使用 Docker 安装
可视化检索数据,非必需
$ docker pull kibana:7.4.2
- 使用 docker-compose 创建容器```shellversion: "2"services:DOClever:image: elasticsearch:7.4.2restart: alwayscontainer_name: "elasticsearch"ports:- 9200:9200- 9300:9300environment:- ES_JAVA_OPTS=-Xms64m -Xmx512m # 注意设置占用内存大小,否则可能机器内存不足启动不了- "discovery.type=single-node"kibana:image: kibana:7.4.2restart: alwayscontainer_name: "kibana"ports:- 5601:5601environment:- ELASTICSEARCH_HOSTS=http://elasticsearch:9200
- 启动容器
docker-compose up -d
基本概念
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。为了方便理解,我们将 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比: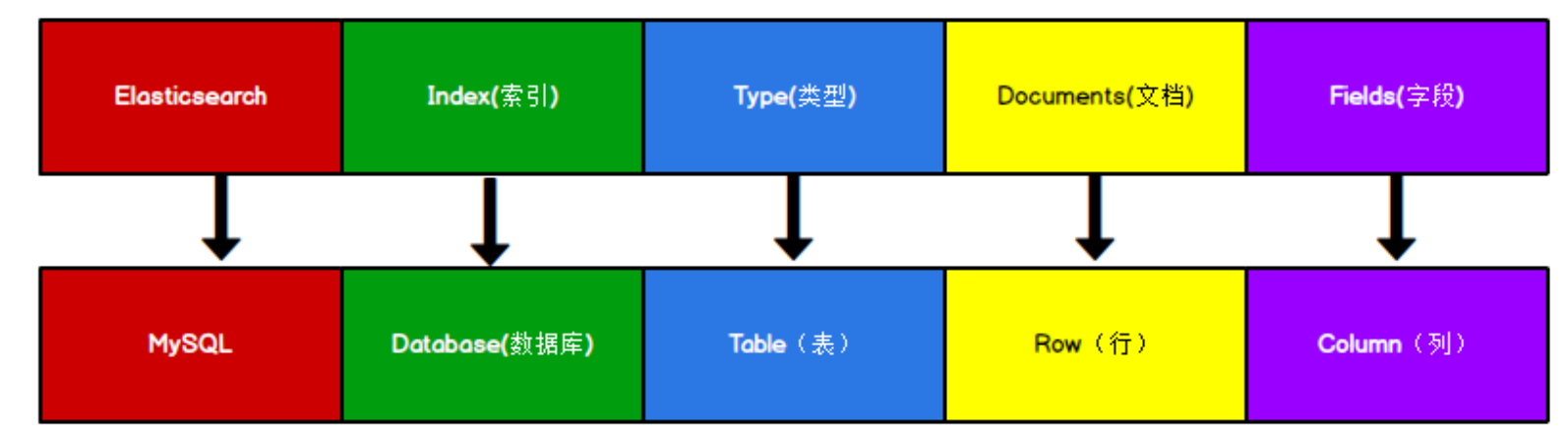
ES 里的 Index 可以看做一个库,而 Types 相当于表,Documents 则相当于表的行。这里 Types 的概念已经被逐渐弱化,Elasticsearch 6.X 中,一个 index 下已经只能包含一个 type,Elasticsearch 7.X 中, Type 的概念已经被删除了。基本操作
查看服务状态与信息
```shell查看所有节点
GET _cat/nodes
查看健康状态
GET _cat/health
查看主节点
GET _cat/master
<a name="j8i6u"></a>### 索引的增删改查```shell# 创建一个名为 product 的索引PUT product# 查看所有索引,?v 的作用是让返回的数据格式更方便查看GET _cat/indices?v# 查看名为 product 的索引GET _cat/indices/product?v或GET product# 删除名为 product 的索引DELETE product
增删改文档
# 不指定 id 的创建方式,自动生成一个随机 idPOST product/_doc{"title": "小米手机","category": "小米","images": "http://www.gulixueyuan.com/xm.jpg","price": 3999}# 指定 id,如果 id 存在则会修改这个数据,版本号加 1POST product/_doc/1{"title": "小米手机","category": "小米","images": "http://www.gulixueyuan.com/xm.jpg","price": 3999}# 只修改指定的字段POST product/_update/1{"doc": {"price": 2000}}# PUT 请求也可以新增或修改数据,但 PUT 必须指定 id,所以一般使用 PUT 修改数据PUT product/_doc/1{"title": "小米手机 new","category": "小米","images": "http://www.gulixueyuan.com/xm.jpg","price": 3999}# 根据 id 删除文档DELETE product/_doc/1# 根据条件删除文档(删除 price 为 2000 的文档)POST product/_delete_by_query{"query": {"match": {"price": 2000}}}
根据 id 查看文档数据
# 根据主键获取文档数据GET product/_doc/1
检索信息 Query DSL 语法
Elasticsearch 提供了一个可以执行查询的 Json 风格的 DSL(domain-specific language 领域特 定语言)。这个被称为 Query DSL。该查询语言非常全面,并且刚开始的时候感觉有点复杂, 真正学好它的方法是从一些基础的示例开始的。
推荐阅读官方文档:https://www.elastic.co/guide/cn/elasticsearch/guide/current/search-in-depth.html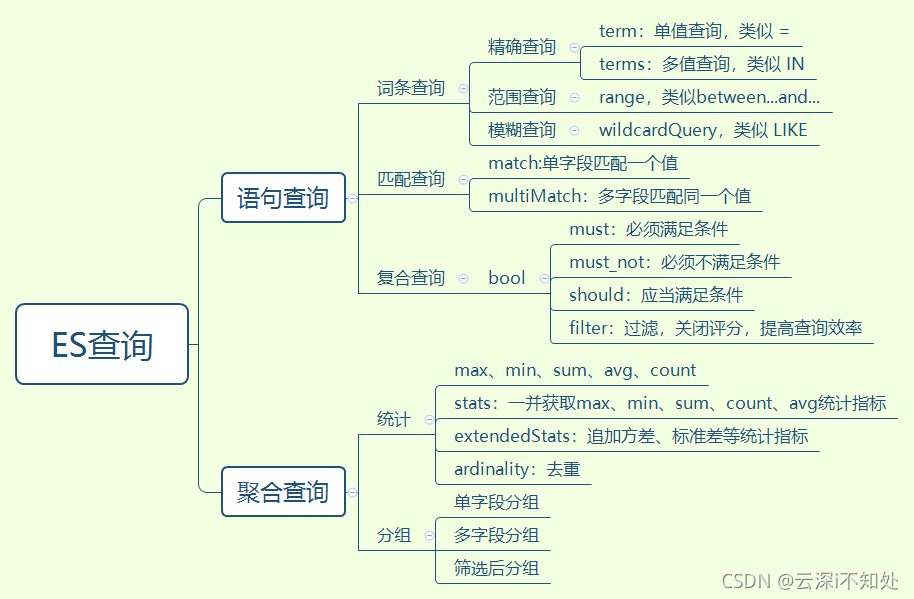
导入测试数据:
https://github.com/elastic/elasticsearch/blob/master/docs/src/test/resources/accounts.json
query查询基本语法
# 检索数据# query 定义如何查询# match_all 查询类型(代表查询所有的所有),es 中可以在 query 中组合非常多的查询类型完成复杂查询# 除了 query 参数之外,我们也可以传递其它的参数以改变查询结果。如 sort、size,可以用 from + size 实现分页# sort 排序,多字段排序,会在前序字段相等时后续字段内部排序,否则以前序为准GET bank/_search{"query": {"match_all": {}}}
返回部分字段
# _source 定义返回部分字段GET bank/_search{"query": {"match_all": {}},"_source": ["balance","firstname"]}
match 匹配查询
## match 匹配查询GET bank/_search{"query": {"match": {"account_number": 20}},"_source": ["balance","firstname","account_number"]}# match 字符串,全文检索,查询出 address 包含 mill 的记录GET bank/_search{"query": {"match": {"address": "mill"}},"_source": ["address","firstname","account_number"]}# 字符串,多个单词(分词+全文检索),查询出 address 包含 mill 和 road 的记录,并给出相关性得分GET bank/_search{"query": {"match": {"address": "mill road"}},"_source": ["address","firstname","account_number"]}
match_phrase 短语匹配,不分词
