一、哨兵(sentinel)模式下的脑裂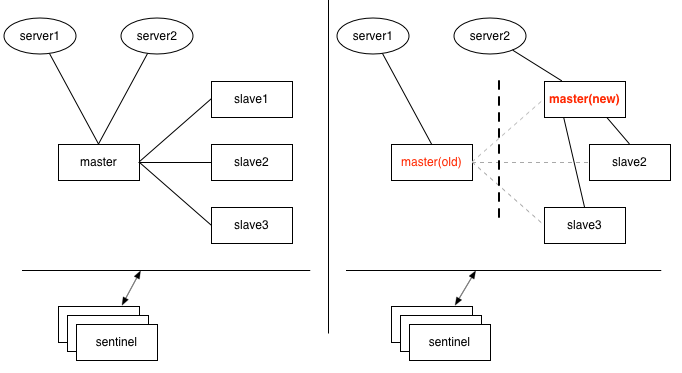
如上图,1个master与3个slave组成的哨兵模式(哨兵独立部署于其它机器),刚开始时,2个应用服务器server1、server2都连接在master上,如果master与slave及哨兵之间的网络发生故障,但是哨兵与slave之间通讯正常,这时3个slave其中1个经过哨兵投票后,提升为新master,如果恰好此时server1仍然连接的是旧的master,而server2连接到了新的master上。
基于setNX指令的分布式锁,可能会拿到相同的锁;基于incr生成的全局唯一id,也可能出现重复。
二、集群(cluster)模式下的脑裂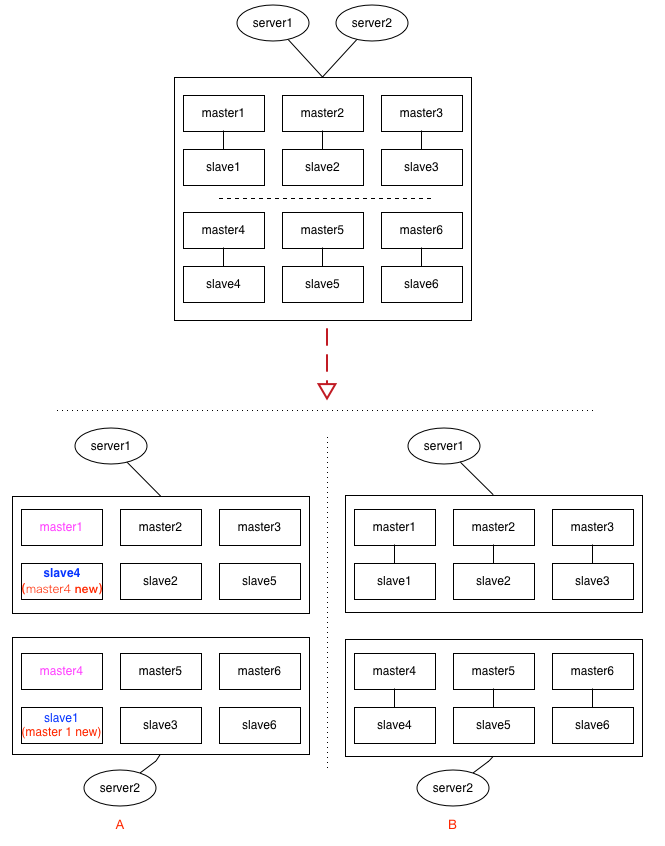
custer模式下,这种情况要更复杂,见上面的示意图,集群中有6组分片,每给分片节点都有1主1从,如果出现网络分区时,各种节点之间的分区组合都有可能,上面列了2种情况:
情况A:
假设master1与slave4落到同1个分区,这时slave4经过选举后,可能会被提升为新的master4,而另一个分区里的slave1,可能会提升为新的master1。看过本博客前面介绍redis cluster的同学应该知道,cluster中key的定位是依赖slot(槽位),情况A经过这一翻折腾后,master1与master4上的slot,出现了重复,在二个分区里都有。类似的,如果依赖incr及setNX的应用场景,都会出现数据不一致的情况。
情况B:
如果每给分片内部的逻辑(即:主从关系)没有乱,只是恰好分成二半,这时slot整体上看并没有出现重复,如果原来请求的key落在其它区,最多只是访问不到,还不致于发生数据不一致的情况。(即:宁可出错,也不要出现数据混乱)
三、主从迁移带来的不一致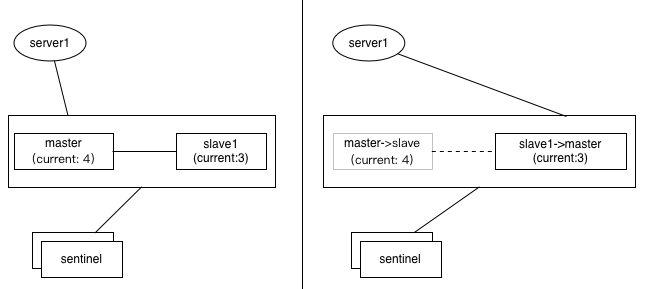
如上图,1主1从,如果采用incr来生成全局唯一键,假如master上的值是4,但是尚未同步到slave上(slave上仍然是旧值3),这时候如果发生选举,slave被提升为新master,应用服务器server1切换到新主后,下次再incr获取的值,就可能重复了(3+1=4)
虽然上面的情况都比较极端,但实际中还是有可能发生的,正如官方文档所言,redis并不能保证强一致性(Redis Cluster is not able to guarantee strong consistency. / In general Redis + Sentinel as a whole are a an eventually consistent system) 对于要求强一致性的应用,更应该倾向于相信RDBMS(传统关系型数据库)。
redis作为高可用的缓存架构,它更倾向于AP(高可用),而非CAP(一致性)。
集群脑裂数据丢失问题
因为Redis没有写数据过半机制,网络分区问题导致脑裂后多个主节点对外提供写服务,一旦网络分区恢复,会将其中一个主节点变为从节点,这时会有大量数据丢失。
