创建虚拟数据
faker库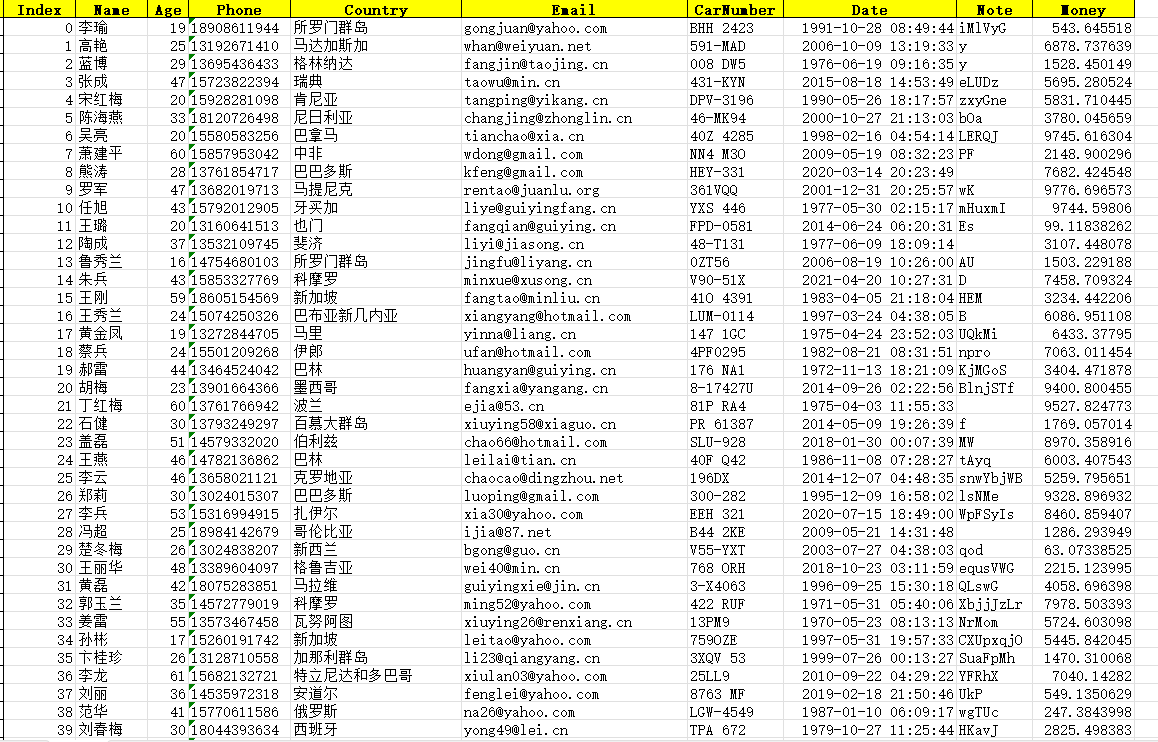
import pandas as pdfrom faker import Fakerimport random as rdfake = Faker("zh-CN")# 要输入到DF中的数据字典dic = {}# 姓名list_name = []# 随机手机号list_phone_number = []# 随机国家list_country = []# 随机邮件list_email = []# 随机车牌号list_car_number = []# 随机年份,格式2022-02-22list_date = []# 随机字符串,长度在min-max之间list_str =[]# 随机年龄list_age = []# 随机金额list_money = []# 索引list_index = []for i in range(0,1000):list_index.append(i)list_name.append(fake.name())list_phone_number.append(fake.phone_number())list_country.append(fake.country())list_email.append(fake.email())list_car_number.append(fake.license_plate())list_date.append(fake.date_time(tzinfo=None, end_datetime=None))list_str.append(fake.pystr(min_chars=0, max_chars=8))list_age.append(rd.randint(15,65))list_money.append(rd.random()*9999)dic['Index'] = list_indexdic['Name'] = list_namedic['Age'] = list_agedic['Phone'] = list_phone_numberdic['Country'] = list_countrydic['Email'] = list_emaildic['CarNumber'] = list_car_numberdic['Date'] = list_datedic['Note'] = list_strdic['Money'] = list_moneydf = pd.DataFrame(dic)print(df.columns)df.to_excel('./TestExcel/AlbertData.xlsx')
创建文件
import pandas as pd# DataFrame-->Worksheet# 初始化数据df = pd.DataFrame({'ID': [1, 2, 3, 4, 5, 6], 'Name': ['Tim', 'Victor', 'Nick', 'Timthony', 'Yangzhongke', 'Zack']})# 设置ID为索引,而不是默认的ID 0 1 2df = df.set_index('ID')print(df.columns)print(df)excelPath = './TestExcel/output.xlsx' # 使用相对路径df.to_excel(excelPath)print('Create excel successfully!')