# 短语匹配,不分词GET bank/_search{"query": {"match_phrase": {"address": "mill road"}},"_source": ["address","firstname","account_number"]}
multi_match 多字段匹配
# multi_match 多字段匹配,查询 state 或者 address 包含 mill 的记录GET bank/_search{"query": {"multi_match": {"query": "mill","fields": ["state","address"]}},"_source": ["address","firstname","state"]}
bool 复合查询
# bool 复合查询# 复合语句可以合并任何其它查询语句,包括复合语句,了解这一点是很重要的# 这就意味着复合语句之间可以互相嵌套,可以表达非常复杂的逻辑# must:必须达到must列举的所有条件# should:应该达到should列举的条件,如果达到会增加相关文档的评分,并不会改变 查询的结果。# 如果 query 中只有 should 且只有一种匹配规则,那么 should 的条件就会被作为默认匹配条而改变查询结果GET bank/_search{"query": {"bool": {"must": [{"match": {"address": "mill"}},{"match": {"gender": "M"}}],"should": [{"match": {"address": "lane"}}],"must_not": [{"match": {"email": "baluba.com"}}]}}}
filter 结果过滤
# 并不是所有的查询都需要产生分数,特别是那些仅用于 “filtering”(过滤)的文档# 为了不计算分数 Elasticsearch 会自动检查场景并且优化查询的执行GET bank/_search{"query": {"bool": {"must": [{"match": {"address": "mill"}}],"filter": {"range": {"balance": {"gte": 10000,"lte": 20000}}}}},"_source": ["balance","address"]}
term
### term 和 match 一样。匹配某个属性的值。全文检索字段用 match,其他非 text 字段匹配用 term,这是一个规范GET bank/_search{"query": {"bool": {"must": [{"term": {"age": {"value": "28"}}}]}}}
aggregations 聚合
### 搜索 address 中包含 mill 的所有人的年龄分布以及平均年龄,但不显示这些人的详情GET bank/_search{"query": {"match": {"address": "mill"}},"aggs": {"group_by_state": {"terms": {"field": "age"}},"avg_age": {"avg": {"field": "age"}}},"size": 0}# 按照年龄聚合,并且请求这些年龄段的这些人的平均薪资GET bank/_search{"query": {"match_all": {}},"aggs": {"ageAgg": {"terms": {"field": "age","size": 1000},"aggs": {"balanceAvg": {"avg": {"field": "balance"}}}}}}# 查出所有年龄分布,并且这些年龄段中 M 的平均薪资和 F 的平均薪资以及这个年龄段的总体平均薪资GET bank/_search{"query": {"match_all": {}},"aggs": {"ageAgg": {"terms": {"field": "age"},"aggs": {"genderAgg": {"terms": {"field": "gender.keyword","size": 5},"aggs": {"balanveAvg": {"avg": {"field": "balance"}}}},"ageBalanceAvg": {"avg": {"field": "balance"}}}}}}
Mapping 字段类型
映射
Mapping 是用来定义一个文档(document),以及它所包含的属性(field)是如何存储和 索引的。比如,使用 mapping 来定义:
- 哪些字符串属性应该被看做全文本属性(full text fields)
- 哪些属性包含数字,日期或者地理位置
- 文档中的所有属性是否都能被索引(_all 配置)
- 日期的格式
-
新版本改变
ES7 及以上移除了 type 的概念。
关系型数据库中两个数据表示是独立的,即使他们里面有相同名称的列也不影响使用,但 ES 中不是这样的。elasticsearch 是基于 Lucene 开发的搜索引擎,而 ES 中不同 type 下名称相同的 filed 最终在 Lucene 中的处理方式是一样的。
两个不同 type 下的两个 user_name,在 ES 同一个索引下其实被认为是同一个 filed,你必须在两个不同的 type 中定义相同的 filed 映射。否则,不同 type 中的相同字段名称就会在处理中出现冲突的情况,导致 Lucene 处理效率下降。
去掉 type 就是为了提高 ES 处理数据的效率。 Elasticsearch 7.x
URL中的type参数为可选。比如,索引一个文档不再要求提供文档类型。
- Elasticsearch 8.x
不再支持URL中的type参数。
- 解决方法:
将索引从多类型迁移到单类型,每种类型文档一个独立索引,将已存在的索引下的类型数据,全部迁移到指定位置即可,详见数据迁移。
Mapping 类型
- type:类型
- String:分为两种,text:可分词;keyword:不可分词,数据会作为完整字段进行匹配
