训练题:复杂链表拷贝
方法一:递归+哈希
- 时间复杂度:O(n)
- 空间复杂度:O(n) ```cpp
Node copyRandomList(Node head) { if(!head) return head;
unordered_map<Node*, Node*> info;return _copy(info, head);
}
Node _copy(unordered_map<Node, Node>& info, Node node){ if(!node) return nullptr;
Node* copy_node = nullptr;if(info.count(node)) copy_node = info[node];else{copy_node = copyNode(node);info[node] = copy_node;}if(!node->random) copy_node->random = nullptr;else{if(!info.count(node->random)) info[node->random] = copyNode(node->random);copy_node->random = info[node->random];}copy_node->next = _copy(info, node->next);return copy_node;
}
Node copyNode(Node node) { if(!node) return nullptr; return new Node(node->val); }
<a name="5lft7"></a>## 方法二:迭代+哈希- 时间复杂度:O(n)- 空间复杂度:O(n)```cppNode* copyRandomList(Node* head) {if(!head) return head;unordered_map<Node*, Node*> info;Node copyHead(1), *copyHeadPtr = ©Head;for(Node* node = head; node; node = node->next){if(!info.count(node)) info[node] = new Node(node->val);;copyHeadPtr->next = info[node];copyHeadPtr = copyHeadPtr->next;if(!node->random) copyHeadPtr->random = nullptr;else{if(!info.count(node->random)) info[node->random] = new Node(node->random->val);copyHeadPtr->random = info[node->random];}}return copyHead.next;}
方法三
- 时间复杂度:O(n)
- 空间复杂度:O(1) ```cpp
Node copyRandomList(Node head) { if(!head) return head;
Node* node = nullptr, *tmpNode = nullptr;// 第一步,在原链表每个节点后插入拷贝的节点// 原链表:node1->node2->node3// 新链表:node1->copy1->node2->copy2->node3->copy3for(node = head, tmpNode = nullptr; node; node = tmpNode->next){tmpNode = new Node(node->val);tmpNode->next = node->next;node->next = tmpNode;}// 为每个copy node赋值random// 在新链表中,任意node的next就是它的copy nodefor(node = head; node; node = node->next->next){if(node->random) node->next->random = node->random->next;}// 链表:node1->copy1->node2->copy2->node3->copy3// 拆分成两个链表:// 链表1:node1->node2->node3// 链表2:copy1->copy2->copy3Node* ret = head->next;for(node = head, tmpNode = head->next; tmpNode->next;){node->next = tmpNode->next;node = node->next;tmpNode->next = node->next;tmpNode = tmpNode->next;}node->next = nullptr;return ret;
}
<a name="1XsV0"></a># 训练题:删除链表节点题目:[http://t.cn/A6VqjZ1i](http://t.cn/A6VqjZ1i)```cppListNode* deleteNode(ListNode* head, int val) {if( !head ) { return head; }if( head->val == val) { return head->next; }ListNode* tmpHead = head, *tmpPre = nullptr;for( ; tmpHead && tmpHead->val != val; tmpPre = tmpHead, tmpHead = tmpHead->next );if( tmpHead ) tmpPre->next = tmpHead->next;return head;}
训练题:逆序打印链表
方法一:递归