读取文件
import pandas as pdexcelPath = './TestExcel/output.xlsx' # 使用相对路径outExcel = pd.read_excel(excelPath, index_col='ID')# outExcel = pd.read_excel(excelPath, header=1) # 从第1行开始作为标题# 如果excel里面没有header,但是我们知道如何操作?下面两行# 操作将Name列显示为了SubNameoutExcel = pd.read_excel(excelPath, header=None)outExcel.columns = ['ID', 'SubName']# 将修改好的数据SubName写到新的文件中outExcel.set_index('ID', inplace=True)outExcel.to_excel('./TestExcel/output002.xlsx')print('Done')print(outExcel.shape) # 显示出这个表有几行几列print(outExcel.columns) # 显示出所有列名称print(f'我是文件头两行数据:\n{outExcel.head(2)}') # 查看前2行print(f'我是文件尾三行数据:\n{outExcel.tail(3)}') # 后三行
行,列,单元格
import pandas as pd# dic = {'x': 100, 'y': 200, 'z': 300}# s1 = pd.Series(dic)# 下面这种方式是一样的效果# index是行号 name是列号 [100,200,300]是行内容# s1 = pd.Series([100, 200, 300], index=['x', 'y', 'z'])s1 = pd.Series([1, 2, 3], index=[1, 2, 3], name='A') # 一行数据s2 = pd.Series([10, 20, 30], index=[1, 2, 3], name='B')s3 = pd.Series([100, 200, 300], index=[2, 3, 4], name='C')# 以Dictionary的形式将Series加入到DataFrame中df = pd.DataFrame({s1.name: s1, s2.name: s2, s3.name: s3})# df = df.set_index('A')# 假如Series index是[2,3,4] 没有的则会填充NaNprint(df.head())
数据区域的读取,填充数字,文字序列
import pandas as pdfrom datetime import date, timedelta# 实现月份累加算法,d是初始时间,md是累加的月份def add_month(d, md):yd = md // 12m = d.month + md % 12if m != 12:yd += m // 12m = m % 12return date(d.year + yd, m, d.day)# 跳过空行16行,选取E:H列 指定ID列的数据类型为int(先转为string类型,直接转int类型不行)books = pd.read_excel('./TestExcel/output004.xlsx', skiprows=16, usecols="E:H",dtype={'ID': str, 'InStore': str, 'Date': str})startTime = date(2021, 12, 25)for i in books.index:books['ID'].at[i] = i + 1print(type(books['ID'])) # 此种写法books['ID']是pandas.core.series.Series对象books['InStore'].at[i] = 'Yes' if i % 2 == 0 else 'NO' # 在Python中if else可以组成表达式用# books['Date'].at[i] = startTime + timedelta(days=i) # 天数依次累加# books['Date'].at[i] = date(startTime.year+i,startTime.month,startTime.day) # 年份依次累加books['Date'].at[i] = add_month(startTime, i) # 月份依次累加# print(books['ID'])books.to_excel('./TestExcel/output004Test.xlsx')print(books)
填充日期序列