- Numerical:数值类型,分两类,基本数据类型:long、integer、short、byte、double、float、 half_float;浮点数的高精度类型:scaled_float
- Date:日期类型
- Array:数组类型
- Object:对象
- index:是否索引,默认为 true,也就是说你不进行任何配置,所有字段都会被索引。true:字段会被索引,则可以用来进行搜索,false:字段不会被索引,不能用来搜索。
- store:是否将数据进行独立存储,默认为 false,原始的文本会存储在_source 里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source 里面提取出来的。当然也可以独立的存储某个字段,只要设置”store”: true 即可,获取独立存储的字段要比从_source 中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置。
-
Mapping 基本操作
查看索引的 mapping 信息
# 查看 product 索引的 mapping 信息GET product/_mapping
创建 mapping
PUT product{"mappings": {"properties": {"age": {"type": "integer"},"email": {"type": "keyword"},"name": {"type": "text"}}}}
添加新的字段 mapping
# 添加新的字段 mappingPUT product2/_mapping{"properties": {"price": {"type": "integer"}}}
更新 mapping
对于已经存在的 mapping,不能对它进行更新,只能创建新的索引再进行数据迁移。
数据迁移
创建新索引,命名为 product2
# 创建新索引,修改字段类型PUT product2{"mappings": {"properties": {"category": {"type": "text"},"images": {"type": "text"},"price": {"type": "half_float"},"title": {"type": "text"}}}}
进行数据迁移,将 product 的数据迁移到 product2
POST _reindex{"source": {"index":"product"},"dest": {"index": "product2"}}
分词
安装分词器
下载分词器,版本要和 elasticsearch 一样:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.4.2
将下载的文件解压到 plugins,重启容器
$ pwd/usr/share/elasticsearch/plugins$ lselasticsearch-analysis-ik-7.4.2
进行 bin 目录,查看插件是否安装成功 ```shell $ pwd /usr/share/elasticsearch/bin
$ ./elasticsearch-plugin list elasticsearch-analysis-ik-7.4.2
<a name="c6849b04"></a>### 测试分词器```shellGET _analyze{"analyzer": "ik_smart","text": ["尚硅谷电商项目", "苹果手机"]}GET _analyze{"analyzer": "ik_max_word","text": ["尚硅谷电商项目", "苹果手机"]}
自定义词库
- 增加本地词库
/usr/share/elasticsearch/plugins/elasticsearch-analysis-ik-7.4.2/config/ext_dict.dic
尚硅谷电商
- 修改配置文件,加入在 key 为 ext_dict 的 entry 节点内容填上 ext_dict.dic
/usr/share/elasticsearch/plugins/elasticsearch-analysis-ik-7.4.2/config/IKAnalyzer.cfg.xml
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">ext_dict.dic</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords"></entry><!--用户可以在这里配置远程扩展字典 --><!-- <entry key="remote_ext_dict">https://xxx.com/keyword/word.txt</entry>--><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> --></properties>
- 重启容器即可,测试分词: ```shell GET _analyze
{ “analyzer”: “ik_max_word”, “text”: “尚硅谷电商项目” }
响应:```shell{"tokens": [{"token": "尚硅谷","start_offset": 0,"end_offset": 3,"type": "CN_WORD","position": 0},{"token": "电商","start_offset": 3,"end_offset": 5,"type": "CN_WORD","position": 1},{"token": "项目","start_offset": 5,"end_offset": 7,"type": "CN_WORD","position": 2}]}
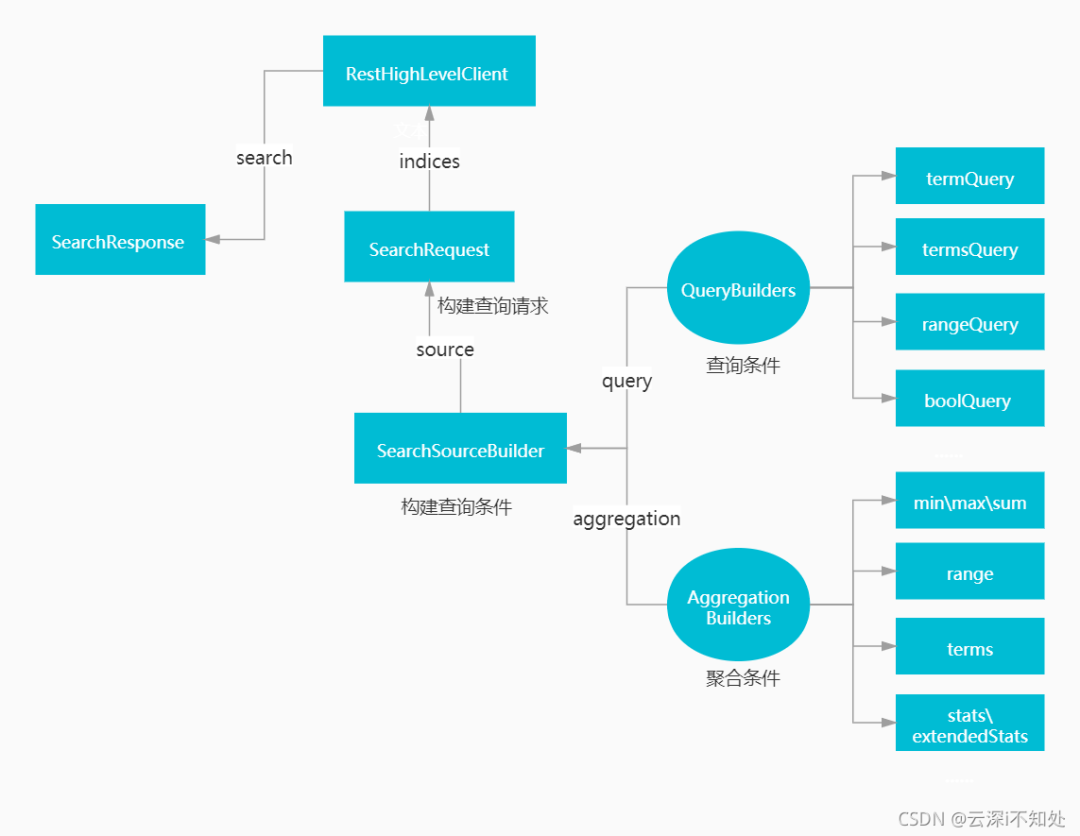
Elasticsearch-Rest-Client
- 9300端口
TCP 协议,适用于 spring data,spring-data-elasticsearch:transport-api.jar,spring boot 版本不同则 transport-api.jar 不同,不能适配 es 版本,
7.x已经不建议使用,8以后就要废弃
- 9200端口
HTTP 协议,可使用多种 http 工具直接发送 http 请求
JestClient:非官方,更新慢
RestTemplate:模拟发HTTP请求,ES 很多操作需要自己封装,比较麻烦