vector<int> reversePrint( ListNode* head ){vector<int> shit;int count = 0;for( ListNode* node = head; node; node = node->next, ++count );shit.reserve( count );return _reverse( head, shit );}vector<int> &_reverse( ListNode* head, vector<int> &container ){if( !head ) { return container; }_reverse( head->next, container );container.push_back( head->val );return container;}
方法二:迭代(栈)
vector<int> reversePrint(ListNode* head) {stack<int> shit;int count = 0;for( count = 0; head; head = head->next, ++count ) { shit.push( head->val ); }vector<int> ret;ret.reserve( count );for( ; !shit.empty(); shit.pop() ) { ret.push_back( shit.top() ); }return ret;}
训练题:合并链表
场景一:合并两个有序链表
方法一:迭代
- 时间复杂度:O(n+m)
- 空间复杂度:O(1) ```cpp
ListNode mergeTwoLists(ListNode l1, ListNode* l2) { if( !l1 ) { return l2; } if( !l2 ) { return l1; }
// newHead是合并后的表头// tail是当前迭代过程中的表尾// tmpNode是l1和l2迭代过程中更小的表头。// 每一次迭代去取更小的表头,该链表表土也相应位移ListNode* newHead = nullptr, *tail = nullptr, *tmpNode = nullptr;while( l1 && l2 ){// 第一步取更小的节点if( l1->val < l2->val ){tmpNode = l1;l1 = l1->next;}else{tmpNode = l2;l2 = l2->next;}// 第二步,拼接到newHead~tail构成的链表的尾部。if( !newHead ){newHead = tail = tmpNode;}else{tail->next = tmpNode;tail = tmpNode;}}if( !l1 ) { tail->next = l2; } // l1比l2短,直接接上剩余的l2部分if( !l2 ) { tail->next = l1; } // 同理return newHead;
}
<a name="rtATP"></a>### 方法二:递归时间复杂度:O(n+m)<br />空间复杂度:O(n+m),递归栈空间<br />既然可以迭代,就可以考虑递归```cpp// 先去l1和l2更小的表头,比如是l1// 则接下来合并l1->next和l2即可,并让l1->next = 新合并的表头即可。ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {if( !l1 ) { return l2; }if( !l2 ) { return l1; }if( l1->val < l2->val ){l1->next = mergeTwoLists( l1->next, l2 );return l1;}else{l2->next = mergeTwoLists( l1, l2->next );return l2;}}
场景二:合并K个链表
方法一:顺序合并
- 时间复杂度:O(k2n)
- 空间复杂度:O(1) ```cpp
ListNode mergeKLists( vector<ListNode> &lists ) { ListNode* head = nullptr; for( auto list : lists ) { head = mergeTwoLists( head, list ); } return head; }
<a name="cQpI8"></a>### 方法二:分治合并(递归)归并排序的分治思想。- 时间复杂度:O(kn x logk)- 空间复杂度:O(log k)```cppListNode* mergeKLists(vector<ListNode*>& lists) {if(lists.empty()) return nullptr;if(lists.size() == 1) return lists[0];return merge(lists, 0, lists.size() - 1);}ListNode* merge(vector<ListNode*>& lists, int left, int right){if(right <= left) return lists[left];int mid = left + ((right - left) >> 1);ListNode* node1 = merge(lists, left, mid);ListNode* node2 = merge(lists, mid+1, right);return mergeTwoLists(node1, node2);}ListNode* mergeTwoLists(ListNode* listNode1, ListNode* listNode2){if(!listNode1) return listNode2;if(!listNode2) return listNode1;if(listNode1->val < listNode2->val){listNode1->next = mergeTwoLists(listNode1->next, listNode2);return listNode1;}listNode2->next = mergeTwoLists(listNode1, listNode2->next);return listNode2;}
方法三:分治合并(迭代)
有递归,就可以再考虑迭代,这里我们可以借助队列queue实现。
