聊一聊网络程序的发展, 有利于了解Netty为什么设计成这样
这里默认各位都知道UDP和TCP协议是什么
理解了实现再谈网络性能_202202更新.pdf https://zh.wikipedia.org/wiki/Berkeley%E5%A5%97%E6%8E%A5%E5%AD%97 The Java Community Process(SM) Program - JSRs: Java Specification Requests - detail JSR# 51 The C10K problem 如何处理10000 TCP连接 - OSCHINA - 中文开源技术交流社区 为什么QQ用的是UDP协议而不是TCP协议?-悬赏问答/综合互动区 - 即时通讯开发者社区! 高性能网络编程(一):单台服务器并发TCP连接数到底可以有多少-网络编程/专项技术区 - 即时通讯开发者社区! 高性能网络编程(二):上一个10年,著名的C10K并发连接问题-网络编程/专项技术区 - 即时通讯开发者社区! 高性能网络编程(五):一文读懂高性能网络编程中的I/O模型-网络编程/专项技术区 - 即时通讯开发者社区! 高性能网络编程(六):一文读懂高性能网络编程中的线程模型-网络编程/专项技术区 - 即时通讯开发者社区! 新手入门:目前为止最透彻的的Netty高性能原理和框架架构解析-网络编程/专项技术区 - 即时通讯开发者社区! 高性能网络编程(七):到底什么是高并发?一文即懂!-网络编程/专项技术区 - 即时通讯开发者社区!
网络IO模型发展的一些时间点
- 1983年Unix操作系统(于1983发布)的一套应用程序接口
- 1996年1月23日,Sun Microsystems 宣布发布 Java 1.0
- 1999年 Dan Kegel 提出了C10K问题(concurrently handling ten thousand connections)
- 1999年2月10日,腾讯公司正式推出第一版QQ——OICQ
- 2002年 Java 1.4, JSR 51, 第一版 NIO, https://jcp.org/en/jsr/detail?id=51
1.BIO时代
Berkeley套接字
1983年, Berkeley套接字(也作BSD套接字应用程序接口)刚开始是4.2BSD Unix操作系统的一套应用程序接口
Berkeley套接字应用程序接口形成了事实上的网络套接字的标准精髓。 大多数其他的编程语言使用与这套用C语言写成的应用程序接口[1] 类似的接口。 这套应用程序接口也被用于Unix域套接字(Unix domain sockets),后者可以在单机上为进程间通讯(IPC)的接口。

- Java在类Unix系统上都是通过调用这些系统接口进行网络通信的
其实Berkeley套接字是支持IO复用的网络模型的, 但是Java第一版没有选择IO复用的网络模型
JavaBIO
BIO是java1.0就有的IO模型
