正则表达式 ( regular expression ) 是一种描述字符序列的方法。这里我们介绍如何使用C++正则表达式库。它是新标准库的一部分。
一、库组件
RE库定义在头文件regex中,它包含多个组件:
//三个方法regex_match //将一个字符序列与一个正则表达式匹配regex_search //寻找第一个与正则表达式匹配的子序列regex_replace //使用给定格式替换一个正则表达式//四种类型regex //表示有一个正则表达式的类smatch //容器类,保存在string中搜索的结果ssub_match //string中匹配的子表达式的结果sregex_iterator //迭代器适配器,调用regex_search来遍历一个string中所有匹配的子串
输入序列类型可能有多种形式:
- string
- wstring
- const char*
- const wchar_t*
RE库为不同的输入序列类型定义了对应版本的组件,如果使用类型不匹配的组件会产生错误。
//序列为:string 使用组件:regex、smatch、ssub_match、sregex_iterator//序列为:const char* 使用组件:regex、cmatch、csub_match、cregex_iterator//序列为:wstring: 使用组件:wregex、wsmatch、wssub_match、wsregex_iterator//序列为:const wchar_t*: 使用组件:wregex、wcmatch、wcsub_match、wcregex_iterator
二、search和match方法
//如果seq的子串与r匹配返回true,否则false。regex_search(seq, m, r, mft);regex_search(seq, r, mft); //seq: 目标字符序列,可以是如下类型:// 1、string// 2、C风格字符串数组指针// 3、一对迭代器beg、end,表示范围// r: regex对象,正则表达式。// m: smatch对象,保存匹配结果细节,和seq必须具有兼容的类型。//mft: match_flag_type值,可选,下面会讲。//如果整个seq与r匹配,返回true,否则false。regex_match(seq, m, r, mft);regex_match(seq, r, mft); //seq: 目标字符序列,可以是如下类型:// 1、string// 2、C风格字符串数组指针// 3、一对迭代器beg、end,表示范围// r: regex对象,正则表达式。// m: smatch对象,保存匹配结果细节,和seq必须具有兼容的类型。//mft: match_flag_type值,可选
例子
string pattern("[^c]ei"); //查找不在字符c之后的字符串eipattern = "[[:alpha:]]*" + pattern + "[[:alpha:]]*"; //我们需要包含pattern的整个单词//[[:alpha:]]匹配任意字母regex r(pattern); //构造一个用于查找模式的regexsmatch results; //定义一个对象保存搜索结果string test_str = "receiptfreindtheifreceive";if(regex_search(test_str, results, r)) //test_str查找匹配r的串cout << results.str() << endl; //输出:freind
三、regex类型
//regex保存char类型、wregex保存wachar_t类型//构造函数和赋值操作可能抛出类型为regex_error的异常。//用re构建一个正则表达式对象,默认使用ECMAScript处理对象regex r(re); //re:表示一个正则表达式,可以是:// string:字符串// beg, end:一对范围迭代器// cp:C风格字符数组指针// cp, n:字符数组 + 字符数量// {c1, c2,...}:字符列表//用re构建一个正则表达式对象,并指定对象如何处理regex r(re, f); //f指出对象如何处理的标志,默认ECMAScript,可能值如下://值都定义在regex和regex_constants::syntax_option_type中。// 1、icase 在匹配过程中忽略大小写// 2、nosubs 不保存匹配的子表达王// 3、optimize 执行速度优先千构造速度// 4、ECMAScri pt 使用 ECMA-262 指定的语法,默认值。// 5、basic 使用 POSIX 基本的正则表达式语法// 6、extended 使用 POSIX 扩展的 正则表达式语法// 7、awk 使用 POSIX 版本的 awk 语言 的语法// 8、grep 使用 POSIX 版本的 grep 的语法// 9、egrep 使用 POSIX 版本的 egrep 的语法r = re; //r的正则表达式替换为rer.assign(re, f); //含义同上r.mark_count(); //子表达式的数目r.flags(); //返回r的标志集
例子
//匹配*.cpp、*.cxx、*.cc文件。regex r("[[:alnum:]]+\\.(cpp|cxx|cc)$", regex::icase);smatch results;string filename;while (cin >> filename)if(regex_search(filename, results, r))cout << results.str()<< endl ; //打印匹配结果