ListNode* mergeKLists( vector<ListNode*> &lists ){if( lists.empty() ) { return nullptr; }if( lists.size() == 1 ) { return lists[0]; }queue<ListNode*> q;for( auto shit : lists ) if( shit ) { q.push( shit ); }、// 每次迭代去两个出来合并,在插入队列尾部。for( ListNode* node1 = nullptr, *node2 = nullptr; q.size() > 1 ; ){node1 = q.front();q.pop();node2 = q.front();q.pop();q.push( mergeTwoLists( node1, node2 ) );}if( q.empty() ) { return nullptr; }return q.front();}
方法四:优先队列
struct SHIT{ListNode* node;SHIT() = default;SHIT( ListNode* n ) : node( n ) {}bool operator<( const SHIT &shit1 ) const{return node->val > shit1.node->val;}};ListNode* mergeKLists( vector<ListNode*> &lists ){priority_queue<SHIT> pq;ListNode head;for( auto shit : lists ) if( shit ) { pq.push( shit ); }for( ListNode* tail = &head; !pq.empty(); ){SHIT shit = pq.top();pq.pop();tail->next = shit.node;tail = tail->next;if( shit.node->next ) { pq.push( shit.node->next ); }}return head.next;}
方法五:普通迭代
时间复杂度:O(k2n)
空间复杂度:O(1)
ListNode* mergeKLists( vector<ListNode*> &lists ){if( lists.empty() ) { return nullptr; }if( lists.size() == 1 ) { return lists[0]; }short tmpIdx = -1;ListNode head;ListNode* tail = &head;ListNode* tmpNode = nullptr;for( auto it = lists.begin(); it != lists.end(); ){if( !*it ) { it = lists.erase( it ); }else { ++it; }}while( !lists.empty() ){for( short idx = 0, size = lists.size(); idx < size; ++idx ){if( lists[idx] ){if( !tmpNode || ( tmpNode && lists[idx]->val < tmpNode->val ) ){tmpIdx = idx;tmpNode = lists[tmpIdx];}}}if( !lists[tmpIdx]->next ) { lists.erase( lists.begin() + tmpIdx ); }else { lists[tmpIdx] = lists[tmpIdx]->next; }tail->next = tmpNode;tail = tail->next;tmpNode = nullptr;}return head.next;}
训练题:翻转链表
情形一:整个翻转
方法一:容器逆序
// 方法一:C++ STL容器的逆序// 时间复杂度:O(n)// 空间复杂度:O(n)ListNode* ReverseList( ListNode* pHead ){if( !pHead || !pHead->next ) { return pHead; }vector<ListNode*> vNodes;while( pHead ){vNodes.push_back( pHead );pHead = pHead->next;}// 将容器逆序reverse( vNodes.begin(), vNodes.end() );for( int i = 1; i < vNodes.size(); i++ ){vNodes[i - 1]->next = vNodes[i];}vNodes.back()->next = nullptr;return vNodes[0];}
方法二:栈
// 方法二:栈的特性,先入栈,再弹栈。每次弹栈,插入链表尾部。// 时间复杂度:O(n)// 空间复杂度:O(n)ListNode* ReverseList( ListNode* pHead ){if( !pHead || !pHead->next ) return pHead;stack<ListNode*> stackNodes;while( pHead ){stackNodes.push( pHead );pHead = pHead->next;}pHead = stackNodes.top();ListNode* cur = pHead;stackNodes.pop();while( !stackNodes.empty() ){cur->next = stackNodes.top();cur = cur->next;stackNodes.pop();}cur->next = nullptr;return pHead;}
方法三:递归一