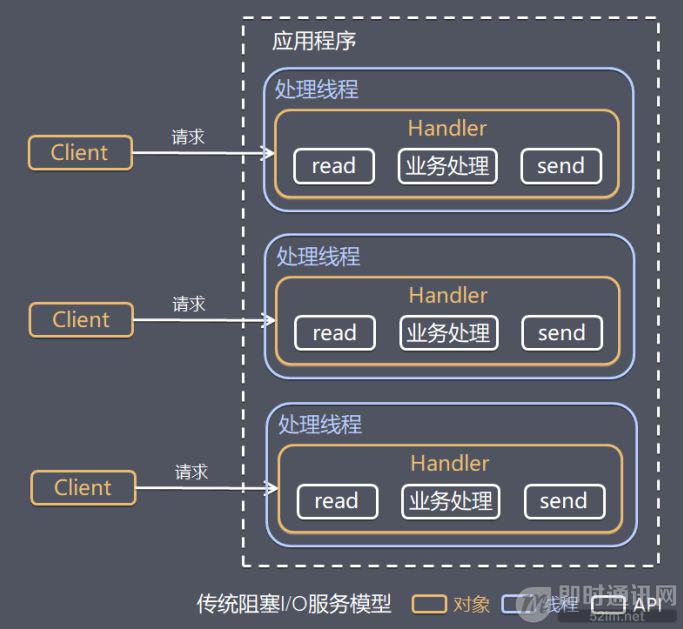
基于Linux的Java就是基于Berkeley套接字设计的IO模型, 虽然Berkeley套接字提供了IO多路复用的使用方式, 但是Java1.0并没有使用, 依然使用的是传统的一个线程处理一个连接
远古时期服务端的网络程序开发, 都是一个线程对应一个连接, 那个年代不仅仅是Java, 其他的编程语言, 网络模型都是一个线程处理一个连接
这里指的是Java1.4之前BIO的好处
那就是编程的时候, 非常符合人类的直觉, 在一个线程中的操作都是线性的, 写出来的代码稳定, 可维护性高
BIO的问题
在Linux上进程上下文切换一次, 得需要几个微秒, BIO要处理成百上千个线程, 就会浪费大量的CPU时间片去切换上下文, 一旦连接数过大(比如1000个), 性能会急剧下降
2.C10K问题
英文原文: http://www.kegel.com/c10k.html
中文翻译: https://www.oschina.net/translate/c10k
- 在 1999 年,Dan Kegel 提出了一个针对网络服务器的难题:
是时候让网络服务器去同时应对 10000 个客户端了,你觉得呢?毕竟网络已经变得很普及了。
那个年代, 网络编程的模型都是BIO的模型 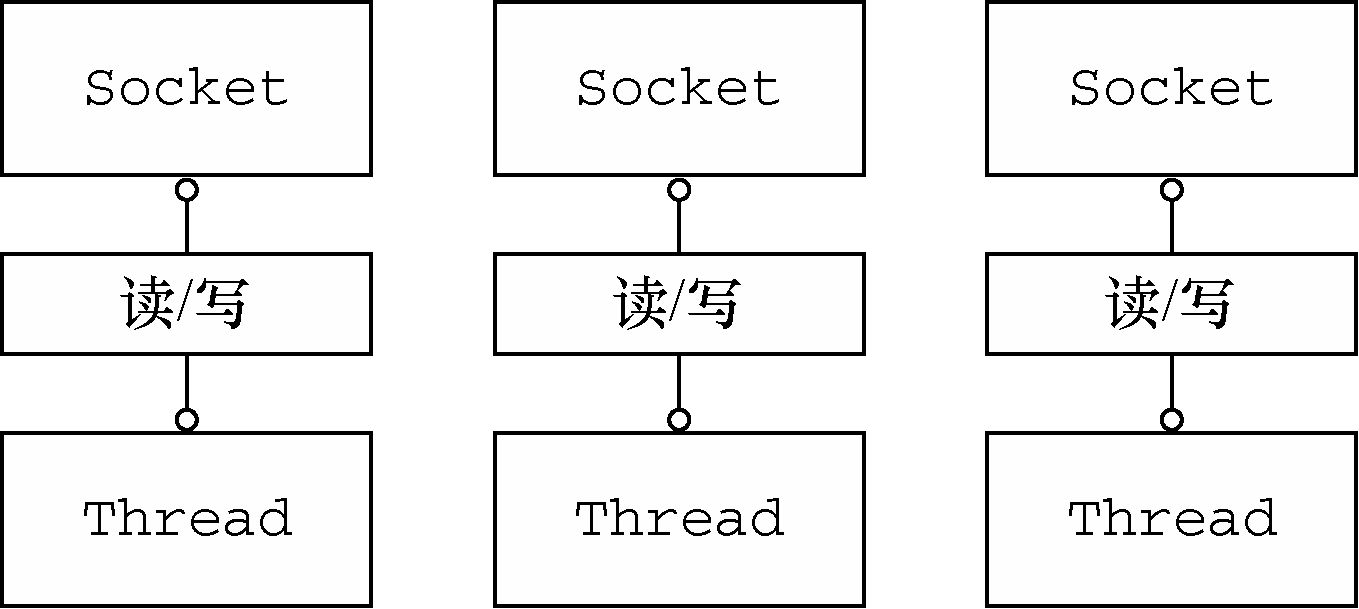
但实际上, CPU在这么多线程上, 并不是一直都在处理读写操作, 更多的是在切换上下文, 和等待, 这他妈不是妥妥的浪费么,
这些上下文切换, 就跟很多大公司的制度一样, 纯纯的浪费人力物力 
站在Java的角度去看BIO, 浪费了哪些资源:
- 大量线程处于休眠状态
- 线程多了, 自然上下文切换就多了
- 内存的浪费: 每个线程的调用栈都分配内存(64KB~1MB)
如此的浪费让机器很难满足C10K的需求
那么要让一个服务器支持更多的并发连接,其实是完全可以达到的, 想办法把无用的浪费干掉就OK了家人们
3.单台服务器并发TCP连接数到底可以有多少
上面讨论了BIO的先天问题, 导致并发数上不去, 那么我们排除掉所有限制, 看看一台服务器理论上能达到多少并发
3.1 服务器理论最大并发数
(排除文件描述符限制, 排除内存消耗, 排除进程/线程切换消耗, 排除其他所有资源限制, 只层协议层面看)
发送方IP:port — 接收方IP:port
假设这里接收方IP和PORT固定不变
IP 地址是⼀个 32 位的整数,所以发送方 IP 最⼤有 2 的 32 次⽅这么多个。 端⼝是⼀个 16 位的整
数,所以端⼝的数量就是 2 的 16 次⽅。 2 的 32 次⽅(ip数)× 2的 16 次⽅(port数)⼤约等于两百多万亿。-
3.2 内存开销
- 文件句柄: 一个连接要占据一个文件句柄 FD
每一条TCP链接都需要file,socket等内核对象; 等于一条空TCP连接最起码得消耗3.3KB左右的内存空间
