vector<TreeNode*> getPath(TreeNode* root, TreeNode* target) {
vector<TreeNode*> path;
TreeNode* node = root;
while (node != target) {
path.push_back(node);
if (target->val < node->val) {
node = node->left;
}
else {
node = node->right;
}
}
path.push_back(node);
return path;
}
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
vector<TreeNode*> path_p = getPath(root, p);
vector<TreeNode*> path_q = getPath(root, q);
TreeNode* ancestor;
for (int i = 0; i < path_p.size() && i < path_q.size(); ++i) {
if (path_p[i] == path_q[i]) {
ancestor = path_p[i];
}
else {
break;
}
}
return ancestor;
}
};
一次遍历方法
这下面的第三四点比较关键,确实没有想到。当节点再中间时直接就找到岔点了。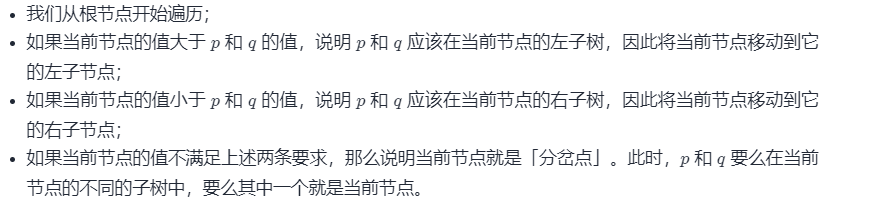
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
TreeNode* ancestor = root;
while (true) {//使用while(true)来制造无穷循环
if (p->val < ancestor->val && q->val < ancestor->val) {
ancestor = ancestor->left;
}
else if (p->val > ancestor->val && q->val > ancestor->val) {
ancestor = ancestor->right;
}
else {
break;
}
}
return ancestor;
}
};
剑指 Offer 68 - II. 二叉树的最近公共祖先(重点)
这一题与上一题不同的地方在于,这一题不是二叉搜索树
这一题的想法比较特殊,需要考虑右边和左边的情况,对于递归中的某一个节点来说
- 当一个节点的l与r都不为空时,就代表这个节点就是 答案
- 当一个节点的l与r有一个为空时,就证明答案位于另一子树或者祖先中。
- 当一个节点的l与r都为空时,就代表上层l为空。
返回值就是当前节点是否含有目标节点。
思路非常黑科技,建议反复研究。
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if (root == NULL || p == root || q == root) {
return root;
}
TreeNode* l = lowestCommonAncestor(root->left, p, q);
TreeNode* r = lowestCommonAncestor(root->right, p, q);
return l == NULL ? r : (r == NULL ? l : root);
}
};
剑指 Offer 38. 字符串的排列(记忆化+dfs)
这里要记得重复的情况
如果前面一个没有选,而且后面的等于前一个字母的情况就需要进行排除。
这里可以分解一下(常规写法)
如果没有这个判断的话,结果会错误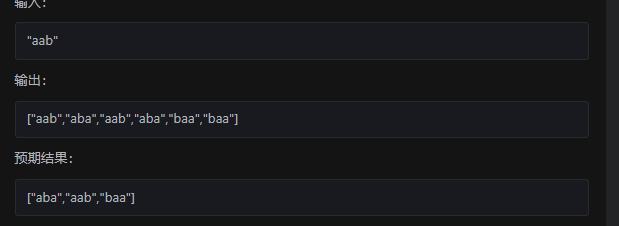
这里可以看到两个是重复的。
- 只保留一种情况,就是前面的a永远在后面的a这一种情况。
- 首先按照顺序排列,确定相同的字母都在一起
所以判断条件为, 序号大于0(不是第一个字母)&&上一个字母没有被选用(因为从前到后选用的顺序被视为正常顺序)&&本字母与上一个字母相同(客观的判断条件)
class Solution { public: vector<string> rec; vector<int> vis;//果然是记忆化+DFS void backtrack(const string& s, int i, int n, string& perm) { if (i == n) { rec.push_back(perm); return; } for (int j = 0; j < n; j++) { if (vis[j] || (j > 0 && !vis[j - 1] && s[j - 1] == s[j])) {//这里是为了去除重复的情况 continue; } vis[j] = true; perm.push_back(s[j]); backtrack(s, i + 1, n, perm); perm.pop_back(); vis[j] = false; } } vector<string> permutation(string s) { int n = s.size(); vis.resize(n);//差点忘记还有这个resize,来通过 sort(s.begin(), s.end()); string perm; backtrack(s, 0, n, perm); return rec; } };使用swap的写法(不用开辟空间来存储字符串)