//// 递归方法一:// 设某个递归过程中,链表结构如下: * -> * -> cur -> next -> * -> ...// 递归子过程:// 1、翻转next起始的链表部分。// 2、翻转后,next为表尾,将cur接到next之后// 结果如下:* -> * -> cur <- next <- * <- ...//// 整个递归过程是从后往前进行逆序//// 时间复杂度:O(n)// 空间复杂度:O(n)ListNode* ReverseList( ListNode* pHead ){// 递归终止条件if( !pHead || !pHead->next ) { return pHead; } // 空链表或者只有1个节点。// 递归子过程:翻转head链表,就先翻转head->next链表,然后将head放到翻转后的结尾即可。ListNode* reverseNode = ReverseList_3( next ); // 翻转后:表头reverseNode,表尾next// 将head放到表尾next后面pHead->next->next = pHead;pHead->next = nullptr;return reverseNode;}
方法四:递归二
// 递归方法二:当然就是从前往后进行逆序// 设某个递归过程中,链表结构如下: * <- * <- cur -> next -> * -> ...// 其中cur往左部分为已逆序部分,next之后部分为链表的原始部分// 递归一次之后:* <- * <- cur <- next -> * -> ...// 时间复杂度:O(n)// 空间复杂度:O(n)ListNode* ReverseList( ListNode* pHead ){if( !pHead || !pHead->next ) { return pHead; }ListNode* nextNode = pHead->next;pHead->next = nullptr;// 此时的pHead为首的链表是已逆序链表// 而nextNode则为pHead在原链表中的next节点return _ReverseList( pHead, nextNode ); // 尾递归,性能比普通递归要好一点}// 以curNode为首的链表是已逆序链表// nextNode为curNode在原链表中的next节点// 这里要做的就是把nextNode插入逆序链表中,使得其还是逆序,非常简单,// nextNode->next = curNode即可。则nextNode又是一个逆序链表ListNode* _ReverseList( ListNode* curNode, ListNode* nextNode ){if( !nextNode ) { return curNode; }ListNode* newNextNode = nextNode->next;nextNode->next = curNode;return _ReverseList( nextNode, newNextNode );}
方法五:迭代
// 方法五:其实就是用迭代代替递归过程。// 时间复杂度:O(n)// 空间复杂度:O(1)ListNode* ReverseList( ListNode* pHead ){if( !pHead || !pHead->next ) { return pHead; }// pReverseHead 逆序链表的表头// pHead 当前迭代的节点// tmpNext 下一节点// 把pHead插入到pReverseHead的表头,pHead又是一个逆序链表。// tmpNext保存了下一节点,然后继续下一个迭代。ListNode* pReverseHead = nullptr;ListNode* tmpNext = nullptr;while( pHead ){tmpNext = pHead->next;pHead->next = pReverseHead;pReverseHead = pHead;pHead = tmpNext;}return pReverseHead;}
情形二:k个一组翻转
方法一:栈
ListNode* reverseKGroup( ListNode* head, int k ){// k = 0 / 1时,返回原数组// head为空或者只有1个元素时,返回原数组if( k < 2 || !head || !head->next ) { return head; }ListNode* newHead = nullptr; // 新链表的表头ListNode* tmpNodeStack = nullptr; // 栈遍历的tmpNodeListNode* tail = nullptr; // 新链表的表尾ListNode* oldHead = nullptr; // 在栈中原链表顺序的表头,即栈底元素stack<ListNode*> s; // 栈for( ListNode* tmpNode = head; tmpNode; ){oldHead = tmpNode;while( s.size() < k && tmpNode ) // 每次压栈k个元素{s.push( tmpNode );tmpNode = tmpNode->next;}if( s.size() == k ) // 压满,则全部弹栈,构成newHead为表头,tail为表尾的新链表{while( !s.empty() ){tmpNodeStack = s.top();s.pop();if( !newHead ) { newHead = tmpNodeStack; }if( !tail ) { tail = tmpNodeStack; }else{tail->next = tmpNodeStack;tail = tail->next;}}tail->next = nullptr;}else if(!s.empty()) // 栈中元素不够k个,按原链表顺序。{if( !newHead ) { newHead = head; } // 整个链表的数量都小于K个,链表原样输出else if( oldHead && tail ) { tail->next = oldHead; } // 将栈中的链表部分的头部oldHead接入到新链表表尾tail}}return newHead;}
方法二:递归