import pandas as pdfrom datetime import date, timedelta# 实现月份累加算法,d是初始时间,md是累加的月份def add_month(d, md):yd = md // 12m = d.month + md % 12if m != 12:yd += m // 12m = m % 12return date(d.year + yd, m, d.day)# 跳过空行16行,选取E:H列 指定ID列的数据类型为int(先转为string类型,直接转int类型不行)books = pd.read_excel('./TestExcel/output004.xlsx', skiprows=16, usecols="E:H",dtype={'ID': str, 'InStore': str, 'Date': str})startTime = date(2021, 12, 25)for i in books.index:books['ID'].at[i] = i + 1print(type(books['ID'])) # 此种写法books['ID']是pandas.core.series.Series对象books['InStore'].at[i] = 'Yes' if i % 2 == 0 else 'NO' # 在Python中if else可以组成表达式用# books['Date'].at[i] = startTime + timedelta(days=i) # 天数依次累加# books['Date'].at[i] = date(startTime.year+i,startTime.month,startTime.day) # 年份依次累加books['Date'].at[i] = add_month(startTime, i) # 月份依次累加# print(books['ID'])books.to_excel('./TestExcel/output004Test.xlsx')print(books)
函数填充,计算列
import pandas as pddef add_2(x):return x + 2books = pd.read_excel('./TestExcel/output005.xlsx', dtype={'ID': str, 'Name': str},index_col='ID')for i in books.index:books['FirstPrice'].at[i] = 20 + i;books['LastPrice'].at[i] = 30 + i;# 列计算无需取出每行,直接列运算即可books['FinalPrice'] = books['FirstPrice'] * books['LastPrice']# 自己列加2块钱books['FinalPrice'] += 2# 另一种方式追加2块钱,函数books['FinalPrice'] = books['FinalPrice'].apply(add_2)# 另一种方式追加2块钱,lambda表达式books['FinalPrice'] = books['FinalPrice'].apply(lambda x: x + 2)print(books)books.to_excel('./TestExcel/output005.xlsx')
排序
import pandas as pdbooks = pd.read_excel('./TestExcel/output006.xlsx', dtype={'ID': str, 'Name': str}, index_col='ID')# inplace=True是为了不生产新的DF# 按照价格排序 ascending默认为True升序排列# books.sort_values(by='FinalPrice', inplace=True, ascending=False)# 先按照Worthly排序,再按照FinalPrice排序books.sort_values(by=['Worthly', 'FinalPrice'], inplace=True, ascending=[True,False])print(books)
数据筛选、过滤
import pandas as pddef lastPrice_32_to_42(a):return a >= 32 and a < 42def finalPrice_657_to_2000(a):return 657 <= a < 2000books = pd.read_excel('./TestExcel/output007.xlsx', index_col='ID')# 这边loc定位到某列,按照apply里面的函数关系来进行筛选# books = books.loc[books['LastPrice'].apply(lastPrice_32_to_42)].loc[books['FinalPrice'].apply(finalPrice_657_to_2000)]# 可以直接.列名来修改books = books.loc[books.LastPrice.apply(lastPrice_32_to_42)].loc[books.FinalPrice.apply(finalPrice_657_to_2000)]books.sort_values(by=['Worthly', 'FinalPrice'], inplace=True, ascending=[True, False])print(books)
柱状图
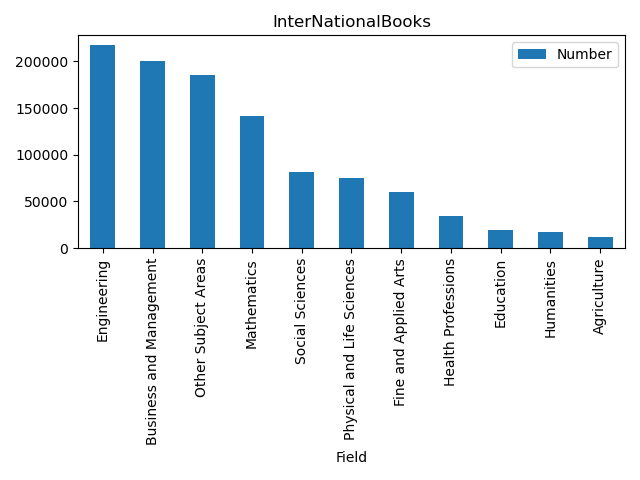
