- 剑指 Offer II 047. 二叉树剪枝(dfs剪枝)">剑指 Offer II 047. 二叉树剪枝(dfs剪枝)
- 剑指 Offer II 049. 从根节点到叶节点的路径数字之和(dfs)">剑指 Offer II 049. 从根节点到叶节点的路径数字之和(dfs)
- 剑指 Offer II 048. 序列化与反序列化二叉树(必看!!)">剑指 Offer II 048. 序列化与反序列化二叉树(必看!!)
- 剑指 Offer II 050. 向下的路径节点之和">剑指 Offer II 050. 向下的路径节点之和
- 剑指 Offer II 051. 节点之和最大的路径(重点)">剑指 Offer II 051. 节点之和最大的路径(重点)
- 前中后序遍历
- 剑指 Offer II 052. 展平二叉搜索树(中序遍历)">剑指 Offer II 052. 展平二叉搜索树(中序遍历)
- 剑指 Offer II 053. 二叉搜索树中的中序后继(中序遍历)">剑指 Offer II 053. 二叉搜索树中的中序后继(中序遍历)
- 剑指 Offer II 054. 所有大于等于节点的值之和(反中序遍历)">剑指 Offer II 054. 所有大于等于节点的值之和(反中序遍历)
- 剑指 Offer II 055. 二叉搜索树迭代器">剑指 Offer II 055. 二叉搜索树迭代器
- 剑指 Offer II 056. 二叉搜索树中两个节点之和">剑指 Offer II 056. 二叉搜索树中两个节点之和
- 前缀树、
剑指 Offer II 047. 二叉树剪枝(dfs剪枝)
注意剪枝的方式,只有左右字节点都为空且当前的val为0,才能剪掉当前节点
class Solution {public:TreeNode* pruneTree(TreeNode* root) {if(!root) return nullptr;root->left = pruneTree(root->left);root->right = pruneTree(root->right);if(root->val == 0&&!root->left&&!root->right) return nullptr;return root;}};
剑指 Offer II 049. 从根节点到叶节点的路径数字之和(dfs)
注意这里之所以不使用回溯法,是因为输入左右字节点的num都是一样的。因此不需要回溯
class Solution {private:int ret;public:int sumNumbers(TreeNode* root) {dfs(root, 0);return ret;}void dfs(TreeNode* root, int num) {if(!root) return;num = num*10+root->val;if(!root->left&&!root->right) {ret +=num;return;}dfs(root->left, num);dfs(root->right, num);}};
剑指 Offer II 048. 序列化与反序列化二叉树(必看!!)
使用分割函数拆分字符串会使得题目更简单
- 千万注意+=的效率比=+的效率要高,这里换成=+直接超时,因为=+是先申请一个临时的内存空间表达式存放操作之后的值,然后将这个值赋值,然后在释放。而+=则直接找到地址进行修改,因此运行效率更高。
- 使用队列来完成编码解码
用一个idx来指示左右孩子在数组中的位置
class Codec {public://根据分割符拆分字符串vector<string> split(const string & s, char sep){vector<string> strs;string tmp;for(auto ch:s){if(ch!=sep){tmp+=ch;}else{strs.emplace_back(tmp);tmp.clear();}}return strs;}// Encodes a tree to a single string.string serialize(TreeNode* root) {string ans;if(!root) {ans+="X,";return ans;}queue<TreeNode*> q;q.push(root);while(!q.empty()){int q_size=q.size();for(int i=0;i<q_size;++i){TreeNode* cur=q.front();q.pop();if(!cur) {ans+="X,";//用X来表示空节点就行了continue;}ans+=to_string(cur->val);ans+=",";q.push(cur->left);q.push(cur->right);}}cout << ans << endl;return ans;}// Decodes your encoded data to tree.TreeNode* deserialize(string data) {vector<string> nodes=split(data, ',');//这个分割函数是在是太妙了if(nodes[0]=="X") return nullptr;//空树TreeNode *head=new TreeNode(stoi(nodes[0]));queue<TreeNode*> q;q.push(head);int idx=1;//指示当前节点左右孩子在nodes数组中的位置(左孩子位置),父节点使用一个idx后挪两位。while(!q.empty()){TreeNode *cur=q.front();q.pop();if(nodes[idx]!="X"){//这里只判断不为空的情况,因为TreeNode的构造函数左右子节点默认为1.cur->left=new TreeNode(stoi(nodes[idx]));q.push(cur->left);}++idx;if(nodes[idx]!="X"){cur->right=new TreeNode(stoi(nodes[idx]));q.push(cur->right);}++idx;}return head;}};
剑指 Offer II 050. 向下的路径节点之和
深度优先搜索
分别计算从每个根节点开始的值