ListNode* reverseKGroup( ListNode* head, int k ){// k = 0 / 1时,返回原数组// head为空或者只有1个元素时,返回原数组if( k < 2 || !head || !head->next ) { return head; }ListNode* tail = head;for( int i = 0; i < k ; i++ ){if( !tail ) { return head; }tail = tail->next;}// 链表初始状态// |---------k----------|// head, ..., tail1, tail, ...// 翻转[head, tail)左闭右开区间,返回的表头tail1// |---------k----------|// tail1, ..., head, tail, ...ListNode* newHead = reverse( head, tail );// 在翻转[tail, ...)区间,令head->next等于其表头head->next = reverseKGroup( tail, k );return newHead;}// 翻转链表:head, ..., tail1, tail// 得到结果:tail1, ..., head, tail// 返回tail1ListNode* reverse( ListNode* head, ListNode* tail ){if( head == tail ) { return head; }ListNode* pre = nullptr, *next = nullptr;while( head != tail ){next = head->next;head->next = pre;pre = head;head = next;}return pre;}
训练题:链表环
方法一:快慢指针
- 时间复杂度:O(n)
- 空间复杂度:O(1) ```cpp
bool hasCycle(ListNode *head) { if( !head || !head->next || !head->next->next ) { return false; }
for(ListNode* slow = head, *fast = head; fast && fast->next;){if( slow ) slow = slow->next;fast = fast->next->next;if(slow == fast) return true;}return false;
}
<a name="7yMPm"></a>## 方法二:set集合- 时间复杂度:O(n)- 空间复杂度:O(n)```cpp// 将所有节点记录到集合中,如果有重复,则包含环。bool hasCycle(ListNode *head) {set<ListNode*> s;while(head){if(s.count(head)) return true;s.insert(head);head = head->next;}return false;}
方法三:删除表头
- 时间复杂度:O(n)
- 空间复杂度:O(1) ```cpp
bool hasCycle(ListNode *head) {
// 迭代删除表头head,且令head->next = head// 若没有环,则表会被全部删除// 若有环,则最终会出现head == head->nextfor(ListNode* tmpNode = nullptr; head;){if( head && head == head->next ) { return head; }tmpNode = head->next;head->next = head;head = tmpNode;}return false;
}
<a name="8ssuZ"></a># 训练题:倒数第K节点题目:[http://t.cn/A6VZCfdr](http://t.cn/A6VZCfdr)<a name="xv1Al"></a>## 情形一:找出倒数第K节点<a name="SLaJi"></a>### 方法一:统计链表长度- 时间复杂度:O(n) + O(n-k)- 空间复杂度:O(1)```cppListNode* FindKthToTail(ListNode* pHead, int k) {if( k <= 0 ) { return nullptr; }int count = 0;for(ListNode* tmp = pHead; tmp; tmp = tmp->next, ++count);if(count < k) return nullptr;int n_k = count - k;for(ListNode* tmp = pHead;; n_k--, tmp = tmp->next){if(!n_k) return tmp;}}
方法二:双指针
- 时间复杂度:O(n)
- 空间复杂度:O(1) ```cpp
ListNode FindKthToTail(ListNode pHead, int k) { if( k— <= 0 ) { return nullptr; }
// first和second之间距离相隔K个节点,当first到达链表尾部,second即是倒数第K个节点ListNode* first = pHead, *second = pHead;while( k-- && first ) { first = first->next; }if( !first ) { return nullptr; } // 链表没有K个节点,返回空。while( first->next ){first = first->next;second = second->next;}return second;
}