import pandas as pdimport matplotlib.pyplot as plt# 绘图,不要添加index_col='Field'索引列books = pd.read_excel('./TestExcel/output008.xlsx')print(books.head(5))# 按照Number列排序 降序 替换原先的DFbooks.sort_values(by='Number', ascending=False, inplace=True)# 使用pandas绘图:横坐标为Field 纵坐标为Number 颜色橘色 标题xxx# books.plot.bar(x='Field', y='Number',color='orange',title='InterNationalBooks')# 使用plt绘图plt.bar(books.Field, books.Number, color='orange')# 旋转标签90plt.xticks(books.Field, rotation=90)plt.xlabel('Field')plt.ylabel('Number')plt.title('InternationalBooks', fontsize=16)# 紧凑型绘图,能够将横坐标全部显示出来plt.tight_layout()plt.show()
分组柱图,深度优化
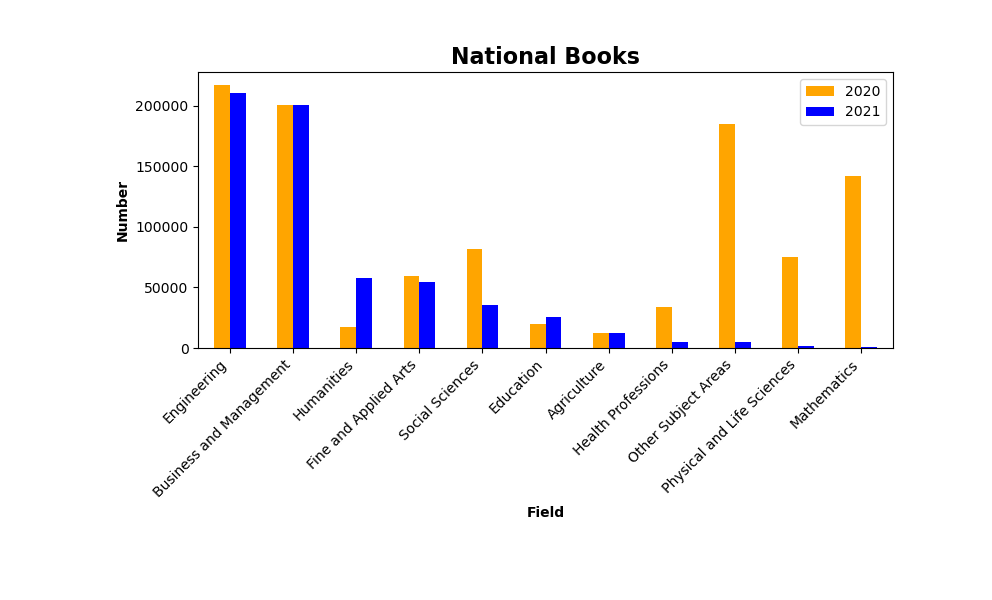
import pandas as pdimport matplotlib.pyplot as pltbooks = pd.read_excel('./TestExcel/output009.xlsx')print(books)books.sort_values(by=2021, inplace=True, ascending=False)books.plot.bar(x='Field', y=[2020, 2021],color=['orange','blue'])plt.title('National Books', fontsize=16, fontweight='bold')plt.xlabel('Field', fontweight='bold')plt.ylabel('Number', fontweight='bold')# 自定义X轴样式:斜45° 文字最末端对齐ax = plt.gca()ax.set_xticklabels(books.Field, rotation=45, ha='right')# 将图片左边和底部固定figures = plt.gcf()figures.subplots_adjust(left=0.2,bottom=0.42)# plt.tight_layout()plt.show()
叠加柱状图,水平柱状图
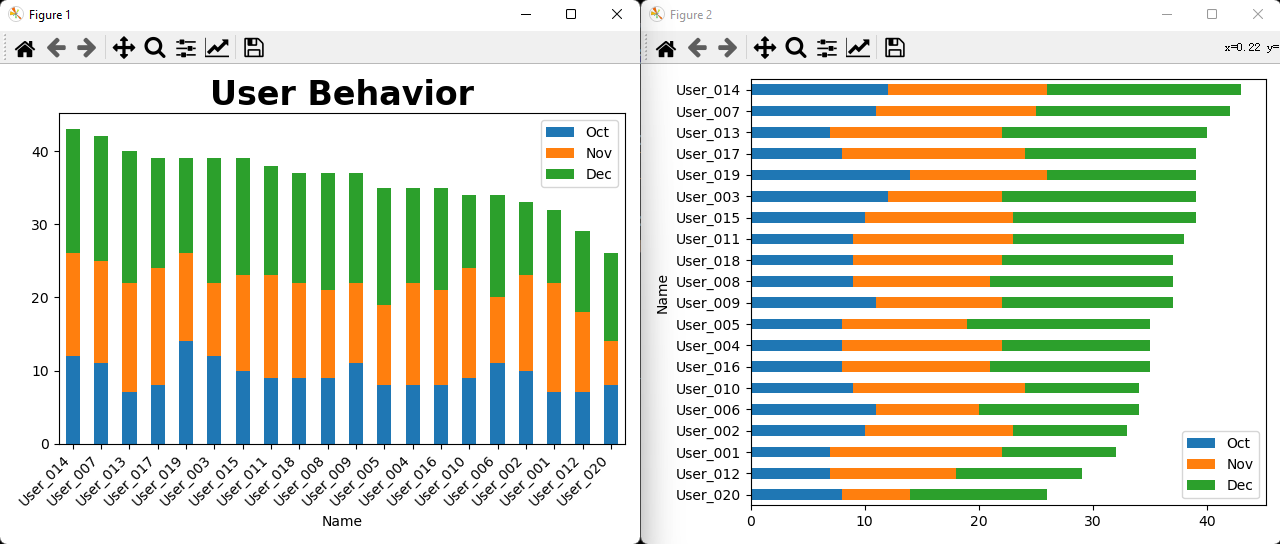
import pandas as pdimport matplotlib.pyplot as pltusers = pd.read_excel('./TestExcel/output010.xlsx')users['Total'] = users.Oct+users.Nov+users.Decusers.sort_values(by='Total',ascending=False,inplace=True)print(users)# 分组柱状图-->叠加柱状图stackedusers.plot.bar(x='Name',y=['Oct','Nov','Dec'],stacked=True)plt.title('User Behavior',fontsize=24,fontweight='bold')# 旋转X轴文字45°ax = plt.gca()ax.set_xticklabels(users.Name,rotation=45,ha='right')plt.tight_layout()# 水平柱状图users.sort_values(by='Total',ascending=True,inplace=True)users.plot.barh(x='Name',y=['Oct','Nov','Dec'],stacked=True)plt.tight_layout()plt.show()
饼图
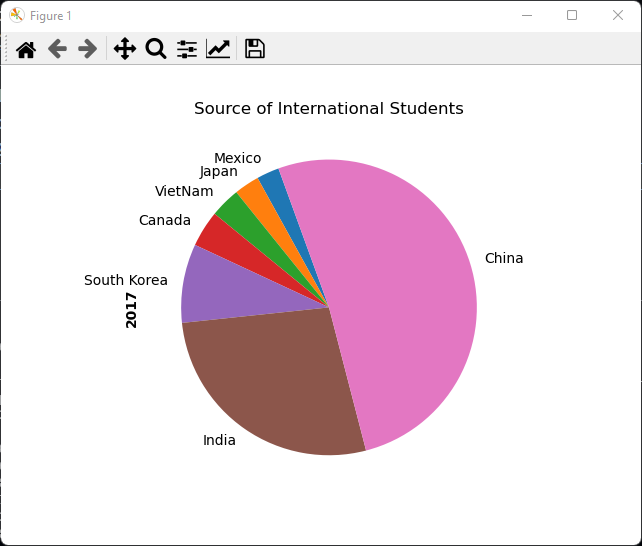
import pandas as pdimport matplotlib.pyplot as pltstudents = pd.read_excel('./TestExcel/output011.xlsx',index_col='From')print(students)# 绘制饼图,默认情况下以index_col作为图例显示饼图# 排序以顺时针形式呈现,并将开始位置设置为-250# students['2017'].sort_values().plot.pie(startangle=-250)# 第二种方式counterclock=False顺时针方式呈现students['2017'].plot.pie(counterclock=False)plt.title('Source of International Students')plt.ylabel('2017',fontweight='bold')plt.show()
折线趋势图,叠加区域图
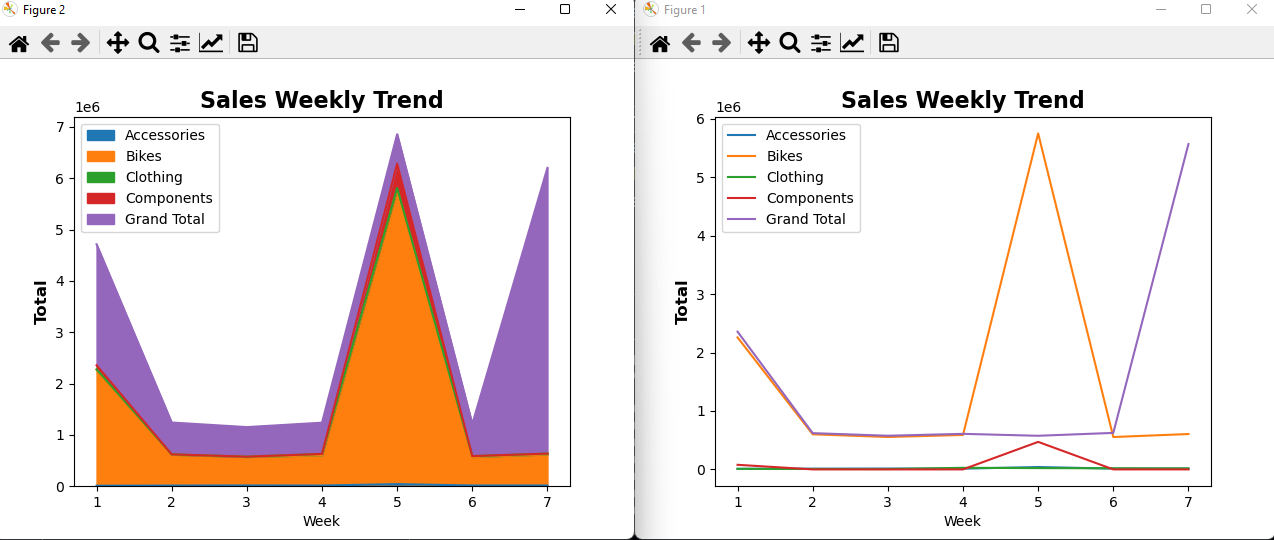