class Solution { public: int rootSum(TreeNode* root, int targetSum) { if (!root) { return 0; } int ret = 0; if (root->val == targetSum) { ret++; } ret += rootSum(root->left, targetSum - root->val); ret += rootSum(root->right, targetSum - root->val); return ret; } int pathSum(TreeNode* root, int targetSum) { if (!root) { return 0; } int ret = rootSum(root, targetSum);//以每一个节点为根节点出发,来寻找targetsum ret += pathSum(root->left, targetSum); ret += pathSum(root->right, targetSum); return ret; } };前缀和
为了避免重复计算就,将每一个路径的前缀和通过回溯法的形式来存储在哈希表里面。
- 这里为了避免路径之间的相互影响,使用回溯法。
- 哈希表的键是从根节点到当前节点的前缀和,值是前缀和出现的次数。
ret代表以当前节点,以及后面所有节点为终点的满足条件的情况。
class Solution { public: unordered_map<long long,int> hash;//哈希表键是前缀和的值,值为出现的次数。 int ret = 0; void dfs(TreeNode* root, long long sum, int targetSum){ if(!root) return; sum += root->val; //hash[sum]++如果写在这里如果targetsum为0,就会默认多了一次满足条件。但是实际上并不存在路径。 if(hash.count(sum-targetSum)) {//每一层都是计算以当前节点为终点的情况的多少。 ret += hash[sum-targetSum]; } hash[sum]++;//之所以写在这里是防止出现重复计算的情况,如果写在条件判断之前,当target为0的时候,会出现多计算一次的情况。 dfs(root->left, sum, targetSum); dfs(root->right, sum, targetSum); hash[sum]--;//避免干扰到别的分支 return; } int pathSum(TreeNode* root, int targetSum) { hash[0] = 1; dfs(root, 0, targetSum); return ret; } };剑指 Offer II 051. 节点之和最大的路径(重点)
这题一开始,我是用了一个函数专门用来计算最大贡献,然后一个函数用来计算节点最大值。后面才发现可以把最大值作为成员变量,然后把两个递归合并,只写一个递归。
Timeout写法
class Solution { public: int maxPathSum(TreeNode* root) { if(!root) return INT_MIN; int sum = root->val+dfs(root->left)+dfs(root->right); return max(sum, max(maxPathSum(root->left), maxPathSum(root->right)));//这个返回值写道成员变量里面 } int dfs(TreeNode* root) { if(!root) return 0; int num = root->val + max(dfs(root->left), dfs(root->right)); return max(0, num); //这个返回值作为总体返回值。 } };合并写法
class Solution { public: int maxnum = INT_MIN; int maxPathSum(TreeNode* root) { dfs(root); return maxnum; } int dfs(TreeNode* root) { if(!root) return 0; int left = dfs(root->left); int right = dfs(root->right); maxnum = max(root->val + left+right, maxnum);//最大值 int num = root->val + max(left, right);//最大贡献 return max(0, num); } };前中后序遍历
剑指 Offer II 052. 展平二叉搜索树(中序遍历)
难点初始化一个全局变量 prenode节点来表示前一个节点
- 使用一个dummy来表示root节点的头一个节点
在中序便利中需要将当前节点的左节点置空,因为节点的大方向是从左往右的。而且当遍历到最后一个节点时,节点的右节点一定为空,但是左节点不一定。因此每次遍历需要将当前节点置空。
class Solution { public: TreeNode* prenode; TreeNode* increasingBST(TreeNode* root) { TreeNode* dummy = new TreeNode(-1); prenode = dummy; inorder(root); return dummy->right; } void inorder(TreeNode* root) { if(!root) return; inorder(root->left); prenode->right = root; root->left = nullptr;//这里是当前节点的左节点置空 prenode = root; inorder(root->right); } };剑指 Offer II 053. 二叉搜索树中的中序后继(中序遍历)
这题是寻找指定节点按照中序遍历的后一个节点。
