一、消息发送过程
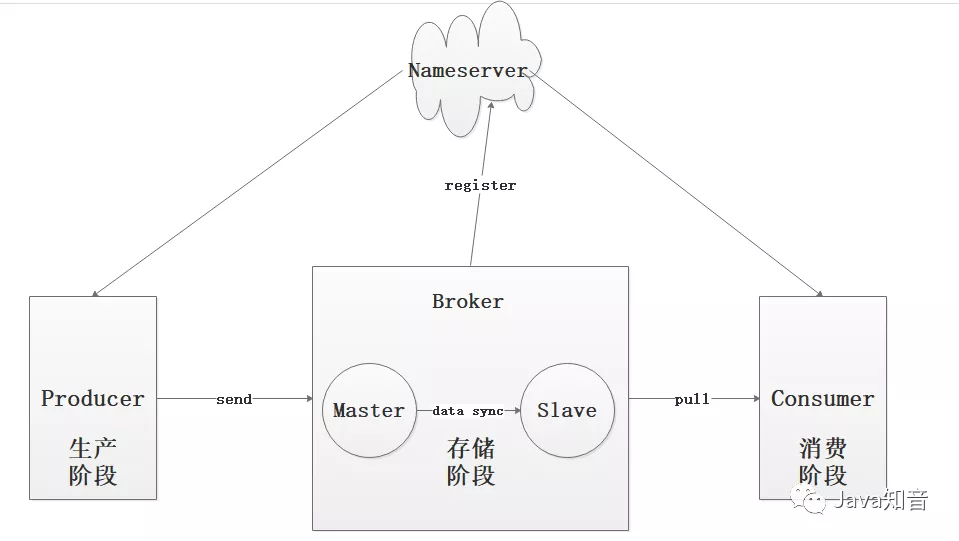
我们将消息流程分为如下三大部分,每一部分都有可能会丢失数据。
- 生产阶段:Producer通过网络将消息发送给Broker,这个发送可能会发生丢失,比如网络延迟不可达等。
- 存储阶段:Broker肯定是先把消息放到内存的,然后根据刷盘策略持久化到硬盘中,刚收到Producer的消息,再内存中了,但是异常宕机了,导致消息丢失。
- 消费阶段:消费失败了其实也是消息丢失的一种变体吧。
二、Producer生产阶段
Producer通过网络将消息发送给Broker,这个发送可能会发生丢失,比如网络延迟不可达等。1、解决方案一
1.1、说明
有三种send方法,同步发送、异步发送、单向发送。我们可以采取同步发送的方式进行发送消息,发消息的时候会同步阻塞等待broker返回的结果,如果没成功,则不会收到SendResult,这种是最可靠的。其次是异步发送,再回调方法里可以得知是否发送成功。单向发送(OneWay)是最不靠谱的一种发送方式,我们无法保证消息真正可达。1.2、源码
```java /**- {@link org.apache.rocketmq.client.producer.DefaultMQProducer} */
// 同步发送 public SendResult send(Message msg) throws MQClientException, RemotingException, MQBrokerException, InterruptedException {}
// 异步发送,sendCallback作为回调 public void send(Message msg,SendCallback sendCallback) throws MQClientException, RemotingException, InterruptedException {}
// 单向发送,不关心发送结果,最不靠谱 public void sendOneway(Message msg) throws MQClientException, RemotingException, InterruptedException {}
<a name="pTOv4"></a>## 2、解决方案二<a name="wTVpS"></a>### 2.1、说明发送消息如果失败或者超时了,则会自动重试。默认是重试三次,可以根据api进行更改,比如改为10次:```javaproducer.setRetryTimesWhenSendFailed(10);
2.2、源码
/*** {@link org.apache.rocketmq.client.producer.DefaultMQProducer#sendDefaultImpl(Message, CommunicationMode, SendCallback, long)}*/// 自动重试次数,this.defaultMQProducer.getRetryTimesWhenSendFailed()默认为2,如果是同步发送,默认重试3次,否则重试1次int timesTotal = communicationMode == CommunicationMode.SYNC ? 1 + this.defaultMQProducer.getRetryTimesWhenSendFailed() : 1;int times = 0;for (; times < timesTotal; times++) {// 选择发送的消息queueMessageQueue mqSelected = this.selectOneMessageQueue(topicPublishInfo, lastBrokerName);if (mqSelected != null) {try {// 真正的发送逻辑,sendKernelImpl。sendResult = this.sendKernelImpl(msg, mq, communicationMode, sendCallback, topicPublishInfo, timeout - costTime);switch (communicationMode) {case ASYNC:return null;case ONEWAY:return null;case SYNC:// 如果发送失败了,则continue,意味着还会再次进入for,继续重试发送if (sendResult.getSendStatus() != SendStatus.SEND_OK) {if (this.defaultMQProducer.isRetryAnotherBrokerWhenNotStoreOK()) {continue;}}// 发送成功的话,将发送结果返回给调用者return sendResult;default:break;}} catch (RemotingException e) {continue;} catch (...) {continue;}}}
说明:
这里只是总结出核心的发送逻辑,并不是全代码。可以看出如下:
- 重试次数同步是
1 + this.defaultMQProducer.getRetryTimesWhenSendFailed(),其他方式默认1次。 this.defaultMQProducer.getRetryTimesWhenSendFailed()默认是2,我们可以手动设置producer.setRetryTimesWhenSendFailed(10);- 调用sendKernelImpl真正的去发送消息
- 如果是sync同步发送,且发送失败了,则continue,意味着还会再次进入for,继续重试发送
- 发送成功的话,将发送结果返回给调用者
- 如果发送异常进入catch了,则continue继续下次重试。
3、解决方案三
3.1、说明
假设Broker宕机了,但是生产环境一般都是多主多从的,所以还会有其他master节点继续提供服务,这也不会影响到我们发送消息,我们消息依然可达。因为比如恰巧发送到broker的时候,broker宕机了,producer收到broker的响应发送失败了,这时候producer会自动重试,这时候宕机的broker就被踢下线了, 所以producer会换一台broker发送消息。4、总结
Producer怎么保证发送阶段消息可达?