import pandas as pdimport matplotlib.pyplot as pltweeks = pd.read_excel('./TestExcel/output012.xlsx',index_col='Week')print(weeks)print(weeks.columns)# 折线图weeks.plot(y=['Accessories', 'Bikes', 'Clothing', 'Components', 'Grand Total'])plt.title('Sales Weekly Trend',fontsize=16,fontweight='bold')plt.ylabel('Total',fontsize=12,fontweight='bold')plt.xticks(weeks.index)# 叠加区域图weeks.plot.area(y=['Accessories', 'Bikes', 'Clothing', 'Components', 'Grand Total'])plt.title('Sales Weekly Trend',fontsize=16,fontweight='bold')plt.ylabel('Total',fontsize=12,fontweight='bold')plt.xticks(weeks.index)plt.show()
散点图、直方图、密度图、数据相关性
import pandas as pdimport matplotlib.pyplot as plt# 显示所有列pd.options.display.max_columns =777homes = pd.read_excel('./TestExcel/output013.xlsx')# print(homes.head())# 散点图scatter#homes.plot.scatter(x='sqft_living',y='price')# 直方图hist 分布区间bins# homes.sqft_living.plot.hist(bins=100)# plt.xticks(range(0,max(homes.sqft_living),5000),fontsize=8,rotation=90)# 密度图kdehomes.sqft_living.plot.kde()plt.xticks(range(0,max(homes.sqft_living),5000),fontsize=8,rotation=90)plt.show()# 数据相关性分析 column row relationprint(homes.corr())
多表联合(从VLOOKUP到JOIN)
连接了两张表,一张学生姓名表,一张分数表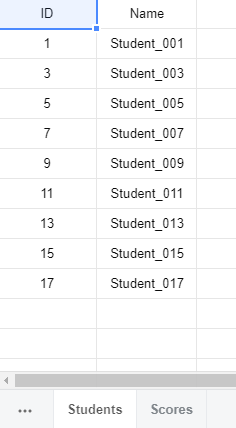

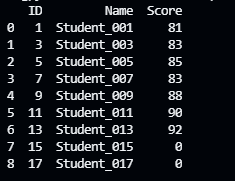
from typing import SupportsRoundimport pandas as pdstudents = pd.read_excel('./TestExcel/output014.xlsx',sheet_name='Students',index_col='ID')scores = pd.read_excel('./TestExcel/output014.xlsx',sheet_name='Scores',index_col='ID')# students表join scores表 how表示不论是否能查询到数据始终保持students表的数据 以ID列来join# fillna 用0来填充空值# 如果左右两边ID列名字不一样 left_on right_on# table = students.merge(scores,how='left',left_on=students.index, right_on=scores.index).fillna(0)table = students.join(scores,how='left').fillna(0)# 将浮点数转为原始的int数据table.Score = table.Score.astype(int)print(table)
数据校验、轴的概念
import pandas as pddef validate_score(x):"""[校验函数]Args:x ([object]): [学生信息]"""try:assert 0<=x.Score<=100except:print(f'#{x.ID}\tStudent {x.Name} has an invalid score {x.Score}')#第二种写法#if not 0<=x.Score<=100:#print(f'#{x.ID}\tStudent {x.Name} has an invalid score {x.Score}')students = pd.read_excel('./TestExcel/output015.xlsx')# axis默认为0,从上到下 1,从左到右进行校验students.apply(validate_score,axis=1)# print(students)
把一列数据分割成两列
import pandas as pdStudents = pd.read_excel('./TestExcel/output015.xlsx')# 一列数据分割成两列expand=True n=0切出来多少子字符串就保留多少df = Students.Name.str.split('_',expand=True)Students['StudentTitle'] = df[0].str.upper()Students['StudentIndex'] = df[1]print(Students)
求和、求平均、统计引导