HttpClient:同上
Elasticsearch-Rest-Client:官方 RestClient,封装了 ES 操作,API 层次分明,上手简单
最终选择 Elasticsearch-Rest-Client
文档地址:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high.html
spring boot 整合
- pom.xml 加入依赖,注意版本要与 es 一致
```xml
…
… 7.4.2
…
- 配置客户端 bean> com.atguigu.gulimall.search.config.GulimallElasticSearchConfig```java@Configurationpublic class GulimallElasticSearchConfig {@Beanpublic RestHighLevelClient esRestClient() {return new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));}}
官方文档:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high-search.html
索引的增删查操作
创建索引
public static void testCreateIndex() throws IOException {RestHighLevelClient esClient = createClient();CreateIndexRequest createIndexRequest = new CreateIndexRequest("user");CreateIndexResponse createIndexResponse = esClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);boolean acknowledged = createIndexResponse.isAcknowledged();esClient.close();System.out.println("create index response: " + acknowledged);}
获取索引
public static void testGetIndex() throws IOException {RestHighLevelClient esClient = createClient();GetIndexRequest getIndexRequest = new GetIndexRequest("product");GetIndexResponse getIndexResponse = esClient.indices().get(getIndexRequest, RequestOptions.DEFAULT);esClient.close();System.out.println(getIndexResponse.getAliases());System.out.println(getIndexResponse.getMappings());}
删除索引
public static void testDeleteIndex() throws IOException {RestHighLevelClient esClient = createClient();DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("user");AcknowledgedResponse acknowledgedResponse = esClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);esClient.close();System.out.println("delete index response: " + acknowledgedResponse.isAcknowledged());}
文档的增删改查操作
创建文档 ```java public static void testCreateDoc() throws IOException { RestHighLevelClient esClient = createClient();
IndexRequest indexRequest = new IndexRequest(); indexRequest.index(“user”).id(“1002”);
HashMap
indexRequest.source(JSON.toJSONString(map), XContentType.JSON); IndexResponse response = esClient.index(indexRequest, RequestOptions.DEFAULT); esClient.close();
System.out.println(“create doc result: “ + response.getResult()); }
// 批量插入文档 public static void teatBatchCreateDoc() throws IOException { RestHighLevelClient esClient = createClient();
BulkRequest bulkRequest = new BulkRequest();for (int i = 0; i < 10; i++) {IndexRequest indexRequest = new IndexRequest().index("user").id("100" + i).source(XContentType.JSON, "name", "name:" + i, "password", "password:" + i);bulkRequest.add(indexRequest);}BulkResponse response = esClient.bulk(bulkRequest, RequestOptions.DEFAULT);System.out.println(response.getTook());System.out.println(Arrays.toString(response.getItems()));
}