规避方法可以在redis配置里加上参数(这种方法不可能百分百避免数据丢失,参考集群leader选举机制):
min-replicas-to-write 1 //写数据成功最少同步的slave数量,这个数量可以模仿大于半数机制配置,//比如集群总共三个节点可以配置1,加上leader就是2,超过了半数
注意:这个配置在一定程度上会影响集群的可用性,比如slave要是少于1个,这个集群就算leader正常也不能提供服务了,需要具体场景权衡选择。
集群是否完整才能对外提供服务
当redis.conf的配置cluster-require-full-coverage为no时,表示当负责一个插槽的主库下线且没有相应的从库进行故障恢复时,集群仍然可用,如果为yes则集群不可用。
Redis集群为什么至少需要三个master节点,并且推荐节点数为奇数?
因为新master的选举需要大于半数的集群master节点同意才能选举成功,如果只有两个master节点,当其中一个挂了,是达不到选举新master的条件的。
奇数个master节点可以在满足选举该条件的基础上节省一个节点,比如三个master节点和四个master节点的集群相比,大家如果都挂了一个master节点都能选举新master节点,如果都挂了两个master节点都没法选举新master节点了,所以奇数的master节点更多的是从节省机器资源角度出发说的。
Redis集群对批量操作命令的支持
对于类似mset,mget这样的多个key的原生批量操作命令,redis集群只支持所有key落在同一slot的情况,如果有多个key一定要用mset命令在redis集群上操作,则可以在key的前面加上{XX},这样参数数据分片hash计算的只会是大括号里的值,这样能确保不同的key能落到同一slot里去,示例如下:
mset {user1}:1:name zhuge {user1}:1:age 18
假设name和age计算的hash slot值不一样,但是这条命令在集群下执行,redis只会用大括号里的 user1 做hash slot计算,所以算出来的slot值肯定相同,最后都能落在同一slot。
哨兵leader选举流程
当一个master服务器被某sentinel视为下线状态后,该sentinel会与其他sentinel协商选出sentinel的leader进行故障转移工作。每个发现master服务器进入下线的sentinel都可以要求其他sentinel选自己为sentinel的leader,选举是先到先得。同时每个sentinel每次选举都会自增配置纪元(选举周期),每个纪元中只会选择一个sentinel的leader。如果所有超过一半的sentinel选举某sentinel作为leader。之后该sentinel进行故障转移操作,从存活的slave中选举出新的master,这个选举过程跟集群的master选举很类似。
哨兵集群只有一个哨兵节点,redis的主从也能正常运行以及选举master,如果master挂了,那唯一的那个哨兵节点就是哨兵leader了,可以正常选举新master。
不过为了高可用一般都推荐至少部署三个哨兵节点。为什么推荐奇数个哨兵节点原理跟集群奇数个master节点类似。

若有收获,就点个赞吧
0 人点赞