import pandas as pdhouse_price = pd.read_excel('./TestExcel/output013.xlsx')# DataFrame.sum()# axis 1横轴 0纵轴 sum求和 mean求平均temp_total = house_price[['bedrooms','bathrooms']].sum(axis=1)temp_average = house_price[['bedrooms','bathrooms']].mean(axis=1)house_price['TotalRooms'] = temp_totalhouse_price['AverageRooms'] = temp_average# house_price['AverageRooms'] .astype(int)# 追加列方向的累加col_sum = house_price[['ID','price','bedrooms','bathrooms','sqft_living','sqft_basement']].sum()col_sum['TotalRooms'] = 'Summary'# 将自动按照col_sum的列名来进行追加house_price = house_price.append(col_sum,ignore_index=True)print(house_price)
定位、消除重复数据
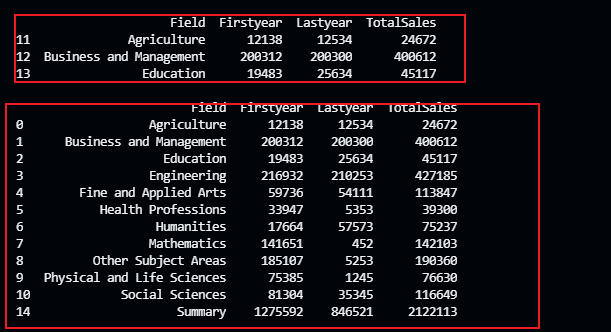
from os import dupimport pandas as pdstudents = pd.read_excel('./TestExcel/output009.xlsx')row_sum = students[['Firstyear','Lastyear']].sum(axis=1)students['TotalSales'] = row_sumcol_sum = students[['Firstyear','Lastyear','TotalSales']].sum()col_sum['Field'] = 'Summary'students = students.append(col_sum,ignore_index=True)print(students)print('\n')# 取出那些重复的数据dupe = students.duplicated(subset='Field')print(dupe.any())print(dupe.count())print(dupe[dupe]) #自己和True比较dupe = dupe[dupe==True]print(f'{dupe.index}\n')print(f'{students.iloc[dupe.index]}\n') #取出那些数据# 消除重复数据,基于哪些列 subset=['Field',Firstyear'] keep='first'/'last'保留开始还是后面的students.drop_duplicates(subset='Field',inplace=True,keep='first')print(students)
旋转数据表(行转换)
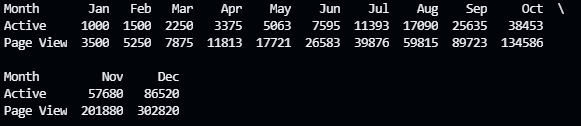
import pandas as pd# 显示最大列pd.options.display.max_columns = 999videos = pd.read_excel('./TestExcel/output016.xlsx',index_col='Month')# 旋转表格,要将index_col设置为旋转坐标列Month,不然就会以默认index来作为列名videos = videos.transpose()print(videos)
读取CVS、TSV、TXT文件中的数据
import pandas as pdstudents1 = pd.read_csv('./TestOtherFiles/Students.csv')print(students1)students2 = pd.read_csv('./TestOtherFiles/Students.txt',sep='|')print(students2)
透视表、分组、聚合(GroupBy)
import pandas as pdimport numpy as nppd.options.display.max_columns = 777orders = pd.read_excel('./TestExcel/output017.xlsx')orders['Year'] = pd.DatetimeIndex(orders.Date).yearprint(orders)piovot_table1=orders.pivot_table(index='Category',columns='Year',values='Total',aggfunc=np.sum)print(piovot_table1)groups = orders.groupby(['Category','Year'])s = groups['Total'].sum()c = groups['ID'].count()piovot_table2 = pd.DataFrame({'Sum':s,'Count':c})print(piovot_table2)
线性回归、数据预测
数据分析和机器学习的边界