<a name="1PAiW"></a>## 情形二:删除倒数第K节点<a name="85eAN"></a>### 方法一:统计链表长度原理同上面方法一。<a name="Fpup3"></a>### 方法二:双指针```cppListNode* removeNthFromEnd(ListNode* head, int n) {// first和second之间距离相隔K个节点,当first到达链表尾部,second即是倒数第K个节点// beforeSecond是second之前的节点ListNode* first = head, *second = head, *beforeSecond = nullptr;while( n-- > 1 ) { first = first->next; }while( first->next ){first = first->next;beforeSecond = second;second = second->next;}if( !beforeSecond ) { head = head->next; } // 删除的是表头else { beforeSecond->next = second->next; } // 删除非表头return head;}
训练题:链表环入口
方法一:集合set
- 时间复杂度:O(n)
- 空间复杂度:O(n) ```cpp
ListNode detectCycle(ListNode head) {
set
<a name="fGR4u"></a>## 方法二:删除链表头- 时间复杂度:O(n)- 空间复杂度:O(1)```cppListNode *detectCycle(ListNode *head) {// 迭代删除表头head,且令head->next = head// 若没有环,则表会被全部删除// 若有环,则最终会出现head == head->nextfor( ListNode* tmpNode = nullptr; head; ){if( head && head == head->next ) { return head; }tmpNode = head->next;head->next = head;head = tmpNode;}return nullptr;}
方法三:快慢指针
- 时间复杂度:O(n)
- 空间复杂度:O(1)
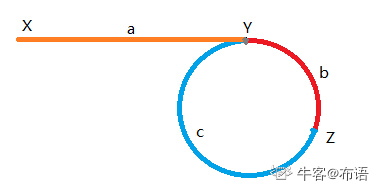

结论:slow指针从Y开始走一圈之内就会被fast指针追上。
证明:设slow指针在Y位置时,fast指针在Z位置,从Z顺时针到Y的距离为c,我们想象fast指针“追赶”slow指针,slow每走一步,之间的距离就会减少1,也就是说slow从Y位置走c步,fast指针就追赶上了slow,显然c<=b+c,得证。
因此n1=0,有a=(b+c)*n2-b。这句话用现实意义表达就是:
设有有两个速度一样的指针(一次移动一个节点)p1、p2,p1从X出发,p2从Z顺时针出发,当p1到达Y时,走过的路程为a,此时p2也到达了Y。(先转n2圈,然后再(逆时针)回退距离b)。
综上,两个速度一样的指针,一个从链表头出发,一个从快慢指针的相遇点出发,最终会在环入口相遇。
ListNode *detectCycle(ListNode *head) {if( !head || !head->next || !head->next->next ) { return nullptr; }// 快慢指针找到环for( ListNode* slow = head, *fast = head; fast && fast->next; ){if( slow ) { slow = slow->next; }fast = fast->next->next;if( slow == fast ) // 有环。{slow = head;for(; slow != fast; slow = slow->next, fast = fast->next);return slow;}}return nullptr;}
训练题:链表公共节点
方法一:set集合
ListNode* FindFirstCommonNode( ListNode* pHead1, ListNode* pHead2 ){if( !pHead1 || !pHead2 ) { return nullptr; }set<ListNode*> dataSet;// 从两个表头同时开始遍历,保存到set中,一旦发现已存在,则表示找到第一公共节点while( pHead1 || pHead2 ){if( pHead1 ){if( dataSet.count( pHead1 ) ) { return pHead1; }dataSet.insert( pHead1 );pHead1 = pHead1->next;}if( pHead2 ){if( dataSet.count( pHead2 ) ) { return pHead2; }dataSet.insert( pHead2 );pHead2 = pHead2->next;}}return nullptr;}
方法二:移动到相同长度位置
struct ListNode* FindFirstCommonNode( struct ListNode* pHead1, struct ListNode* pHead2 ){if( !pHead1 || !pHead2 ) { return nullptr; }// 链表长度const auto len1 = findListLength( pHead1 );const auto len2 = findListLength( pHead2 );// 将长的链表头移动到和短链表头长度一样的地方。if( len1 != len2 ){if( len1 > len2 ) { pHead1 = walkStep( pHead1, len1 - len2 ); }else { pHead2 = walkStep( pHead2, len2 - len1 ); }}// 然后同时移动,这两个表头必定会在公共节点相遇for( ; pHead1; pHead1 = pHead1->next, pHead2 = pHead2->next ){if( pHead1 == pHead2 ) { return pHead1; }}return nullptr;}int findListLength( struct ListNode* pHead1 ){if( !pHead1 ) { return 0; }int sum = 0;while( ( ++sum ) && ( pHead1 = pHead1->next ) );return sum;}struct ListNode* walkStep( struct ListNode* pHead1, int step ){while( step-- ) { pHead1 = pHead1->next; }return pHead1;}