class Solution { private: TreeNode* pre = nullptr; public: TreeNode* inorderSuccessor(TreeNode* root, TreeNode* p) { if(!root) return nullptr; TreeNode* n1 = inorderSuccessor(root->left, p); if(n1) return n1; if(pre == p ) { return root; } else pre = root; TreeNode* n2 = inorderSuccessor(root->right, p); return n2; } };剑指 Offer II 054. 所有大于等于节点的值之和(反中序遍历)
之前写过一次,可以用一个数组保存下来
- 这里使用反中序遍历
从最右端开始,定义一个成员变量sum表示和。
class Solution { private: int sum = 0; public: TreeNode* convertBST(TreeNode* root) { if(!root) return nullptr; convertBST(root->right); sum += root->val; root->val = sum; convertBST(root->left); return root; } };剑指 Offer II 055. 二叉搜索树迭代器
可以使用递归来保持一个数据结构来完成操作,但是空间复杂度为O(n)
更推荐使用迭代用栈来维护,空间复杂度为树的高度,因为使用栈来完成树的遍历,同一时间只有h个节点在栈中。class BSTIterator { private: TreeNode* cur; stack<TreeNode*> stk; public: BSTIterator(TreeNode* root): cur(root) {} int next() { while (cur != nullptr) { stk.push(cur); cur = cur->left; } cur = stk.top(); stk.pop(); int ret = cur->val; cur = cur->right; return ret; } bool hasNext() { return cur != nullptr || !stk.empty(); } };剑指 Offer II 056. 二叉搜索树中两个节点之和
不知道怎么利用二叉搜索树的性质。
class Solution { private: unordered_set<int> hash; public: bool findTarget(TreeNode* root, int k) { if(!root) return false; if(hash.count(k - root->val)) { return true; } hash.insert(root->val); return findTarget(root->left, k)||findTarget(root->right, k); } };前缀树、
模板
```cpp class Solution { private:
public:
struct Trie {
vector
Trie* searchprx(string prefix) {
Trie* node = root;
for(auto c : prefix) {
if(!node->next[c-'a']) return NULL;
node = node->next[c-'a'];
}
return node;
}
//查看word是否为前缀树中的前缀。
bool search(string word) {
return this->searchprx(word)&&this->searchprx(word)->isend;
}
//查看prefix是否在前缀树中
bool startsWith(string prefix) {
return this->searchprx(prefix);
}
}
<a name="QYhlQ"></a>
### [剑指 Offer II 062. 实现前缀树](https://leetcode-cn.com/problems/QC3q1f/)
- 这里需要遇到了error: expected parameter declarator,是因为vector<Trie*> next(26),编译器无法区分这个vector是成员变量声明,还是成员方法声明。所以后续的初始化挪到初始化列表。
```cpp
class Trie {
public:
vector<Trie*> next;//这里是因为二义性,如果vector<Trie*> next(26);编译器无法区分是成员变量还是成员方法。
bool isend = false;
/** Initialize your data structure here. */
Trie() :next(26){
}
/** Inserts a word into the trie. */
void insert(string word) {
Trie* node = this;
for(auto c : word) {
if(node->next[c-'a'] == NULL) {
node->next[c-'a'] = new Trie;
}
node = node->next[c-'a'];
}
node->isend = true;
}
Trie* searchprx(string prefix) {
Trie* node = this;
for(auto c : prefix) {
if(!node->next[c-'a']) return NULL;
node = node->next[c-'a'];
}
return node;
}
/** Returns if the word is in the trie. */
bool search(string word) {
return this->searchprx(word)&&this->searchprx(word)->isend;
}
/** Returns if there is any word in the trie that starts with the given prefix. */
bool startsWith(string prefix) {
return this->searchprx(prefix);
}
};
剑指 Offer II 063. 替换单词
- 这是上一题的升级版
不要怕麻烦就不写!!!