import pandas as pdimport matplotlib.pyplot as pltfrom scipy.stats import linregressdef validate_revenue(series):if not 5<series.Revenue<20:print(f'{series}值不在范围内')sales = pd.read_excel('./TestExcel/output018.xlsx',dtype={'Month':str})# 斜率,截距slope,intercept,r,p,std_err = linregress(sales.index,sales.Revenue)# 线性回归方程exp = sales.index*slope+intercept# sales.plot.area(y='Revenue')# 散点图plt.scatter(x=sales.index,y=sales['Revenue'],color='orange')plt.plot(sales.index,exp,color='blue')#plt.bar(sales.index,sales.Revenue)ax = plt.gca()ax.set_xticklabels(sales['Month'],rotation=45,ha='right')plt.title(f'y={slope}*X+{intercept}')plt.tight_layout()plt.show()# 横向验证,传入函数的是series#sales.apply(validate_revenue,axis=1)#print(sales.Month.dtype)
条件格式化
anacoda input: jupyter notebook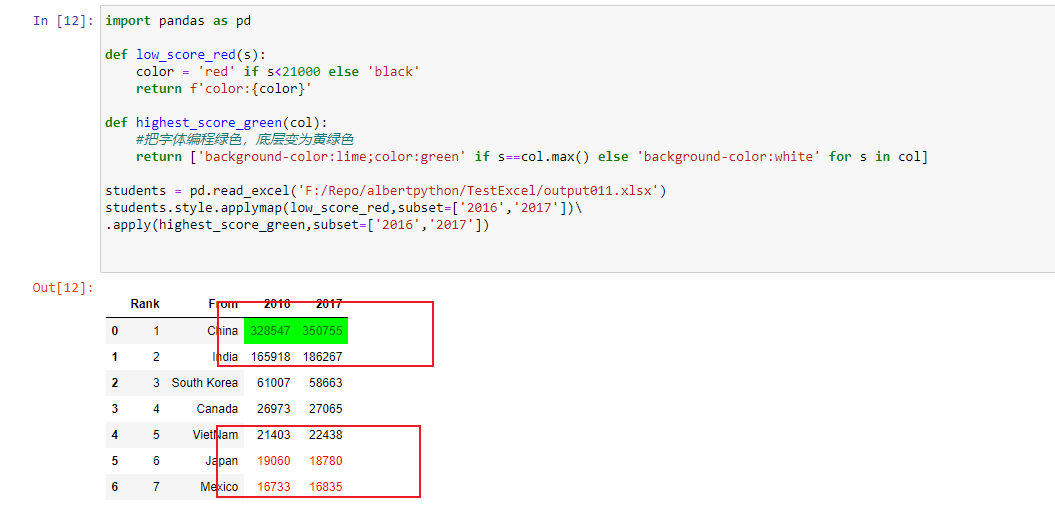
import pandas as pddef low_score_red(s):color = 'red' if s<21000 else 'black'return f'color:{color}'def highest_score_green(col):#把字体编程绿色,底层变为黄绿色return ['background-color:lime;color:green' if s==col.max() else 'background-color:white' for s in col]students = pd.read_excel('F:/Repo/albertpython/TestExcel/output011.xlsx')students.style.applymap(low_score_red,subset=['2016','2017'])\.apply(highest_score_green,subset=['2016','2017'])
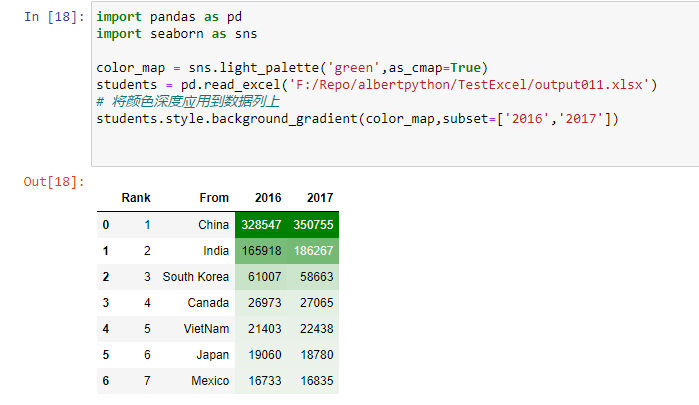
import pandas as pdimport seaborn as snscolor_map = sns.light_palette('green',as_cmap=True)students = pd.read_excel('F:/Repo/albertpython/TestExcel/output011.xlsx')# 将颜色深度应用到数据列上students.style.background_gradient(color_map,subset=['2016','2017'])
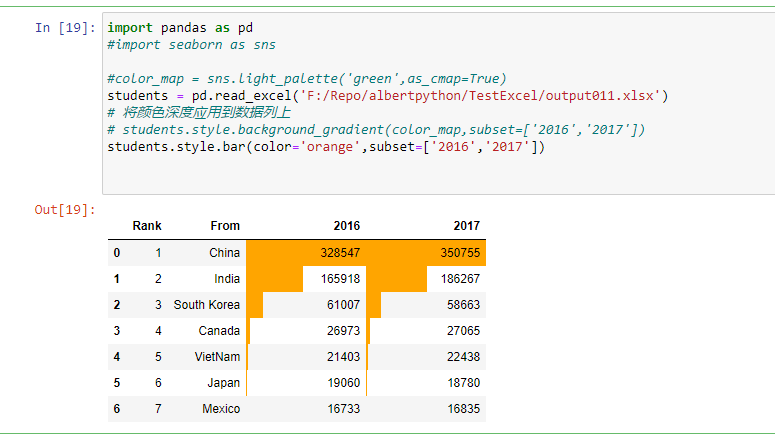
import pandas as pd#import seaborn as sns#color_map = sns.light_palette('green',as_cmap=True)students = pd.read_excel('F:/Repo/albertpython/TestExcel/output011.xlsx')# 将颜色深度应用到数据列上# students.style.background_gradient(color_map,subset=['2016','2017'])students.style.bar(color='orange',subset=['2016','2017'])
行操作集锦
import pandas as pdstudents1 = pd.read_excel('F:/Repo/albertpython/TestExcel/output011.xlsx',sheet_name='Sheet1')students2 = pd.read_excel('F:/Repo/albertpython/TestExcel/output011.xlsx',sheet_name='Sheet2')# 两个Sheet合并为一个,重置index_col drop=True放弃原来的student_total = students1.append(students2).reset_index(drop=True)# 追加手动创建的一行stu = pd.Series({'Rank':100,'From':'USA','2016':90,'2017':100})student_total=student_total.append(stu,ignore_index=True)# 更改其中一行的值student_total['From'].at[13] = 'Mexico3'student_total.at[12,'From'] = 'Japan3'# 插入一行 切片技术stu = pd.Series({'Rank':101,'From':'USB','2016':90,'2017':100})# 