方法三:构造相同长度链表
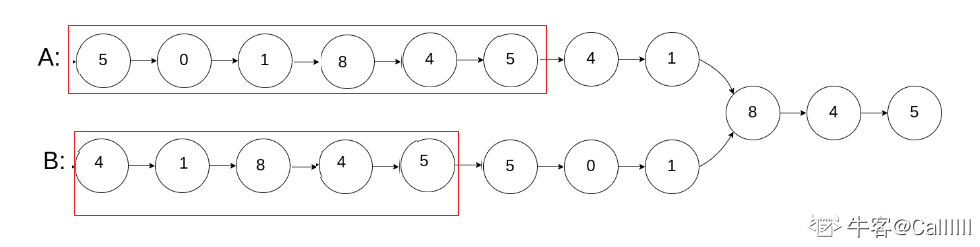
ListNode* FindFirstCommonNode( ListNode* pHead1, ListNode* pHead2) {if( !pHead1 || !pHead2 ) { return nullptr; }ListNode* node1 = pHead2, *node2 = pHead1;while( node1 != node2 ){node1 = node1 ? node1->next : pHead1;node2 = node2 ? node2->next : pHead2;}return node1;}
训练题:链表相加
方法一:栈
数字相加,最好从最低位开始加,因此最好从链表的表尾逆序。我们想到的第一个办法是借助栈来实现链表的逆序
ListNode* addInList( ListNode* head1, ListNode* head2 ){if( !head1 ) { return head2; }if( !head2 ) { return head1; }// 两个栈分别保存,然后不断弹栈依次相加,做到从低位往高位依次相加的顺序。// 我们将结果保存到较长的链表中,如果最后还有一个进位,则用较短链表的一个节点接上。stack<ListNode*> set1, set2;stack<ListNode*> *bigSet = &set1, *smallSet = &set2; // bigSet指向更长链表的栈ListNode* headLong = head1; // 指向更长链表的表头ListNode* backupNode = nullptr; // 指向更短链表的表尾,用于最高相加之后还有1个进位时,需再加一个节点。for( ListNode* node1 = head1; node1; node1 = node1->next ) { set1.push( node1 ); }for( ListNode* node2 = head2; node2; node2 = node2->next ) { set2.push( node2 ); }if( set1.size() < set2.size() ){bigSet = &set2;smallSet = &set1;headLong = head2;backupNode = smallSet->top();}int carry = 0; //进位,1/0// 先根据更短链表进行遍历,然后将结果保存到更长的链表中for( int tmp = 0; !smallSet->empty(); smallSet->pop(), bigSet->pop() ){tmp = bigSet->top()->val + smallSet->top()->val + carry;bigSet->top()->val = tmp % 10;carry = tmp / 10;}// 再遍历更长的链表for( int tmp = 0; !bigSet->empty(); bigSet->pop() ){tmp = bigSet->top()->val + carry;bigSet->top()->val = tmp % 10;carry = tmp / 10;}// 最后还有一个进位,需额外接入一个节点到更长链表的表头。if( carry ){backupNode->val = 1;backupNode->next = headLong;headLong = backupNode;}return headLong;}
方法二:翻转链表
除了借助栈,我们还可以自己先翻转链表,然后再翻转回来。
// 翻转链表ListNode* reverseList( ListNode* head, int &count ){count = 0;ListNode* pre = nullptr;ListNode* next = !head ? head : head->next;while( head ){++count;head->next = pre;pre = head;head = next;if( next ) { next = next->next; }}return pre;}ListNode* addInList( ListNode* head1, ListNode* head2 ){if( !head1 ) { return head2; }if( !head2 ) { return head1; }if( head1 == head2 ) { return nullptr; }ListNode* backupNode = head2; // 同上,一个备份节点,用于最后还有1个进位的情况ListNode* rHeadLong1 = nullptr; // 翻转后的更长链表的表头int count1 = 0, count2 = 0; // 用于判断哪个链表更长int carry = 0; // 进位auto rHeadLong2 = rHeadLong1 = reverseList( head1, count1 ); // 翻转后更长的链表表头auto rHeadShort = reverseList( head2, count2 ); // 翻转后更短的链表表头if( count1 < count2 ){std::swap( rHeadLong2, rHeadShort );rHeadLong1 = rHeadLong2;backupNode = head1;}// 先遍历更短的链表for( int