regex错误
我们可以将正则表达式本身看作用一种简单程序设计语言编写的“程序”。这种语言不是由 C++编译器解释的。正则表达式是在运行时,当一个regex对象被初始化或被赋予一个新模式时,才被“编译"的。与任何其他程序设计语言一样,我们用这种语言编写的正则表达式也可能有错误。如果正则表达式存在错误,则在运行时标准库会抛出一个类型为regex_error的异常。
//这里仅为了展示regex_error异常的结构,并不是有意义的代码。regex_error e = {what = "shit"; //"描述发生了什么错误";code = 4; //某个错误类型对应的数值编码,可能的数值如下://定义在regex和regex_constants::error_type中// error_collate:0 无效的元素校对请求// error_ctype:1 无效的字符类// error_escape:2 无效的转义字符或无效的尾置转义// error_backref:3 无效的向后引用// error_brack:4 不匹配的方括号([或])// error_paren:5 不匹配的小括号((或))// error_brace:6 不匹配的花括号({或})// error_badbrace:7 {}中无效的范围// error_range:8 无效的字符范围(如[z-a])// error_space:9 内存不足,无法处理此正则表达式// error_badrepeat:10 重复字符(*、?、+或{)之前没有有效的正则表达式// error_complexity:11 要求的匹配过于复杂// error_stack:12 栈空间不足,无法处理匹配}
例子
try {//错误:alnum漏掉了右括号,构造函数会抛出异常regex r{"[[:alnum:]]+\\.{cpp|cxx|cc)$", regex::icase);}catch(regex_error e){cout << e.what{) << "\ncode:" << e.code{) << endl ;}//输出如下://regex_error(error_brack)://The expression contained mismatched [and].//code: 4
正则表达式的“运行时编译”非常慢,所以我们应该避免创建过多的正则表达式,也避免在循环迭代中创建。
四、Regex迭代器
//以下操作也适用于//cregex_iterator//wsregex_iterator//wcregex_iteratorsregex_iterator it(b, e, r);// 一个sregex_iterator, 遍历迭代器b和e表示的string。// 它调用sregex_search(b, e, r)将it定位到输入中第一个匹配的位置sregex_iterator end; //sregex_iterator的尾后迭代器*it //根据最后一个调用regex_search的结果,返回一个smatch对象的引用it-> //同上,返回一个指向smatch对象的指针++it //从输入序列当前匹配位置开始调用regex_search。返回递增后迭代器it++ //从输入序列当前匹配位置开始调用regex_search。返回旧值it1 != it2 //it1 == it2为true的情况:it1 == it2 // 1、都是相同类型迭代器的尾后迭代器// 2、从相同的输入序列和regex对象构造//其余it1 != it2为ture。
五、smatch
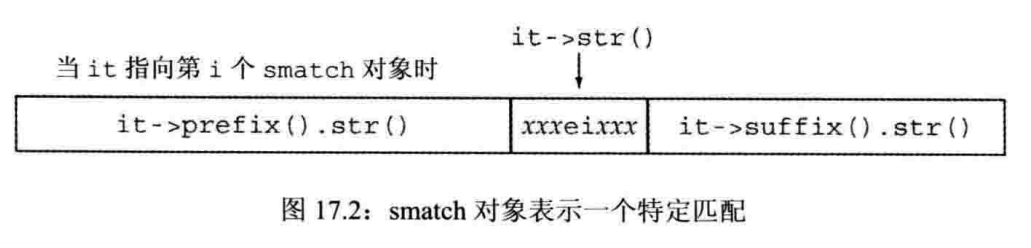
//这些操作也适用于cmatch、wsmatch、wcmatch和对应的csub_match、wssub_match、wcsub_match。//假设m是一个smatch对象。m.ready() //如果已经通过调用regex_serach或regex_match设置了m,//则返回true; 否则返回false。//如果ready返回false, 则对m进行操作是未定义的m.size() //如果匹配失败,则返回0,否则返回最近一次匹配的正则表达式中子表达式的数目m.empty() //若m.size()为0, 则返回truem.prefix() //当前匹配之前的序列,ssub_match对象m.suffix() //当前匹配之后的部分,ssub_match对象m.format(fmt, mft); // 使用格式字符串fmt生成格式化输出,返回一个string// fmt: 格式化字符串,可以是string、C风格字符数组指针。// mft: match_flag_type标志,可选,默认值format_defaultm.format(dest, fmt, mft);// 同上,但是输出到dest写入迭代器指向的位置。// dest: 写入迭代器// fmt: 格式化字符串,可以是string、字符数组范围的一对指针// mft: match_flag_type标志,可选,默认值format_default//0 <= n < m.size()。//注意!!第0个子匹配表示整个匹配。m.length(n) //第n个匹配的子表达式的大小,第m.position(n) //第n个子表达式距序列开始的距离m.str(n) //第n个子表达式匹配的string,m.str(0) //整个stringm[n] //对应第n个子表达式的ssub_match对象m.begin(), m.end() //表示m中sub_match元素范围的迭代器。m.cbegin(), m.cend() //const_iterator