左闭右开part1 = student_total[:10]part2 = student_total[10:]student_total = part1.append(stu,ignore_index=True).append(part2).reset_index(drop=True)# 删除数据行# student_total.drop(index=[0,1,2],inplace=True)# student_total.drop(index=range(4,6),inplace=True)for i in range(5,8):student_total['From'].at[i] =''missing_data = student_total.loc[student_total['From']=='']student_total.drop(index=missing_data.index,inplace=True) #切片的方式传入student_total.reset_index(drop=True) # 重新铺一下indexprint(student_total)
列操作集锦
import pandas as pdimport numpy as npstudents = pd.read_excel('./TestExcel/output014.xlsx',sheet_name='Students')scores = pd.read_excel('./TestExcel/output014.xlsx',sheet_name='Scores')# 列横向拼接list_total = pd.concat([students,scores],axis=1).reset_index(drop=True)print(list_total)# 行追加第二种写法list_total2 = pd.concat([students,scores],ignore_index=True).reset_index(drop=True)print(list_total2)# 将ID相同Join进来list_total3 = students.merge(scores,how='left',on=['ID','ID'])# 追加一列:list_total3['Age'] = 25list_total3['RealAge'] = np.arange(0,len(list_total3))print(f'Total3:\n{list_total3}\n')print(np.arange(0,len(list_total3)))# 删除列list_total3.drop(columns=['Age','RealAge'],inplace=True)print(f'DropTotal3:\n{list_total3}\n')# 插入列list_total3.insert(1,column='Foo',value=26)print(f'DropTotal3:\n{list_total3}\n')# 列名大写list_total3.rename(columns={'Foo':'FOO'},inplace=True)print(f'Upper:\n{list_total3}\n')# 删除空行list_total3.dropna(inplace=True)print(f'Dropnan:\n{list_total3}\n')
读取数据库
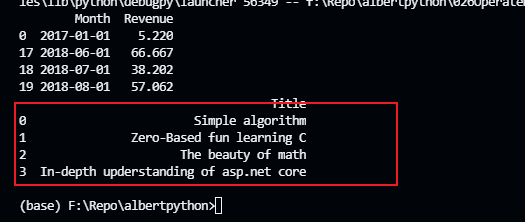
import pandas as pdimport numpy as npimport pyodbc as dbc# ORM框架 create_engineimport sqlalchemybooks = pd.read_excel('./TestExcel/output019.xlsx')print(books)# 此处注意Server={ServerName} ServerName未必是{local}connection = dbc.connect('Driver={SQL Server};''Server={DESKTOP-07OJ9VD};''Database=AlbertBook;''Trusted_Connection=yes;')query = 'Select Title from T_Books'df1 = pd.read_sql_query(query,connection)print(df1)
编写复杂方程
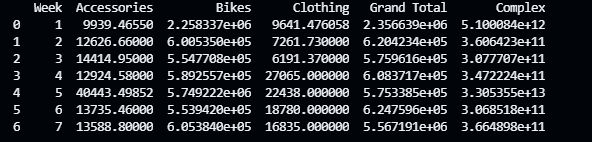
import pandas as pdimport numpy as npdef cal_bike_complex_clothing(b,c):return b**2+c*np.pisales = pd.read_excel('./TestExcel/output012.xlsx')sales['complex'] = sales.apply(lambda row:cal_bike_complex_clothing(row['Bikes'],row['Clothing']),axis=1)#将列名大写sales.rename(columns={'complex':'Complex'},inplace=True)sales.drop(columns={'Components'},inplace=True)print(sales)

若有收获,就点个赞吧
0 人点赞