tmp = 0; rHeadShort; rHeadLong2 = rHeadLong2->next, rHeadShort = rHeadShort->next ){tmp = rHeadLong2->val + rHeadShort->val + carry;rHeadLong2->val = tmp % 10;carry = tmp / 10;}// 再遍历更长的链表for( int tmp = 0; rHeadLong2; rHeadLong2 = rHeadLong2->next ){tmp = rHeadLong2->val + carry;rHeadLong2->val = tmp % 10;carry = tmp / 10;}// 遍历完成将更长的链表再翻转rHeadLong1 = reverseList( rHeadLong1, count1 );// 最后还有一个进位的情况if( carry ){backupNode->val = 1;backupNode->next = rHeadLong1;rHeadLong1 = backupNode;}return rHeadLong1;}
训练题:LRU机制
题目:https://leetcode-cn.com/problems/lru-cache/
// 双向链表class DoubleLinkNode{public:DoubleLinkNode() = default;virtual ~DoubleLinkNode() = default;DoubleLinkNode(const int& key, const int& val, DoubleLinkNode* pre = nullptr, DoubleLinkNode* next = nullptr): key(key), val(val), pre(pre), next(next) {}public:int val;int key;DoubleLinkNode* pre;DoubleLinkNode* next;};class LRUCache {public:LRUCache(int capacity): _capacity(max(capacity, 1)), _tail(nullptr){}int get(int key) {if(!dataContainer.count(key)) return -1; // 数据不存在dataUsed(key); // 使用过了,将其放在链表尾部return dataContainer[key]->val;}void put(int key, int value) {if(dataContainer.count(key)) {dataContainer[key]->val = value;dataUsed(key); // 使用过了,将其放在链表尾部}else {if(dataContainer.size() == _capacity) handleOverload(); // 超载,清除链表首元素,也就是最远未使用元素dataContainer[key] = new DoubleLinkNode(key, value); // 创建数据节点dataAdded(key); // 放在链表尾部,这是最近使用过的元素}}private:// 数据超载,清除最远未使用元素,也就是链表首部的元素void handleOverload(){if(!_head.next) return;DoubleLinkNode* nodeToDel = _head.next; // 要删除的元素DoubleLinkNode* next = nodeToDel->next; // 该元素的next元素// 衔接删除节点后的链表_head.next = next;if(next) next->pre = &_head;dataContainer.erase(nodeToDel->key); // 清除数据if(_tail == nodeToDel) _tail = nullptr; // 删除的刚好是尾部元素,即双向链表只有一个元素delete nodeToDel; // 别忘了释放内存}// 添加了数据,应在双向链表尾部添加该元素void dataAdded(const int& key){DoubleLinkNode* tmpNode = dataContainer[key];if(!_tail){_tail = tmpNode;_head.next = _tail;_tail->pre = &_head;_tail->next = nullptr;return;}_tail->next = tmpNode;tmpNode->pre = _tail;tmpNode->next = nullptr;_tail = tmpNode;}// 数据使用过,则将该数据对应的节点放到链表尾部void dataUsed(const int& key){DoubleLinkNode* tmpNode = dataContainer[key];if(tmpNode == _tail) return;DoubleLinkNode* pre = tmpNode->pre;DoubleLinkNode* next = tmpNode->next;pre->next = next;if(next) next->pre = pre;_tail->next = tmpNode;tmpNode->pre = _tail;tmpNode->next = nullptr;_tail = tmpNode;}private:int _capacity; // 数据容量,超过则需要删除最远未使用元素// 双向链表,越往后则表示数据是越近被访问,即首元素为最远未使用元素。DoubleLinkNode _head; // 链表虚拟首部,一直存在,_head->next才是首元素DoubleLinkNode* _tail; // 链表尾部,方便尾部添加// 数据容器std::unordered_map<int, DoubleLinkNode*> dataContainer;};

若有收获,就点个赞吧
0 人点赞