这里使用了leetcode/数学/31 下一个排列的思维
class Solution { public: bool nextPermutation(string& s) { int i = s.size() - 2; while (i >= 0 && s[i] >= s[i + 1]) { i--; } if (i < 0) { return false; } int j = s.size() - 1; while (j >= 0 && s[i] >= s[j]) { j--; } swap(s[i], s[j]); reverse(s.begin() + i + 1, s.end()); return true; } vector<string> permutation(string s) { vector<string> ret; sort(s.begin(), s.end()); do { ret.push_back(s); } while (nextPermutation(s)); return ret; } };297. 二叉树的序列化与反序列化(仔细研究)
我最开始的写法没有递归的规律,使用bfs来序列化,后面反序列化的时候就很麻烦了。因为想要构建二叉树的结构,最好的情况还是使用dfs比较好。
dfs
困难题,要求是先将输入的二叉树序列化为一个字符串结构,然后将这个字符串结构反序列化为二叉树。 ```shell class Codec { public: void rserialize(TreeNode* root, string& str) {
if (root == nullptr) { str += "None,"; } else { str += to_string(root->val) + ","; rserialize(root->left, str); rserialize(root->right, str); }}
string serialize(TreeNode* root) {
string ret; rserialize(root, ret); return ret;}
TreeNode* rdeserialize(list
& dataArray) { if (dataArray.front() == "None") { dataArray.erase(dataArray.begin()); return nullptr; } TreeNode* root = new TreeNode(stoi(dataArray.front())); dataArray.erase(dataArray.begin()); root->left = rdeserialize(dataArray); root->right = rdeserialize(dataArray); return root;}
TreeNode* deserialize(string data) {
list<string> dataArray; string str; for (auto& ch : data) { if (ch == ',') { dataArray.push_back(str); str.clear(); } else { str.push_back(ch); } } if (!str.empty()) { dataArray.push_back(str); str.clear(); } return rdeserialize(dataArray);} };
<a name="ytkHm"></a>
#### bfs(层次化遍历)
使用广度优先搜索来进行操作。在反序列化时,不停的将每一层的节点输入到队列当中。然后分发左右子节点。
```shell
class Codec {
public:
//split a string according to a separation character
vector<string> split(const string & s, char sep){//这里是一个分离操作
vector<string> strs;
string tmp;
for(auto ch:s){
if(ch!=sep){
tmp+=ch;
}
else{
strs.emplace_back(tmp);
tmp.clear();
}
}
return strs;
}
// Encodes a tree to a single string.
//序列化操作,使用bfs
string serialize(TreeNode* root) {
string ans;
if(!root) {
ans+="X,";
return ans;
}
queue<TreeNode*> q;
q.push(root);
while(!q.empty()){
int q_size=q.size();
for(int i=0;i<q_size;++i){
TreeNode* cur=q.front();
q.pop();
if(!cur) {
ans+="X,";
continue;
}
ans+=to_string(cur->val);
ans+=",";
q.push(cur->left);
q.push(cur->right);
}
}
return ans;
}
// Decodes your encoded data to tree.