- 更新文档```javapublic static void testUpdateDoc() throws IOException {RestHighLevelClient esClient = createClient();UpdateRequest updateRequest = new UpdateRequest();updateRequest.index("user").id("1001");updateRequest.doc(XContentType.JSON, "name", "jone nea");UpdateResponse response = esClient.update(updateRequest, RequestOptions.DEFAULT);esClient.close();System.out.println("update doc result: " + response.getGetResult());}
删除文档 ```java public static void testDeleteDoc() throws IOException { RestHighLevelClient esClient = createClient();
DeleteRequest deleteRequest = new DeleteRequest(); deleteRequest.index(“user”).id(“1001”);
DeleteResponse response = esClient.delete(deleteRequest, RequestOptions.DEFAULT); esClient.close();
System.out.println(“delete doc result: “ + response.getResult()); }
// 批量删除文档 public static void testBatchDeleteDoc() throws IOException { RestHighLevelClient esClient = createClient();
BulkRequest bulkRequest = new BulkRequest();for (int i = 0; i < 5; i++) {DeleteRequest deleteRequest = new DeleteRequest();deleteRequest.index("user").id("100" + i);bulkRequest.add(deleteRequest);}BulkResponse response = esClient.bulk(bulkRequest, RequestOptions.DEFAULT);esClient.close();System.out.println(response.getTook());System.out.println(Arrays.toString(response.getItems()));
}
- 根据id获取文档```javapublic static void testGetDoc() throws IOException {RestHighLevelClient esClient = createClient();GetRequest getRequest = new GetRequest();getRequest.index("user").id("1006");GetResponse response = esClient.get(getRequest, RequestOptions.DEFAULT);esClient.close();System.out.println(response.getSource().toString());}
查询索引中的全部数据
public static void testQueryAll() throws IOException {RestHighLevelClient esClient = createClient();SearchRequest request = new SearchRequest();request.indices("user");request.source(new SearchSourceBuilder().query(QueryBuilders.matchAllQuery()));SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);SearchHits hits = response.getHits();esClient.close();System.out.println(hits.getTotalHits());System.out.println(response.getTook());for (SearchHit hit : hits) {System.out.println(hit.getSourceAsString());}}
条件查询 : termQuery
public static void testQueryTerm() throws IOException {RestHighLevelClient esClient = createClient();SearchRequest request = new SearchRequest();request.indices("user");TermQueryBuilder termQuery = QueryBuilders.termQuery("age", "20");SearchSourceBuilder query = new SearchSourceBuilder().query(termQuery);request.source(query);SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);esClient.close();SearchHits hits = response.getHits();System.out.println(hits.getTotalHits());System.out.println(response.getTook());for ( SearchHit hit : hits ) {System.out.println(hit.getSourceAsString());}}
分页查询