如果连接要接收数据就需要接收缓冲区了
接收缓冲区: 接收缓存区大小是可以配置的,通过sysctl命令就可以查看。比如这里是4K
$ sysctl -a | grep rmemnet.ipv4.tcp_rmem = 4096 87380 8388608net.core.rmem_default = 212992net.core.rmem_max = 8388608
“其中在tcp_rmem”中的第一个值是为你们的TCP连接所需分配的最少字节数。该值默认是4K,最大的话8MB之多。也就是说你们有数据发送的时候我需要至少为对应的socket再分配4K内存,甚至可能更大。”
发送数据缓冲区: TCP分配发送缓存区的大小受参数net.ipv4.tcp_wmem配置影响。这里是4K
$ sysctl -a | grep wmemnet.ipv4.tcp_wmem = 4096 65536 8388608net.core.wmem_default = 212992net.core.wmem_max = 8388608
“在net.ipv4.tcp_wmem”中的第一个值是发送缓存区的最小值,默认也是4K。当然了如果数据很大的话,该缓存区实际分配的也会比默认值大。”
- 如果是空TCP连接, 那么100w个连接只需要3.5G左右的内存空间
- 如果是活动的TCP连接, 那么也就是一个TCP连接大约需要12K的内存空间
3.3 CPU开销
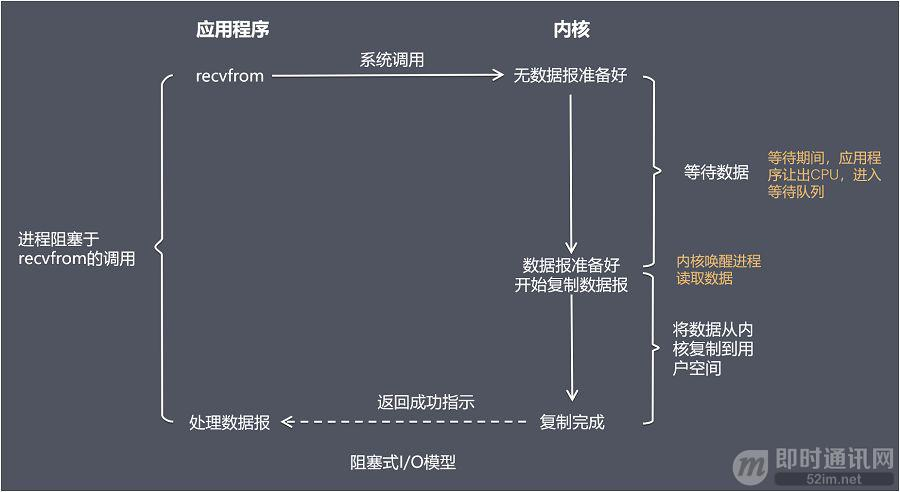
- 这是BIO的工作流程
- 这是I/O 复用模型的工作流程
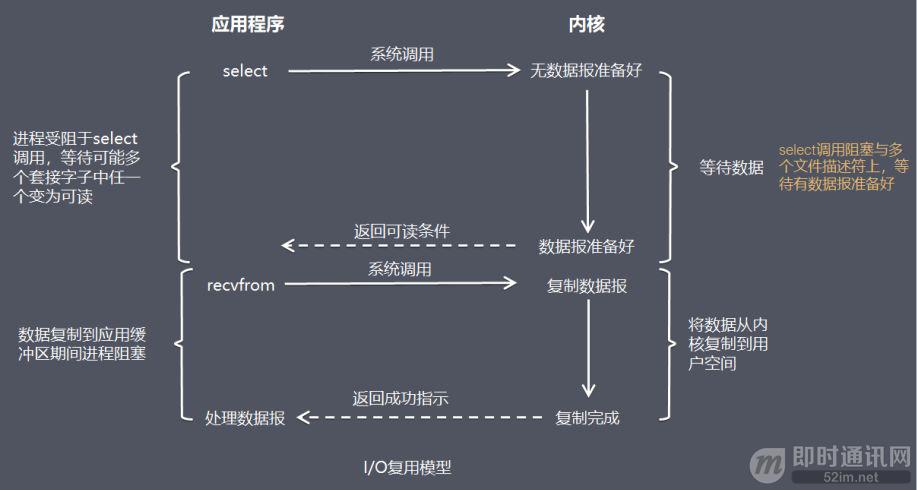
单纯看TCP协议下的网络包处理中,CPU的开销
- 系统态CPU开销: 当⽤户进程调⽤ socket、connect、recvfrom 等等函数的时候,都会将⽤户进程陷⼊到内核态; 这些是必须的
- 硬中断, 软中断: 内核收到包以后会在硬中断、软中断上下⽂中进⾏内核相关⼯作的处理; 这些是必须的
- 进程上下文切换
也就是说, 后面对网络模型的改进, 实际上就是想办法消除进程(线程)上下文切换对CPU的消耗
4.QQ是怎么处理网络连接的问题?
- QQ是1999年出现的即时通讯软件, QQ的一个服务器需要支持大量的客户端连接
那个年代基于TCP协议的网络模型, 都是一个线程对应一个连接, 别说腾讯了, 全世界基于TCP的网络应用都无法处理大量的TCP连接
于是腾讯选择了UDP协议, 自己模拟了三次握手之类的操作, 封装了一下, 相当于模拟了TCP, 这样就可以绕开Linux提供的标准的函数, 自己决定如何触发监听网络事件
虽然之后Linux出现了epoll, 解决了腾讯以前遇到的内核接口无法很好支持大量TCP连接问题, 但是由于腾讯自己搞的基于UDP的那套很成熟很稳定了,于是就没有改回使用TCP了
现在再做类似的东西就不需要使用udp了
