1. 包含 # 的url是什么?
包含 # 符号的url就是一个 Fragment URL。# 指定了网页中的一个位置。
浏览器就会查询网页中 name 属性值匹配 print 的 <a> 标签。即:<a name="print"></a> ,或者是 id 属性匹配 print 的 <a> 标签。即 <a id="print"></a> 匹配后,浏览器会将该部分滚动到可视区域的顶部。
2. Http请求不包括 #
# 仅仅作用于浏览器,它不会影响服务器端。所以http请求中不会包括 #。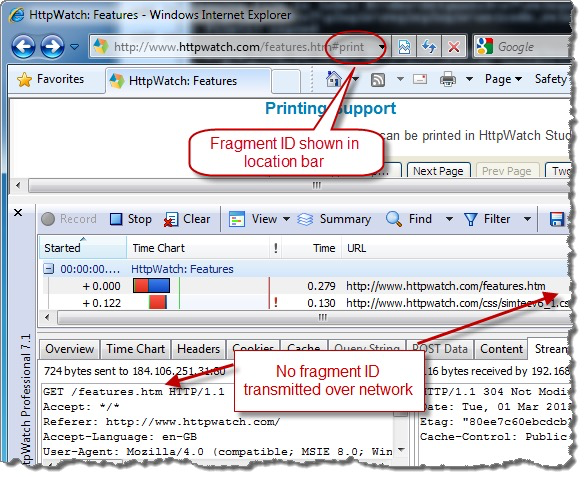
3. # 后面的所有字符,都会被浏览器当做位置标志符
例如,这里有一个网址,试图将color作为查询参数[http://example.com/?color=#ffff&shape=circle](http://example.com/?color=#ffff&shape=circle)
不幸的是,# 后面的内容都不会被发送到服务器,如图所示,color的值为空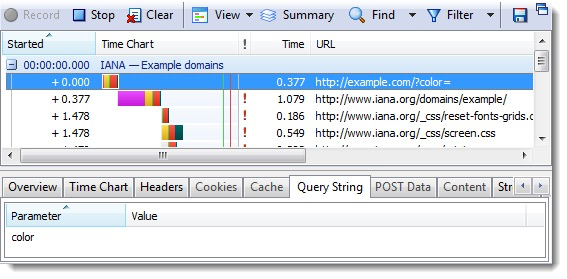
4. 修改#不会导致页面重新加载,但是会改变浏览器的历史记录
如果修改改的URL # 号后面的内容:
从http://www.httpwatch.com/features.htm#filter
改成http://www.httpwatch.com/features.htm#print
浏览器会滚动的网页到新的位置,但不会重新加载页面。 它会在浏览器的历史记录增加一条记录,以便点击返回按钮时回到原来 的位置。
5. javascript可以通过 window.location.hash 来读取或改变 #
6. 谷歌的网络蜘蛛默认会忽略#后面的内容
谷歌网络蜘蛛负责爬取网页的内容,以及网页里面的链接,它们会成为google搜索索引的一部分。网络蜘蛛会抓取并分析HTML,但由于它并不是浏览器程序,也没有javascript引擎,页面上用来加载显示内容的javascript并不会被执行。因此,#后面的字符会被网络蜘蛛忽视,只抓取#前面的内容,举例:
http://www.cnblogs.com/#casperhttp://www.cnblogs.com/#chyingp
这点无论对于开发者,还是搜索引擎都是不利的,前者辛苦创作的内容(应用)少了很多被访问的机会,而后者则失去了进一步丰富其内容索引的机会,特别是在ajax应用越来越多的今天。
7. onhashchange 事件
这是一个HTML 5新增的事件,当#值发生变化时,就会触发这个事件。IE8+、Firefox 3.6+、Chrome 5+、Safari 4.0+支持该事件。
它的使用方法有三种:
window.onhashchange = func;<body onhashchange="func();">window.addEventListener("hashchange", func, false);
参考: https://juejin.cn/post/6844903705809010696 http://blog.httpwatch.com/2011/03/01/6-things-you-should-know-about-fragment-urls/

若有收获,就点个赞吧
0 人点赞