public static void testQueryPage() throws IOException {RestHighLevelClient esClient = createClient();SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());// (当前页码 - 1) * 每页显示数据条数builder.from(0);// 每页显示数量builder.size(4);request.source(builder);SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);esClient.close();SearchHits hits = response.getHits();System.out.println(hits.getTotalHits());System.out.println(response.getTook());for ( SearchHit hit : hits ) {System.out.println(hit.getSourceAsString());}}
排序
public static void testQueryOrderBy() throws IOException {RestHighLevelClient esClient = createClient();SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());// 根据 age 反向排序builder.sort("age", SortOrder.DESC);request.source(builder);SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);esClient.close();SearchHits hits = response.getHits();System.out.println(hits.getTotalHits());System.out.println(response.getTook());for ( SearchHit hit : hits ) {System.out.println(hit.getSourceAsString());}}
只查询部分字段
public static void testQuerySource() throws IOException {RestHighLevelClient esClient = createClient();SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());// 声明不需要查询的字段String[] excludes = {"age"};// 声明需要查询的字段String[] includes = {};builder.fetchSource(includes, excludes);request.source(builder);SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);esClient.close();SearchHits hits = response.getHits();System.out.println(hits.getTotalHits());System.out.println(response.getTook());for ( SearchHit hit : hits ) {System.out.println(hit.getSourceAsString());}}
范围查询
public static void testQueryScope() throws IOException {RestHighLevelClient esClient = createClient();SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder();RangeQueryBuilder rangeQuery = QueryBuilders.rangeQuery("age");rangeQuery.gte(18);rangeQuery.lt(28);builder.query(rangeQuery);request.source(builder);SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);SearchHits hits = response.getHits();System.out.println(hits.getTotalHits());System.out.println(response.getTook());for ( SearchHit hit : hits ) {System.out.println(hit.getSourceAsString());}}
模糊查询
public static void testQueryFuzzy() throws IOException {RestHighLevelClient esClient = createClient();SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder();builder.query(QueryBuilders.fuzzyQuery("name", "name:6").fuzziness(Fuzziness.ZERO)); // Fuzziness.ZERO ONE TWO 代表相差n个字符request.source(builder);SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);esClient.close();SearchHits hits = response.getHits();System.out.println(hits.getTotalHits());System.out.println(response.getTook());for ( SearchHit hit : hits ) {System.out.println(hit.getSourceAsString());}}
高亮查询