5.IO模型

Linux提供了几个网络编程的接口, 可以通过这些接口实现IO复用的网络模型
select
- 每次调用select函数都会把所有需要关注的文件描述符都传进去
- select 入参是个数组, select返回的是含有整个句柄的数组,应用程序需要遍历整个数组才能发现哪些句柄发生了事件
select 是水平触发, 只要有IO数据可读, 就会触发通知
poll
每次调用poll函数都会把所有需要关注的文件描述符都传进去
- poll 入参是个链表
-
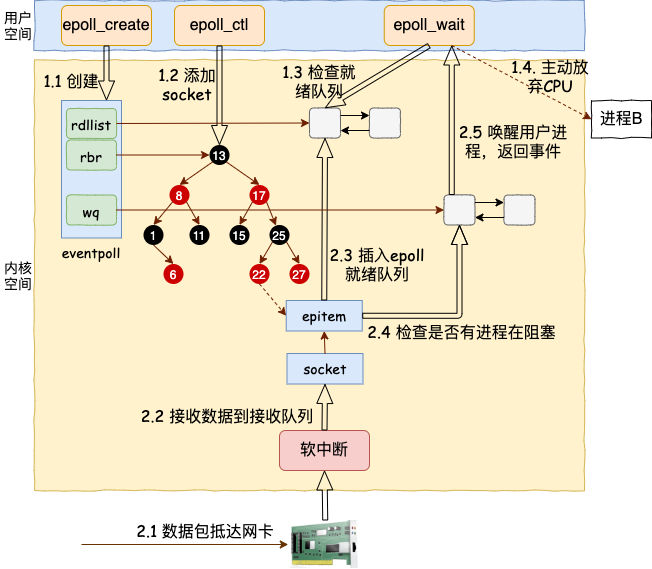
epoll
epoll每次调用只会向多路复用器传入新需要关注的文件描述符
- epoll开辟了一个内存空间, 专门保存需要监听的文件描述符(红黑树)
- epoll是边缘触发, 只有新的IO活动到来, 才会触发通知; 即使通道中有数据也不会再触发
IO复用模型
在 I/O 复用模型中,会用到 select 或 poll 函数或 epoll 函数,这三个函数也会使进程阻塞,但是和阻塞 I/O 有所不同。
这三个函数可以同时阻塞多个 I/O 操作,而且可以同时对多个读操作,多个写操作的 I/O 函数进行检测,直到有数据可读或可写时,才真正调用 I/O 操作函数。
- BIO一个线程阻塞的时候, 只能监听一个连接的一个事件
- IO多路复用的模式, 一个线程阻塞的时候, 可以监听一堆连接的各种事件
6.JavaNIO
Channel
java.nio.channels.Channel
Java把所有IO连接抽象成了一个Channel对象, 包括文件IO,网络IO等等
java.nio.channels.SocketChannel
为了消除不同操作系统之间的差异 , SocketChannel是专门处理网络IO的抽象, 可以认为它表示一个TCP连接;
事件
SelectionKey.OP_ACCEPT: 接收连接进行事件,表示服务器监听到了客户连接,那么服务器可以与客户端建立TCP连接SelectionKey.OP_CONNECT: 连接就绪事件,表示客户与服务器的连接已经建立成功SelectionKey.OP_READ: 读就绪事件,表示通道中已经有了可读的数据,可以执行读操作了(通道目前有数据,可以进行读操作了)SelectionKey.OP_WRITE: 写就绪事件,表示已经可以向通道写数据了(通道目前可以用于写操作)
7.Netty
既然Java有了NIO标准的编程库为什么还要用Netty
JavaNIO的问题
- NIO 的类库和 API 繁杂,使用麻烦:你需要熟练掌握 Selector、ServerSocketChannel、SocketChannel、ByteBuffer 等。
- 需要具备其他的额外技能做铺垫:例如熟悉 Java 多线程编程,因为 NIO 编程涉及到 Reactor 模式,你必须对多线程和网路编程非常熟悉,才能编写出高质量的 NIO 程序。