例子
string pattern("[^c]ei"); //查找前一个字符不是c的字符串eipattern = " [[:alpha:]]* " + pattern + "[[:alpha:]]*"; //我们想要包含pattern的单词的全部内容regex r(pattern, regex::icase); //在进行匹配时将忽略大小写for (sregex_iterator it(file.begin(), file.end(), r), end_it; it != end_it; ++it)cout << it->str() << endl; //匹配的单词
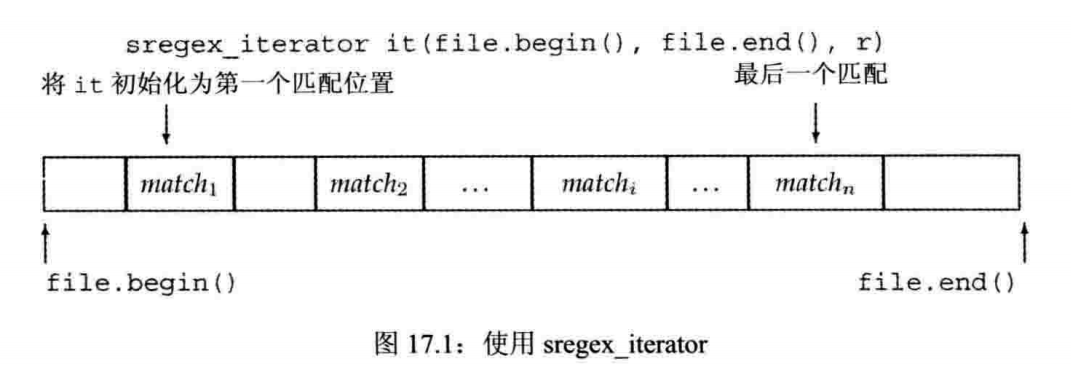
for (sregex_iterator it(file.begin(), file.end(), r), end_it; it != end_it; ++it) {auto pos = it->prefix().length(); //前缀的大小pos = pos > 40 ? pos - 40 : 0; //我们想要最多40个字符cout << it->prefix().str().substr(pos) //前缀的最后一部分<< "\n\t\t>>>" << it->str() << " <<<\n " //匹配的单词<< it->suffix().str().substr(0, 40) //后缀的第一部分<< endl;}
使用子表达式
在正在表达式中用()括号的部分就是子表达式,类似Lua的captures捕获。
//第一个子表达式:([[:alnum:]]+),表示文件名的部分//第二个子表达式:(cpp|cxx|cc),表示文件扩展名regex r("([[:alnum:]]+)\\.(cpp|cxx|cc)$", regex::icase);//匹配*.cpp、*.cxx、*.cc文件。regex r("[[:alnum:]]+\\.(cpp|cxx|cc)$", regex::icase);smatch results;string filename;while (cin >> filename)if(regex_search(filename, results, r))cout << results.str(1)<< endl ; //打印第一个子表达式//如果文件名为foo.cpp,则//results.str(0):foo.cpp//results.str(1):foo//results.str(2):cpp
//匹配美国的电话号码,(333).333.4444// (333)是区号,.号可能是-也可能是空格,也可能没有。//下面就是相应的正则表达式(ECMAScript)//( 333 ) - 333 - 4444"(\\()? (\\d{3}) (\\))? ([-. ])? (\\d{3}) ([-.]?) (\\d{4})";string phone = "(\\()?(\\d{3})(\\))?([-. ])?(\\d{3})([-.]?)(\\d{4})";regex r(phone); //regex对象,用于查找我们的模式smatch m;string s;//从输入文件中读取每条记录while (getline(cin, s)) {//对每个匹配的电话号码for (sregex_iterator it(s.begin(), s.end(), r), end_it; it != end_it; ++it)//检查号码的格式是否合法if (valid(*it)) //valid方法见下面知识点。cout << "valid:" << it->str() << endl;elsecout << "not valid:" << it->str() << endl;}
六、ssub_match
使用子匹配操作。
//注意:这些操作适用于ssub_match、csub_match、wssub_match、wcsub_match。//ssub是一个ssub_match对象。ssub.matched //指出此ssub_match是否匹配到了,可能这部分匹配的内容不存在,那就false。//一个public bool数据成员ssub.first & ssub.second//指向匹配序列首元素和尾后位置的迭代器。//如果未匹配,则first和second是相等的//public数据成员,ssub.length() //匹配的大小。如果matched为false, 则返回0ssub.str() //返回一个包含输入中匹配部分的string。//如果matched为false,则返回空stringstring s = ssub //将ssub_match对象ssub转化为string对象s。//等价于s = ssub.str()。转换运算符不是explicit的
例子
//匹配美国的电话号码,(333).333.4444// (333)是区号,.号可能是-也可能是空格,也可能没有。//下面就是相应的正则表达式(ECMAScript)//( 333 ) - 333 - 4444"(\\()? (\\d{3}) (\\))? ([-. ])? (\\d{3}) ([-.]?) (\\d{4})";bool valid(const smatch& m){if (m[1].matched) //如果区号前有一个左括号//m[3].matched:区号后必须有一个右括号//m[4].matched == 0: 之后紧跟剩余号码//m[4].str() == " ": 之后紧跟一个空格return m[3].matched && (m[4].matched == 0 || m[4].str() == " ");else//!m[3].matched:区号后不能有右括号,区号没有括号//m[4].str() == m[6].str():另两个组成部分间的分隔符必须匹配return !m[3].matched && m[4].str() == m[6].str();}