class Solution { public: struct Trie {//前缀树结构体 vector<Trie*> next; bool isend; Trie():next(26), isend(false) {}; }; Trie* root = new Trie; void buildtree(vector<string> &dictionary) {//以dicitonary构建前缀树 for(auto str : dictionary) { Trie* node = this->root; for(auto c : str) { if(!node->next[c-'a']) { node->next[c-'a'] = new Trie; } node = node->next[c-'a']; } node->isend = true; } } string searchprefix(string words) {//在前缀字典中寻找,找到的符合的前缀一定是最短的 Trie* node = this->root; string str = ""; for(auto c : words) { if(!node->next[c-'a']) { return words; } str += c; node = node->next[c-'a']; if(node->isend) return str; } return words; } vector<string> split(string word) {//将word以空格分割为数个字符串 vector<string> ret; string str; for(auto c : word) { if(c == ' ') { ret.push_back(str); str.clear(); } else { str += c; } } ret.push_back(str); return ret; } string replaceWords(vector<string>& dictionary, string sentence) { this->buildtree(dictionary); string ret = ""; vector<string> words = split(sentence); for(int i = 0; i < words.size(); i++) { if(i == words.size()-1) { ret += searchprefix(words[i]); } else { ret += searchprefix(words[i]); ret += " "; } } return ret; } };剑指 Offer II 064. 神奇的字典(前缀树+dfs)
这题是更加升级版,主要是这个思路需要想到。 ```cpp // 构造前缀树节点 class Trie { public: bool isWord; vector
void insert(const string& str) {
Trie* node = this; for (auto& ch : str) { if (node->children[ch - 'a'] == nullptr) { node->children[ch - 'a'] = new Trie(); } node = node->children[ch - 'a']; } node->isWord = true;} };
class MagicDictionary { private: Trie root; bool dfs(Trie root, string& word, int i, int edit) { if (root == nullptr) { return false; }
if (root->isWord && i == word.size() && edit == 1) {//edit代表编辑过一次
return true;
}