失败会自动重试,即使重试N次也不行后,那客户端也会知道消息没成功,这也可以自己补偿等,不会盲目影响到主业务逻辑。再比如即使Broker挂了,那还有其他Broker再提供服务了,高可用,不影响。
总结为几个字就是:同步发送+自动重试机制+多个Master节点三、Broker存储阶段
Broker肯定是先把消息放到内存的,然后根据刷盘策略持久化到硬盘中,刚收到Producer的消息,在内存中了,但是异常宕机了,导致消息丢失。1、解决方案一
MQ持久化消息分为两种:同步刷盘和异步刷盘。默认情况是异步刷盘,Broker收到消息后会先存到cache里然后立马通知Producer说消息我收到且存储成功了,你可以继续你的业务逻辑了,然后Broker起个线程异步的去持久化到磁盘中,但是Broker还没持久化到磁盘就宕机的话,消息就丢失了。同步刷盘的话是收到消息存到cache后并不会通知Producer说消息已经ok了,而是会等到持久化到磁盘中后才会通知Producer说消息完事了。这也保障了消息不会丢失,但是性能不如异步高。看业务场景取舍。
修改刷盘策略为同步刷盘。默认情况下是异步刷盘的,如下配置
对应的Java配置类如下: ```java package org.apache.rocketmq.store.config;## 默认情况为 ASYNC_FLUSH,修改为同步刷盘:SYNC_FLUSH,实际场景看业务,同步刷盘效率肯定不如异步刷盘高。flushDiskType = SYNC_FLUSH
public enum FlushDiskType { // 同步刷盘 SYNC_FLUSH, // 异步刷盘(默认) ASYNC_FLUSH }
异步刷盘默认10s执行一次,源码如下:```java/** {@link org.apache.rocketmq.store.CommitLog#run()}*/while (!this.isStopped()) {try {// 等待10sthis.waitForRunning(10);// 刷盘this.doCommit();} catch (Exception e) {CommitLog.log.warn(this.getServiceName() + " service has exception. ", e);}}
2、解决方案二
集群部署,主从模式,高可用。
即使Broker设置了同步刷盘策略,但是Broker刷完盘后磁盘坏了,这会导致盘上的消息全TM丢了。但是如果即使是1主1从了,但是Master刷完盘后还没来得及同步给Slave就磁盘坏了,不也是GG吗?没错!
所以我们还可以配置不仅是等Master刷完盘就通知Producer,而是等Master和Slave都刷完盘后才去通知Producer说消息ok了。
## 默认为 ASYNC_MASTERbrokerRole=SYNC_MASTER
3、总结
若想很严格的保证Broker存储消息阶段消息不丢失,则需要如下配置,但是性能肯定远差于默认配置。
# master 节点配置flushDiskType = SYNC_FLUSHbrokerRole=SYNC_MASTER# slave 节点配置flushDiskType = SYNC_FLUSHbrokerRole=slave
上面这个配置含义是:
Producer发消息到Broker后,Broker的Master节点先持久化到磁盘中,然后同步数据给Slave节点,Slave节点同步完且落盘完成后才会返回给Producer说消息ok了。
四、Consumer消费阶段
1、解决方案一
消费者会先把消息拉取到本地,然后进行业务逻辑,业务逻辑完成后手动进行ack确认,这时候才会真正的代表消费完成。而不是说pull到本地后消息就算消费完了。举个例子
consumer.registerMessageListener(new MessageListenerConcurrently() {@Overridepublic ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext consumeConcurrentlyContext) {for (MessageExt msg : msgs) {String str = new String(msg.getBody());System.out.println(str);}// ack,只有等上面一系列逻辑都处理完后,到这步CONSUME_SUCCESS才会通知broker说消息消费完成,如果上面发生异常没有走到这步ack,则消息还是未消费状态。而不是像比如redis的blpop,弹出一个数据后数据就从redis里消失了,并没有等我们业务逻辑执行完才弹出。return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}});
2、解决方案二
消息消费失败自动重试。如果消费消息失败了,没有进行ack确认,则会自动重试,重试策略和次数(默认15次)如下配置
/*** Broker可以配置的所有选项*/public class org.apache.rocketmq.store.config.MessageStoreConfig {private String messageDelayLevel = "1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h";}

若有收获,就点个赞吧
0 人点赞