七、replace方法
正则表达式不仅用在我们希望查找一个给定序列的时候,还用在当我们想将找到的序列替换为另一个序列的时候。例如,我们可能希望将美国的电话号码转换为”ddd.ddd.dddd”的形式,即区号和后面三位数字用一个点分隔。
regex_replace(dest, seq, r, fmt, mft);// 遍历seq,用regex_search查找seq序列中与r匹配的子串。// 使用格式字符串fmt和mft标志来生成输出。// 并将输出写入到迭代器dest指定的位置,并接受一对迭代器seq表示范围。// dest: 写入迭代器// seq: 目标序列,可以是一对迭代器// r: regex类对象,正则表达式// fmt: 格式化字符串,可以是string、C字符串数组指针// mft: match_flag_type标志,默认是match_defaultregex_replace(seq, r, fmt, mft);// 遍历seq,用regex_search查找seq序列中与r匹配的子串。// 使用格式字符串fmt和mft标志来生成输出。// 返回一个string,保存输出// seq: 目标序列,可以是string、C字符串数组指针// r: regex类对象,正则表达式// fmt: 格式化字符串,可以是string、C字符串数组指针// mft: match_flag_type标志,默认是match_default
例子
//使用match中的第2、5、7个子表达式。string fmt = "$2.$5.$7"; //将号码格式改为ddd.ddd.ddddstring phone = "(\\()?(\\d{3})(\\))?([-. ])?(\\d{3})([-.]?)(\\d{4})";regex r(phone);string number = "(908)555-1800";cout << regex_replace(number, r, fmt) << endl; //908.555.1800
例子
我们有一个保存人名及其电话号码的文件:
morgan (201) 555-2368 862-555-0123
drew (973)555.0130
lee (609) 555-0132 2015550175 800 . 555-0000
我们希望将数据转换为下面这样:
morgan 201.555. 2368 862.555.0123
drew 973.555. 0130
lee 609.555.0132 201.555.0175 800.555.0000
int main(){regex r("(\\()?(\\d{3})(\\))?([-. ])?(\\d{3})([-.]?)(\\d{4})");smatch m;string s;string fmt = "$2.$5.$7"; //使用smatch的第2、5、7个子表达式while(getline(cin, s))cout << regex_replace(s, r, fmt) << endl ;return O;}
八、match_flag_type
用来控制匹配和格式的标志。
就像标准库定义标志来指导如何处理正则表达式一样,标准库还定义了用来在替换过程中控制匹配或格式的标志。
这些值都定义在名为regex_constants 的命名空间中。类似用于bind的placeholders。
using std::regex_constants::format_no_copy;//定义在 std::regex_constants::match_flag_type中match_default //等价于format_defaultmatch_not_bol //不将首字符作为行首处理match_not_eol //不将尾字符作为行尾处理match_not_bow //不将首字符作为单词首处理match_not_eow //不将尾字符作为单词尾处理match_any //如果存在多与一个匹配,则可返回任意一个匹配match_not_null //不匹配任何空序列match_continuous //匹配必须从输入的首字符开始match_prev_avail //输入序列包含第一个匹配之前的内容format_default //用 ECMAScript 规则替换字符串format_sed //用 POS IX sed 规则替换字符串format_no_copy //不输出输入序列中未匹配的部分format_first_only //只替换子表达式的第一次出现
默认情况下,regex_replace输出整个输入序列。未与正则表达式匹配的部分会原样输出;匹配的部分按格式字符串指定的格式输出。
//只生成电话号码:使用新的格式宇符串using std::regex_constants::format_no_copy;//在最后一部分号码后放置空格作为分隔符string fmt2 = "$2.$5.$7 ";//通知regex_replace只拷贝它替换的文本cout << regex_replace(s, r, fmt2 , format_no_copy) << endl;//输出如下://201.555.2368 862.555.0123//973.555.0130//609.555.0132 201.555.0175 800.555.0000

若有收获,就点个赞吧
0 人点赞