//反序列化操作,也是用bfs
TreeNode* deserialize(string data) {
vector<string> nodes=split(data, ',');
if(nodes[0]=="X") return nullptr;//空树
TreeNode *head=new TreeNode(atoi(nodes[0].c_str()));
queue<TreeNode*> q;
q.push(head);
int idx=1;//指示当前节点左右孩子在nodes数组中的位置(左孩子位置)
while(!q.empty()){
TreeNode *cur=q.front();
q.pop();
if(nodes[idx]!="X"){
cur->left=new TreeNode(atoi(nodes[idx].c_str()));
q.push(cur->left);
}
++idx;
if(nodes[idx]!="X"){
cur->right=new TreeNode(atoi(nodes[idx].c_str()));
q.push(cur->right);
}
++idx;
}
return head;
}
};
剑指 Offer 49. 丑数(很妙)
- 这里的想法是,每一个后面的数都是由前面的数 × 2, 3, 5来得到的
- 因此维护三个指针,分别用这个三个指针乘235来然后其中最小的数就是结果
- 这个三指针分别代表,指针所在的当前这个数还没有乘相应的值
注意这里我第一次写错,将3个if写成了if else 写法。这里少考虑的情况,例如6这个数字,可能是由32得到,也有可能是由23得到,要去除这种重复的情况。因此对235每个都单独判断一次。
class Solution {
public:
int nthUglyNumber(int n) {
int p2 = 1, p3 = 1, p5 = 1;
vector<int> dp(n + 1);
dp[1] = 1;
for(int i = 2; i <= n; i++){
dp[i] = min(dp[p2]*2, min(dp[p3]*3, dp[p5]*5));
if(dp[i] == dp[p2]*2){
p2++;
}
if(dp[i] == dp[p3]*3){
p3++;
}
if(dp[i] == dp[p5]*5) {
p5++;
}
}
return dp[n];
}
};
剑指 Offer 19. 正则表达式匹配(每看,头痛)
class Solution {
public:
bool isMatch(string s, string p) {
int m = s.size();
int n = p.size();
auto matches = [&](int i, int j) {
if (i == 0) {
return false;
}
if (p[j - 1] == '.') {
return true;
}
return s[i - 1] == p[j - 1];
};
vector<vector<int>> f(m + 1, vector<int>(n + 1));
f[0][0] = true;
for (int i = 0; i <= m; ++i) {
for (int j = 1; j <= n; ++j) {
if (p[j - 1] == '*') {
f[i][j] |= f[i][j - 2];
if (matches(i, j - 1)) {
f[i][j] |= f[i - 1][j];
}
}
else {
if (matches(i, j)) {
f[i][j] |= f[i - 1][j - 1];
}
}
}
}
return f[m][n];
}
};
回溯法
集合和排列的区别是,集合没有顺序这一说法231,123,312都是同一种情况,而对于排列这是三种不同的情况。因此集合的每一次dfs的i都是从上一次的i开始,防止重复情况。然而排列不同,每次的dfs i都是从0开始,因此顺序不同也属于不同情况。排列一般需要使用记忆化来记录已经选择的元素避免重复选取,而当给定数组有重复的情况也需要剪枝,比如 1113,这里有三个1 ,虽然下标不同但是可以选出三个113,因此需要进行剪枝,当元素的前面元素和当前元素相等的时候直接跳过。这样就只会选取第一个1!!!