- 可靠性能力补齐,开发工作量和难度都非常大:例如客户端面临断连重连、网络闪断、半包读写、失败缓存、网络拥塞和异常码流的处理等等。NIO 编程的特点是功能开发相对容易,但是可靠性能力补齐工作量和难度都非常大。
- JDK NIO 的 Bug:例如臭名昭著的 Epoll Bug,它会导致 Selector 空轮询,最终导致 CPU 100%。官方声称在 JDK 1.6 版本的 update 18 修复了该问题,但是直到 JDK 1.7 版本该问题仍旧存在,只不过该 Bug 发生概率降低了一些而已,它并没有被根本解决。 Java NIO中的 epoll bug分析与复现_speakguoer的博客-CSDN博客
Netty如何解决JavaNIO的问题
- Netty 对 JDK 自带的 NIO 的 API 进行了封装,解决了上述问题。
- 设计优雅:
- 适用于各种传输类型的统一 API 阻塞和非阻塞 Socket;(统一的异步 I/O API - netty中文指南
- 基于灵活且可扩展的事件模型,可以清晰地分离关注点;(Netty 4.x 基于拦截链模式的事件模型_w3cschool)
- 高度可定制的线程模型 - 单线程,一个或多个线程池;(Netty系列之Netty线程模型性能调优李林锋_InfoQ精选文章)
- 真正的无连接数据报套接字支持(自 3.1 起)(Netty 实现 UDP 通讯_PAX-K的博客-CSDN博客_netty udp)。
- 使用方便:
- 详细记录的 Javadoc,用户指南和示例;没有其他依赖项,JDK 5(Netty 3.x)或 6(Netty 4.x)就足够了。
- 高性能、吞吐量更高:
- 延迟更低;减少资源消耗;最小化不必要的内存复制。(Netty中关于Direct Buffers的问题思考)
- 安全:
- 完整的 SSL/TLS 和 StartTLS 支持。(Netty应用示例(二)SSL/TLS应用示例)
- 社区活跃、不断更新:
社区活跃,版本迭代周期短,发现的 Bug 可以被及时修复,同时,更多的新功能会被加入。(Netty: Get Involved)
Java的NIO代码怎么写
https://gitee.com/spitman/learnnetty/blob/master/src/main/java/org/zyj/io/SelectorNIO_2.java
其实Java中NIO,BIO,AIO等待写法都是不一样的, 更别说UDP协议更不一样了, 因为JDK提供的API就是分开的
Netty的代码怎么写
https://gitee.com/spitman/learnnetty/blob/master/src/main/java/org/zyj/io/NettyIO_2.java
Netty统一了Java中网络编程的API, 写法不仅仅支持NIO, 还对BIO或者UDP协议都有很好的支持

若有收获,就点个赞吧
0 人点赞
