_ 这个示例是做什么的呢?
由于JVM的复杂性,每次测试结果都有差异
怎么消除这种差异, 对我们判断影响呢?
就是多测几次, 用多个JVM多跑几次benchmark
这里可以使用@Fork注解很方便地启动多个 JVM 经过多次测试来消除这种差异
—-
大数法则: 在数学与统计学中,大数法则(又称大数定律、大数律)是描述相当多次数重复实验的结果的定律。根据这个定律知道,样本数量越多,则其算术平均值就有越高的概率接近期望值。
大数定律很重要,因为它“说明”了一些随机事件的均值的长期稳定性。
_
之前介绍了那么多Fork怎么使用, 那么我们什么时候该使用它呢?
我们现在来介绍一下JMH官方示例的第三个例子
(从上介绍一下这个例子的干了什么)
这个例子解释了为什么需要fork?
……………………
从这个例子中我们可以看出
如果我们的代码带有一定的随机性
比如Java程序启动的时候会随机生成一些值, 然后整个执行过程中都会使用它
比如我们有些取随机算法, 会在启动的时候生成一个种子, 然后整个运行过程中都使用这个种子
那么, 我们JMH仅仅执行一遍是不能够覆盖所有情况的, 代表不了普遍的情况,
那有些人又说了, 你测试一百万遍都不能代表普遍情况, 那我们看这个报告还有什么意义?
在统计上有一个大数法则, 当我们试验样本足够多的情况下, 结果分布就越接近于期望值
我们如果想要知道一个算法的平均值, 那就多测几次
怎么消除这种不确定性呢?
那就需要大量的测试
@State(Scope.Thread)public static class SleepyState {public long sleepTime;@Setuppublic void setup() {sleepTime = (long) (Math.random() * 1000);}}
有点数学知识的都知道, 这个sleepTime的预期值应该是500
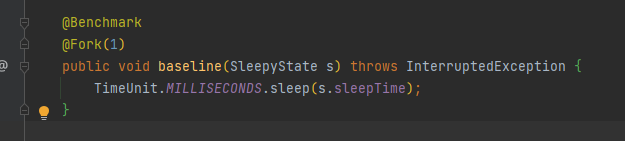
baseline
Fork5
@Benchmark@Fork(5)public void fork_1(SleepyState s) throws InterruptedException {TimeUnit.MILLISECONDS.sleep(s.sleepTime);}
Fork20
@Benchmark@Fork(20)public void fork_2(SleepyState s) throws InterruptedException {TimeUnit.MILLISECONDS.sleep(s.sleepTime);}
我们估计, 结果会越来越趋近与 预测值500
看看是不是这样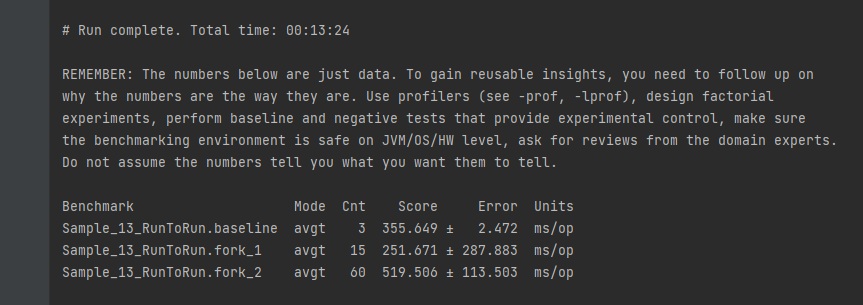

若有收获,就点个赞吧
0 人点赞