剑指 Offer II 079. 所有子集(集合)
class Solution {
private:
vector<vector<int>> vec;
public:
vector<vector<int>> subsets(vector<int>& nums) {
vector<int> num;
dfs(nums, num, 0);
return vec;
}
void dfs(vector<int> &nums, vector<int>& num,int idx) {
vec.push_back(num);
if(idx == nums.size()) return;
for(int i = idx; i < nums.size(); i++) {
num.push_back(nums[i]);
dfs(nums, num, i+1);
num.pop_back();
}
}
};
剑指 Offer II 080. 含有 k 个元素的组合(k集合)
和上题差不多
class Solution {
private:
vector<vector<int>> vec;
public:
vector<vector<int>> combine(int n, int k) {
vector<int> num;
dfs(n, k, num, 1);
return vec;
}
void dfs(int n , int k, vector<int>& num, int idx) {
if(num.size() == k) {
vec.push_back(num);
return;
}
for(int i = idx; i <= n; i++) {
num.push_back(i);
dfs(n, k , num, i+1);
num.pop_back();
}
}
};
剑指 Offer II 081. 允许重复选择元素的组合(带重复的集合)
class Solution {
private:
vector<vector<int>> vec;
public:
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
vector<int> num;
dfs(candidates, target, 0, num, 0);
return vec;
}
void dfs(vector<int>& candidates, int target, int sum, vector<int>& num, int idx) {
if(sum > target||idx == candidates.size()) return ;
if(sum == target) {
vec.push_back(num);
return;
}
for(int i = idx; i < candidates.size(); i++) {
num.push_back(candidates[i]);
sum += candidates[i];
dfs(candidates, target, sum, num, i);
sum -= candidates[i];
num.pop_back();
}
}
};
剑指 Offer II 082. 含有重复元素集合的组合(原数组重复的集合)
class Solution {
private:
vector<vector<int>> vec;
public:
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
vector<int> num;
sort(candidates.begin(), candidates.end());
dfs(candidates, target, 0, num);
return vec;
}
void dfs(vector<int>& candidates, int target, int idx, vector<int> &num) {
if(target == 0) {
vec.emplace_back(num);
return;
}
if(target < 0||idx == candidates.size()) {
return ;
}
for(int i = idx; i < candidates.size(); i++) {
if(i > idx&& candidates[i] == candidates[i-1]) {
continue;
}
num.push_back(candidates[i]);
target -= candidates[i];
dfs(candidates, target, i+1, num);
target += candidates[i];
num.pop_back();
}
}
};
剑指 Offer II 083. 没有重复元素集合的全排列(全排列)
- 排列问题因为顺序不同也算一种情况,所以每一次递归需要从0开始。
- 为了防止选取重复的元素,需要进行记忆化,记录已经选取的元素。
class Solution { private: vector<vector<int>> vec; vector<bool> flag; public: vector<vector<int>> permute(vector<int>& nums) { vector<int> num; flag.resize(nums.size()); dfs(nums, num); return vec; } void dfs(vector<int>& nums, vector<int>& num) { if (num.size() == nums.size()) { vec.emplace_back(num); return; } for(int i = 0; i < nums.size(); i++) { if(flag[i]) continue; flag[i] = true; num.push_back(nums[i]); dfs(nums, num); num.pop_back(); flag[i] = false; } } };剑指 Offer II 084. 含有重复元素集合的全排列