if (i < word.size() && edit <= 1) {//这里代表编辑次数小于等于1
bool found = false;
for (int j = 0; j < 26 && !found; ++j) {
//这一句使用来更新edit,如果当前的j代表的字符相等就不变,否则认为编辑了一次。
int next = (j == word[i] - 'a') ? edit : edit + 1;
found = dfs(root->children[j], word, i + 1, next);
}
return found;
}
return false;
}
public: /* Initialize your data structure here. / MagicDictionary() { root = new Trie(); }
void buildDict(vector<string> dictionary) {
for (auto& word : dictionary) {
root->insert(word);
}
}
bool search(string searchWord) {
return dfs(root, searchWord, 0, 0);
}
};
<a name="IzAnC"></a>
### [剑指 Offer II 065. 最短的单词编码](https://leetcode-cn.com/problems/iSwD2y/)(后缀+ dfs)
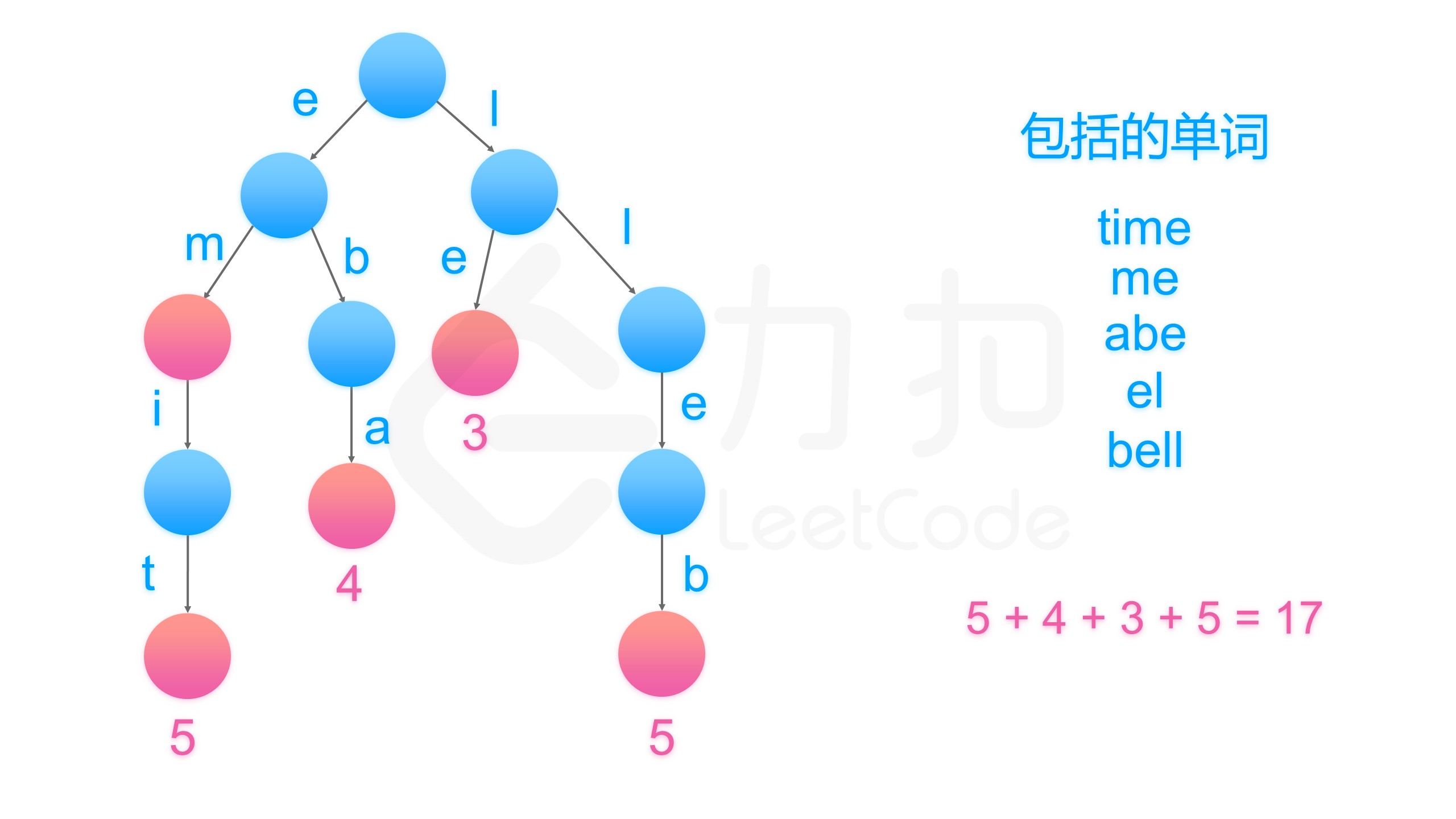
- 这一题非常巧妙,要转化为后缀才好写
- 需要计算一条路径的长度
- 统计叶子节点代表的单词长度加1的和即为我们要的答案
```cpp
class Solution {
public:
struct Trie {
bool isend;//代表是不是叶子节点
vector<Trie*> next;
int count;//代表字符数目,也就是深度-1,因为root是不含字符的。
Trie(): isend(false), next(26), count(0) {}
};
int ret = 0;//返回值
Trie* root = new Trie;
void insert(string &word) {
Trie *node = this->root;
for(auto c : word) {
if(!node->next[c-'a']) {
node->next[c-'a'] = new Trie;
node->next[c-'a']->count = node->count+1;
node->isend = false;//确保一条路径只有一个被标记叶子。
}
node = node->next[c-'a'];
}
for(int i = 0; i < 26; i++) {//只有最后一个节点才能为叶子
if(node->next[i]) return;
}
node->isend = true;
return;
}
void dfs(Trie* node) {//递归所有的叶子节点。
if(!node) return ;
if(node->isend) {
ret += node->count;
ret++;
}
for(int i = 0; i < 26; i++) {
dfs(node->next[i]);
}
}
int minimumLengthEncoding(vector<string>& words) {
Trie* node = this->root;
for(auto word : words) {
reverse(word.begin(), word.end());//将前缀转化为后缀
this->insert(word);
}
dfs(node);
return ret;
}
};
剑指 Offer II 066. 单词之和
前缀和的简单应用
class MapSum {
public:
/** Initialize your data structure here. */