public static void testHighlightQuery() throws IOException {RestHighLevelClient esClient = createClient();SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder();TermsQueryBuilder termsQueryBuilder = QueryBuilders.termsQuery("name", "name");builder.query(termsQueryBuilder);HighlightBuilder highlightBuilder = new HighlightBuilder();highlightBuilder.preTags("<font color='red'>");highlightBuilder.postTags("</font>");highlightBuilder.field("name");builder.highlighter(highlightBuilder);request.source(builder);SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);esClient.close();SearchHits hits = response.getHits();System.out.println(hits.getTotalHits());System.out.println(response.getTook());for ( SearchHit hit : hits ) {System.out.println(hit.getSourceAsString());// 高亮标签拼接在这里System.out.println(hit.getHighlightFields());}}
聚合查询
public static void testQueryAggregation() throws IOException {RestHighLevelClient esClient = createClient();SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder();// 查询age最大值AggregationBuilder aggregationBuilder = AggregationBuilders.max("maxAge").field("age");// 按照age分组,并返回每组的数量// AggregationBuilder aggregationBuilder = AggregationBuilders.terms("maxGroup").field("age");builder.aggregation(aggregationBuilder);request.source(builder);SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);esClient.close();SearchHits hits = response.getHits();System.out.println(hits.getTotalHits());System.out.println(response.getTook());for ( SearchHit hit : hits ) {System.out.println(hit.getSourceAsString());}}
复杂的查询
/*** 测试查询数据*/@Testpublic void searchData() throws IOException {// 创建查询对象SearchRequest searchRequest = new SearchRequest();// 指定索引searchRequest.indices("bank");// 封装检索条件SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();// 构造检索条件searchSourceBuilder.query(QueryBuilders.matchQuery("address", "mill"));TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg").field("age").size(10);searchSourceBuilder.aggregation(ageAgg);AvgAggregationBuilder balanceAvg = AggregationBuilders.avg("balanceAvg").field("balance");searchSourceBuilder.aggregation(balanceAvg);// 将查询条件传给查询请求对象searchRequest.source(searchSourceBuilder);// 发起查询请求,返回结果SearchResponse searchResponse = client.search(searchRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);// 获取聚集结果Aggregations aggregations = searchResponse.getAggregations();Terms ageAggRes = aggregations.get("ageAgg");for (Terms.Bucket bucket : ageAggRes.getBuckets()) {System.out.println(bucket.getKey() + " : " + bucket.getDocCount());}Avg balanceAvgRes = aggregations.get("balanceAvg");System.out.println("balanceAvg: " + balanceAvgRes.getValue());// 获取 _source 结果SearchHit[] hits = searchResponse.getHits().getHits();for (SearchHit hit : hits) {System.out.println("docId: " + hit.docId());System.out.println("id: " + hit.getId());Map<String, Object> sourceAsMap = hit.getSourceAsMap();System.out.println("firstname: " + sourceAsMap.get("firstname"));System.out.println("lastname: " + sourceAsMap.get("lastname"));System.out.println("---");}}

若有收获,就点个赞吧
0 人点赞