这里需要注意,含有重复元素的全排列,这里可以有两种情况。第一种情况只能选择从前往后顺序选择,这里选择(i>0 &&nums[i] == nums[i-1]&&!flag[i-1]),第二种情况只能从后往前倒序选择(i>0 &&nums[i] == nums[i-1]&&flag[i-1])class Solution { private: vector<vector<int>> vec; vector<bool> flag; public: vector<vector<int>> permuteUnique(vector<int>& nums) { vector<int> num; flag.resize(nums.size()); sort(nums.begin(), nums.end()); dfs(nums, num); return vec; } void dfs(vector<int>& nums, vector<int> &num) { if(num.size() == nums.size()) { vec.emplace_back(num); return; } for(int i = 0; i < nums.size(); i++) { if(flag[i]||(i>0 &&nums[i] == nums[i-1]&&flag[i-1])) {//这里的flag[i-1]为true和false都行,分别代表从前往后和从后往前两种特例。只需要一种就行。 continue; } flag[i] = true; num.push_back(nums[i]); dfs(nums, num); num.pop_back(); flag[i] = false; } } };剑指 Offer II 085. 生成匹配的括号
class Solution { private: vector<char> chars = {'(', ')'}; vector<string> res; int flag = 0;//flag用来判断两种括号的数量,如果两种括号的数量相同就为0,如果反括号多就为负数,这种情况可以直接剪枝。如果正括号多就为正数。 public: vector<string> generateParenthesis(int n) { string str = ""; dfs(n, str, 0); return res; } void dfs(int n, string &str, int num) {//这里的第三个参数num用来表示括号的数量,如果括号的数量等于括号对数的两倍进入判断条件。 if(flag < 0) return; if(num == 2*n) {//当括号数量等于2倍括号的对数,而且正反括号相等则找到正确答案。 if(flag == 0) { res.push_back(str); } return ; } for(int i = 0; i < 2; i++) { str.push_back(chars[i]); int a = i ? -1:1; flag += a; dfs(n, str, num+1); str.pop_back(); flag -= a; } } };剑指 Offer II 086. 分割回文子字符串(可以看)
回溯中进行处理
class Solution { private: vector<vector<string>> res; public: vector<vector<string>> partition(string s) { vector<string> strs; dfs(s, strs, 0); return res; } void dfs(string &s, vector<string> &strs, int idx) {//这里的idx代表当前层的子串的起始位置 if(idx == s.size()) { res.push_back(strs); return; } for(int i = 1; i <= (s.size() - idx); i++) {//这里的i表示能取的子串的长度。 string str = s.substr(idx, i); if(helper(str)) {//是回文串则进入下一层递归 strs.push_back(str); dfs(s, strs, idx+i); strs.pop_back(); } else continue; } } bool helper(string &str) {//判断是不是回文串 int l = 0, r = str.size() -1;//双指针 while(l < r) { if(str[l] != str[r]) return false; l++; r--; } return true; } };先进行动态规划预处理,然后进行回溯
```cpp class Solution { private: vectorans; int n;
public: void dfs(const string& s, int i) { if (i == n) { ret.push_back(ans); return; } for (int j = i; j < n; ++j) { if (f[i][j]) { ans.push_back(s.substr(i, j - i + 1)); dfs(s, j + 1); ans.pop_back(); } } }
vector<vector<string>> partition(string s) {
n = s.size();
f.assign(n, vector<int>(n, true));
for (int i = n - 1; i >= 0; --i) {//动态规划先处理是不是回文串
for (int j = i + 1; j < n; ++j) {
f[i][j] = (s[i] == s[j]) && f[i + 1][j - 1];
}
}
dfs(s, 0);
return ret;
}
};
<a name="B5E4z"></a>
### [剑指 Offer II 087. 复原 IP](https://leetcode-cn.com/problems/0on3uN/)
- 看注释即可
```cpp
class Solution {
private:
vector<string> res;
public:
vector<string> restoreIpAddresses(string s) {
string str = "";
back_trace(s, str, 0, 0);
return res;
}
void back_trace(string &s, string & str, int idx, int num) {
if(num > 4) return;//剪枝
if(num == 4&&idx == s.size()) {//找到出口,分了四个整数,且idx到了末尾
res.push_back(str);
return;
}
for(int i = 1; i <= 3; i++) {//这里表示分别从s中取1、2、3个数字
if(idx + i > s.size()) return;
string tmp = s.substr(idx, i);
int a = stoi(tmp);//字符串转换为int类型
if(a > 255||(i > 1&& tmp[0] == '0')) continue;//剪枝
if(str.size()) {//判断是不是第一个整数,如果是的话前面不用加点
str.push_back('.');
}
str += tmp;
back_trace(s, str, idx+i, num+1);
str.erase(str.size()-i,i);
if(str.size()) {//与上面同理,这里是删去点
str.pop_back();
}
}
}
};

若有收获,就点个赞吧
0 人点赞