struct Trie {
vector<Trie*> next;
bool isend;
int val;
Trie() : next(26), isend(false), val(0) {}
};
Trie* root = new Trie;
MapSum() {
}
void insert(string key, int val) {
Trie* node = this->root;
for(auto c : key) {
if(!node->next[c-'a']) {
node->next[c-'a'] = new Trie;
}
node = node->next[c-'a'];
}
node->isend = true;
node->val = val;
}
Trie* searchprefix(string &prefix) {
Trie* node = this->root;
for(auto it : prefix) {
if(!node->next[it-'a']) {
return nullptr;
}
node = node->next[it-'a'];
}
return node;
}
int getsum(Trie * node) {
if(!node) return 0;
int sum = 0;
if(node->isend) sum += node->val;
for(int i = 0; i < 26; i++) {
sum = sum + getsum(node->next[i]);
}
return sum;
}
int sum(string prefix) {
Trie* node = searchprefix(prefix);
return getsum(node);
}
};
剑指 Offer II 067. 最大的异或(太难了)
- 异或+字典树
- 把数组中的每个数按照二进制位插入到前缀树中,根节点存储最高位,每一条路径都代表一个整数。
- 对于没一个int形元素都有32位,所以前缀树的深度为32
- 遍历数组,在前缀树中寻找与当前元素的当前位不同的路径(因为两个数在同一位的值不用,他们异或的结果才是最大的)
两层循环,第一层遍历N个数,第二层遍历32位故时间复杂度为O(n) ```cpp class Solution { private: struct TrieNode //前缀树结构体,只用来存位的值(0或1) {
vector<shared_ptr<TrieNode>> children; TrieNode() : children(2, 0) {}};
shared_ptr
root = make_shared ();
public:
void buildTrieNode(vector
node = node->children[bit];
}
}
}
int findMaximumXOR(vector<int>& nums) {
buildTrieNode(nums);
int maxXorSum = 0;
for (int& num : nums) //遍历数组
{
auto node = root;
int xorSum = 0;
for (int i = 31; i >= 0; -- i) //从高位开始寻找
{
int bit = (num >> i) & 1;
if (node->children[1 - bit] != nullptr) //尽量走与当前位相反的路径才能达到最大异或值
{
xorSum = (xorSum << 1) + 1;
node = node->children[1 - bit];
}
else
{
xorSum = xorSum << 1;
node = node->children[bit];
}
}
maxXorSum = max(maxXorSum, xorSum);
}
return maxXorSum;
}
}; ```

若有收获,就点个赞吧
0 人点赞
